
近年、ディープラーニングテクノロジーの使用は、パターン認識、自動翻訳などの分野で大きな進歩を遂げました。この成功は、GOゲームでの無人車両とコンピューターの成果の発展とともに、人工知能がすぐに想像できるようになりました。人々が今している仕事をし、彼らの仕事に応募します 。
ロボットによる人の普遍的な置き換えは魅力的なプロセスですが、高速ではありません。 ただし、今では、コンピューターの向上した計算能力を使用して、人々が日々直面するタスクの解決を促進することができます。 たとえば、プログラムを書くプロセス。 プログラミングプロセスを容易にするシステムの使用は例外的なものではなく、開発環境では多くのツールが提供されます。
この記事では、プログラマーがJava言語のモジュールに基づいてテストを作成するのに役立つテクノロジーを紹介します。 このテクノロジーは、テストを手動で作成する場合に比べて大幅に時間を節約できます。
テスト
ソフトウェアモジュールの作成プロセスでは、プログラムされた機能が要件を満たしていることを常に確認する必要があります。 作成したプログラムの実際の動作が期待される結果に対応することを知るために、テストが使用されます。
テストの作成の必要性、すべての長所と短所をここにリストします 。 ただし、テストの作成にはかなりの時間がかかることは確かです(開発者がテストの作成に費やす時間の最大30%を費やすことを研究が示しています )。 さらに、このアクティビティではメインソフトウェアモジュールの機能は開発されないため、多くのチームがテストの記述を避けようとするのは当然です。 一方、古い機能のサポートと新しい機能のプログラミングは、テストを使用しないと非常に複雑です。
テストでは、プログラムの正しい実行を確認するだけでなく、プログラムの機能を「自然言語」で説明することもできます。 つまり、テストスクリプトには、 BDDパラダイムのテストおよびテストプログラムの動作を説明するテキストドキュメントを添付できます。
この記事では、自動テスト生成のテクノロジーについて説明します。 テストの合成では、 ガーキン表記法を使用します。
Gherkinを使用したロシア語のテストの例:
# language: ru @all : PIN- , PIN- , PIN- : PIN- @correct : PIN- @fail : PIN- , PIN-
BDD、TDD
TDDおよびBDDのテクニックは、テスト対象モジュールの開発の前にテストが記述されることを意味します(テストによるhttps://ru.wikipedia.org/wiki/Development )。
テスト->モジュール
TDDおよびBDDアプローチの長所と短所については説明しませんが、モジュールの準備が整った後にテストを作成するか、テストをまったく作成しない場合、状況(およびこれらのケースのほとんどは最も可能性が高い)が非常に一般的であると言わなければなりません。 これは、コードが読みにくくなり、保守が困難になるという事実につながり、特にレガシーコードの現象につながります。
したがって、完成したコードに基づいて、テストとコード記述をBDD形式で合成する機会を提供します。テストがまったくない場合、またはソフトウェアモジュールの作成後にテストが記述される場合です。
モジュール->テスト
合成
テストを作成するプロセスは、完成したソフトウェアモジュールの分析から始まります。 現在、Javaで記述されたクラスを使用しています。 作業の一般的なスキームは次のとおりです。最初にソフトウェアモジュールの実行に関するログと情報を収集し、次にこれらのログに基づいてニューラルネットワークをトレーニングし、次にニューラルネットワークを使用して既製のテストスクリプトを生成します。
ログ収集
クライアントの銀行口座を提供するモジュールがあるとします。
プログラムの各ステップでログを収集します。入力と出力に関する情報で始まり、変数の変更で終わります。

コレクション自体は次のとおりです。
入力を取得します-アクセスログからのデータ、またはプログラマーによって提供されたオプション、またはさまざまな遺伝的またはランダムなメカニズム( Evosuite 、 Randoop )を使用して自動的に生成されたデータです。
特別な場合には、ログ収集モジュールを本番のままにしておくことができますが、一般的な場合、これは推奨されません。
ニューラルネットワークトレーニング
ニューラルネットワークトレーニングは、 Neural Programmer-Interpretersパラダイムで行われます。
NPIは次のように機能します。入力データ(図の「以前のNPI状態」、「環境観測」、「入力プログラム」)に基づいて、コマンド(「出力プログラム」)が予測します。

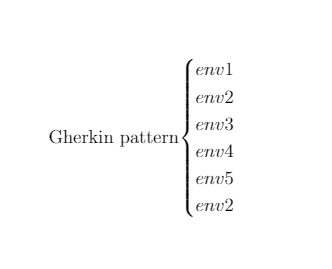
単純なプログラム(加算、スケーリングの操作)を予測するための環境を認識できるため、プログラムはこのデータのガーキン表記を予測できます。 NPIを使用する品質は、特定の入力データを処理する能力と、ニューラルネットワークのアーキテクチャの開発の両方に依存します。
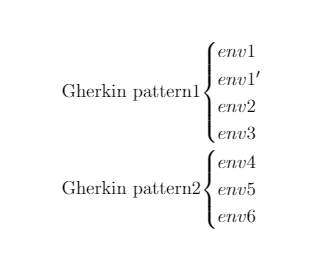
したがって、訓練されたニューラルネットワークは、ソフトウェア合成の従来の問題-現在の入力データ(env1 ')に適切なプログラム(ガーキン表記、テストケース)を見つける方法を解決します。
スクリプト生成。
トレーニングされたニューラルネットワークに基づいて、テストケースが生成されます。 最も単純なケースでは、有効に渡されたデータのリストと検証に失敗したデータのリスト。

完成したスクリプトは、最終要件を考慮して編集できます。 Gherkinテストは「自然言語」で記述されています。これは、コードを書いた人とモジュールの開発に関与しなかった人の両方が、チーム全体でこれらのテストを読み、編集できることを意味します。
テストを実行するたびに、テストでエンコードされた条件がチェックされます。 テストしたソフトウェアモジュールの機能が変更された場合、ニューラルネットワークを再トレーニングして新しいテストを生成できます。
Gherkin言語でのテストの実行は、 Cucumberテストフレームワークで実行されます。
フレームワークは、Mavenを使用したアセンブリ中の自動スクリプト実行をサポートしています。
<dependency> <groupId>info.cukes</groupId> <artifactId>cucumber-java</artifactId> <version>1.2.4</version> <scope>test</scope> </dependency> <dependency> <groupId>info.cukes</groupId> <artifactId>cucumber-junit</artifactId> <version>1.2.4</version> </dependency>
Cucumberは、Jenkinsなどの他の継続的統合ツールとも統合されます。
テストスクリプトの生成、制限
自動ジェネレータには、一度にいくつかの制限があります。 それらはすべて、プログラムがアルゴリズムを「学習」せず、アルゴリズムを「理解」しないためです。 プログラムの目的は、理解可能なタイプの入力データを出力データと比較し、 条件付きプログラム生成の単純なケースであるラベルを選択できるようにすることです。
シンプルなケース
プログラムの論理を直観したり深く理解していなければ、システムはプログラム障害の単純なケース(たとえば、エラーメッセージにつながるパラメーター)のみを検出できますが、同時に、プログラマーのみが検出できるケースが残ります。
記録されたパラメータの限定セット
ニューラルネットワークによってプリミティブタイプ(線、数字)をログに記録して分析することは簡単ですが、オブジェクトをログに記録して分析することはより困難です。
単純な関係を特定する
したがって、単純なデータの単純な関係を簡単に識別できます。 上記のすべては、現時点では、自動テストの検証と改良が手動であることを意味しています。
見込み
システムの開発の主な方向は、認識可能なパターンの数と複雑さを増やすことです。
興味のある場合は、詳細について話し合うことができます-nayname@gmail.comへのメール