
ニューラルネットワークは誰も驚かないでしょう。 ほとんどの人は、機械学習とは何か、線形回帰、ランダムフォレストを知っています。 毎年、何千人もの人々がODSとCourseraで機械学習コースを受講しています。 数週間のうちに、生徒はケラスをマスターし、neurochochkiをリベットできるようになりました。 しかし、ニューラルネットワークでは、すべての機械学習と同様に、優れたアルゴリズムの作成に加えて、アルゴリズムをトレーニングするデータが必要です。
自己紹介させてください、私の名前はRoman Kutsevです。 私は、Prisma AIのRnDチームで働いており、タスクのデータセットを作成しています。
そのため、突然製品のリクエストが届きます。KirkorovとFaceを区別するニューロンが緊急に必要です(もちろん、これは架空の例です。このようなナンセンスは扱いません)。
アントン(ニューロンの主なもの)にどのようなデータが必要かを尋ねると、「2つのフォルダー、1つのFaceの画像、もう1つのKirkorov、できればクラスごとに約500の画像があり、299x299である」と聞きます。
データはどこにありますか?
- ImageNet 、 COCO 、 openimagesなどの公開データセットを調べます。
- 人気のあるパブリックデータセット、グーグルで必要なタグ付きデータがない場合、必要なデータセットへのリンクがどこかにあることを期待して、arxiv.orgでこれらのトピックに関する記事を開きます。
- 最初の2つのポイントが失敗した場合、必要なデータセットはないため、作成する必要があります!
明らかに、これまでKirkorovとFaceを分類するタスクを扱った人はいませんでした。 したがって、このようなデータセットを自分で作成する必要があります。
パイプラインは次のとおりです。
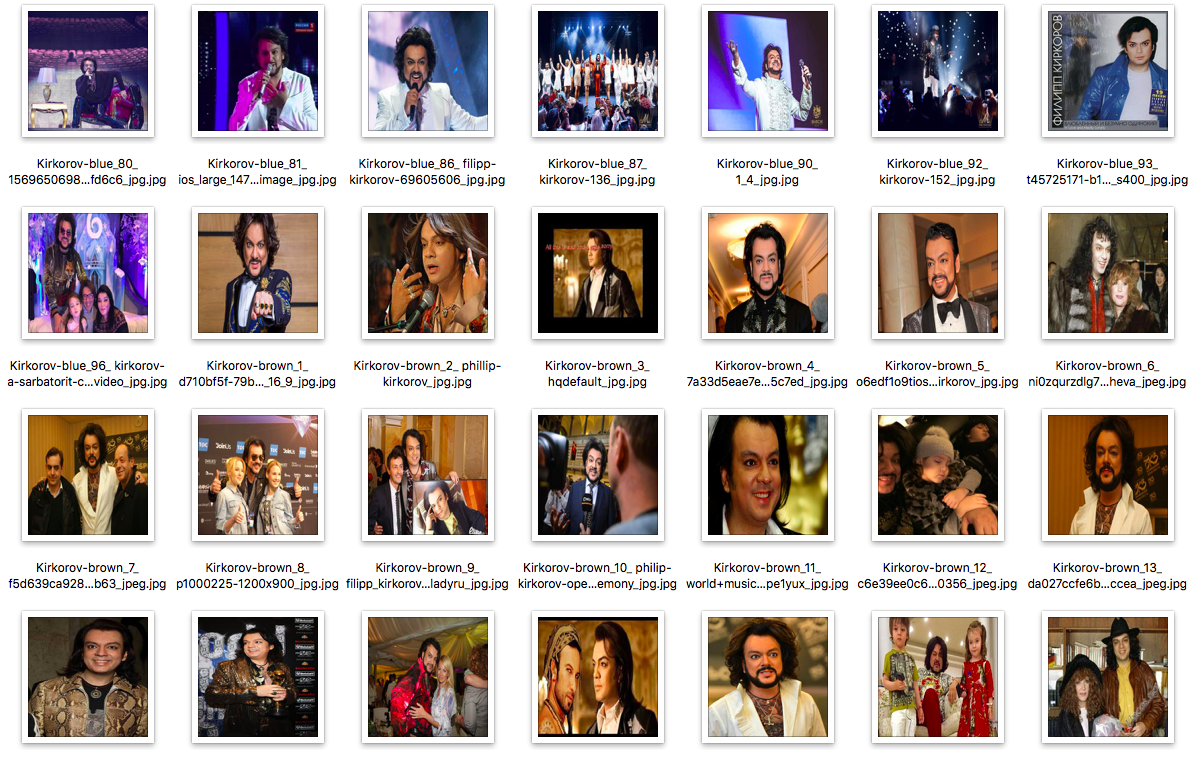
- GoogleからKirkorovとFaceの1k画像をダウンロードします。
- 目的のサイズに変更します。
- Yandex Tolokのフリーランサーで確認します。
ダウンロードには、 Google Images Downloadを使用します 。
ターミナルでは次のように記述します。
googleimagesdownload -k '' -l 1000 -t photo -s '>400*300' -o 'Kirkorov' googleimagesdownload -k ' Face' -l 1000 -t photo -s '>400*300' -o 'Face'
(実際、すべてがそれほど単純ではなく、1つのリクエストでダウンロードできるのは100枚の画像のみであるため、異なる設定でダウンロードする必要があります)
すぐに画像のサイズを299x299に変更します。このため、この関数をスケッチしました。
from PIL import Image import multiprocessing, time, os def resize_img(img_path): img = Image.open(os.path.join('Kirkorov',img_path)) img = img.resize((299,299), Image.ANTIALIAS) img.save(os.path.join('Kirkorov_resize',img_path)) num_processes = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=num_processes) st = time.time() pool.map(resize_img, os.listdir('Kirkorov')) print("Execution time: ", time.time()-st)
画像を見ると、基本的に目的の画像がダウンロードされていることがわかりますが、場所によってはゴミがあります。




さて、最初の2つのポイントは準備ができており、3番目のポイントは残っています。
それでもYandex Tolokが何かわからない場合は、 この記事とこの記事を読むことをお勧めします。
一言で言えば:Toloka-ステロイドのフリーランス交換。顧客がタスクを作成し、データをダウンロードし、フリーランサーがそれを実行します。 もちろん、他のマークアップツールもありますが、このタスクにはTolokaを使用するのが最も便利です。
Yandex Tolokaの使用を開始する方法:
1. sandbox.toloka.yandex.ruおよびtoloka.yandex.ruに顧客として登録します(sandboxは、タスクを作成し、フリーランサーの側から正当性をチェックし、すべてが問題なければtoloka.yandexに転送するサンドボックスです。 .ru )。
2. toloka.yandex.ruアカウントで、残高を補充します。
3. [プロジェクト]タブのsandbox.toloka.yandex.ruで、[プロジェクトの作成]を選択します。

4.既製のテンプレートが提供されます。 すべてのテンプレートのうち、「画像の分類」テンプレートが最適です。 選択します。

5.フリーランサー向けの指示とプロジェクト名を作成します。
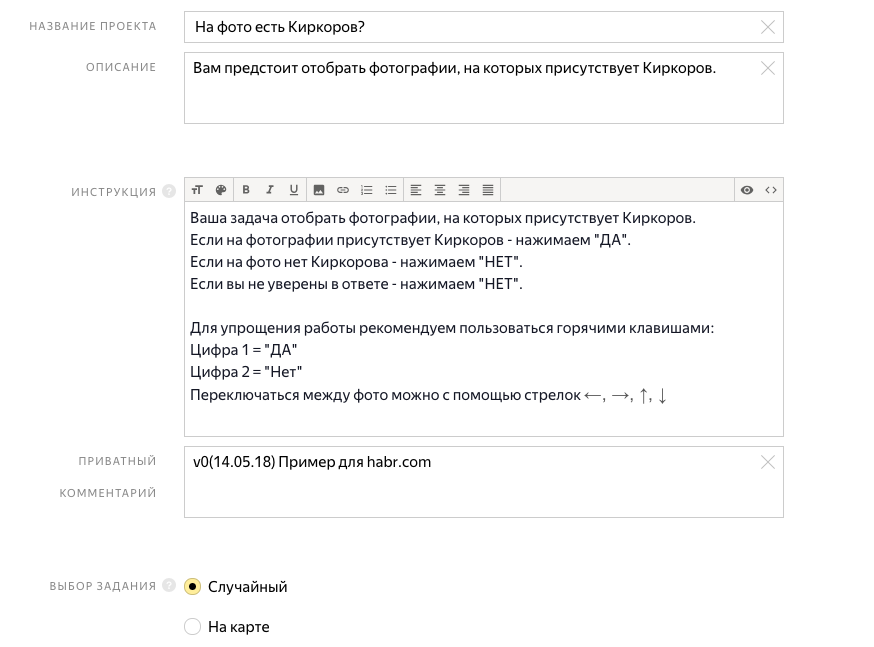
6.タスクへの入力パラメーターには、画像へのURLがあります。 週末:ライン出力。 タスクインターフェイスはhtmlとjavascriptで記述されています(これは非常に便利です。ほとんどのタスクで、実行者に表示されるページを作成できるからです)。 htmlテンプレートを少し変更すれば完了です。 プロジェクトを保存します。
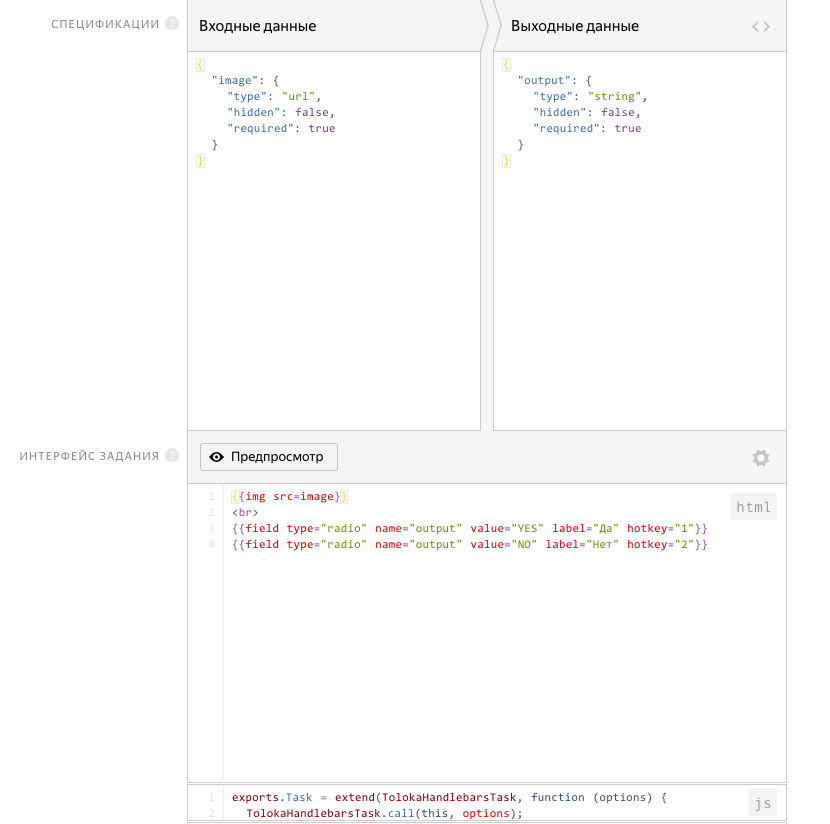
7.プロジェクトの準備ができました。 これで、 タスクプールを追加できます 。 この記事では、トレーニングプールを作成しません(フリーランサーが私たちの最も難しいタスクをすぐに達成できることを望みます)。 ただし、課題には常に学習プールを作成します。 これにより、以下が可能になります。
- タスクを理解していない人々を除草します。
- タスクに対して常に同じ答えを選択するボットを許可しないでください。
- 実行者にタスクを正しくかつ効率的に完了するように教える。
プールの名前を思いつきます(それは私たちだけが見ることができます)。 タスクのページあたり0.01ドルの価格を設定します。 貪欲Yandexは0.005ドルの手数料を取ります。 タスクの時間:10分。 重複:3(私たちの写真はそれぞれ3人の異なる人々に表示されます)。 「成人向けコンテンツ」をオンにします。そうでなければ、インターネットからダウンロードできるほど悪くはありません。 そして、貧しい仕事をするフリーランサーにお金を与えないために、「遅延受け入れ」を有効にします。
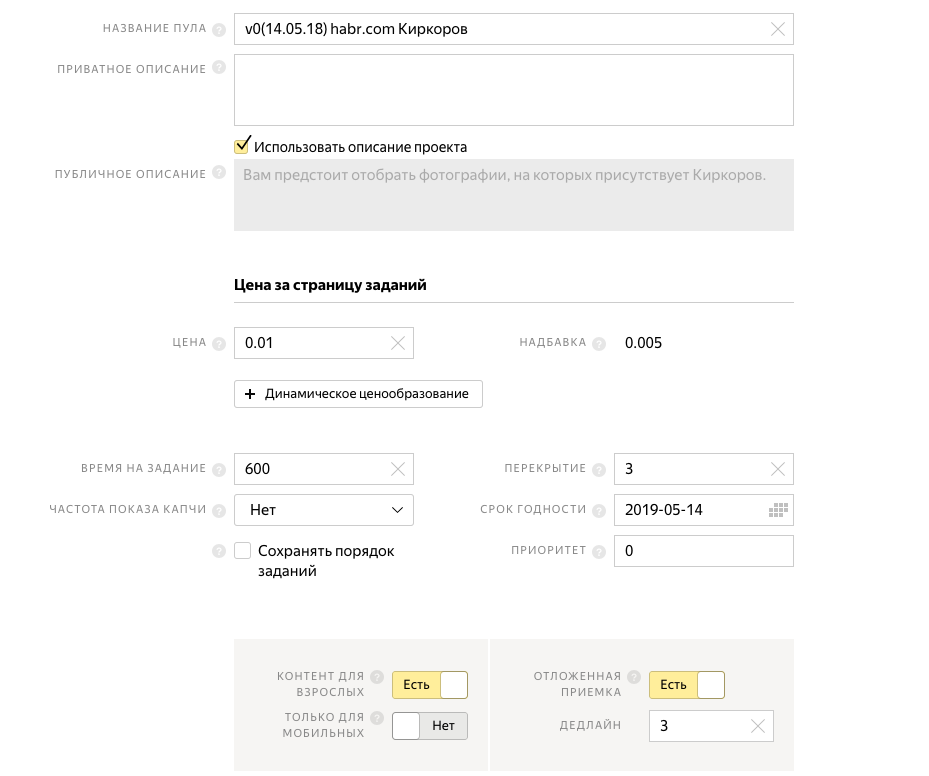
次の項目は「ユーザーの要件」です。ここでは、パフォーマーに要求を出すことができます。 私たちの場合、パフォーマーはロシア出身で、ロシア語を話さなければなりません。 各パフォーマーには独自の評価があり、適切な評価のパフォーマーのみを選択できます。 最高のパフォーマンスの80%を選択します。
開発に関して最も重要で最も難しいのは、品質管理ユニットです。 それについての個別の説明は記事全体を描くので、あなたはそれをよく理解することをお勧めします。 私たちのプロジェクトでは、クイックアンサーの制限を選択しました。 請負業者が5秒のうち3回の回答を40秒より速くすると、システムは彼をブロックします。
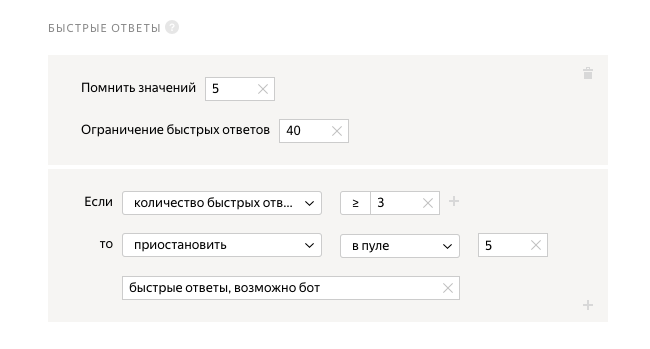
素晴らしい、私たちはフィニッシュラインにいます。ほんの少し残っています。 プールを保存します。
8.作成されたプールで、サンプルブートファイルをダウンロードします。 リンクを介してアクセスできるように、画像をYandex Diskまたはサーバーにアップロードします。 [入力:画像]フィールドで、URLを画像に貼り付けます。 例:
INPUT:image http://kucev.ru/Kirkorov/Kirkorov-pink_17_ 21787_l_jpg.jpg http://kucev.ru/Kirkorov/Kirkorov-green_82_ hqdefault_jpg.jpg http://kucev.ru/Kirkorov/Kirkorov-pink_25_ hqdefault_jpg.jpg
受信したtsvファイルをYandex Tolokuにアップロードします。 一度にアーティストに表示する画像の数を指定します。
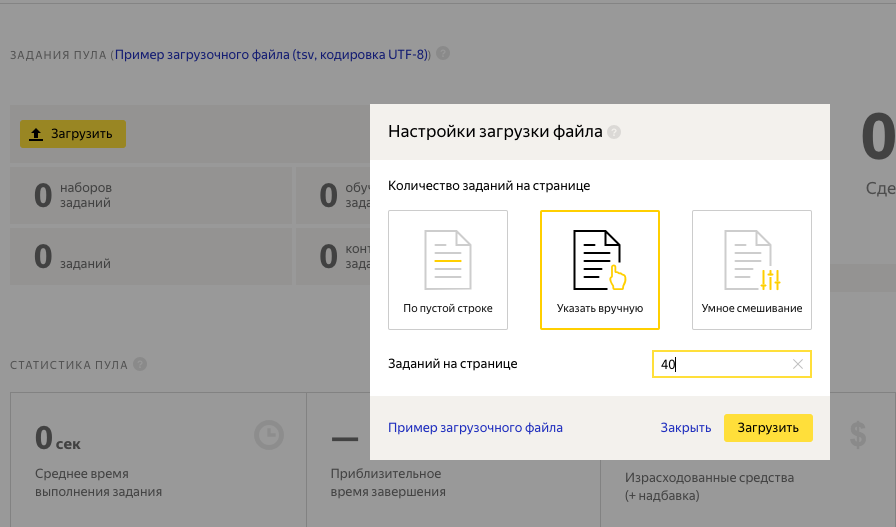
まあ、エラーは出なかったので、すべてを正しく行い、プールを開始できます。
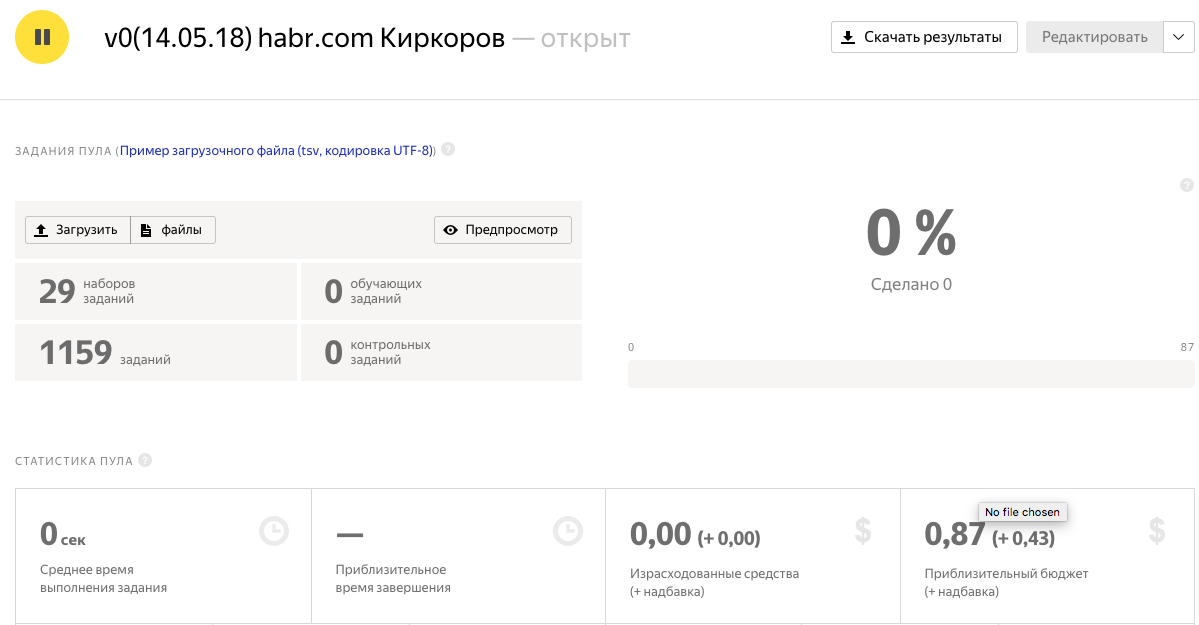
9.次に、パフォーマー側からすべてが正しく表示されることを確認する必要があります。 これを行うには、 sandbox.toloka.yandex.ruに新しいアカウントを作成します(アーティストとしてのみ)。 顧客のアカウントで[ユーザー]タブを選択し、信頼できるユーザーのリストに新しいアーティストアカウントを追加します。
プールが実行されている場合、タスクはアーティストのテストアカウントから使用できます。
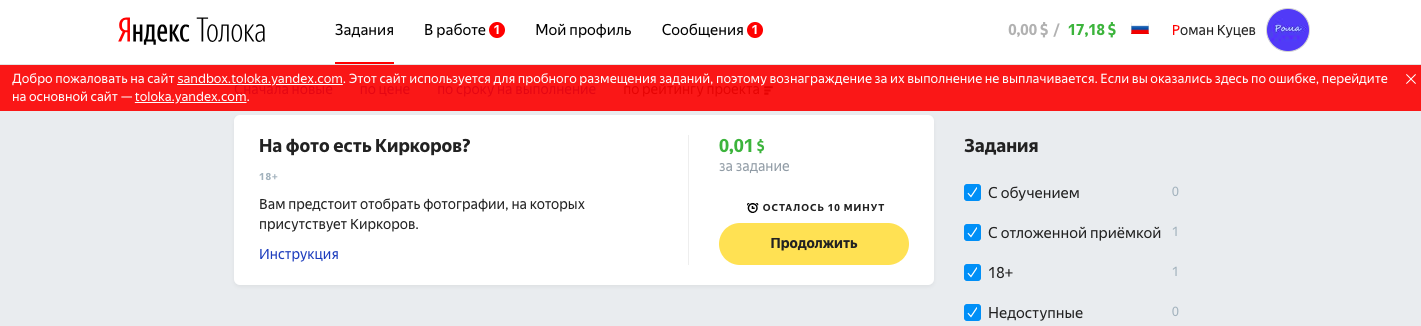
[続行]をクリックします。 パフォーマー向けのページは次のようになります。
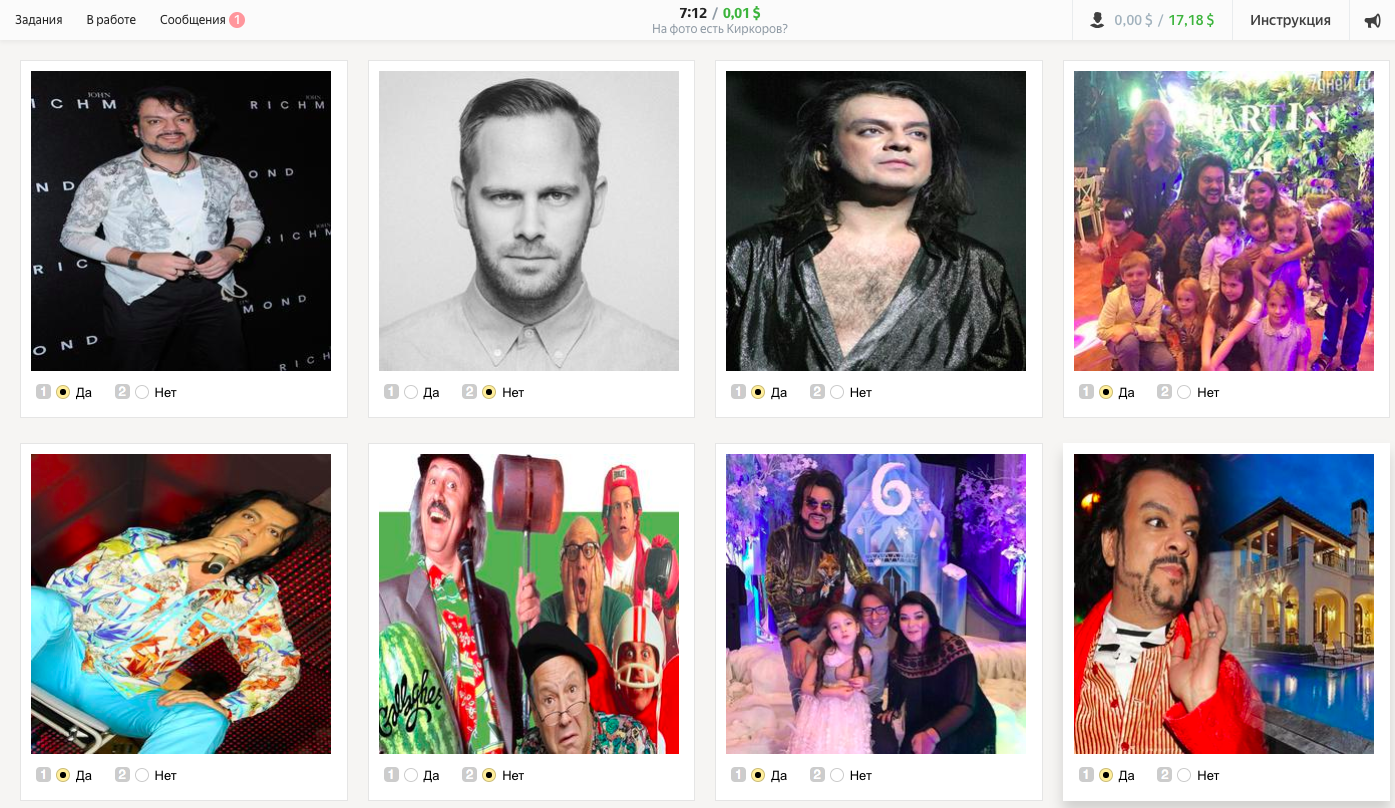
すべてが正しく機能し、バグが発生しないことを確認します。
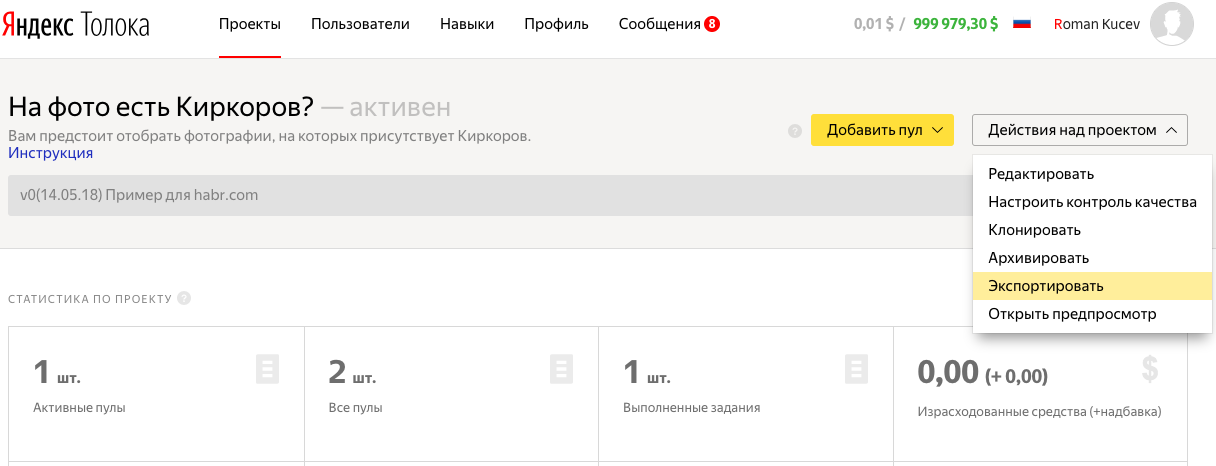
10.結果に満足したら、赤ちゃんを大きな世界に連れて行く、つまり、プロジェクトをサンドボックスからメインの天井に移します。 これを行うには、[プロジェクトのアクション]タブのアーティストのアカウントで[エクスポート]を選択します。
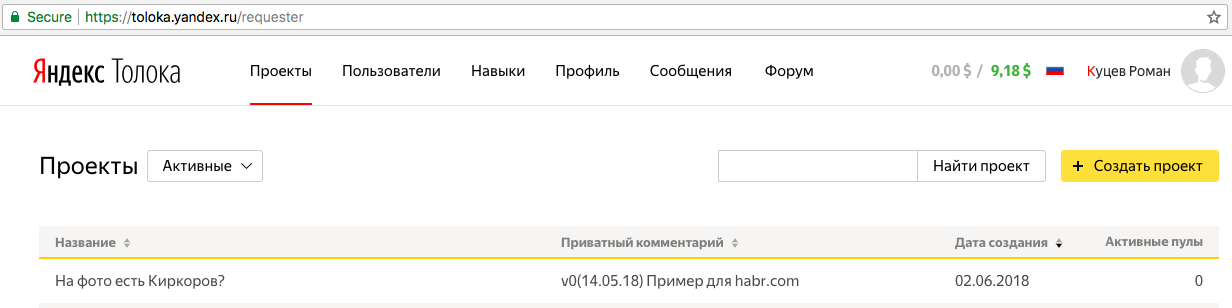
toloka.yandex.ruにアクセスして、プロジェクトが正常にエクスポートされたことを確認します。
それを開き、もう一度すべてが正しいことを確認します。 誤ってタスクを作成してミスを犯し、2000人のエグゼキュータが完了した後、結果を送信できませんでした(私が殺した人数はまだ不明です)。
11.プールを実行し、20分待って結果を取得します。

合計:1159枚の写真がありました。 フリーランサーの1ページに40枚の写真がありました。 つまり 1159/40 = 29セットのタスクがありました。 ただし、オーバーラップは3でした。つまり、合計で29 x 3 = 87ページが表示されました。 1ページに対して、0.01ドル+ 0.005ドルを支払います。 したがって、1,159枚の写真を確認するには、1.3ドルまたは80ルーブルかかりました。 同時に、フリーランサーは0.87ドルまたは50ルーブルのみを受け取り、約97秒x 87タスク= 2時間20分かかりました。 あなたは1時間あたり25ルーブルで働く準備ができていますか?
12.タスクを確認し、結果をダウンロードします。
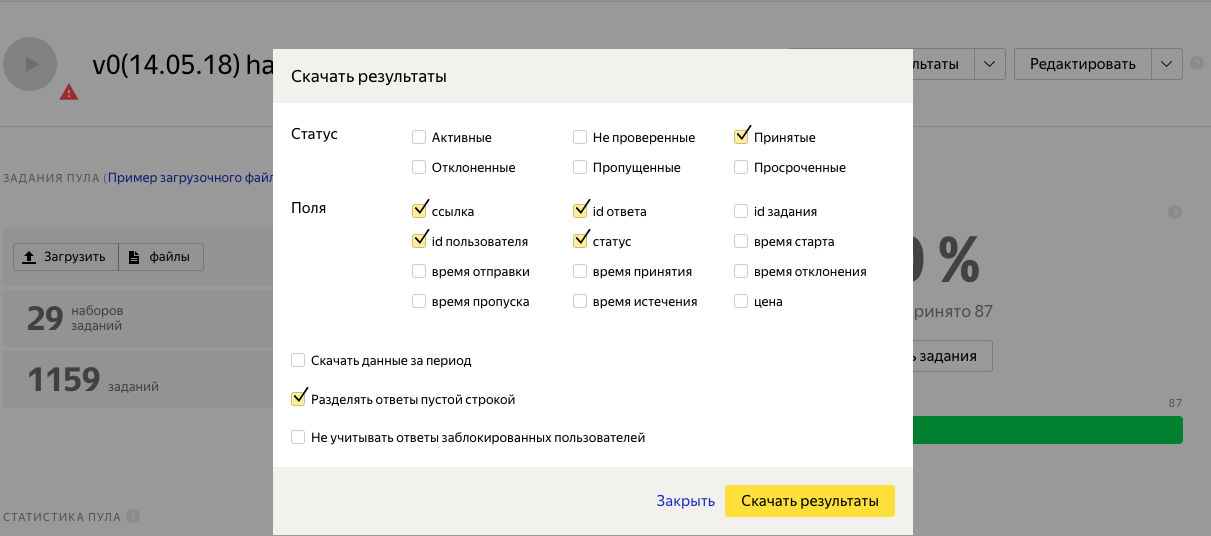
結果のファイルをパンダで開き、「INPUT:image」でグループ化します
import pandas as pd data = pd.read_csv('assignments_v0(14.05.18).tsv',sep = '\t') data['OUTPUT:output'] = data['OUTPUT:output'].map({'NO':0,'YES':1}) data_groupby = data.groupby('INPUT:image').sum()
受け取った:

data_groupby['OUTPUT:output'].value_counts() 3.0 634 0.0 445 2.0 57 1.0 23
投票方法を使用し、写真のKirkorovで、少なくとも2人の出演者が彼に投票した場合、634 + 57 = 691枚の写真を受け取ったことを考慮します。
要約すると、私はそれを言いたい:
- Tolokaは、あらゆるタスクに合わせて調整できる柔軟なツールです。
- Tolokには非常に安い労働力があります。
- Tolokには約10,000人のパフォーマーがいます。これにより、非常に短時間で大量のデータをマークアップできます。
- Tolokaにはパフォーマーを制御するための非常に便利なツールがあり、データセットの高品質なレイアウトを作成できます。
重大な欠点のうち、個人データをTolokにマークすることは不可能です。パフォーマーと署名するNDAがないため、152-152およびGDPRに違反するためです。
データセットの作成のトピックに興味がある場合は、プラスを付けて、次の記事でsticky-aiアプリケーションのデータセットを作成する方法を説明します。