
著者に床を渡します。
最初は、実際にチェックアウトしたくありませんでした。AmazonAWSでディープラーニング用にカスタマイズされたAMIインスタンスをすでに持っていました。 私はよくこれを使用しますが、すべてのPyImageSearchリーダーが自分のプロジェクトで使用できます。

私はAmazon AWSユーザーインターフェイスのファンではありませんが、長年にわたって順応しています。 彼の不器用な複雑さについて何かおなじみがあると思います。 しかし、Ubuntu DSVMに関する非常に良いレビューに出くわしたので、まだ試してみることにしました。 そして、彼女は私の期待をすべて上回りました。 より便利なインターフェース。 素晴らしいパフォーマンス。 リーズナブルな価格。
...さらに、Pythonを使用したコンピュータービジョン向けディープラーニングの書籍のすべてのコードは、変更することなく獲得できました。 マイクロソフトは、機械学習会社のブログに多数のゲスト記事を公開することを親切に許可しました。そこで、仮想マシンを評価し、その使用とテストの印象を共有しました。
- Microsoft Azureクラウドのディープラーニングとコンピュータービジョン 。
- ディープラーニングとAzureテクノロジーのアルゴリズムは、わずか22分でKaggleコンテストの1つで2位になりました 。
- Microsoft Azureクラウドでの高度なニューラルネットワークのトレーニング 。
マイクロソフトは、ディープラーニング、機械学習、データ処理、分析用のクラウドプラットフォームを選択する際に、自社の環境が優先事項となるように積極的に取り組んでいます。 DSVM製品の品質は、このコミットメントを示しています。
この記事では、DSVMに関する私の考えを共有し、マシンの最初のインスタンスを起動し、ディープラーニングのためのコードの実行を開始する方法を示します。 Microsoftのディープラーニング仮想マシンに興味がある場合(および問題を解決するのに適しているかどうかを理解したい場合)、この記事が役立ちます。
Microsoft Deep Learning Virtual Machine:概要
ディープラーニング、データ処理、分析(DSVM)のためにマイクロソフトの仮想マシンに初めて精通したとき、Pythonを使用したコンピュータービジョン向けディープラーニングの書籍からすべてのコードサンプルを取り出し、DSVMでそれぞれ実行しました。 各サンプルの手動開始と結果の確認は単調な作業ですが、DSVMの機能を研究し、次のパラメーターで評価するのに役立ちました。
- 初心者(つまり、ディープラーニングに慣れ始めたばかりの人)が使用できる可能性
- 深層学習モデルを準備し、有効性を迅速に評価することが重要である、実際的な問題を解決する能力。
- 研究の問題を解決する能力、つまり、大量のグラフィックデータでディープニューラルネットワークをトレーニングする能力。
本「Pythonによるコンピュータービジョンのディープラーニング」に付属するコードは、この種のテストに最適です。
Starter Bundleパッケージのコードは、画像分類、ディープラーニング、および畳み込みニューラルネットワーク(SNA)の最初の知人を対象としています。 このコードがDSVMで問題なく実行される場合、ディープラーニングを習得するための既製の環境を必要とする初心者にマシンを推奨できることを意味します。
Practitioner Bundleパッケージのトレーニング資料と添付コードは、はるかに高度なテクノロジー(トレーニングの転送、生成的競合ネットワークの微調整など)に専念しています。 実務家やエンジニアが日常業務で使用するのはこれらの技術です。
DSVMがこれらの例に対処できる場合、ディープラーニングの分野の実践者に推奨できます。 最後に、ImageNet Bundleパッケージのコードには、強力なGPU(より強力で優れたもの)と高スループットのI / O操作が必要です。 このパッケージの一部として、膨大なグラフィックデータセット(たとえば120万枚の画像で構成されるImageNetセット)で取得した最新の出版物(ResNet、SqueezeNetなど)の結果を再現する方法を示します。
DSVMが最新の記事の結果を再現できる場合、研究者に推奨できます。 記事の前半では、説明した各テストの結果と個人的な印象を示します。 次に、マイクロソフトクラウドでディープラーニングシステムの最初のインスタンスを起動し、DSVMで対応するコードの最初のフラグメントを実行する方法を示します。
ディープラーニングライブラリの包括的なセット
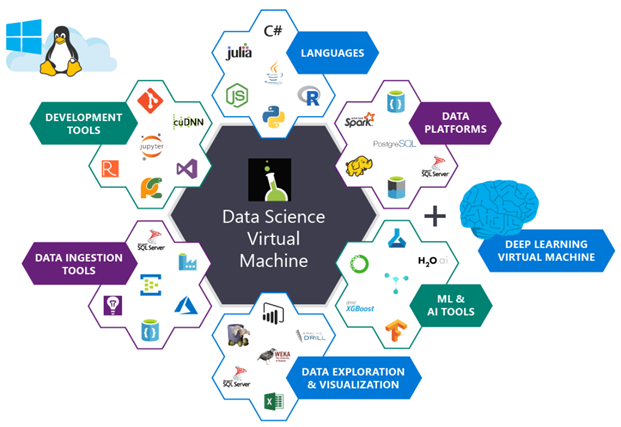
図 1.この図は、データを処理および分析するためにMicrosoft Azure仮想マシンにインストールされているパッケージを示しています。 これらはすでに構成されており、使用する準備ができています。
Microsoftディープラーニング仮想マシンは、企業が所有するAzureクラウドで実行されます。 技術的には、WindowsとLinuxの両方を実行できますが、ディープラーニングプロジェクトには、会社が作成したUbuntu DSVMのインスタンスを使用することをお勧めします(Windowsを使用する理由がない限り)。
DSVMにプリインストールされているパッケージのリストは非常に広範です-完全なリストはこちらから入手できます。 以下に、ディープラーニングとコンピュータービジョンの問題(特に、PyImageSearchの読者が興味を持つ可能性のある問題)を解決するための最も重要なパッケージをリストします。
- テンソルフロー
- ケラス
- mxnet
- Caffe / caffe2
- トーチ/パイトーチ
- Opencv
- ジュピター
- CUDAおよびcuDNN
- Python 3
DSVMの作成者は、数か月ごとに最新バージョンのパッケージが事前にインストールおよびカスタマイズされた新しいバージョンのマシンをリリースします。 これは巨大な作業であり、インスタンスの安定した動作を保証するためのDSVMチームの信じられないほどの努力(DSVMパッケージ間の潜在的な競合を排除するのは難しいタスクですが、マシンはユーザーに対して完全に透過的です)と、それと対話する製品をリリースするマイクロソフトの要望の両方を示していますユーザーにとって便利で快適。
GPUはどうですか?
DSVMを実行するには、CPUのみを備えたインスタンスとGPUを備えたインスタンスの両方を使用できます。
以下に説明するほとんどの実験とテストは、標準のNVIDIA K80 GPUを搭載したUbuntu GPUのインスタンスで実行されました。 さらに、マイクロソフトは最近リリースされたNVIDIA V100モンスターへのアクセスを許可し、その上でいくつかの簡単なテストを実行しました(結果を以下に示します)。 Starter BundleおよびPractitioner Bundleパッケージのすべての実験では、Microsoft Jupyter Notebookを使用しました。 プロセスは非常に簡単でした。
Jupyter NotebookサーバーのURLをブラウザーのアドレスバーにコピーして貼り付け、新しいメモ帳を起動し、数分後に本からコードフラグメントを実行しました。
ImageNet Bundleの実験では、SSHを使用しました。最新の出版物から結果を再現するには、数日間のトレーニングが必要だからです。 さらに、これはJupyterノートブックを使用するのに最適なオプションではないように思えます。
ディープラーニングの初心者向けの便利さ

図 2. MNISTデータセットに関するLeNetアーキテクチャトレーニング。 この組み合わせは、しばしば「Hello World Deep Learning」と呼ばれます
マイクロソフトに関する最初のゲストブログ投稿の一環として、MNIST手書き数字セットで単純な畳み込みニューラルネットワーク(LeNet)をトレーニングしました。 MNISTキットのLeNetトレーニングは、ディープラーニングテクノロジーを習得する初心者向けの最初の「実際の」実験になる可能性があります。
モデルとデータセットの両方が非常に明確に編成されています。 トレーニングには、CPUまたはGPUを使用できます。 Pythonを使用したコンピュータービジョン向けディープラーニングの第14章(スターターバンドル)からサンプルコードを取得し、Microsoft DSVMのJupyterノートブック( こちらから入手可能)で実行しました。 結果を上の図2に示します。
20エポックの研究の後、分類精度は98%でした。 Deep Learning for Computer Vision for Pythonのスターターバンドルパッケージの他のすべてのコードサンプルも問題なく機能しました。 Azure DSVMのJupyter Notebookを使用して、ブラウザーでコードを実行できる機能を追加の構成なしで喜んでいます。 ディープラーニングの分野の初心者にも感謝します。
ディープラーニングの専門家を練習するのに便利
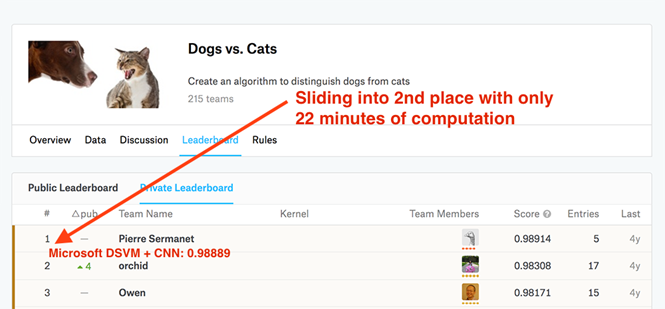
図 3. Microsoft Azure DSVMの事前に構成されたコピーとPythonを使用したコンピュータービジョンのディープラーニングのコードにより、Kaggleリーダーボードの2行目を簡単に解決できました。 猫」(写真の物体認識-猫または犬)
2番目の Microsoftブログ投稿は、実務者向けでした。 高精度モデルを迅速にトレーニングするために、専門家はトレーニング転送(より正確には、そのタイプ、特徴抽出)と呼ばれるアプローチをよく使用します。
モデルを迅速にトレーニングし、さまざまなハイパーパラメーターを評価する必要がある開業医にDSVMがどのように役立つかを示すために、次のことを行いました。
- 以前にKaggleタスク「犬対犬」からのデータセットで訓練されたResNetモデルを使用して特徴抽出を適用しました。 猫。」
; - ロジスティック回帰に基づいた分類器を適用し、グリッド上の抽出されたフィーチャのハイパーパラメーターを検索しました。
- 競争で2位になったモデルを手に入れました。
これらすべてを25分以内に完了するタスクを自分で設定しました。 最終モデルは2位になり、計算にはわずか22分しかかかりませんでした(図3を参照)。 ソリューションの詳細な説明、Jupyter Notepad、およびコードは、 この資料に記載されています。
しかし、この問題をさらに速く解決することは可能ですか? Kaggle実験を完了した後、Dogs vs. 「NVIDIA K80では、Microsoftの担当者が、新しくリリースされたNVIDIA V100 GPUを使用することを許可しました。 私は以前にNVIDIA V100を扱ったことがありませんでしたが、その由来に非常に興味がありました。 結果は素晴らしかった。
NVIDIA K80でのプロセス全体は22分かかり、NVIDIA V100は5分でタスクを完了しました。つまり、4.4倍以上高速です。 動作中のソリューションをK80からV100に移行すると、パフォーマンスが大幅に改善されると確信しています。 しかし、ここには別の要因があります-経済的実現可能性(以下で説明します)。
高度なディープラーニングに十分な能力

図 4. Microsoft Azure DSVMは、ImageNetデータセットでSqueezeNetを簡単にトレーニングします
DSVMは、初心者と経験豊富なディープラーニングプロフェッショナルの両方に最適です。 しかし、業界の最前線で働く研究者はどうでしょうか? DSVMは問題の解決に役立ちますか? この質問に対する答えを見つけるために、私は次のことをしました。
- ImageNetデータセット全体を仮想マシンにダウンロードしました。
- Pythonによるコンピュータービジョンのディープラーニング(ImageNetバンドルパッケージ)の第9章のコードを取り上げ、ImageNetベースのSqueezeNetのトレーニング方法を示します。
SqueezeNetを選んだ理由はいくつかあります。
- ImageNetベースのSqueezeNetは、ローカルコンピューターで1つのプロジェクトのために既にトレーニングされていたため、結果を簡単に比較できました。
- SqueezeNetは、私のお気に入りのアーキテクチャの1つです。
- 小さいため(量子化なしで5 MB未満)、最終モデルは、機能に制限のあるネットワークまたはデバイスが展開によく使用される実稼働環境での使用に適しています。
NVIDIA K80でのSqueezeNetのトレーニングには80時代かかりました。 ネットワークのトレーニングには、SGDを1e-2の初期学習率で使用しました(Landola et al。の出版物の1つでは、4e-2は安定した学習の指標としては大きすぎるという発言があります)。 学習率は、それぞれ50、65、75の時代に一桁減少しました。 各時代はK80で約140分かかったため、合計トレーニング時間は約1週間でした。
複数のGPUを使用すると、プロセッサの数に応じて、トレーニング時間を1〜3日に簡単に短縮できます。
トレーニングが完了した後、50,000枚の画像セットを確認しました(これらはトレーニングセットから取得されたため、ImageNetテストサーバーに結果を送信する必要はありませんでした)。 要約精度指標:ランク1で58.86%、ランク5で79.38%。これらはランドラと共著者によって報告された結果に対応しています。
SqueezeNet + ImageNetバンドルの完全な記事は、Microsoftブログで入手できます。
NVIDIA V100で最高の学習速度
NVIDIA K80を使用してImageNetでSqueezeNetをトレーニングした後、単一のV100 GPUで実験を繰り返しました。 学習速度の向上は驚くべきものでした。 K80では、1つの時代に約140分かかりました。 V100の時代は28分で完了しました。つまり、5倍以上高速です。
わずか36時間でSqueezeNetをトレーニングし、前の実験の結果を再現することができました。 DSVMは、特にハードウェアを購入して保守したくない場合、研究者にとって非常に魅力的なツールのようです。
しかし、価格はどうですか?
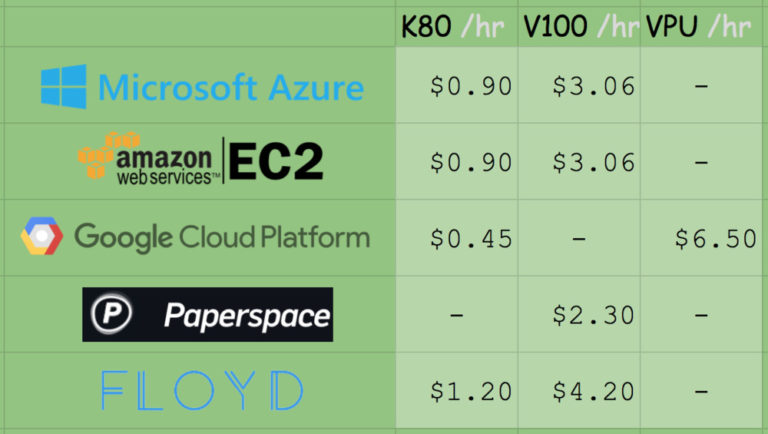
図 5.さまざまなディープラーニングサービスプロバイダーとGPUリソース間のGPUコンピューティングの電力価格の比較
Amazon EC2上のp2.xlargeインスタンスのコストは、1時間あたり0.90ドル(K80倍)、7.20(K80倍)、または14.40ドル(K80倍)です。 したがって、K80のコピーを1つ使用するコストは0.90ドル/時間です。 Microsoft Azureでは、価格はまったく同じです:1時間あたり0.90(1x K80)、1.80(2x K80)、$ 3.60(4x K80)。 1台のK80デバイスを使用する総費用も0.90ドル/時間です。
Amazonは、V100ですぐに使用できるマシンを提供しています。 それらのコストは、3.06(1x V100)、12.24(4x V100)および24.48(8x V100)USドル/時間です。 したがって、Amazon EC2でV100を取得する場合は、3.06ドル/時間を支払う準備をしてください。
最近Azureに登場したV100のコピーのコストは、3.06(1x V100)、6.12(2x V100)および12.24(4x V100)USドル/時間と非常に競争力があり、1つのV100の合計コストも3です。 $ 06 /時間
Microsoftは、Azure Batch AIパッケージをリリースしました 。これは、Amazonスポットインスタンスに似ており、インスタンスのより良い価格設定を利用できます。
完全かつ公正な価格比較のために、Google、Paperspace、Floydhubの提供も検討する必要があります。
Googleの価格は、提案されたコピーを使用して1時間あたり0.45ドル(K80倍)、0.90ドル(K80倍)、1.80ドル(K80倍)、3.60ドル(K80倍)です。 MS / EC2のK80の半分の価格で、間違いなく最高の価格です。 GoogleのV100を搭載した車の提供に関する情報はありません。 しかし、彼らは独自の開発TPUを実装しています。その使用コストは、TPUあたり1時間あたり6.50ドルです。
ペーパースペースの運賃は2.30ドル/時間(1x V100)です。 APIのエンドポイントも提供していることは注目に値します。
Floydhubは1時間あたり4.20ドル(1x V100)を請求しますが、優れたコラボレーションソリューションを提供します。
信頼性の面では、EC2とAzureの製品はそれ自体が十分に証明されています。 そして、AzureでのEC2と比較して快適な作業を考えると、Amazonが長期使用に適していると明確に言うことはできません。
ビジネスでAzureの機能を評価する場合、Microsoftは試用用の無料のリソースを提供しています。 ただし、このボーナスを使用してGPUを搭載したマシンを起動することはできません(残念ながら、GPUを搭載したインスタンスは「プレミアム」に分類されます)。
Microsoftクラウドでディープラーニングの最初のインスタンスを起動する
DSVMインスタンスの実行は非常に簡単です。 このセクションでは、その方法を説明します。
詳細設定が必要な場合は、 ドキュメントを参照してください-主にデフォルト設定を使用します。 Azureクラウドのパワーを無料で体験するには、無料のMicrosoft Azureトライアルアカウントにサインアップできます。
ご注意 Microsoft試用版サブスクリプションの一部としてGPUを使用してインスタンスを作成することはできません。 残念ながら、GPUを備えたインスタンスはプレミアムとして分類されます。
手順1. portal.azure.comでユーザーアカウントを作成するか、ログインします。
ステップ2.左上の「リソースの作成」ボタンをクリックします。
図 6. Microsoft Azureのリソース作成画面
ステップ3.検索フィールドに、「Linux用のData Science Virtual Machine」と入力します。 必要なオプションがリストに表示されます。 「Ubuntu」という単語のある最初の行を選択します。
ステップ4.基本設定を構成します。 名前を入力します(スペースや特殊文字は使用しません)。 HDDオプション(SSDではありません)を選択します。 キーファイルを設定する代わりに、単純なパスワードを入力しましたが、選択はあなた次第です。 「サブスクリプション」セクションをご覧ください。アカウントで無料で資金を提供できます。 また、リソースグループを作成する必要があります。 既存のrg1を選択しました。
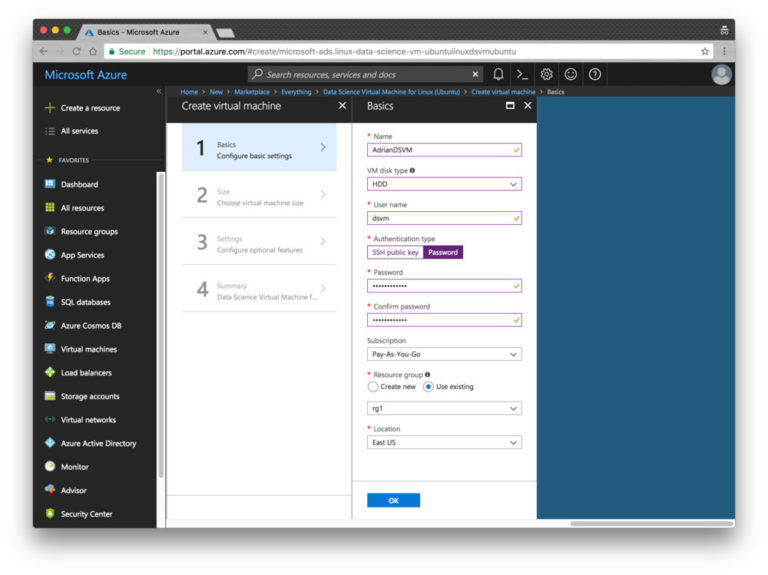
図 7.リソースMicrosoft Azureの主なパラメーター
ステップ5.リージョンと仮想マシンを選択します。 K80(NC65_V3)で使用可能なインスタンスを選択しました。 V100のインスタンスはリストの下位(NC6S_V3)です。 この命名システムは私には明らかではないことに注意する必要があります。 これは、プラットフォームを使用することの否定的な印象の1つです。 ここでの命名システムがスポーツカーの命名システムとほぼ同じになることを望んでいました。 極端な場合、2つのK80 GPUを搭載した車は「K80-2」と呼ばれます。 ただし、ここでの名前は仮想CPUの数によって決まりますが、GPUに興味があります。

図 8. Microsoft Azure DSVM仮想マシンは、K80 GPUおよびV100 GPUに基づいて動作します
手順6. [概要]ページを調べて、契約条件への同意を確認します。

図 9. [概要]ページで、契約の条件をよく理解し、契約条件を確認できます
手順7.システムの展開が完了するまで待ちます。 プロセスが終了すると、通知を受け取ります。
ステップ8. [すべてのリソース]を選択します。 このリストは、あなたが支払うすべてのものをリストします。
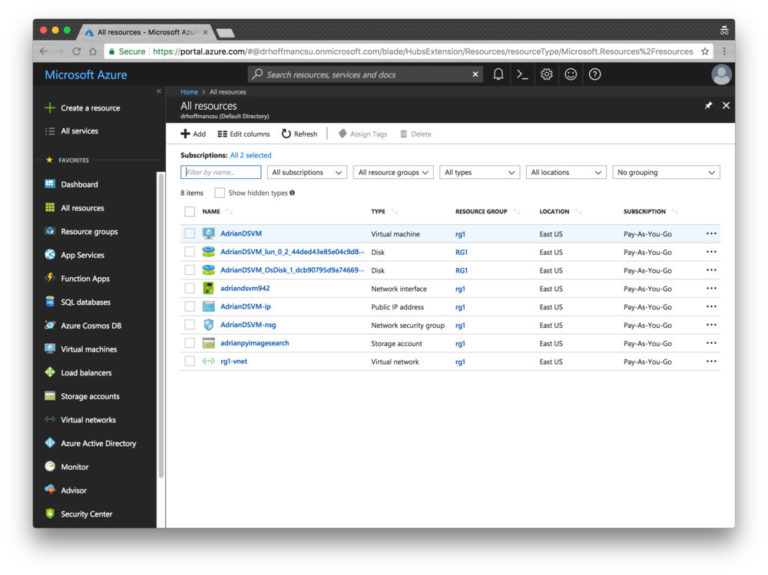
図 10. Azureポータルの[すべてのリソース]ページにDSVMマシンと関連サービスが表示されます
仮想マシンを選択すると、それに関する情報がウィンドウに表示されます(新しいタブで下のスクリーンショットを開き、高解像度で調査します-IPアドレスなどが表示されます)。

図 11. [リソースの概要]ページで、インスタンスを表示できます。
ステップ9. SSHまたはJupyterを介してマシンに接続します。
[接続]ボタンをクリックすると、SSH接続のセットアップに関する情報(キーファイルまたはパスワードを使用)が画面に表示されます。 残念ながら、ここにはJupyterへの便利なリンクはありません。 Jupyterに接続するには、次の手順を実行します。
- ブラウザで新しいタブを開きます。
- アドレス「https:// your_Azure_Dsvmのpublic_IP_:8000_インスタンス」に移動します(つまり、httpではなくhttps)。 URLの適切な部分をインスタンスのパブリックIPに置き換えます。
ディープラーニングのための仮想マシンコードの実行
次に、LeNet + MNISTの例を実行します。これは、Jupyterでの最初の Microsoftブログ投稿で説明されています。 このプロセスは2つのステップで構成されます。
手順1. SSH経由でマシンに接続します(前のセクションの手順9を参照)。
〜/ notebooksディレクトリに移動します。
コマンド$ git clone github.com/jrosebr1/microsoft-dsvm.gitでリポジトリを複製します
ステップ2.ブラウザーでJupyterページを開きます(前のセクションのステップ9を参照)。
microsoft-dsvmディレクトリをクリックします。
目的の.ipynbファイル(pyimagesearch-training-your-first-cnn.ipynb)を開きます。
まだノートブックを起動しないでください。まず、便利なトリックについて説明します。 使用する必要はありませんが、DSVMで複数のノートブックを使用している場合は、作業が少し楽になります。 実際、メモ帳を実行して「実行中」状態のままにすると、メモ帳のコアがGPUをブロックします。 別のノートブックを起動しようとすると、「リソースが使い果たされました」などのエラーが表示されます。
これを回避するには、ノートブックの最後の別のセルに次の2行を追加します。
%%javascript Jupyter.notebook.session.delete();
これで、すべてのセルが処理された後、ノートブックはカーネルを静かにシャットダウンし、手動で停止することを心配する必要がなくなります。
これで、最初のセル内をクリックして、メニュー項目「セル>すべて実行」を選択できます。 したがって、すべてのノートブックセルの実行を開始し、MNISTに基づいてLeNetトレーニングを開始します。 これで、ブラウザの進行状況を追跡し、私のような結果を得ることができます。
図 12. Microsoft Azureクラウドのデータ処理および分析(DSVM)のための仮想マシンでのMNISTベースのLeNetトレーニング
通常、シャットダウンした後、または変更したメモ帳を再起動する前に、出力の内容全体を削除します。 これを行うには、メニュー項目「Kernel> Restart&Clear Output」を選択します。
おわりに
この出版物では、マイクロソフトの仮想マシンを使用してディープラーニング、処理、およびデータ分析(DSVM)を行う個人的な経験について話しました。 また、最初のDSVMインスタンスを起動し、そのインスタンスで最初の深層学習コードを実行する方法も示しました。 最初は、DSVMについて疑問がありましたが、このマシンを使用してみて良かったです。
DSVMは、初心者向けのトレーニングタスクから最先端の実験まで、すべてのテストに簡単に対応できます。 インスタンスをNVIDIA K80からMicrosoftの新しいNVIDIA V100 GPUに切り替えた後、実験の速度は5倍に増加しました。
ディープラーニング用のGPUを備えたクラウドベースのインスタンスを探している場合、MicrosoftのDSVMに注意することをお勧めします-私の印象は最も肯定的であり、Microsoftのサポートはうまく機能し、DSVM自体は強力で使いやすいものでした。