
物語
80年代にジョンホップフィールドによって再帰レイヤーが発明されました。 彼らは彼が開発した人工連想ニューラルネットワーク(ホップフィールドネットワーク)の基礎を形成しました。 現在、リカレントネットワークは、自然言語、音声、音楽、映像などのシーケンス処理タスクで広く使用されています。
挑戦する
階層強化学習タスクの一部として、1つのエージェントアクションではなく、アクションのシーケンスを予測できるトレーニング済みのネットワークを使用して、複数のエージェントアクションを予測することにしました。 この記事では、このネットワークをトレーニングするための「シーケンスツーシーケンス」アルゴリズムの実装方法を示し、次に、Qラーニングトレーニングでの使用方法を説明します。
環境
小さな2Dゲームの世界、5x5セルを想像してください。 各セルは、オブジェクトまたは空のスペースを占有します。

ネットワークの前に、タスクを設定します。特定のアクションセットからアクションのシーケンスを発行する[「左」、「右」、「アップ」、「ダウン」、「テイク」、「攻撃」]。
25個の個別のセルで構成される世界の入力状態。各セルは、セットから1つの値を取ることができます:["space"、 "enemy"、 "life"、 "source point"、 "destination point"]。

このような世界を、次元が6 * 25のベクトルの形式で表示してから、埋め込みアルゴリズムを圧縮できます。 このようなモデルは、この世界のセルとオブジェクトの数の変化に非常に敏感です。
このような制限を取り除くために、入力レイヤーをシーケンスとして形成できます。このシーケンスの各要素は、世界の1つのオブジェクトです。 したがって、さまざまな長さのシーケンス(シミュレートされた世界のさまざまなサイズ)をフィードし、事前トレーニングの過程で、世界のオブジェクトの数を増やすことができます。
シーケンスからシーケンス
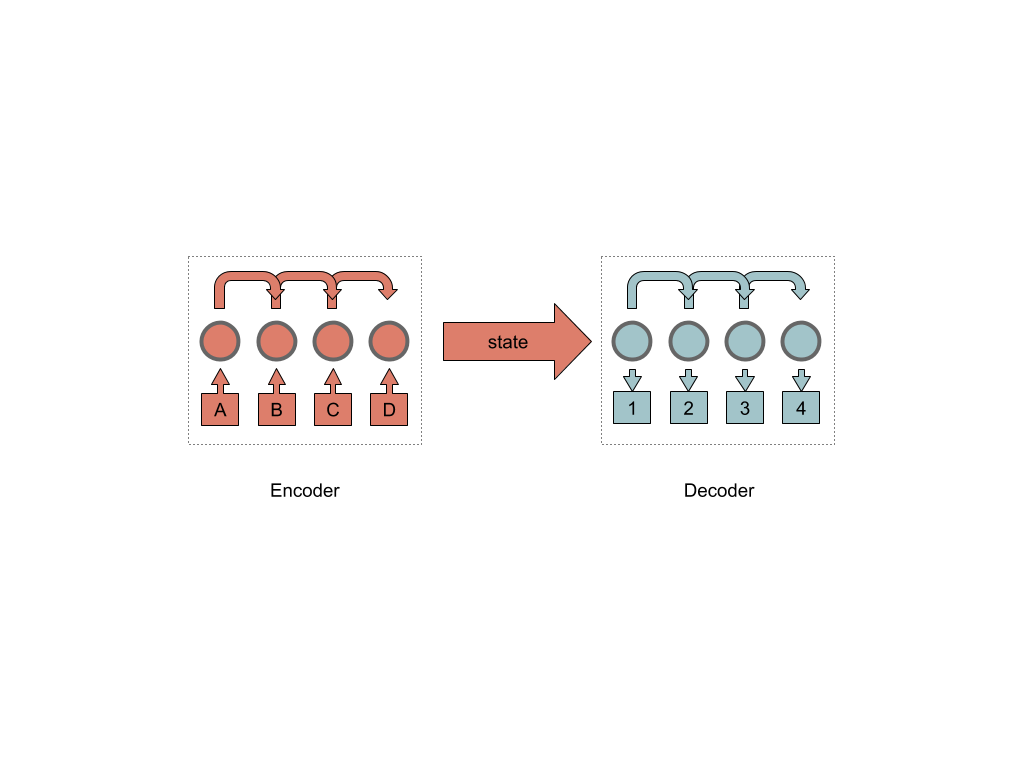
シーケンスからシーケンスへのニューラルネットワークは、2つのエンコーダーブロックとデコーダーブロックであり、それらを接続する内部状態の特定の隠れ層です。
次に、エンコーダは一連の繰り返しセルで構成されます(実装では、1つまたは複数の場合があります)。
今日の最も一般的なリカレントセル(私の主観的な意見では)は、LSTM(Long short term memory)セルです。
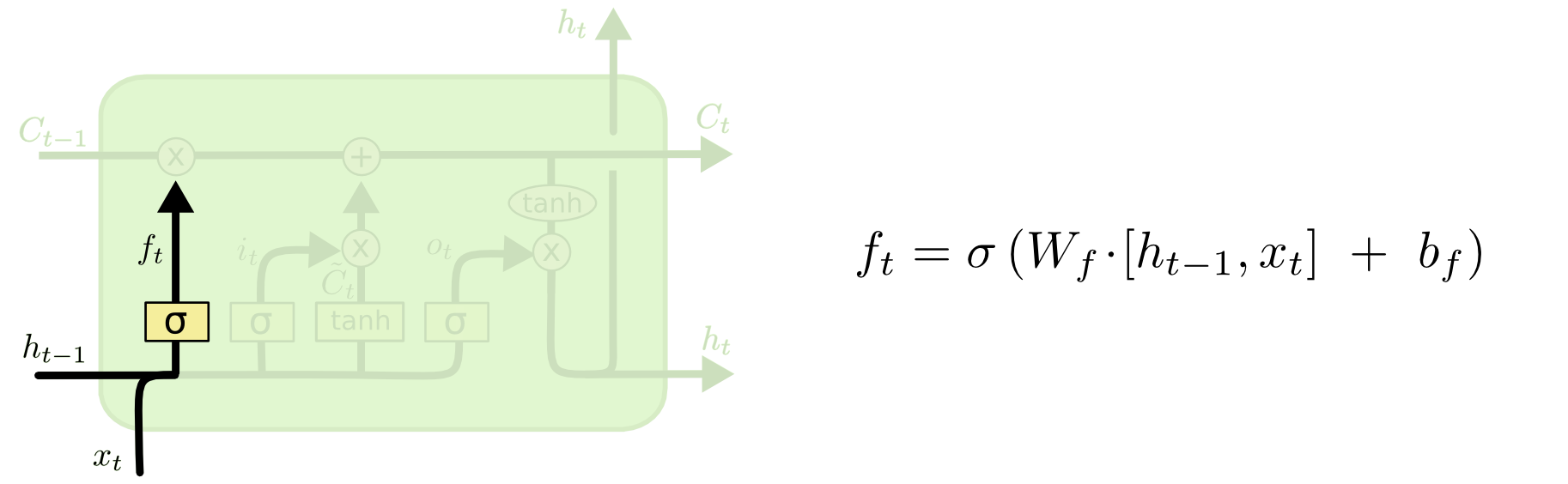
LSTMの実装を詳しく調べることなく( ここで詳細を読むことをお勧めします )、その動作原理について簡単に説明します。
LSTMセルの入力には、3つの入力C、H、Xがあります。セル内の信号の線形修正が可能な「コンベヤ」Cの入力。 最初の変更は「ゲート」です。
入力HとXからの信号を処理するとき、「ゲート」は、現在コンベヤCに到着した信号を渡すかどうかを決定します。これは、信号CにパラメータH、X、W、bをもつシグモイド関数の値を掛けることによって起こります。
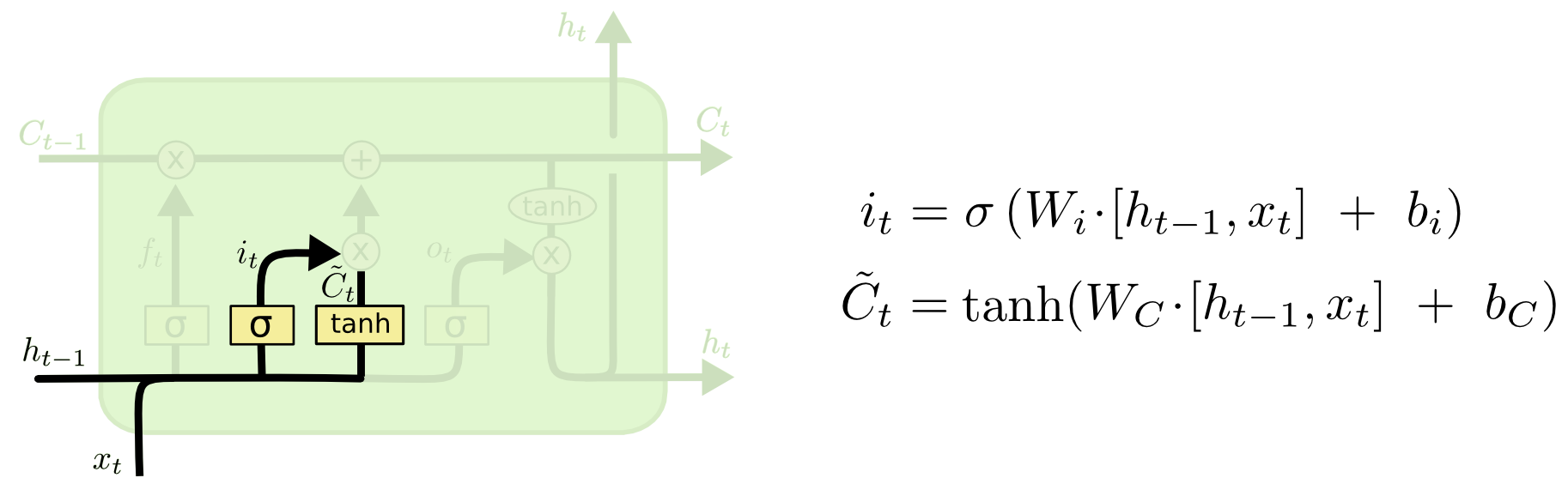
次のステップは、セル状態に保存する新しい情報を決定することです。 この決定は2段階で行われます。
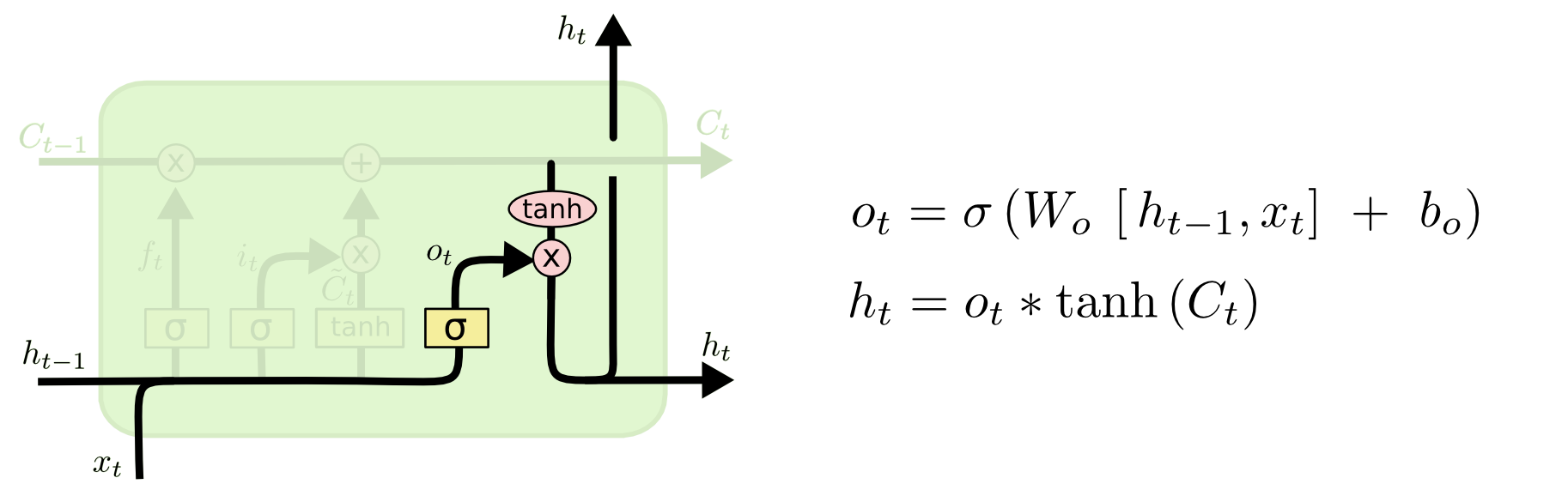
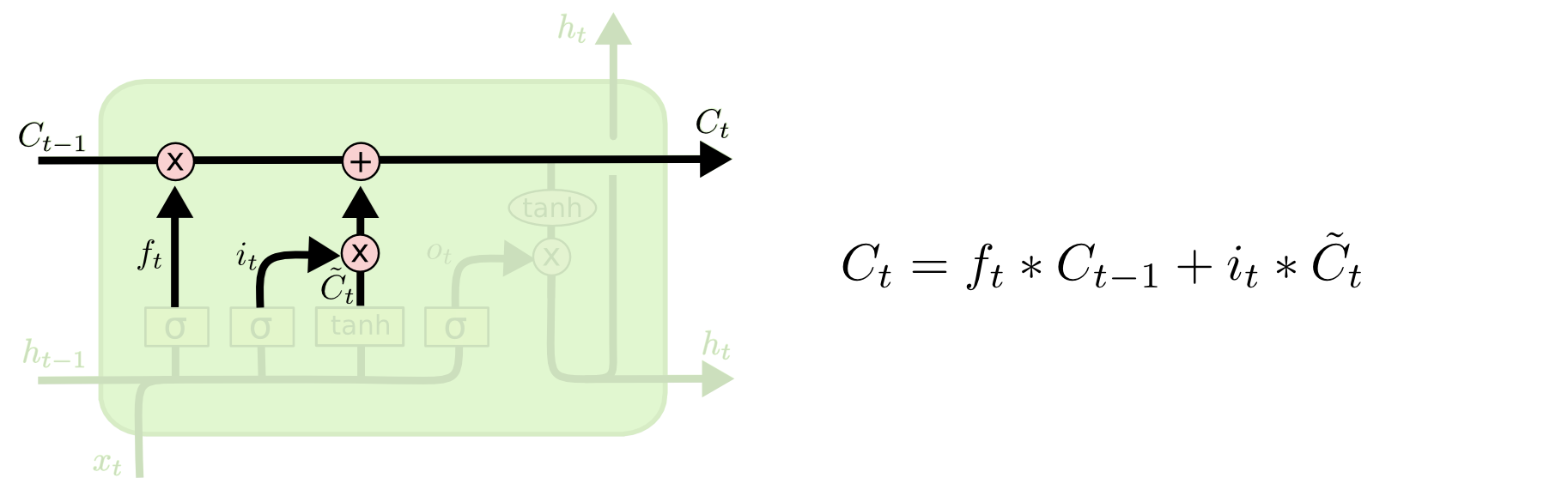
まず、「入力ゲート層」と呼ばれる2番目のシグモイド層が、更新する値を決定します。 次に、tanhレイヤーは、状態に追加できる出力レイヤーCの新しい候補値のベクトルを作成します。 次のステップで、セルは「パイプライン」Cを通る信号と受信した信号を組み合わせて、更新された状態を作成します。 最後に、セルのH出力に何を表示するかを決定する必要があります。 この結論はセルの状態に基づいていますが、これはフィルターを通過します。 最初に、セルはシグモイド層を介して信号を渡します。シグモイド層は、セル状態のどの部分を出力するかを決定します。 次に、tanh関数を通過する「パイプライン」Cの値を乗算します。
また、HabréのLSTMについて読むこともできます 。
したがって、「チェーン」内のいくつかのLSTMセルを収集すると、チェーン内の以前の予測に基づいて特定の状態を予測できます。
このようなネットワークの収束を改善するのに役立つ多くの技術、たとえば双方向セル技術があります。 1つの行が前のセルの状態を監視し、もう1つの行がそれに続くセルの状態を追跡するようにセルを2行に配置することにより、予測される前の単語だけでなく、その後の単語も考慮することができます。 また、「強調」または注意を使用して、文のキーワードを識別します。
実装
TensorFlowとpythonを使用してニューラルネットワークを「収集」します。 また、この記事では、世界をシミュレートするための小さなクラスを作成しました。
最初に行うことは、入力レイヤーを決定することです。
self.input_data_input = tf.placeholder(tf.int32, [None, None], name='input') self.targets = tf.placeholder(tf.int32, [None, None], name='targets') self.learning_rate_input = tf.placeholder(tf.float32, name='learning_rate') self.target_sequences_length_input = tf.placeholder(tf.int32, (None,), name='target_sequences_length') self.max_target_sequences_length = tf.reduce_max(self.target_sequences_length_input, name='max_target_len') self.source_sequences_length_input = tf.placeholder(tf.int32, (None,), name='source_sequences_length')
次に、エンコーダーレイヤーを作成します。
ここで、 埋め込みのメカニズムを使用して次元を削減し、その実装のメカニズムがTensorFlowに既に存在することをここで言う価値があります。
# 1. Encoder embedding encoder_embed_input = tf.contrib.layers.embed_sequence(input_data_input, vocabulary_size, TF_FLAGS.FLAGS.encoding_embedding_size) # 2. Construct the encoder layer encoder_cell = tf.contrib.rnn.MultiRNNCell([self.make_cell() for _ in range(TF_FLAGS.FLAGS.num_layers)]) enc_output, enc_state = tf.nn.dynamic_rnn(encoder_cell, encoder_embed_input, sequence_length=source_sequences_length_input, dtype=tf.float32)
rnnセルを作成し、ネットワークに追加します。
dec_cell = tf.contrib.rnn.LSTMCell(TF_FLAGS.FLAGS.rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
TFSummit 2017のビデオをさらに詳しく見ることができます 。
サブネットの出力は、最後のRNNセルの出力(パイプライン)とその非表示状態で構成されます。 状態だけが必要です。
デコーダーに移動します。
デコーダの場合と同様に、埋め込み層を準備する必要があります。
# 1. Decoder Embedding target_vocab_size = self.vocabulary_size decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, TF_FLAGS.FLAGS.decoding_embedding_size])) decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
次に、リカレントセルを含む最初のレイヤーを作成し、結果をさらに分類するために、完全に接続されたパーセプトロンに出力を投影します。
# 2. Construct the decoder layer dec_cell = tf.contrib.rnn.MultiRNNCell([self.make_cell() for _ in range(TF_FLAGS.FLAGS.num_layers)]) # 3. Dense layer to translate the decoder's output at each time # step into a choice from the target vocabulary output_layer = Dense(target_vocab_size, kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1))
セル出力は、完全に接続された分類レイヤーに送られます。
デコーダーには、2つのGraffブランチがあります。
トレーニング用の最初のブランチ、最終タスクの処理用のもう1つのブランチ。
トレーニングのために、ターゲット(デコーダーの出力で取得したい)シーケンスから最後の文字を削除し、各ターゲットシーケンスの先頭に「GO」を追加する必要があります。 これは、各セルを個別にトレーニングするために必要です。各セルには、隣接する学習セルからの信号ではなく、正しい入力信号を供給する必要があります。
TensorFlowデコーダレイヤーを実装するには、アシスタントが必要です。 実際、これは入力データを前処理する一種の反復子です。
トレーニング用のアシスタントと動的デコーダーを作成します。
# Helper for the training process. Used by BasicDecoder to read inputs. training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_embed_input, sequence_length=target_sequences_length, time_major=False) # Basic decoder training_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, training_helper, encoder_state, output_layer) # Perform dynamic decoding using the decoder training_decoder_output = tf.contrib.seq2seq.dynamic_decode(training_decoder, impute_finished=True, maximum_iterations=max_target_sequences_length)[0]
最終タスクを処理するためのアシスタントと動的デコーダーを作成します。
start_tokens = tf.tile(tf.constant([ua.UrbanArea.vacab_go_key], dtype=tf.int32), [TF_FLAGS.FLAGS.batch_size], name='start_tokens') # Helper for the inference process. inference_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embeddings, start_tokens, ua.UrbanArea.vacab_eos_key) # Basic decoder inference_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, inference_helper, encoder_state, output_layer) inference_decoder_output = tf.contrib.seq2seq.dynamic_decode(inference_decoder, impute_finished=True, maximum_iterations=max_target_sequences_length)[0]
次に、損失関数を追加します。
シーケンスの場合、TensorFlowにはクロスエントロピーの機能があり、これにrnnネットワークの出力とトレーニングの例を入力に提供します。
training_logits = tf.identity(training_decoder_output.rnn_output, 'logits') _ = tf.identity(inference_decoder_output.sample_id, name='predictions') # Create the weights for sequence_loss masks = tf.sequence_mask(self.target_sequences_length_input, self.max_target_sequences_length, dtype=tf.float32, name='masks') with tf.name_scope("optimization"): # Loss function self.cost = tf.contrib.seq2seq.sequence_loss(training_logits, self.targets, masks) tf.summary.scalar("loss", self.cost)
勾配降下とアダムオプティマイザーは重みを更新します。
# Optimizer optimizer = tf.train.AdamOptimizer(self.learning_rate_input) # Gradient Clipping gradients = optimizer.compute_gradients(self.cost) capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None] self.train_op = optimizer.apply_gradients(capped_gradients)
それだけです。シミュレータから数百のトレーニングデータを取得して、トレーニングセッションを開始してください。
Epoch 1/100 Batch 20/65 Loss: 1.170 Validation loss: 1.082 Time: 0.0039s
Epoch 1/100 Batch 40/65 Loss: 0.868 Validation loss: 0.950 Time: 0.0029s
Epoch 1/100 Batch 60/65 Loss: 0.939 Validation loss: 0.794 Time: 0.0031s
...
Epoch 99/100 Batch 60/65 Loss: 0.136 Validation loss: 0.403 Time: 0.0030s
Epoch 100/100 Batch 20/65 Loss: 0.149 Validation loss: 0.430 Time: 0.0037s
Epoch 100/100 Batch 40/65 Loss: 0.110 Validation loss: 0.423 Time: 0.0031s
Epoch 100/100 Batch 60/65 Loss: 0.153 Validation loss: 0.397 Time: 0.0031s
その結果、仮想迷路を通過する一連のステップを取得できます。
アルゴリズムによって計算されたシーケンスは黄色で強調表示され、人工ニューラルネットワークによって提案されたシーケンスは緑色で強調表示されます。

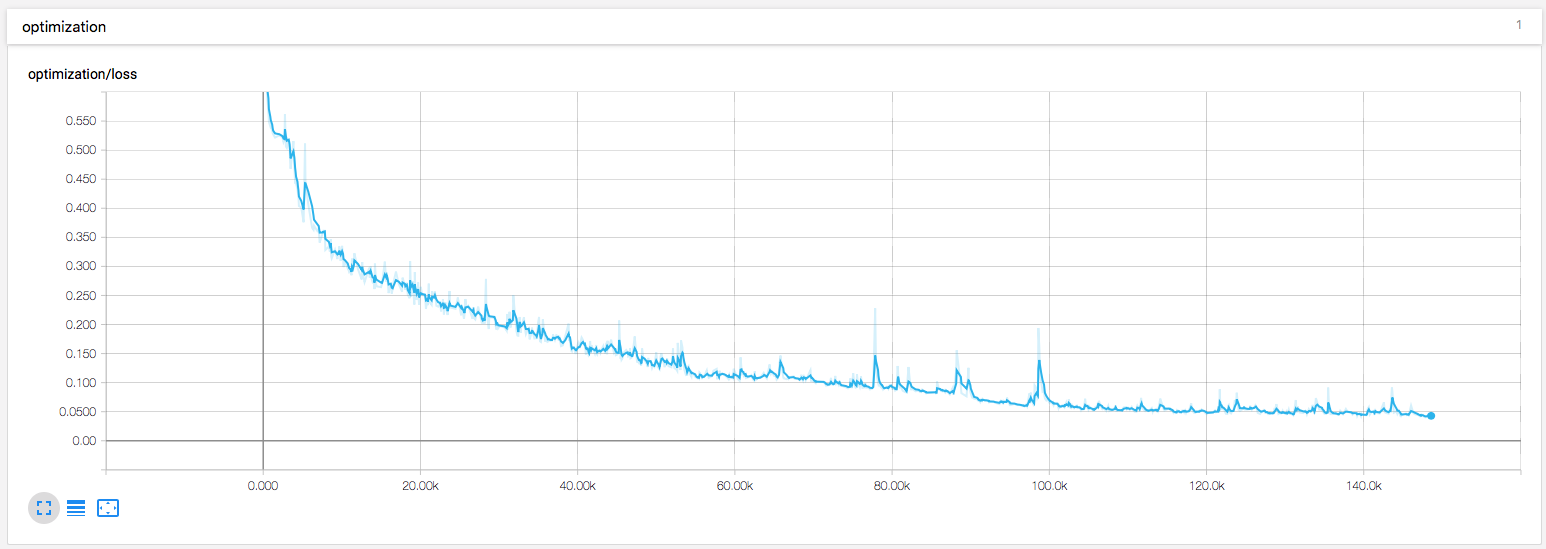
また、トレーニングに少し視覚化を追加しました。
完成したソリューションは、私のgithubリポジトリにあります。