こんにちは、Habr! 私の名前はウラジミールです。私はKubSTUの4年生です(残念ながら)。
少し前に、ヘルメットのない作業員を検出するためのCVシステムの開発に関する記事に出会い、2017年の夏に産業会社でのインターンシップで得たこの分野での自分の経験を共有することにしました。 人とヘルメットを検出するタスクのコンテキストでのOpenCVとTensorFlowの理論と実践はすぐに理解できます。

与えられた:雇用主の産業施設のCCTVカメラへのアクセス、2-4人の研修生(開発中、プロジェクトに関与する人々の数は変化しました)。
目的:ヘルメットのない従業員をリアルタイムで検出するプロトタイプシステムを開発する。 技術の選択はあなた次第です。 私たちの選択は、最初のプロトタイプを最小限の労力で実装できる言語として、そして最初はOpenCVとして最もよく耳にするマシンビジョンライブラリとして、Pythonに選ばれました。
OpenCVは、カスケード分類器などの主に古典的なマシンビジョンメソッドを実装するライブラリです。 このアプローチの本質は、いわゆる 弱い分類器のアンサンブル、すなわち 肯定応答の総数に対するオブジェクトによって正しく分類されたオブジェクトの比率が、少なくとも0.5をわずかに上回るようになりました。 このような分類子の1つでは結果を得ることができませんが、数千のそのような分類子を結合すると非常に正確な結果が得られます。

弱い分類器のアンサンブルがかなり正確な分類を実行する方法の例。 出所
明らかに、ヘルメットのない人を見つけるタスクは、そのような人と...ヘルメットを見つけるタスクに帰着します! またはその不在。 ビデオカメラにアクセスすることで、ヘルメットの有無にかかわらず、ヘルメットと人自身のトリミングされた写真から最初のデータセットをすばやく組み立てることができました(非常に迅速に見つかりました)。将来的には、そのボリュームを2k以上の写真にすることができます。

トレーニング用の画像マークアップ
この段階で、OpenCVの最初の不快な機能が見つかりました- 公式 ドキュメントは散在しており、ライブラリの主要な開発者の1人の本を参照することもありました。 多くのパラメーターでは、値を実験的に選択する必要がありました。
 ヘルメットで訓練された分類器の最初の起動は、誤検出の孤立したケースで約60%の精度でそれらを検出しました! 私たちは正しい軌道に乗っていると感じました。 人を検出するタスクははるかに困難であることが判明しました。ヘルメットとは異なり、人はフレームに多数の角度から現れ、一般的に分類器からはるかに高度な一般化能力を求められました。 私はヘルメットの訓練を受けた分類器の改良に取り組んでいる間、代替案として、Canny輪郭の抽出と移動物体のカウントのアルゴリズムに基づいて、物体のCVクラシック検出をテストしました。
ヘルメットで訓練された分類器の最初の起動は、誤検出の孤立したケースで約60%の精度でそれらを検出しました! 私たちは正しい軌道に乗っていると感じました。 人を検出するタスクははるかに困難であることが判明しました。ヘルメットとは異なり、人はフレームに多数の角度から現れ、一般的に分類器からはるかに高度な一般化能力を求められました。 私はヘルメットの訓練を受けた分類器の改良に取り組んでいる間、代替案として、Canny輪郭の抽出と移動物体のカウントのアルゴリズムに基づいて、物体のCVクラシック検出をテストしました。
並行して、分類器から受け取ったデータを処理するためのサブシステムを開発しました。 作業のロジックは単純です:フレームを監視カメラから取得して分類器に送信し、フレーム内の認識された人とヘルメットの数が一致するかどうかを確認し、ヘルメットのない人が見つかった場合、認識されたオブジェクトの数に関する情報をデータベースに記録し、フレームを保存します手動分析。 このソリューションにはもう1つプラスがありました-分類エラーのために保存されたフレームにより、対処できないデータで再トレーニングすることが可能になりました。
そして、ここで新たな問題が発生しました:ヘルメットのない人ではなく、認識エラーのために大部分のフレームが保存されました。 新鮮なデータで学習すると認識結果がわずかに改善されましたが、ヘルメットはケースの約75%(単一の誤検出)で認識され、フレーム内の重複する数字はケースの半分以上でしか正しくカウントされませんでした。 プロジェクトマネージャーに、ニューラルネットワーク検出器を開発するための1週間を与えるよう説得しました。
NSでの作業を便利にする機能の1つ-少なくとも分類子と比較して-エンドツーエンドのアプローチ:マークされたヘルメット/人に加えて、分類子のトレーニングには特別な形式に変換する必要がある背景画像と分類子を検証する画像が必要です、変換プロセスは、分類子自体のパラメーターは言うまでもなく、多くの異なる重要なパラメーターによって制御されます! 動いているオブジェクトなどをカウントするアルゴリズムを使用する場合、プロセスはさらに複雑になり、フィルターは画像に事前に適用され、背景は削除されます。 エンドツーエンドの学習では、開発者がデータセットとトレーニング中のモデルのパラメーターに「ジャスト」タグを付ける必要があります。
TensorFlow MLフレームワークとtensorflow / modelsリポジトリは、その時に最近登場し、私の要件を満たしていました-十分に文書化されており、作業プロトタイプをすぐに書くことができました( 最も人気のあるアーキテクチャはほとんどすぐに動作します )プロトタイプが成功した場合、機能はさらなる開発に完全に適していました。 101層のreznetを使用して既存のチュートリアルを既存のデータセットに適合させた後(畳み込みニューラルネットワークの原理はHabréで繰り返し説明されていますが、COCOデータセット(以下を含む)の記事のみ参照できます[1] 、 [2] )人々の写真)、私はすぐに90%以上の精度を受け取りました! これは、SNAヘルメット検出器の開発を開始する説得力のある議論でした。

サードパーティのデータセットでトレーニングされたSNSは、近くに立っている人を簡単に認識しますが、認識されることが予期されていなかったミスを犯します:)
モデルのトレーニング中に、TensorFlowは、さまざまな段階でNSをコンパイルおよびテストできるチェックポイントファイルを生成できます。これは、再トレーニング中に問題が発生した場合に役立ちます。 コンパイルされたモデルは有向計算グラフであり、その最初の頂点は入力データ(画像の場合、各ピクセルの色値)であり、最後の頂点は認識結果です。
モデル自体に関するデータに加えて、チェックポイントには学習プロセス自体に関するメタデータを含めることができ、これはTensorboardを使用して視覚化できます。
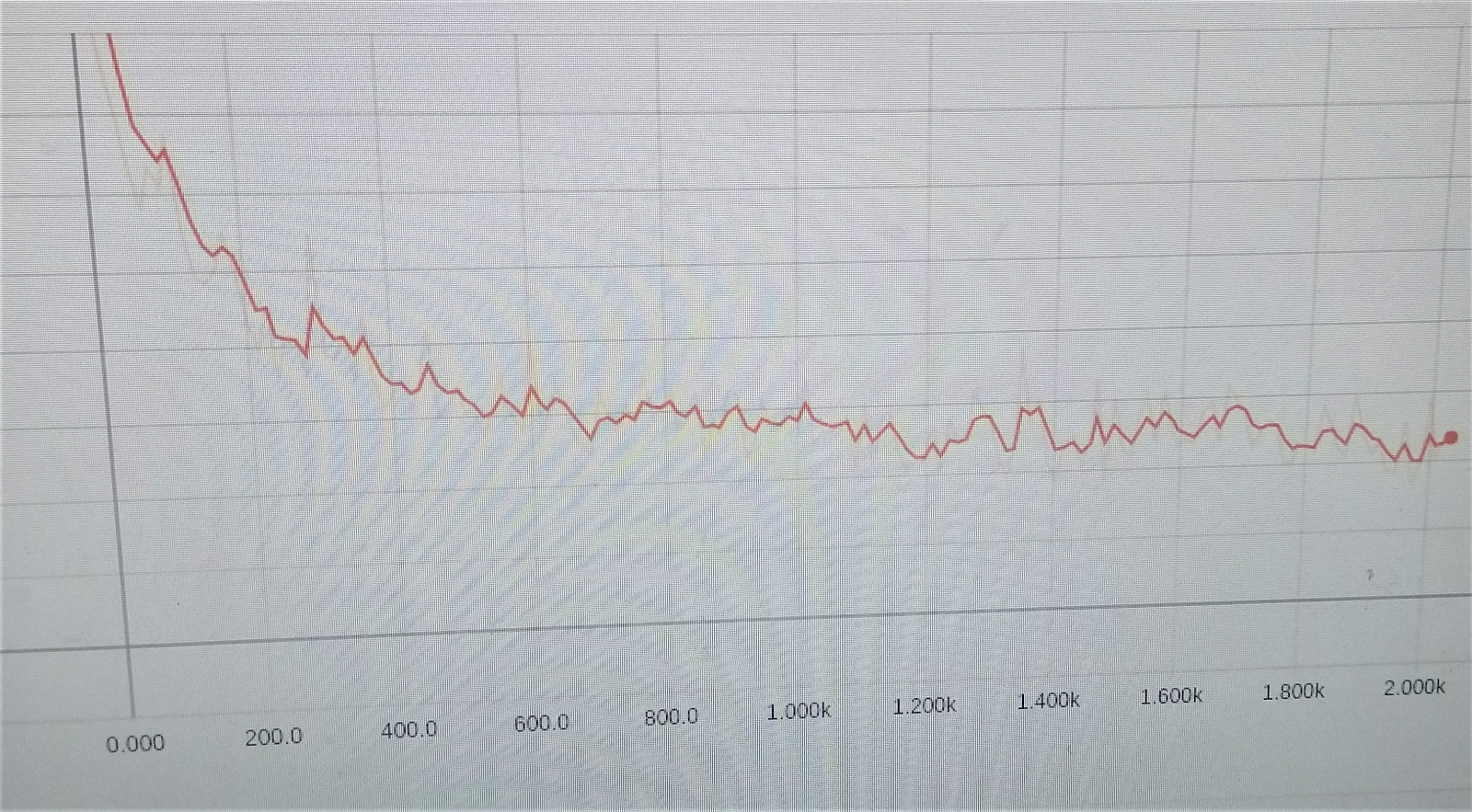
学習エラーを減らす大切なスケジュール
多くのアーキテクチャをテストした後、ResNet-50は、速度と認識品質の最適な組み合わせとして選択されました。 すべての長所と短所を比較検討した後、この訓練されたネットワークをそのまま受け入れ、既に許容できる結果が得られたため、ヘルメットで訓練するより単純なシングルショット検出器(SSD)ネットワーク[3]を決定しました。 、しかしヘルメットで作業するときに満足のいく90%+を提供しました。 この一見非論理的な決定は、SSDの追加使用が認識自体に費やす時間をわずかに増加させたが、異なるパラメーターと更新されたデータセットを使用したネットワークのトレーニングとテストに費やした時間を大幅に短縮したためです(数日から20-30 GTX 1060 6GBで数時間)、これは開発の反復が増加したことを意味します。
したがって、いくつかの結論を導き出すことができます。まず、最新のNSフレームワークはエントリのしきい値が低く(間違いなく、それらの効果的な使用には機械学習の分野での深い知識が必要です)、パターン認識問題の解決においてはるかに便利で機能的です; 第二に、学生はラピッドプロトタイピングとテクノロジーテストに役立ちます;)
コメントで質問と建設的な批判に答えてうれしいです。