ウィキペディアによると、
データ分析は数学とコンピューターサイエンスの分野であり、実験データ(広義)から知識を抽出するための最も一般的な数学的手法と計算アルゴリズムの構築と研究に従事しています。 有用な情報を抽出して決定を下すために、データを調査、フィルタリング、変換、およびモデリングするプロセス。少し単純な言語で言えば、データ処理アルゴリズムに関連するメソッドとアプリケーションの全体を理解し、各着信オブジェクトに対する応答が明確に記録されていないことをデータ分析で理解することをお勧めします。 これにより、ソートや辞書の実装などの従来のアルゴリズムと区別されます。 その実行時間と占有メモリ量は、古典的なアルゴリズムの特定の実装に依存しますが、そのアプリケーションの期待される結果は厳密に固定されています。 対照的に、数字を認識するニューラルネットワークでは、8の手書きの数字を描いた着信画像で8に答えることが期待されますが、この結果を要求することはできません。 さらに、(言葉の合理的な意味での)ニューラルネットワークは、正しい入力データの1つまたは別のバージョンと間違われることがあります。 このような問題のステートメントと、そのソリューションで使用されるメソッドとアルゴリズムを、 非決定的 (またはファジー )なものと呼び、古典的な( 決定論的な、 明確な )ものとは対照的です。
アルゴリズムと発見的方法
説明されている数字認識の問題は、対応するディスプレイを実装する機能を個別に選択することで解決できます。 おそらく、それほど速くなく、あまり良くもありません。 一方、 機械学習法に頼ることができます。つまり、手動でラベル付けされたサンプル(または、特定の履歴データ)を使用して、決定的な関数を自動的に選択できます。 したがって、以下では、(一般化された) 機械学習アルゴリズムを、何らかの方法でデータに基づいて特定の問題を解決する非決定的アルゴリズムを形成するアルゴリズムと呼びます。 (プリロードされたデータまたは外部APIを使用するディレクトリが定義に該当しないように、取得されたアルゴリズムの非決定的な性質が必要です)。
したがって、機械学習は、データ分析の最も一般的で強力な(ただし、それだけではありません)方法です。 残念ながら、人々はまだ多かれ少なかれ任意の性質のデータをうまく処理する機械学習アルゴリズムを発明していないため、専門家はデータを独立して前処理して、アルゴリズムの適用に適した形式にする必要があります。 ほとんどの場合、この前処理は機能選択 (英語の機能選択 )または前 処理と呼ばれます 。 実際、ほとんどの機械学習アルゴリズムは、固定長の数値のセットを入力として受け入れます(数学者の場合、 ) ただし、現在はニューラルネットワークに基づくさまざまなアルゴリズムも広く使用されており、数値のセットだけでなく、画像などの追加の主に幾何学的なプロパティを持つオブジェクトも受け入れることができます(アルゴリズムはピクセル値だけでなく、相対的な位置)、音声、動画、テキスト。 それにもかかわらず、これらのケースでは通常、いくつかの前処理が発生するため、機能選択は成功した前処理の選択に置き換えられると想定できます。
教師との機械学習のアルゴリズム(狭義の意味)は、アルゴリズム(数学者向け、マッピング)と呼ばれ、一連のポイントを取ります。 (例またはサンプルとも呼ばれます) およびラベル(予測しようとしている値) 、および出力はアルゴリズム(=関数)を提供します すでに特定の値と一致しています 任意の入力 例のスペースに属します。 たとえば、番号を認識する前述のニューラルネットワークの場合、トレーニングセットに基づく特別な手順を使用して、ニューロン間の接続に対応する値が確立され、それらの助けを借りて、各新しい例の予測がアプリケーションの段階で計算されます。 ちなみに、例とラベルのコレクションはトレーニングセットと呼ばれます。
(狭い意味での)教師による効果的な機械学習アルゴリズムのリストは厳密に制限されており、この分野での集中的な研究にもかかわらずほとんど補充されていません。 ただし、これらのアルゴリズムを適切に適用するには、経験とトレーニングが必要です。 実用的なタスクをデータの分析、機能または前処理のリスト、モデルとそのパラメーターの選択、および有能な実装のタスクに効果的に減らすという問題は、それらを一緒に取り組むことは言うまでもなく、それ自体簡単ではありません。
機械学習法を使用してデータ分析の問題を解決する一般的なスキームは、次のようになります。
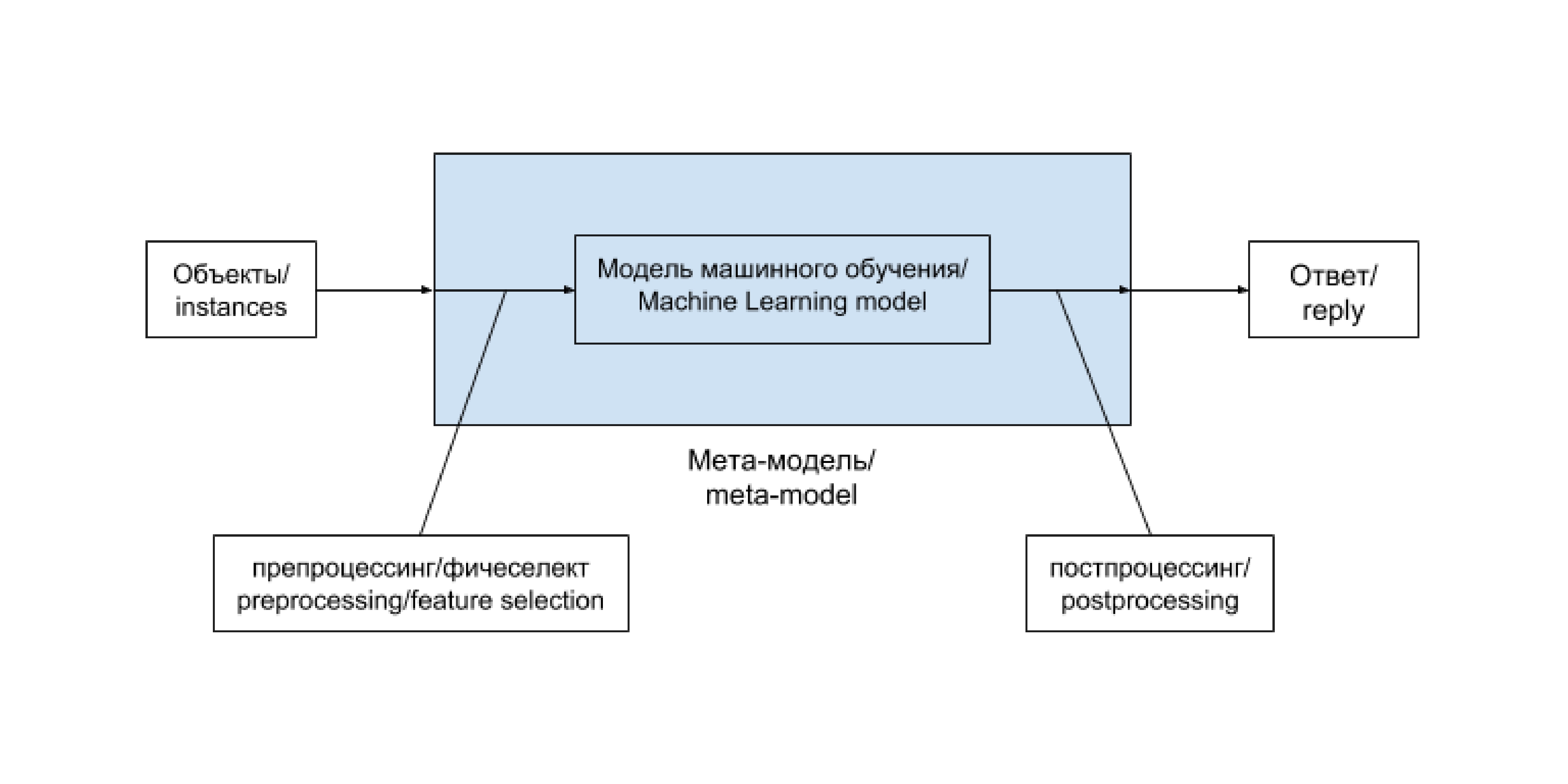
チェーン「前処理-機械学習モデル-後処理」は、単一のエンティティに便利に区別されます。 多くの場合、このようなチェーンは変更されないままで、新しく到着したデータを定期的に再トレーニングします。 場合によっては、特にプロジェクト開発の初期段階では、その内容は、データに直接依存しない多少複雑なヒューリスティックに置き換えられます。 もっと難しいケースがあります。 このようなチェーン(およびその可能なバリアント)に対して別の用語を開始し、 メタモデルと呼びます。 ヒューリスティックの場合、次のスキームに削減されます。
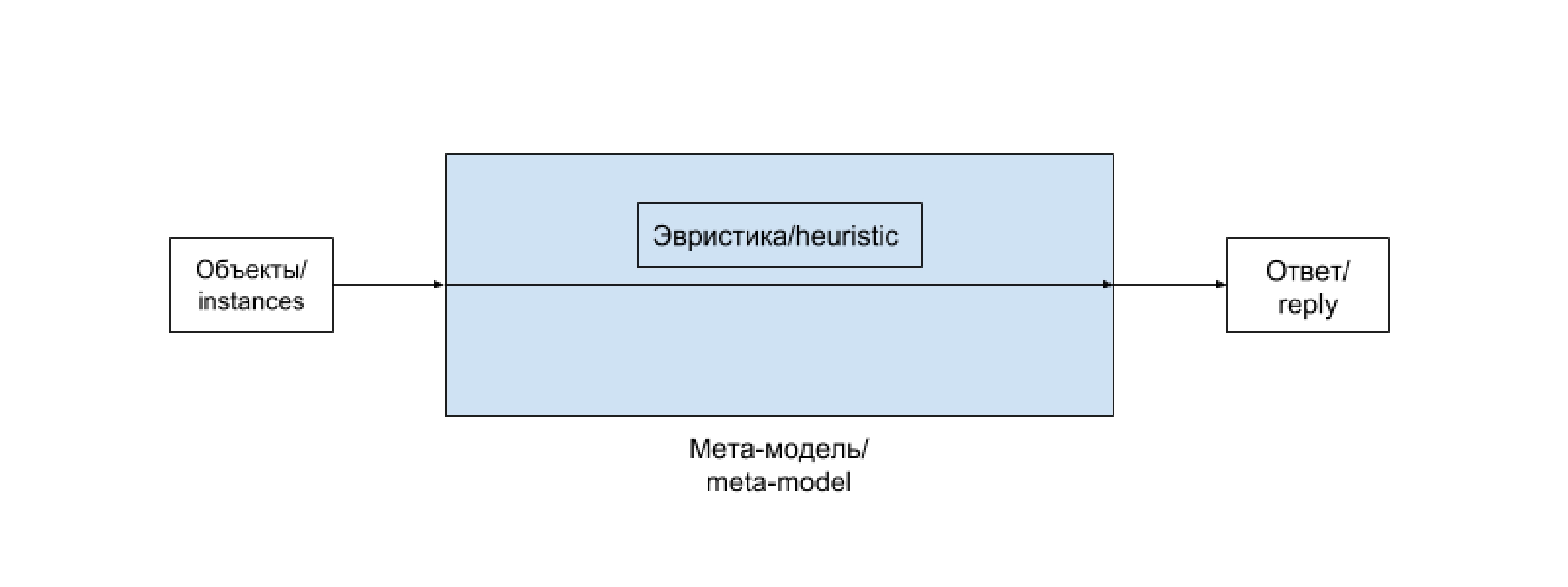
ヒューリスティックは、高度な方法を使用しない、手動で選択された単純な機能であり、原則として、良い結果は得られませんが、プロジェクトの初期段階など、特定のケースでは受け入れられます。
教師との機械学習タスク
設定に応じて、機械学習のタスクは分類、回帰、ロジスティック回帰のタスクに分けられます。
分類とは、着信オブジェクトが明確に定義されたリストのどのクラスに属するかを判断する必要がある問題のステートメントです。 典型的で一般的な例は、上記の数字の認識です。各画像は、表示された図に対応する10のクラスのいずれかと一致する必要があります。
回帰は、価格や年齢など、オブジェクトの定量的な特性を予測する必要がある問題の記述です。
ロジスティック回帰は、上記の2つの問題ステートメントのプロパティを組み合わせます。 オブジェクトで発生したイベントを設定し、新しいオブジェクトでの確率を予測する必要があります。 このようなタスクの典型的な例は、ユーザーが参照リンクまたは広告をクリックする可能性を予測するタスクです。
メトリックの選択と検証手順
(ファジー)アルゴリズムの予測の品質のメトリックは、その作業の品質を評価し、そのアプリケーションの結果を有効な回答と比較する方法です。 より数学的には、これは入力として予測リストを受け取る関数です そして、起こった答えのリスト 、および予測の品質に対応する戻り値。 たとえば、分類問題の場合、最も単純で最も一般的なオプションは不一致の数です 、および回帰問題の場合、標準偏差 。 ただし、場合によっては、実際的な理由で、標準品質の指標を少なくする必要があります。
動作し、実際のユーザーと対話する(または顧客に渡す)アルゴリズムを製品に導入する前に、このアルゴリズムの動作を評価することをお勧めします。 このために、 検証手順と呼ばれる次のメカニズムが使用されます 。 利用可能なラベル付きサンプルは、トレーニングと検証の2つの部分に分かれています。 アルゴリズムはトレーニングサンプルでトレーニングされ、その品質評価(または検証)は検証サンプルで実行されます。 機械学習アルゴリズムをまだ使用せず、ヒューリスティックを選択する場合、アルゴリズムの品質を評価するラベル付きサンプル全体が検証され、トレーニングサンプルが空であり、0個の要素で構成されていると想定できます。
典型的なプロジェクト開発サイクル
最も一般的な用語では、データ分析プロジェクトの開発サイクルは次のとおりです。
- 問題文、可能なデータソースの研究。
- 数学言語の再定式化、予測の質のためのメトリックの選択。
- 実際の環境でのトレーニングおよび(少なくともテスト)使用のためのパイプラインの作成。
- 問題を解決するヒューリスティックまたは単純な機械学習アルゴリズムを作成します。
- 必要に応じて、アルゴリズムの品質を改善して、メトリックを改良し、追加のデータを引き付けることができます。
おわりに
これですべてです。次回は、分類、回帰、ロジスティック回帰の問題を解決するために使用される特定のアルゴリズム、および問題の基本的な研究を行い、応用プログラマーが使用する結果を準備する方法について説明します 。
PS次のトピックでは、私よりも機械学習の問題に関する学術的な観点に固執している人々と少し議論しました。 それは私のhabrokarmにいくらか悪影響を及ぼしました。 したがって、次の記事の表示を加速し、適切な権限を持ちたい場合は、少し試してください。これにより、続編をより迅速に作成およびレイアウトできます。 ありがとう