
今日、ネットワークはあなたの顔を認識して携帯電話のロックを解除し、有名なアーティストの写真をスタイルし、フレームにホットドッグがあるかどうかを判断します。
この記事では、これらすべてを実現できる高度な畳み込みネットワークアーキテクチャであるMobileNetについて説明します。
記事は3つの部分で構成されます。 最初に、ネットワークの構造と、 元の科学研究の著者がアルゴリズムの速度を最適化するために提案したトリックに注目します。 第2部では、数か月前にGoogleの研究者が発表したMobileNetV2の次のバージョンについて説明します。 最後に、このアーキテクチャで達成可能な実用的な結果について説明します。
前のシリーズ
前回の投稿では、Xceptionアーキテクチャについて検討しました。これにより、従来の畳み込みをいわゆる深さ方向に分離可能な畳み込みに置き換えることで、畳み込みネットワークのパラメータ数をInceptionのようなアーキテクチャで大幅に減らすことができました。 それが何であるかを簡単に思い出させてください。
通常の畳み込みはフィルターです Dk∗Dk∗Cin どこで Dk 畳み込みカーネルのサイズ Cin -入力のチャンネル数。 畳み込み層の総計算量は次のとおりです。 Dk∗Dk∗Cin∗Df∗Df∗Cout どこで Df レイヤーの高さと幅です(入力テンソルと出力テンソルの空間次元が一致すると考えられます)。 Cout -出力のチャンネル数。
深さ方向に分離可能な畳み込みの考え方は、同様のレイヤーを深さ方向の畳み込み(チャネルフィルター)と1x1畳み込み(点状畳み込みとも呼ばれます)に分解することです。 そのようなレイヤーを適用するための操作の総数は (Dk∗Dk+Cout)∗Cin∗Df∗Df 。
概して、MobileNetを正しく構築するために知っておく必要があるのはこれだけです。
MobileNetの構造
左側は従来の畳み込みネットワークブロックで、右側はMobileNetベースブロックです。
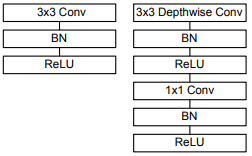
対象とするネットワークの畳み込み部分は、最初の3x3畳み込みの1つの通常の畳み込み層と、図の右側に示されている13個のブロックで構成されます。
このアーキテクチャの特徴は、最大プーリング層の欠如です。 代わりに、2のストライドパラメーターを使用した畳み込みを使用して、空間次元を削減します。
2つのHyperNet MobileNetアーキテクチャパラメーター alpha (幅係数)および rho (深度係数または解像度係数)。
幅係数は、各レイヤーのチャンネル数に影響します。 例えば alpha=1 記事に記載されているアーキテクチャを提供します。 alpha=0.25 -各ブロックの出力に4倍のチャネル数を持つアーキテクチャ。
解像度係数は、入力テンソルの空間次元を決定します。 例えば rho=0.5 は、各レイヤーの入力に供給されるフィーチャマップの高さと幅が半分になることを意味します。
両方のパラメーターを使用すると、ネットワークのサイズを変更できます。 alpha そして rho 、認識精度は低下しますが、同時に作業速度が向上し、消費されるメモリが削減されます。
MobileNetV2
MobileNetの出現自体がモバイルプラットフォームのコンピュータービジョンに革命をもたらしましたが、数日前、Googleはこのファミリーの次世代ニューラルネットワークである MobileNetV2を一般公開しました 。
MobileNetV2はどのようなものですか?
このネットワークの主要な構成要素は一般に前世代と似ていますが、多くの重要な機能があります。
MobileNetV1と同様に、ステップ1(左図)とステップ2(右図)のコンボリューションブロックがあります。 ステップ2のブロックは、テンソルの空間次元を縮小するように設計されており、ステップ1のブロックとは異なり、残留接続がありません。
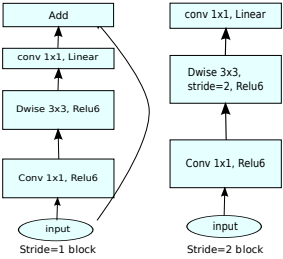
著者によって拡張畳み込みブロック (元の拡張畳み込みブロックまたは拡張層を備えたボトルネック畳み込みブロック )として呼び出されたMobileNetブロックは、3つの層で構成されています。
- 最初に、 拡張レイヤーと呼ばれる多くのチャネルを含む点ごとの畳み込みがあります。
入力では、このレイヤーは次元テンソルを取ります Df∗Df∗Cin 、そして出力はテンソルを与える Df∗Df∗(t∗Cin) どこで t -拡張レベル(元の拡張係数)と呼ばれる新しいハイパーパラメーター。 著者は、このハイパーパラメーターを5〜10の値に設定することをお勧めします。この場合、小さい値のネットワークでは小さい値が、大きい値のネットワークでは大きい値が効果的です(記事自体、すべての実験 t=6 )
このレイヤーは、大きな次元の空間に入力テンソルのマッピングを作成します。 著者は、このマッピングを「ターゲットの多様性」と呼びます(元の「関心のある多様体」 ) - 次に、 ReLU6アクティベーションによる深さ方向の畳み込みが行われます。 このレイヤーは、以前のレイヤーと一緒に、本質的にすでにおなじみのビルディングブロックMobileNetV1を形成します。
入力では、このレイヤーは次元テンソルを取ります Df∗Df∗(t∗Cin) 、そして出力はテンソルを与える (Df/s)∗(Df/s)∗(t∗Cin) どこで s -畳み込みのステップ(ストライド)。思い出すように、深さ方向の畳み込みはチャンネル数を変更しません。 - 最後に、線形アクティベーション関数を使用した1x1コンボリューションがあり、チャネル数が削減されます。 この記事の著者は、前のステップの後に得られた高次元の「ターゲット多様体」は、有用な情報を失うことなく、より小さな次元の部分空間に「入れる」ことができると仮定しています。これは実際、このステップで行われます(実験結果からわかるように、この仮説は完全に正当化)。
入力では、そのような層は次元テンソルを取ります (Df/s)∗(Df/s)∗(t∗Cin) 、そして出力はテンソルを与える (Df/s)∗(Df/s)∗Cout どこで Cout -ブロックの出力のチャネル数。
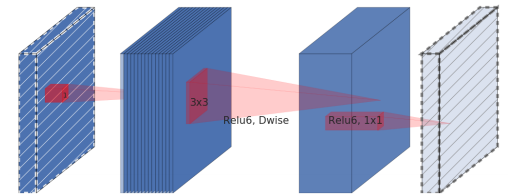
実際、このブロックの3番目のレイヤーはボトルネックレイヤーと呼ばれ、これがMobileNetの第2世代と第1世代の主な違いです。
MobileNetが内部的にどのように機能するかがわかったので、それがどのように機能するかを見てみましょう。
実際の結果
いくつかのネットワークアーキテクチャを比較します。 最後の投稿であるXception、深くて古いVGG16、およびMobileNetのいくつかのバリエーションを例に取ります。
| ネットワークアーキテクチャ | パラメータ数 | トップ1の精度 | トップ5の精度 |
|---|---|---|---|
| Xception | 2291万 | 0.790 | 0.945 |
| VGG16 | 138.35M | 0.715 | 0.901 |
| MobileNetV1(アルファ= 1、ロー= 1) | 420万 | 0.709 | 0.899 |
| MobileNetV1(アルファ= 0.75、ロー= 0.85) | 259万 | 0.672 | 0.873 |
| MobileNetV1(アルファ= 0.25、ロー= 0.57) | 0.47M | 0.415 | 0.663 |
| MobileNetV2(アルファ= 1.4、ロー= 1) | 6.06M | 0.750 | 0.925 |
| MobileNetV2(アルファ= 1、ロー= 1) | 3.47M | 0.718 | 0.910 |
| MobileNetV2(アルファ= 0.35、ロー= 0.43) | 166万 | 0.455 | 0.704 |
これらの実験の最大の成果は、モバイルデバイスで動作可能なネットワークがVGG16よりも高い精度を示していることです。
また、MobileNetV2に関する記事には、他のタスクに関する非常に興味深い結果が示されています。 特に、著者は、畳み込み部分でMobileNetV2を使用するオブジェクト検出タスクのSSDLiteアーキテクチャが、 MS COCOデータセットの精度でよく知られているYOLOv2リアルタイム検出器を上回り、20倍高速で10倍小さいサイズ(特に、Google Pixelスマートフォンでは、MobileNetV2を使用すると5 FPSでオブジェクトを検出できます)。

次は?
MobileNetV2により、モバイル開発者はほぼ無制限のコンピュータービジョンツールを受け取りました。画像を分類するための比較的単純なモデルに加えて、モバイルデバイスでオブジェクト検出とセマンティックセグメンテーションアルゴリズムを直接使用できるようになりました。
同時に、KerasとTensorFlowを使用したMobileNetの使用は非常に簡単であるため、有名な漫画本のように、原則として、開発者はアルゴリズムの内部構造を詳しく調べることなくこれを行うことができます。