...または富田のような事実を明らかにする。
これらのパーサーを見ると、コンピューティング、メモリ要件、ライセンスの制限、そして各ソリューションの制限が非常に複雑であることがわかります。
そこで非常に複雑なことを理解するために、私は自分のパーサーを作りたいと思いました。 幸いなことに、週末は長くなりました。
主なアイデア
自分でテキストをどのように解析すればいいのかと思いました。 フレーズから主要な要素を分離し、頭の中で単語間の関係を構築する方法は?
TomitaはGLRパーサーに基づいて構築されていると言われています。GLRパーサーは、LRパーサーを拡張し、単語を順番に読み取り、それらの間に関係のツリーを構築しようとします。
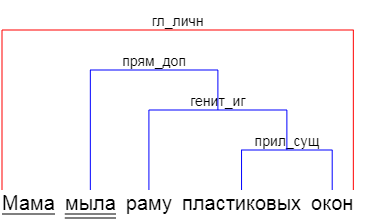
テキストは、私たちが注目している一連のスタンプと見なされるべきだと思いました。 「 赤いバラの白い 」、「 青い海の上の暗い空 」、「 愚かなペンギンが a 病に隠れている 」-名詞とそれに関連する形容詞がどこにでも見られます。 さらに、「白」はroseではなく、を指すことを理解しています。 これをどうやってやるの? 少なくとも、「白」は「moth」のように男性的であり、「赤」はバラのように女性的であることがわかります。 「天」と「海」の場合、名詞が置かれている場合が役立ちます。
さらに、スタンプを見つけて、フレーズ全体を理解するまで、フレーズの結果の断片を他のスタンプなどに結合します-「mothのmoth」(moth-白、rose-赤)、「海の上の空」(空-暗い、海-青)。
適切なツールを選択する
つまり、テンプレート(形容詞、名詞)を検索するには、同じケース、数、性別でいくつかの単語を検索する必要があります。 どうやって? Pythonでのキャラクタリゼーション(grammems)の自然な解決策は、 kmikeのpymorphy2を使用することです
import pymorphy2 as py def tags(word): morph = py.MorphAnalyzer() return morph.parse(word) >>> print(tags('')[0]) Parse(word='', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='', score=0.125, methods_stack=((<DictionaryAnalyzer>, '', 86, 8),)) >>> print(tags('')[0].tag.grammemes) frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'})
「femn」、「ADJF」、「sing」、「gent」、「Qual」という単語は、pymorphy2で受け入れられる文法の表記法です 。 指定は一意であり、単語の望ましい特性を一意に決定するために使用できます。
キャンバスの最初のタッチ
ツールができたので、簡単なテンプレートを作成しましょう。
source = ''' # # / _- NOUN,nomn VERB NOUN,accs '''
ここでは、主格(nomn)の名詞(NOUN)、動詞(VERB)、対格の名詞(accs)が続きます。 テンプレートに記載されていない特性は重要ではありません。
それを読者にしてみましょう:
class PPattern: def __init__(self): super().__init__() import io def parseSource(src): def parseLine(s): nonlocal arr, last s = s.strip() if s == '': last = None return if s[0] == '#': return if last is None: last = PPattern() arr.append(last) last.example = s else: last.tags = s.split() arr = [] last = None buf = io.StringIO(src) s = buf.readline() while s: parseLine(s) s = buf.readline() return arr s = parseSource(source)
ここでStringIOを操作しても怖がらないでください。大きなテキストを読む必要がある場合に備えて、ストリーミングリーディングを行いたいと思いました。
指定されたコードはテンプレートのみを読み取りますが、それ以外のことは行いません。 解析されたテキストとその解析を追加します。
source = ''' # # / _- NOUN,nomn VERB NOUN,accs ADJF NOUN # NOUN,nomn VERB NOUN,loct ''' text = ''' ''' import pymorphy2 as py class PPattern: def __init__(self): super().__init__() def checkPhrase(self,text): def checkWordTags(tags, grams): for t in tags: if t not in grams: return False return True def checkWord(tags, word): variants = morph.parse(word) for v in variants: if checkWordTags(self.tags[nextTag].split(','), v.tag.grammemes): return (word, v) return None morph = py.MorphAnalyzer() words = text.split() nextTag = 0 result = [] for w in words: res = checkWord(self.tags[nextTag].split(','), w) if res is not None: result.append(res) nextTag = nextTag + 1 if nextTag >= len(self.tags): return result return None def parseText(pats, text): def parseLine(line): was = False for p in pats: res = p.checkPhrase(line) if res: print('+',line, p.tags, [r[0] for r in res]) was = True if not was: print('-',line) buf = io.StringIO(text) s = buf.readline() while s: s = s.strip() if s != '': parseLine(s) s = buf.readline() patterns = parseSource(source) parseText(patterns, text)
単語を分析するとき、Pymorphy2はすべての可能なオプションの配列を返します。単語の種類は「soap」は名詞または動詞です。 したがって、私たちのタスクは、これらすべてのオプションをチェックし、単語の特性がパターンに適合するようにそれらから選択することです。 これは、 checkWord関数で行われます。
分析の結果を取得します。
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
まあ、スタートには悪くない。
それですべてですか?
いいえ、もちろん、今では、症例、出産などの対応を記述する必要があります。 言葉の間。 テンプレートの説明を変更します。
source = ''' # ADJF NOUN -a- -b- # , = a.case = b.case = a.number = b.number = a.gender = b.gender '''
変数
-a- -b-
定義と「=」で始まるルールの行がありました。 一般に、テンプレートの構文は気にしませんでした。したがって、各演算子は同じ行にあり、演算子のタイプは最初の文字によって決まります。
ルール解析をテンプレート解析に追加します。 ルールは2つのラムダにコンパイルされます-「=」文字の前の値を取得し、2番目の値を取得します。
def parseFunc(v, names): dest = v.split('.') index = names.index(dest[0]) dest = (eval('lambda a: a.' + '.'.join(dest[1:])), index) return dest def parseLine(s): ... elif s[0] == '-': # s = [x.strip('-') for x in s.split()] last.names = s elif s[0] == '=': # s = [x for x in s[1:].split() if x != ''] dest = parseFunc(s[0],last.names) src = parseFunc(s[2],last.names) last.rules.append(((dest[1],src[1]), dest, src)) else: ...
そして、テキスト解析にルールチェックを追加します。ラムダを計算して、その結果を比較するだけです。
... res = checkWord(self.tags[nextTag].split(','), w) if res is not None: result.append(res) usedP.add(wi) if not self.checkRules(usedP, result): result.remove(res) usedP.remove(wi) else: nextTag = nextTag + 1 if nextTag >= len(self.tags): return (result, usedP) ... def checkRules(self, used, result): for r in self.rules: if max(r[0]) < len(result): destRes = result[r[0][0]] destV = destRes[1] destFunc = r[1][0] srcRes = result[r[0][1]] srcFunc = r[2][0] srcV = srcRes[1] if not self.checkPropRule(destFunc,destV, srcFunc, srcV): return False return True def checkPropRule(self, getFunc, getArgs, srcFunc, srcArgs, \ op = lambda x,y: x == y): v1 = getFunc(getArgs) v2 = srcFunc(srcArgs) return op(v1,v2)
クラシックを運転しましょう
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
また、名前の規則を紹介します。
# NOUN Name -a- -b- = a.tag.case = b.tag.case = a.tag.number = b.tag.number
これにより解析が行われます。
+ - ['NOUN', 'Name'] ['', '']
より良い規則と異なる規則
すべてがとても良かったので、何かに気付かなかったということです。 パーサーは、「若い兄弟のミシャとヴォーバは幼稚園に行く」というフレーズを破りました-「若い人」には性別がなく、男性的な言葉「兄弟」を参照できるため、ルール
= a.gender = b.gender
確認できませんでした、そして女性の「姉妹」に。
したがって、ルールはより複雑にする必要があります。 さて、まだテキストからラムダをコンパイルしているので、2つではなく、チェックの結果を返す1つを作成できます。 このルールは、純粋なPythonの式として記述できます。
= a.tag.gender is None or a.tag.gender == b.tag.gender
Pythonには、式に「a」と「b」という名前を付けるための組み込みの手段が必要であるように思えました。 予感はだまされませんでした。ヘルプとドキュメントを少し読んで、必要なものがすべて揃ったASTパーサーと、次のコードに導かれました。
import ast def parseSource(src): def parseFunc(expr, names): m = ast.parse(expr) # varList = list(set([ x.id for x in ast.walk(m) if type(x) == ast.Name])) # indexes = [ names.index(v) for v in varList ] lam = 'lambda %s: %s' % (','.join(varList), expr) return (indexes, eval(lam), lam)
Python式のすべてのルールを書き直しました。 ちなみに、ルールが誤って記述されている場合、テンプレートディクショナリの読み取り時にコンパイルされず、例外によってプログラムがクラッシュするため、ディクショナリが読み取られると、ルールは実行可能です。
そしてそれはうまくいきました:
+ ['ADJF', 'NOUN'] ['', '']
すべてのテキストとその分析
フレーズは主にABCから取られています。 結局のところ、車を読み始めたら、実績のある方法を使用する方が良いでしょう。
テンプレート辞書
解析
# , text = ''' - '''
テンプレート辞書
# source = ''' # # # / _- NOUN,nomn VERB NOUN,accs # -a- -b- -c- = a.tag.number == b.tag.number # :SNOUN # ADJF NOUN -a- -b- # = a.tag.case == b.tag.case = a.tag.number == b.tag.number = a.tag.gender is None or a.tag.gender == b.tag.gender # # NOUN,nomn VERB PREP NOUN,loct -a- -b- -c- -d- = a.tag.number == b.tag.number # VERB INFN # NOUN Name -a- -b- = a.tag.case == b.tag.case = a.tag.number == b.tag.number # NOUN CONJ NOUN -a- -c- -b- = a.tag.case == b.tag.case # NOUN PNCT NOUN -a- -c- -b- = a.tag.case == b.tag.case = c.normal_form == '-' '''
解析
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN', 'Name'] ['', '']
+ ['NOUN', 'Name'] ['', '']
+ ['NOUN', 'Name'] ['', '']
+ ['NOUN', 'CONJ', 'NOUN'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ - ['NOUN', 'Name'] ['', '']
+ - ['NOUN', 'PNCT', 'NOUN'] ['', '-', '']
+ - ['NOUN', 'PNCT', 'NOUN'] ['', '-', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN', 'CONJ', 'NOUN'] ['', '', '']
+ ['NOUN', 'CONJ', 'NOUN'] ['', '', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['', '', '', '']
+ ['VERB', 'INFN'] ['', '']
次は?
1.ご覧のとおり、個々のテンプレートを検索することに決めましたが、解析結果を解析ツリーに結合しませんでした。 これにはいくつかの理由がありますが、その理由の1つは、何をする価値があるかわからないことです。 各解析オプションから少しの情報が得られます。 それらをツリーに組み合わせて、知識を人工構造に絞り込もうとします。 子供は、どの単語が対象であり、どの単語が述語であるかを知らなくても、文章を読んで理解できます。 彼は穀物を取り、頭に(記述された)世界の絵を作ります。 なぜ車にもっと必要なのですか?
2.明らかに、ある単語を別の単語からテキスト内でどれだけ削除できるかについての十分なルールはありません。 そのため、「パパ」は「イリヤ」になりましたが、「と兄弟」という言葉はその間にあります。
3.また、結果を相互にソートし、可能性の低いものを破棄する必要があることも明らかです。 関連性の定義は未解決の問題であり、少なくともお互いの言葉の隔たりを測定することは可能です。
4.ルールでは、スピーチの残りの部分に加えて、十分な句読点がありません。 定数リテラル「NOUN '-' NOUN」を入力するか、教師の例のように、ルールの記号を確認できます。
5. Pymorphy2は単語が品詞に属すると想定できるため、そのようなオプションも可能です。
>>> parseText(patterns, ' ')
+ ['ADJF', 'NOUN'] ['', '']
+ ['NOUN', 'Name'] ['', '']
ただし、ここでは、Petrushevskayaの元の言葉を交換する必要がありました。 逆ワードパターンはありません。 これが問題であるということではありません。テンプレートを長く入力することはできませんが、ロシア語の単語の並べ替えが頻繁に発生し、すべてをテンプレートでカバーすることはできません。 したがって、テンプレートの説明に置換を許可する修飾子を導入することは理にかなっています。
コードはGitHubにあります 。