ID認証のタスクは、アクセス制御が必要な領域で使用されます。 これらは、銀行、保険会社、および機密情報が使用されるその他の分野です。
従来、認証では、パスワード、制御ワード、パスポート番号などの「キー」を知るという原則が使用されていました。 説明されている方法には欠点があります-確認されるのはアイデンティティではなく、その人に知られている情報です。
生体認証ソリューションにはこの欠点はありません。
問題を解決する有望なアプローチは音声認証です。 各人の声は独特であり、与えられた正確さで、彼が誰に属しているか言うことができます。 識別の問題については、このアプローチは適用できません。これは、現在の技術レベルでは「偽合格」のエラーが3〜5%のエラーを与えるためです。 アルゴリズムの精度は95〜97%であり、検証タスクでテクノロジーを使用できます。
音声検証のもう1つの利点は、コンタクトセンターでの認証時間の短縮です。これにより、オペレーターの数に比例した経済効果が得られます(賃金と通信の節約)。 計算によると、実装の達成可能な効果は最大2700万ルーブルです。 100人のオペレーターのコンタクトセンター(税金、電話費用、2シフトでのオペレーターの作業などを含む)については年に1回ですが、その数は特定のケースによって異なります。
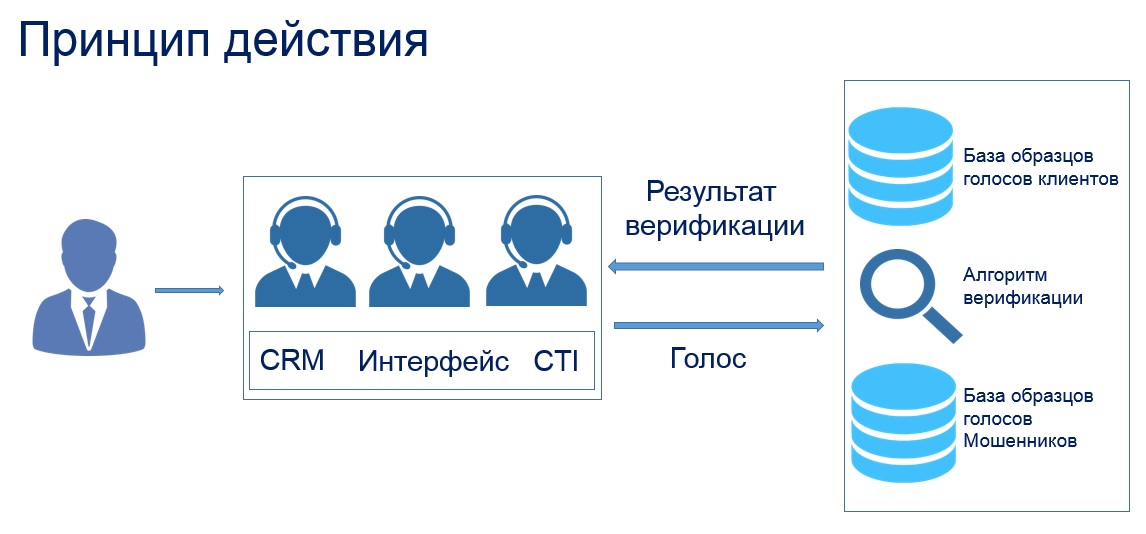
古典的なアプローチの原則
人の声の録音は、処理、特徴の抽出、分類器の作成が必要な信号です。
このソリューションは、デジタル信号処理サブシステム、特徴抽出サブシステム、音声強調サブシステム、分類器の4つのサブシステムで構成されています[1]。
デジタル信号処理サブシステム
- 信号がフィルタリングされ、調査範囲が強調表示されます。 人間の耳には2万から2万Hzの周波数が聞こえますが、生体認証の検証の決定には300から3400 Hzの範囲が使用されます。
- 信号は、高速フーリエ変換法により周波数領域に転送されます。
特性サブシステム
- 信号は20〜25 ml.sのセグメントに分割されます。 さらに、セグメント-フレームと呼びます。
- 各フレームについて、きめの細かい係数が決定されます-MFCC、および最初と2番目のデルタ。 最初の13個のMFCC比率が使用されます。 [2]
音声サブシステム
- 特徴ベクトルは、音声の存在について事前に訓練されたバイナリ分類器に送られます。 分類器は、フレームごとに、音声の存在を決定します。 品質を最大化するために、XGboostなどのツリーベースのブースティングモデルが使用されます。 作業速度を最大化するために、ロジスティック回帰またはSVM参照ベクトル法が使用されます。
分類子
- スピーチが存在したフレームから選択された特徴に応じた分布の混合が構築されます[3]。 モデルのトレーニングには少なくとも24〜30秒、テストには12〜15秒かかります。
- 分布の混合を使用して、100個の値で構成される最終的な特徴ベクトル(i —ベクトル)が構築されます。
- 特徴ベクトルは、バイナリ分類器に送られます。 従来のアプローチでは、SVMまたはブースティングが分類に使用されます。 [4]
正しく動作させるには、第1種と第2種の誤差係数を設定する必要があります。 誤認のエラーを最小限に抑える必要がある場合、誤認のエラーの「ペナルティ」は、誤認のエラーの「ペナルティ」を100〜1000倍超えます。 100の係数を使用しました。
検証ソリューションを構築するには、話者によってラベル付けされたデータと音声の存在が必要です。 電話モデル、部屋のタイプなどの異なる音響条件で、少なくとも5〜10時間、少なくとも数百のスピーカーを使用することをお勧めします。 5,000を超えるオーディオファイルの独自のデータセットを使用しました。 これは、アルゴリズムの再トレーニングを避けるために必要です。 再トレーニングを最小限に抑えるために、相互検証と正則化をさらに使用する必要があります。
次のGoogle ソリューションはVAD(音声検出)として使用できます。 ただし、その仕組みを理解したい場合は、XGboostに基づいて独自のソリューションを作成することをお勧めします。 達成可能な品質メトリック精度> 99%。 私たちの経験から、VADの仕事の質こそが最終的な仕事の質の「ボトルネック」です。
デジタル信号処理タスクについては、 ボブのソリューションが知られています。
まとめ
音声検証ソリューションを構築するには、データ、デジタル信号処理のスキル、機械学習が必要です。
検証ソリューションのデバイスの原理、および添付の文献の機械学習とDSPの基礎をさらに詳しく知ることができます。
参照:
1. A.V. コズロフ、O.Yu。 Kudashev、Yu.N。 マトベエフ、T.S。 ペホフスキー、K.K。 シモンチク、A.K。 シュリパ。 「NIST SREコンテストの音声認識システム」。 2013
2. Yu.N. マトベエフ。 「自動話者識別システムのための音声標識の情報性の研究。」 2013
3. D.V. ベイカー、S.G。 チホレンコ。 「ガウソビエ混合物を使用して、技術システムで音声で話者を識別するアルゴリズム。」
4. N.S. クリメンコ、I.G。 ゲラシモフ。 「話者のテキストに依存しない識別のタスクにおけるブースティングの有効性の研究。」 2014
有用なリソース:
1.モスクワ物理学技術研究所の機械学習コース。
2.内部ポータルのMIPTからのDSPコース。