監視は管理者が持っている主なものです。 監視には管理者が必要であり、管理者には監視が必要です。

過去数年間で、監視のパラダイム自体が変更されました。 新しい時代がすでに到来しており、今、サーバーのセットとしてインフラストラクチャを監視している場合、ほとんど何も監視していません。 現在、「インフラストラクチャ」はマルチレベルのアーキテクチャであり、各レベルを監視するツールがあるためです。
「サーバーがクラッシュした」、「レイドのネジを交換する必要がある」などの問題に加えて、アプリケーションレベルとビジネスレベルの問題を理解する必要があります。アプリケーション内のデータベースクエリが増加している、クエリなどがそうです。」
カスタムDockerネットワークを備えた3台のサーバーのシステムからKubernetesの数百台のサーバーを備えた大規模プロジェクトまで、さまざまな構成で約5,000台のサーバーをサポートしています。 そして、何かが壊れてすぐに修復されることを理解するために、これらすべてを何らかの形で監視する必要があります。 これを行うには、モニタリングとは何か、それが現代の現実にどのように組み込まれているか、どのように設計し、何をすべきかを理解する必要があります。 これについてお話したいと思います。
前と同じように
約10年前、監視は今よりずっと簡単でした。 ただし、アプリケーションはよりシンプルでした。
主に、システムインジケータが監視されました:CPU、メモリ、ディスク、ネットワーク。 phpで実行されているアプリケーションが1つあり、他には何も使用されなかったため、これで十分でした。 問題は、通常、このような指標についてほとんど語ることがないことです。 動作するかどうか。 システムインジケータのレベルを超えて、アプリケーション自体で正確に何が起こるかを理解することは困難です。
問題がアプリケーションレベル(「サイトがダウンしている」だけでなく、「サイトは機能しているが、何かが間違っている」)である場合、クライアントはそのような問題があると書いて電話をかけ、報告し、整理して、私たち自身がそのような問題に気付かなかったからです。
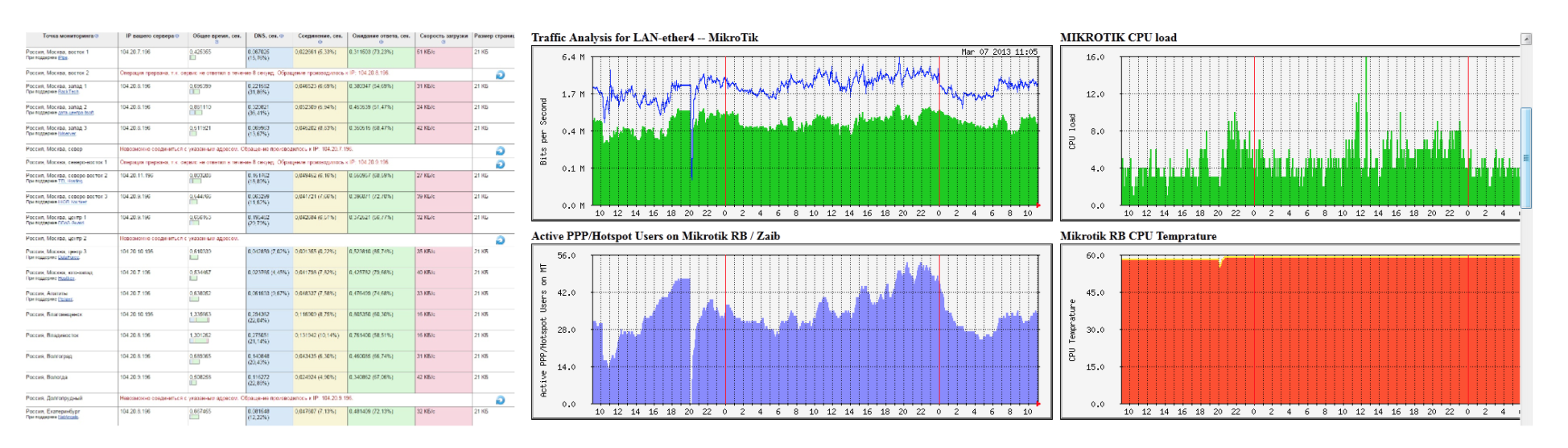
今のように
完全に異なるシステム:スケーリング、自動スケーリング、マイクロサービス、ドッカーを使用。 システムは動的になりました。 多くの場合、すべてが正確に機能する仕組み、サーバーの数、展開の仕組みを誰も実際には知りません。 それはそれ自身の人生を生きます。 何がどこで実行されているかさえ分からない場合があります(たとえば、Kubernetesの場合)。
もちろん、システム自体の複雑さにより、考えられる問題の数が増えました。 アプリのメトリック、Javaアプリケーションで実行されているスレッドの数、ガベージコレクターの一時停止の頻度、キュー内のイベントの数が表示されます。 監視がシステムのスケーリングも監視することは非常に重要です。 Kubernetes HPAがあるとします。 実行中の炉の数を理解する必要があり、実行中の各炉からアプリケーション監視システムにapmでメトリックを移動する必要があります。
これらはすべてシステムの動作に影響するため、これらすべてを監視する必要があります。
そして、問題自体はそれほど明白ではなくなりました。
従来、問題は2つの大きなグループに分けることができます。
第一種の問題-基本的な「ユーザー機能」は機能しません。
第二の種類の問題-何かが正常に機能せず、どこか間違った場所につながる可能性があります。
つまり、個別の「機能する/機能しない」だけでなく、さらに多くのグラデーションを監視する必要があります。 これにより、すべてが崩壊する前に問題をキャッチできます。
さらに、ビジネスパフォーマンスを監視する必要があります。 ビジネスでは、お金、注文の頻度、最後の注文からの経過時間などに関するチャートを作成したいと考えていました。これも監視タスクです。
適切な監視
設計と一般
監視する必要があるものの正確なアイデアは、アプリケーションとアーキテクチャの開発時に策定する必要があります。サーバーアーキテクチャに関することではなく、アプリケーションアーキテクチャ全体に関することです。
開発者/アーキテクトは、システムのどの部分がプロジェクトとビジネスの機能にとって重要であるかを理解し、パフォーマンスを確認する必要があると事前に考えてください。
監視は管理者にとって便利であり、何が起こっているのかを知る必要があります。 監視の目的は、スケジュールに従ってアラートを時間通りに取得し、正確に何が起こっているのか、何を修正する必要があるのかをすばやく理解することです。
メトリックとアラート(アラート)
アラートはできる限り明確にする必要があります。システムに精通していなくても、アラートを受け取った管理者は、このアラートの内容、参照するドキュメント、または少なくとも誰を呼び出すかを理解する必要があります。 正確に何を行う必要があるか、問題を解決する方法について明確な指示があるはずです。
問題が発生したとき、私は本当にそれが発生した理由を理解したいと思います。 アプリケーションが機能しないというアラートを受け取った場合、他の隣接システムの動作が異なるか、標準からのその他の逸脱が何かを知りたいと思います。 ダッシュボードに収集された理解可能なグラフがあるはずです。そこから、逸脱の場所がすぐにわかります。
これを行うには、正常なものと正常でないものを正確に理解する必要があります。 つまり、システムの状態に関する十分な履歴情報が必要です。 タスクは、標準からのすべての可能な逸脱をアラートでカバーすることです。
管理者がアラートを受信した場合、管理者はアラートをどう処理するか、または誰に問い合わせるかを知る必要があります。 対応方法についての指示が必要であり、定期的に更新する必要があります。 オーケストレーションシステムを介してすべてが機能する場合、おそらく、監視を含むすべての変更がオーケストレーションシステムを介してのみ発生する場合、すべてが順調です。 オーケストレーションシステムを使用すると、監視の関連性を適切に監視できます。
監視は、各事故の後に拡大する必要があります。突然、監視をすり抜けた問題が発生した場合、明らかに、次回問題が突然発生しないように、この状況を監視する必要があります。
業績
最後の販売からの時間、その期間の販売数を監視すると便利です。 リリースを投稿した場合、何が変わったのでしょうか。ビジネスインジケータにドローダウンはありますか? もちろん、A / Bテストがこれに答えますが、グラフィックも持ちたいです。 そして、エンドユーザーのアクションを監視する必要があります。購入を繰り返すスクリプトをphantomjsに記述し、メインビジネスプロセスのすべての段階を実行します。
また、おそらく物流サービスが機能しているかどうか、またはIpGeoBaseが再び落ちたかどうかを知りたいと思うでしょう。 (編集者のコメント:IpGeoBaseは、1C-Bitrix上の多数のオンラインストアを使用してユーザーの場所を特定するサービスです。ほとんどの場合、これはページロードコードで直接行われます。 、プログラマーに処理してタイムアウトする必要があること、および誰かに伝えます-落ちないようにIpGeoBaseに依頼してください)。
ビジネスインジケーターの低下がシステムに依存するか、外部のシステムに依存するかを理解する必要があります。
モニタリングモニタリング
監視自体も何らかの方法で監視する必要があります。 監視が正常に機能していることを確認する外部カスタムスクリプトが必要です。 あなたの監視システムがデータセンター全体とともに落ちており、誰もこれについてあなたに言っていないので、誰も電話から目を覚ますことを望みません。

コアツール
スケーリングする現代のシステムでは、原則として類似物がないため、おそらくPrometheusを使用します。 プロメテウスの便利なグラフを表示するには、Grafanaが必要です。プロメテウスのグラフはまあまあだからです。 いくつかのAPMも必要です。 Open Trace、jaeger、またはそのようなものの独自システムです。 しかし、これはめったに行われません。 主にNew RelicまたはDripstatのような特定のスタックシステムを使用します。 監視システムが1つもなく、複数のZabbixがない場合でも、これらのメトリックを収集する方法、およびアラートを配信する方法を理解する必要があります。 誰に通知するか、誰に通知するか、どの順序で、どのアラートに関連するか、それをどう処理するか。
順番に。
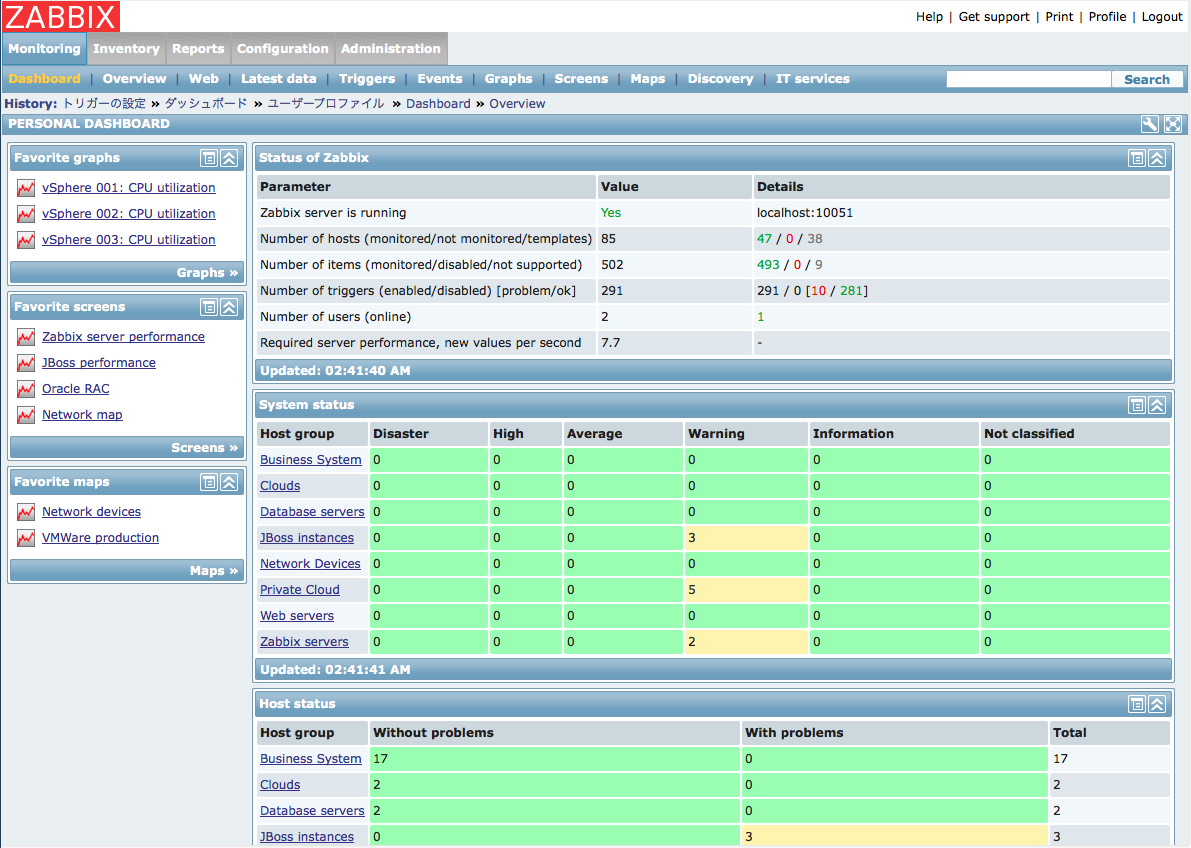
Zabbixは最も便利なシステムではありません。 特にシステムがスケーラブルであり、ロールを定義する必要がある場合、カスタムメトリックに問題があります。 また、非常にカスタムのチャート、アラート、ダッシュボードを作成できますが、これらはすべて非常に不便ではなく、動的でもありません。 これは静的な監視システムです。
プロメテウスは、膨大な数のメトリックを構築するための優れたソリューションです。 Zabbixのカスタムアラートとほぼ同じ機能を備えています。 チャートを表示し、いくつかのパラメーターの任意の組み合わせに基づいてアラートを作成できます。 そして、これはすべて非常にクールですが、見るのは非常に不便なので、Grafanaがそれに追加されます。 Grafanaはとても美しいです。 しかし、それ自体はシステムの監視に実際には役立ちません。 しかし、その上にあるすべてを読むと便利です。 おそらくグラフよりも優れています。

ELKおよびGraylog-アプリケーションのイベントに関するログを収集します。 開発者にとっては便利かもしれませんが、詳細な分析には通常十分ではありません。

New Relic-APM、開発者にも役立ちます。 現在、アプリケーションで何か問題が発生していることを理解する機会があります。 どの外部サービスがあまりうまく機能しないか、どのデータベースの応答が遅いか、またはどのシステムの相互作用が無駄になるかは明らかです。

APM-Open Tracing、zipkin、またはjaegerでシステムを作成した場合、おそらくこれがどのように機能するか、どのコードがどの部分で間違っているかを知っているでしょう。 New Relicもこれを明確にしていますが、必ずしも便利ではありません。
おわりに
システムの設計中にどのインジケータを監視する必要があるかを考え、システムのどの部分がその動作に重要であるか、およびその動作を確認する方法を事前に考えてください。
アラートは多すぎてはならず、アラートは関連する必要があります。 何が壊れたのか、どのように修正するのかをすぐに明確にする必要があります。
ビジネスインジケーターを適切に監視するには、ビジネスプロセスの編成方法、アナリストが必要とするもの、必要なインジケーターを測定するための十分なツールがあるか、何か問題が発生したかどうかを迅速に見つけることができるかを理解する必要があります。
次の投稿では、システム、アプリケーション、ビジネスレベルのすべてのレベルで、最新のインフラストラクチャの監視を適切に計画する方法を説明します。