
タスクは古く、よく研究されており、英語の場合、 Spacy 、 Stanford NER 、 OpenNLP 、 NLTK 、 MITIE 、 Google Natural Language API 、 ParallelDots 、 Aylien 、 Rosette 、 TextRazorなどの商用およびオープンソリューションが多数あります 。 ロシアにも良い解決策がありますが、それらはほとんど閉じています: DaData 、 Pullenti 、 Abbyy Infoextractor 、 Dictum 、 Eureka 、 Promt 、 RCO 、 AOT 、 Ahunter 。 オープンから、私は富田パーサーと新鮮なDeepmipt NERのみを知っています。
私はデータ分析に従事しており、ワープロのタスクは最も頻繁に行われるタスクの1つです。 実際には、たとえば、ロシア語のテキストから名前を抽出することはまったく簡単ではないことが判明しています。 Tomita-parserには既製のソリューションがありますが、Pythonとの統合は不便です。 最近、iPavlovのメンバーから解決策がありましたが、名前は通常の形式に縮小されていません。 たとえば、住所(「Marta St. 4、4」、「Leninsky passage、15」)を抽出するために、私はオープンな解決策を知りません、 pypostalがありますが、住所を解析し、テキストでそれらを探しません。 規制行為への参照の抽出などの非標準タスク(「ロシア連邦民法の第11条」、「法No. 122-FZの第6条の第1項」)では、一般に何をすべきかが不明です。
1年前、 ディマヴェセロフはナターシャプロジェクトを開始しました。 それ以降、コードは大幅に改善されました。 ナターシャはいくつかの大規模プロジェクトで使用されました。 これで、Habrユーザーにそのことを伝える準備ができました。
Natashaは、PythonのTomit-parser ( Yargy-parser )に類似しており、名前、住所、日付、金額、その他のエンティティを取得するための既製のルールのセットです。この記事では、ナターシャの用意されたルールの使用方法、そして最も重要なこととして、Yargyパーサーを使用して独自のルールを追加する方法を示します。
準備ルール
現在、ナターシャには名前、住所、日付、金額を取得するためのルールがあります。 組織の名前と地理的特徴にはまだルールがありますが、それらは非常に高品質ではありません。
名前
既製のルールを使用するのは簡単です:
from natasha import NamesExtractor from natasha.markup import show_markup, show_json extractor = NamesExtractor() text = ''' , , : . , . 1"" - , , - , , , ! ! ''' matches = extractor(text) spans = [_.span for _ in matches] facts = [_.fact.as_json for _ in matches] show_markup(text, spans) show_json(facts) >>> , , : [[ ]] [[ ]]. , . 1"" - [[ ]], , - [[ ]], , , ! ! [ { "first": "", "middle": "", "last": "" }, { "first": "", "middle": "", "last": "" }, { "first": "", "middle": "", "last": "" }, { "first": "", "middle": "" } ]
2016年には、名前付きエンティティの抽出に関するfactRuEval-2016コンテストが開催されました。 参加者の中には、ABBYY、RCOの大企業がいました。 上位のソリューションには、名前が0.9以上のF1メジャーがありました。 ナターシャの結果はさらに悪い-0.78です。 問題は主に外国人の名前と複雑な姓にあります。たとえば、「村上春樹」、「...アフガニスタンの首長、ハミド・カルザイ」、「Ostap Bender meets Kisa Vorobyaninov ...」などです。 ロシア語の名前を持つテキストの場合、 品質は〜0.95です。 たとえば、学校のサイトから教師の名前を抽出し、レビューを集計できます。
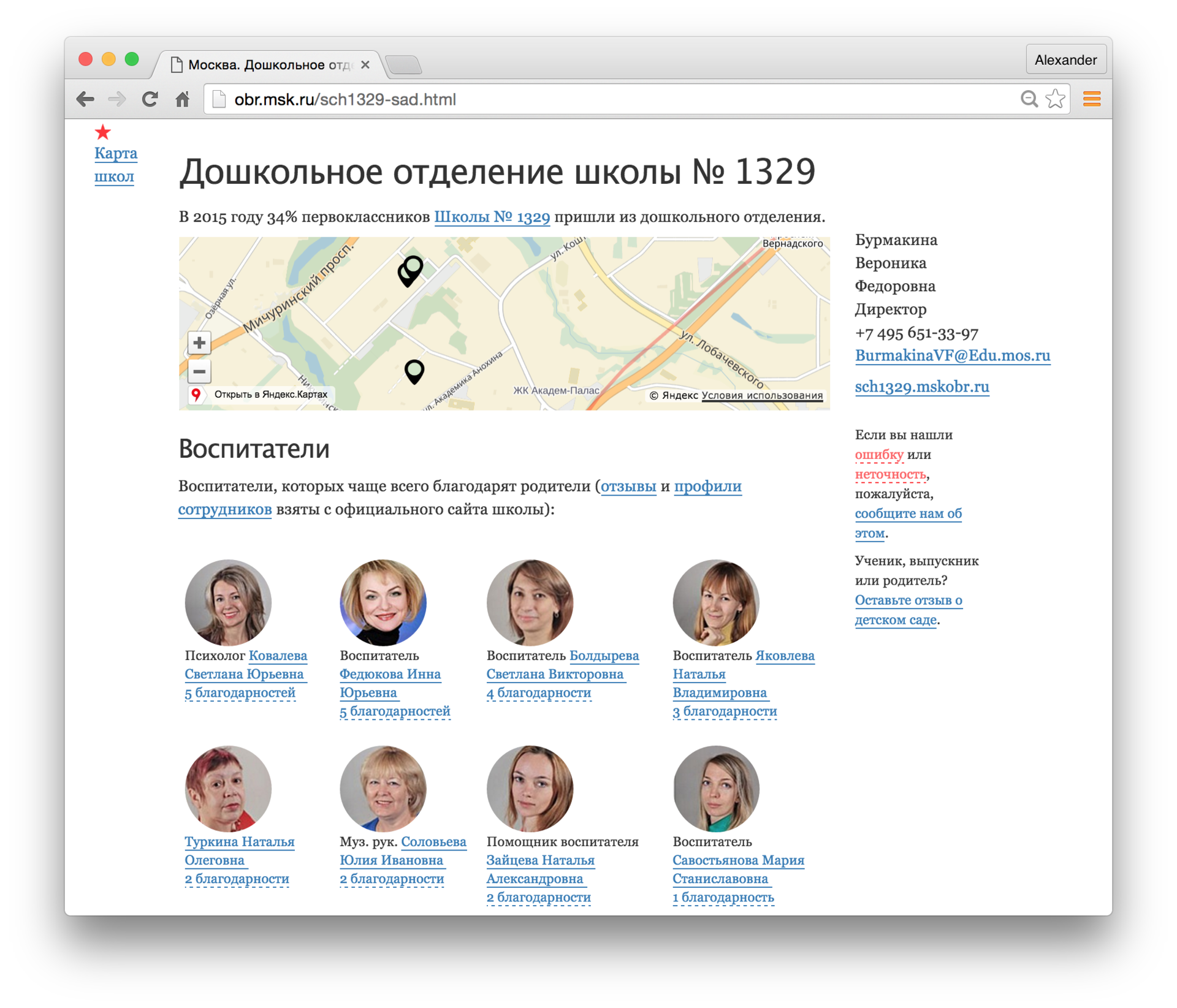
住所
インターフェイスは名前の場合と同じです
NamesExtractor
のみが
NamesExtractor
変更され
AddressExtractor
。
from natasha import AddressExtractor from natasha.markup import show_markup, show_json extractor = AddressExtractor() text = ''' №71 2. .51 ( : , ) . 7 881 574-10-02 ,.,. , .8 , 4 ''' matches = extractor(text) spans = [_.span for _ in matches] facts = [_.fact.as_json for _ in matches] show_markup(text, spans) show_json(facts) >>> №71 [[ 2]]. [[ .51]] ( : , ) . 7 881 574-10-02 [[ ,.,. , .8 , 4]] [ { "parts": [ { "name": "", "type": "" }, { "number": "2" } ] }, { "parts": [ { "name": "", "type": "" }, { "number": "51", "type": "" } ] }, { "parts": [ { "name": "", "type": "" }, { "name": "", "type": "" }, { "name": " ", "type": "" }, { "number": "8 ", "type": "" }, { "number": "4", "type": "" } ] } ]
factRuEval 2016では、参加者は名前、組織名、および地理的特徴を取得するように求められました。 私の知る限り、住所のある作業の質を評価するための独立したテストデータは存在しません。 数年間の作業で、「住所:443041 Samara、ul。」という形式の数十万行を蓄積してきました。 レーニンスキー、d.168 "、"イルクーツクの住所、聖 バイカルスカヤ、d。133、オフィス1(庭からの入り口)。 品質を評価するために、1000個のアドレスのランダムサンプルが作成され、結果が手動で確認され、 行の約90%が正しく処理されました 。 主に通りの名前で問題が発生します。たとえば、「g。 Volzhsk、2nd Industrial、p。2 "、" 111674、モスクワ、Dmitrievsky、d。17 "。
2017年、モスクワの復興の歴史と並行して、新しい土地利用と開発の規則(PPZ)が議論されました。 人口調査が実施されました。 100,000を超えるコメントが巨大なpdfファイルとして公開されています。 ニキータ・クズネツォフは、ナターシャの助けを借りて、言及されている住所を抽出し 、法律がサポートされている地域とそうでない地域を調べました。
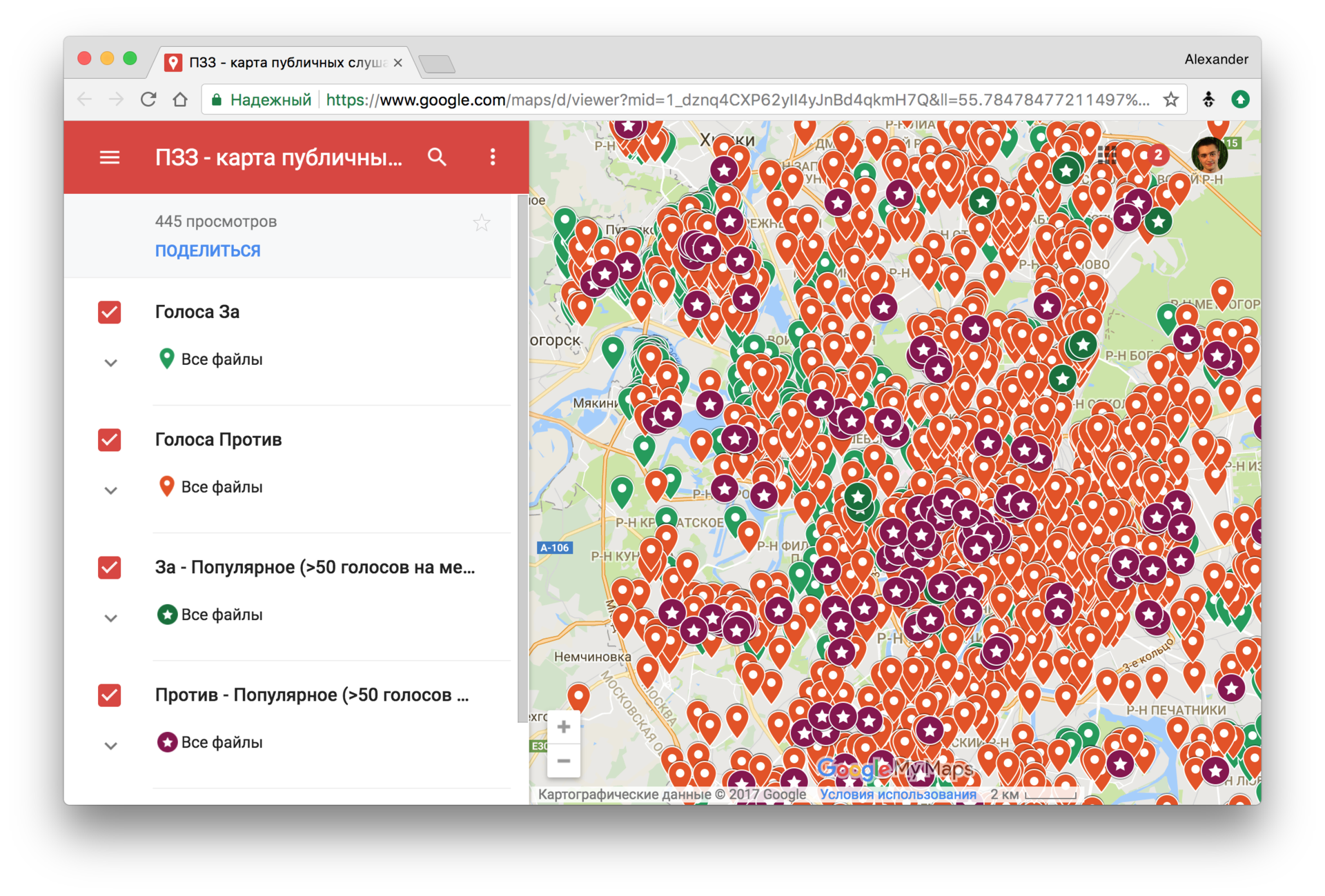
リポジトリ内のPPZに関するコメントを
AddressExtractor
して、データセットに対する
AddressExtractor
の作業の品質を視覚的に評価できます 。
その他の規則
ナターシャには日付とお金のルールもあります。 インターフェースは
AddressExtractor
および
NamesExtractor
と
NamesExtractor
です。
from natasha import ( NamesExtractor, AddressExtractor, DatesExtractor, MoneyExtractor ) from natasha.markup import show_markup, show_json extractors = [ NamesExtractor(), AddressExtractor(), DatesExtractor(), MoneyExtractor() ] text = ''' 10 1970 , -, . , 5/1 8 000 ( ) 00 ''' spans = [] facts = [] for extractor in extractors: matches = extractor(text) spans.extend(_.span for _ in matches) facts.extend(_.fact.as_json for _ in matches) show_markup(text, spans) show_json(facts) >>> [[ ]] [[10 1970 ]], [[ -, . , 5/1]][[]], 5/1 [[8 000 ( ) 00]] [ { "first": "", "middle": "", "last": "" }, { "last": "" }, { "parts": [ { "name": "-", "type": "" }, { "name": "", "type": "" }, { "number": "5/1", "type": "" } ] }, { "year": 1970, "month": 1, "day": 10 }, { "integer": 8000, "currency": "RUB", "coins": 0 } ]
ナターシャのインターフェースは非常にシンプルです
e = Extractor(); r = e(text); ...
e = Extractor(); r = e(text); ...
e = Extractor(); r = e(text); ...
ユーザーが使用できる設定はありません。 実際には、既成のルールでうまくいくことはまれです。 たとえば、ナターシャは日付「2017年4月21日」を解析しません。これは、規則が引用符で囲まれた日付を提供しないためです。 図書館は、通りの名前がないため、住所「Lyubertsy地区、Motyakovo村、d。61/2」を理解しません。
多くの場合、1レベル下に行き、既製のルールを追加して、独自のルールを作成する必要があります。 これにはYargyパーサーが使用されます。 ナターシャのすべてのルールが書かれています。 Yargyは複雑で興味深いライブラリです。この記事では、単純な使用例を検討します。
Yargyパーサー
Yargy-parserは、Python用のYandex Tomit -parserに類似しています。 エンティティを抽出するためのルールは、 コンテキストフリーの文法と辞書を使用して記述されます 。
文法
Yargyの文法は特別なDSLに記録されます。 したがって、たとえば、ISO形式(「2018-02-23」、「2015-12-31」)で日付を抽出するための簡単なルールは次のようになります。
from yargy import rule, and_, Parser from yargy.predicates import gte, lte DAY = and_( gte(1), lte(31) ) MONTH = and_( gte(1), lte(12) ) YEAR = and_( gte(1), lte(2018) ) DATE = rule( YEAR, '-', MONTH, '-', DAY ) parser = Parser(DATE) text = ''' 2018-02-23, 2015-12-31; 8 916 364-12-01''' for match in parser.findall(text): print(match.span, [_.value for _ in match.tokens]) >>> [1, 11) ['2018', '-', '02', '-', '23'] >>> [13, 23) ['2015', '-', '12', '-', '31'] >>> [33, 42) ['364', '-', '12', '-', '01']
それほど印象的ではありませんが、通常の
r'\d\d\d\d-\d\d-\d\d'
で同様の機能を得ることができますが、「1234-56-78」のようなゴミをマークします。
述語
上記の例の
gte
と
lte
は述語です。 多くの既製の述部 がパーサーに組み込まれています 。 独自のを追加することができます 。 Pymorphy2は 、単語の形態を決定するために使用されます。 たとえば、述語
gram('NOUN')
は名詞に対して機能し、
normalized('')
はすべての形式の単語 "January"をマークします。 「2014年1月8日」、「2001年6月15日」の形式の日付のルールを追加します。
from yargy import or_ from yargy.predicates import caseless, normalized, dictionary MONTHS = { '', '', '', '', '', '', '', '', '', '', '', '' } MONTH_NAME = dictionary(MONTHS) YEAR_WORDS = or_( rule(caseless(''), '.'), rule(normalized('')) ) DATE = or_( rule( YEAR, '-', MONTH, '-', DAY ), rule( DAY, MONTH_NAME, YEAR, YEAR_WORDS.optional() ) ) parser = Parser(DATE) text = ''' 8 2014 , 15 2001 ., 31 2018''' for match in parser.findall(text): print(match.span, [_.value for _ in match.tokens]) >>> [21, 36) ['15', '', '2001', '', '.'] >>> [1, 19) ['8', '', '2014', ''] >>> [38, 53) ['31', '', '2018']
解釈
通常、ファクトを含む部分文字列を見つけるだけでは十分ではありません。 たとえば、「ウラジミールプーチン大統領を代表して5月8日」というテキストの場合、パーサーは「5月8日」、「ウラジミールプーチン」だけでなく、
Date(month=5, day=8)
、
Name(first='', last='')
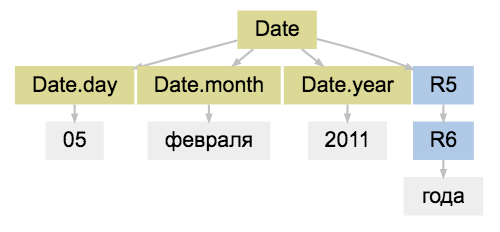
、このYargyは解釈手順を提供します。 パーサーの結果は、解析ツリーです。
match = parser.match('05 2011 ') match.tree.as_dot

(R0、R1-技術的なピーク、「R」は「ルール」の略)
解釈のために、ユーザーは
.interpretation(...)
メソッドを使用してタグツリーのノードを「ハングアップ」し
.interpretation(...)
。
from yargy.interpretation import fact Date = fact( 'Date', ['year', 'month', 'day'] ) DAY = and_( gte(1), lte(31) ).interpretation( Date.day ) MONTH = and_( gte(1), lte(12) ).interpretation( Date.month ) YEAR = and_( gte(1), lte(2018) ).interpretation( Date.year ) MONTH_NAME = dictionary( MONTHS ).interpretation( Date.month ) DATE = or_( rule(YEAR, '-', MONTH, '-', DAY), rule( DAY, MONTH_NAME, YEAR, YEAR_WORDS.optional() ) ).interpretation(Date) match = parser.match('05 2011 ') match.tree.as_dot
parser = Parser(DATE) text = '''8 2014 , 2018-12-01''' for match in parser.findall(text): print(match.fact) >>> Date(year='2018', month='12', day='01') >>> Date(year='2014', month='', day='8')
正規化
日付の例では、月、日、年の名前を数字にする必要があります。このため、正規化手順はYargyに組み込まれています。
.interpretation(...)
内
.interpretation(...)
ユーザーはフィールドを正規化する方法を示します。
from datetime import date Date = fact( 'Date', ['year', 'month', 'day'] ) class Date(Date): @property def as_datetime(self): return date(self.year, self.month, self.day) MONTHS = { '': 1, '': 2, '': 3, '': 4, '': 5, '': 6, '': 7, '': 8, '': 9, '': 10, '': 11, '': 12 } DAY = and_( gte(1), lte(31) ).interpretation( Date.day.custom(int) ) MONTH = and_( gte(1), lte(12) ).interpretation( Date.month.custom(int) ) YEAR = and_( gte(1), lte(2018) ).interpretation( Date.year.custom(int) ) MONTH_NAME = dictionary( MONTHS ).interpretation( Date.month.normalized().custom(MONTHS.__getitem__) ) DATE = or_( rule(YEAR, '-', MONTH, '-', DAY), rule( DAY, MONTH_NAME, YEAR, YEAR_WORDS.optional() ) ).interpretation(Date) parser = Parser(DATE) text = '''8 2014 , 2018-12-01''' for match in parser.findall(text): record = match.fact print(record, repr(record.as_datetime)) >>> Date(year=2018, month=12, day=1) datetime.date(2018, 12, 1) >>> Date(year=2014, month=1, day=8) datetime.date(2014, 1, 8) match = parser.match('31 2014 .') match.fact.as_datetime >>> ValueError: day is out of range for month
やっと 、 dateparserライブラリの機能の一部を繰り返しました。 たとえば日付のみなど、テキストから抽出する必要がある場合は、既製の専用ライブラリを選択する必要があります。 ソリューションはより速く動作し、品質はより高くなります。 Yargyは、大量の非標準タスクに必要です。
和解
名前を取得するための簡単なルールを検討してください。 pymorphy2を使用するOpencorpora辞書では、ラベルは
Name
で、名前はSurnラベルです。 名前をいくつかの単語
Name Surn
または
Surn Name
と見なします。
from yargy.predicates import gram Name = fact( 'Name', ['first', 'last'] ) FIRST = gram('Name').interpretation( Name.first.inflected() ) LAST = gram('Surn').interpretation( Name.last.inflected() ) NAME = or_( rule( FIRST, LAST ), rule( LAST, FIRST ) ).interpretation( Name )
このソリューションには2つの問題があります。
1.ルールは、さまざまなケースで名前と姓をマークします(「Ivanova Lesha」、「Petrova Roma」)
2.正規化後の女性の名前は男性になります
parser = Parser(NAME) text = ''' ... ... ... ... ''' for match in parser.findall(text): print(match.fact) >>> Name(first='', last='') >>> Name(first='', last='') >>> Name(first='', last='')
これらの問題を解決するために、Yargyには調整メカニズムがあります。
.match(...)
メソッドを使用して、ユーザーはルールの制限を指定します。
from yargy.relations import gnc_relation gnc = gnc_relation() # gender, number case (, ) Name = fact( 'Name', ['first', 'last'] ) FIRST = gram('Name').interpretation( Name.first.inflected() ).match(gnc) LAST = gram('Surn').interpretation( Name.last.inflected() ).match(gnc) NAME = or_( rule( FIRST, LAST ), rule( LAST, FIRST ) ).interpretation( Name ) parser = Parser(NAME) text = ''' ... ... ... ... ''' for match in parser.findall(text): print(match.fact) >>> Name(first='', last='') >>> Name(first='', last='')
長所と短所
Natashaは、MITのライセンスソリューションの下で、以前は一般に公開されていなかったソリューションを提供しています(またはそれらについては知りません)。 たとえば、構造化された名前と住所をロシア語のテキストから単純に取り出して抽出することが不可能になる前は、現在では可能です。 以前はPython用のTomitパーサーのようなものがありましたが、現在はそうです。
欠点を要約してみましょう。
- 手動で作成されたルール。
ナターシャは、ルールが事前に作成されたフレーズのみを解析します。 ルールを書くことは非現実的に思えるかもしれません。たとえば、フリーテキストの名前については、ルールがあまりにも異なっています。 実際には、すべてがそれほど悪くはありません:
- 1週間座ったとしても、名前の80%に対してルールを作成できます。
- 通常、任意のテキストではなく、 管理された自然言語のテキストで作業する必要があります。履歴書、判決、規制、連絡先のあるサイトのセクション。
- Yargyパーサーのルールでは、機械学習法で取得したマークアップを使用できます。
- 遅い速度。
最初に、YargyはEarleyパーサーアルゴリズムを実装します。その複雑さはO(n 3 )
。ここで、n
はトークンの数です。 コードは、最適化ではなく読みやすさに重点を置いて、純粋なPythonで書かれています。 要するに、ライブラリは遅いです。 たとえば、名前を抽出するタスクでは 、Natasha はTomitパーサーよりも10倍遅くなります 。 実際には、これで生きることができます:
- PyPyは大いに役立ちます。 加速は10倍で、平均は約3〜4倍です。
- 複数のマシン上の複数のスレッドで実行します。 タスクはよく似ており、レンタカーに簡単にアクセスできるようになりました。
- 標準ルールのエラー。
たとえば、ナターシャから名前を抽出する品質は、 SOTAからはほど遠いものです。 実際には、ライブラリはすぐに使用できる品質であるとは限りません;自分でルールを調整する必要があります。
コミュニティがルールの正確性と完全性の向上に役立つことを願っています。 バグレポートを書いて 、 pullrequestsを送ってください 。
参照資料
Githubのプロジェクトアドレスは単純です-github.com/natasha
インストール
pip install natasha
。 ライブラリは、Python 2.7、3.3、3.4、3.5、3.6、PyPyおよびPyPy3でテストされています。
標準ルールパッケージのドキュメントは短く、インターフェイスは非常にシンプルです-natasha.readthedocs.io 。 Yargyのドキュメントは、より大きくて複雑です-yargy.readthedocs.io 。 Yargyは興味深く、やりがいのあるツールです。おそらく既存のドキュメントでは十分ではありません。 HabréのYargyに関する一連のレッスンを公開したいという要望があります。 コメントにコメントを書くことができます。たとえば、次のトピックを取り上げます。
- 実行速度、大量のテキストの処理。
- 手動ルールと機械学習、ハイブリッドソリューション。
- さまざまな分野でのライブラリの使用例:履歴書の解析、製品名の解析、ボットのチャット。
Natashaのユーザーチャット-t.me/natural_language_processing そこで、ライブラリについて質問することができます。
標準ルールを示すスタンドはnatasha.github.io/demoです。 テキストを入力して、標準ルールがどのように機能するかを確認できます。
