もちろん、インターネットにとどまることができず、2018年にオスカーの勝者を予測するアイデアを思い出しました。その結果は3月4日にまもなく知られるでしょう。 このアイデアは1人の興味深い人物とのコミュニケーションで形成されたため、そのアイデアに感謝します。
私はデータセットの形成を台無しにしたくありませんでした、kaggleにもデータセットがありませんでしたが、私は何か変わった面白いことをしたかったのです。 タスクを修正しました。オスカーの受賞者について世論を判断するためですか?
しかし、最初は、映画業界で何が起こっているのか、誰が指名されているのかを把握する必要があります。
オスカーとは(バージョン20!8)
第90回アカデミー賞シネマアワード2017は、2018年3月4日にドルビーシアター(ハリウッド、ロサンゼルス)で開催されます。 コメディアンのジミーキンメルが2年連続でセレモニーを開催します。 候補者は2018年1月23日に発表されました( 興味のある方 )。
だから、すべてのノミネートは私にとって面白くないので、ノミネーションでの国民の注目を調べます:最高の映画、最高の俳優、最高の女優、最高のサウンドトラック。 リクエストの準備のためのデータを示します。
最優秀映画賞
- あなたの名前で電話してください
- 暗い時代
- ダンケルク
- オフ
- レディバード
- ファントムスレッド
- 秘密の関係書類
- 水の形
- ミズーリ州エビングの国境にある3つの看板
世論調査プラットフォームとしてのTwitter
ただし、最初にTwitter APIへのアクセスを提供する必要があります。
CONSUMER_KEY = '' CONSUMER_SECRET = '' OAUTH_TOKEN = '' OAUTH_TOKEN_SECRET = '' auth = twitter.oauth.OAuth(OAUTH_TOKEN, OAUTH_TOKEN_SECRET, CONSUMER_KEY, CONSUMER_SECRET) twitter_api = twitter.Twitter(auth=auth)
なぜなら データセットがありませんでした。Twitterで世論を評価するための基準を少し考えて策定する必要がありました。
1)現在配布されている(再送信された)メッセージを検索および処理する必要性。これにより世論、傾向の変化が判別されます。 これにはTwitter APIメソッドを使用します 。
tweet=twitter_api.search.tweets(q=(e1.get()), count="100") p = json.dumps(tweet) res2 = json.loads(p)
2)潜在的な配信を決定する必要性。つまり、現在10人のサブスクライバーがいます。25人のサブスクライバーを持つ2人のサブスクライバーをリツイートするメッセージを投稿しています。 T.について。 分布の数は2で、ポテンシャルは10 + 25 + 25 = 60です。
i=0 while i<len(res2['statuses']): tweet=str(i+1)+') '+str(res2['statuses'][i]['created_at'])+' '+(res2['statuses'][i]['text'])+'\n' retweet_count.append(res2['statuses'][i]['retweet_count']) followers_count.append(res2['statuses'][i]['user']['followers_count']) friends_count.append(res2['statuses'][i]['user']['friends_count']) print u' ', sum(retweet_count) print u' ', sum(followers_count)+sum(friends_count)
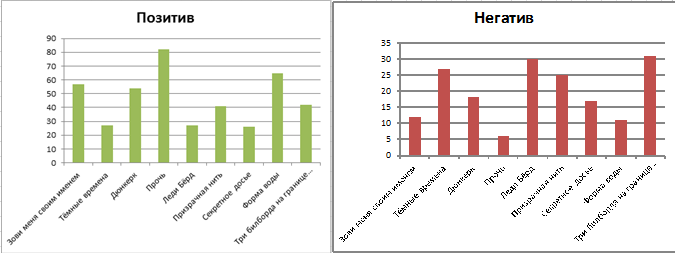
3)メッセージの調性、および肯定的から否定的な態度を判断する必要性。 このために、正と負の単語の2つの辞書を作成します。 ベイズの式(リンク)を使用して、メッセージの調性の条件付き確率を決定します。
def format_sentence(sent): return({word: True for word in nltk.word_tokenize(sent.decode('utf-8'))}) pos = [] with open("pos_tweets.txt") as f: for i in f: pos.append([format_sentence(i), 'pos']) neg = [] with open("neg_tweets.txt") as f: for i in f: neg.append([format_sentence(i), 'neg']) training = pos[:int((.8)*len(pos))] + neg[:int((.8)*len(neg))] test = pos[int((.8)*len(pos)):] + neg[int((.8)*len(neg)):] classifier = NaiveBayesClassifier.train(training) classifier.show_most_informative_features()
4)(オプション)メッセージ言語の定義。 異なる国では、映画の見方が異なります。 私たちはメンタリティに言及します。
stopwords = nltk.corpus.stopwords.words('english') en_stop = get_stop_words('en') stemmer = SnowballStemmer("english") #print stopwords[:10] total_word=[] lang=[] while i<len(res2['statuses']): lang.append(res2['statuses'][i]['lang']) w7=Label(window,text=u" ", font = "Times") w7.place(relx=0.65, rely=0.1) f = Figure(figsize=(6, 4)) a = f.add_subplot(111) t = Counter(lang).keys() y_pos = np.arange(len(t)) performance = Counter(lang).values() error = np.random.rand(len(t)) s = Counter(lang).values() a.barh(y_pos,s) a.set_yticks(y_pos) a.set_yticklabels(t) a.invert_yaxis() a.set_ylabel(u' ') a.set_xlabel(u'') canvas = FigureCanvasTkAgg(f, master=window) canvas.show() canvas.get_tk_widget().place(relx=0.52, rely=0.12)#pack(side=TOP, fill=BOTH, expand=1) canvas._tkcanvas.place(relx=0.52, rely=0.12)#pack(side=TOP, fill=BOTH, expand=1)
出力は図に示されています。
参照の配布
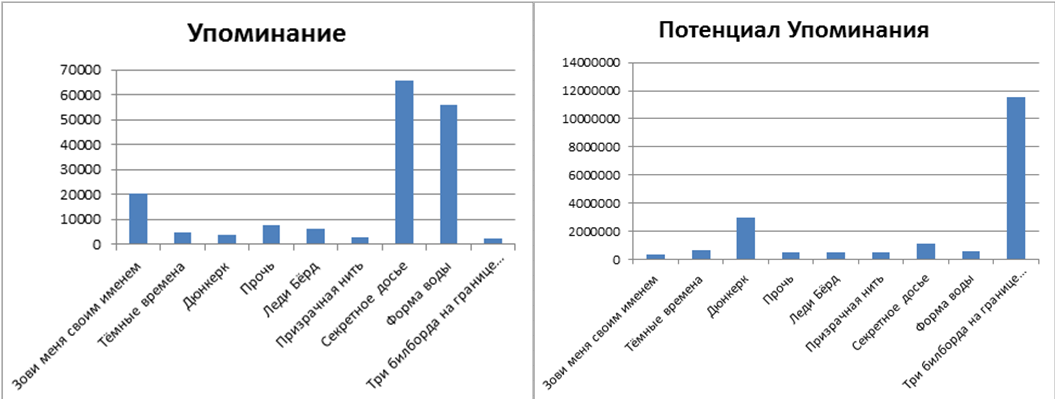
ノミネートされた映画に対するソーシャルネットワークTwitterのユーザーの態度
言語分布を表示します
つまり、彼らがどの映画をどの言語で(それぞれの国の)話しているかを調べます。
- あなたの名前で電話してください

- 暗い時代
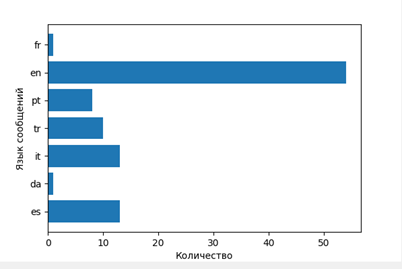
- ダンケルク
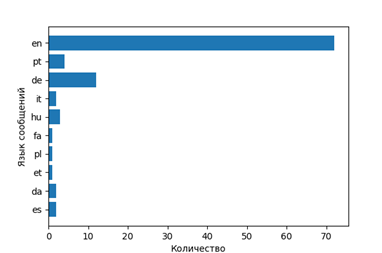
- オフ
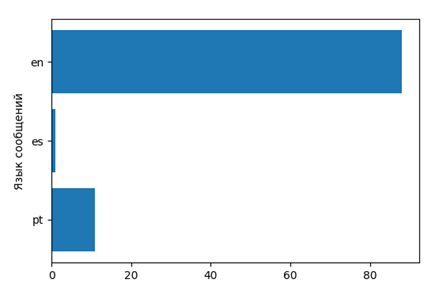
- レディバード
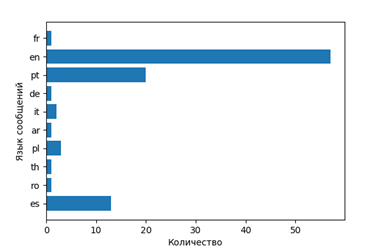
- ファントムスレッド
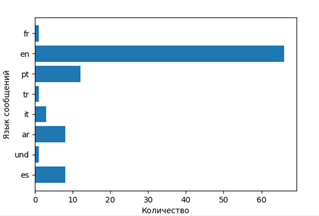
- 秘密の関係書類

- 水の形

- ミズーリ州エビングの国境にある3つの看板

ノミネートベストアクター
(表形式で表示)
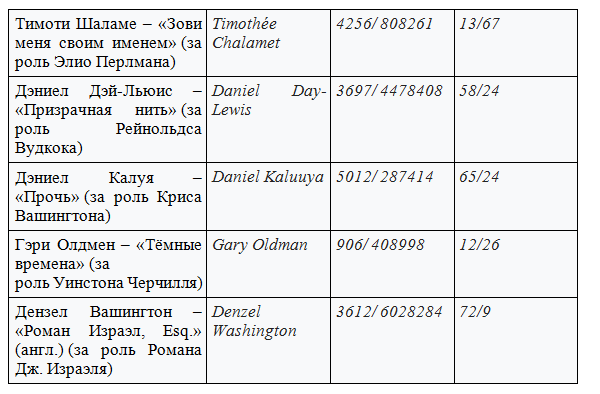
ノミネートベスト女優
(表形式で表示)
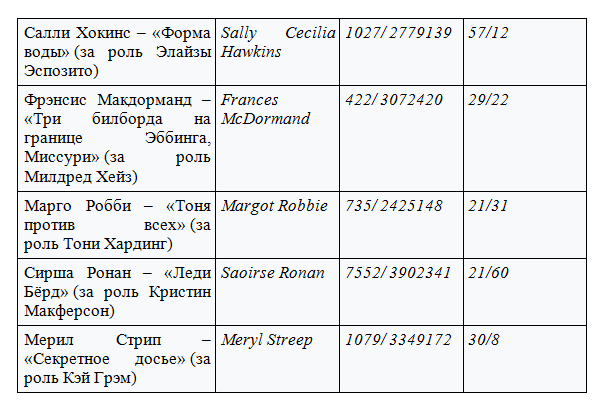
改善提案
もちろん、世論のこの「スライス」は、映画に対する態度を部分的にしか示すことができません。 より詳細な分析を行うには、特に情報行が表示される場合に、Twitterから中間時間にデータを収集する必要があります。 しかし、現時点では、世論の同情のリーダーは次のとおりです 。 水の形 。 夕方でも見たいと思います!
ソーシャルネットワークでは、視聴者を分析および分類することもできます。 キー定義モデルを学習するためのリポジトリと辞書へのリンク 。