「アリスの中に何があるか教えてあげましょう。」 アリスは大きく、彼女は多くのコンポーネントを持っているので、私は少し表面的に走ります。
アリスは、2017年10月10日にYandexによって開始された音声アシスタントです。 iOSおよびAndroidのYandexアプリケーション、モバイルブラウザー、およびWindows用の個別のアプリケーションに含まれています。 そこで、問題を解決し、対話形式で情報を見つけ、テキストまたは音声で情報を伝えることができます。 そして、RuNetでアリスを有名にしたキラー機能があります。 既知のシナリオだけを使用するのではありません。 何をすべきかわからないときは、ディープラーニングのすべての力を使用して、アリスに代わって回答を生成します。 それはかなり面白いことが判明し、誇大宣伝列車に乗ることができました。
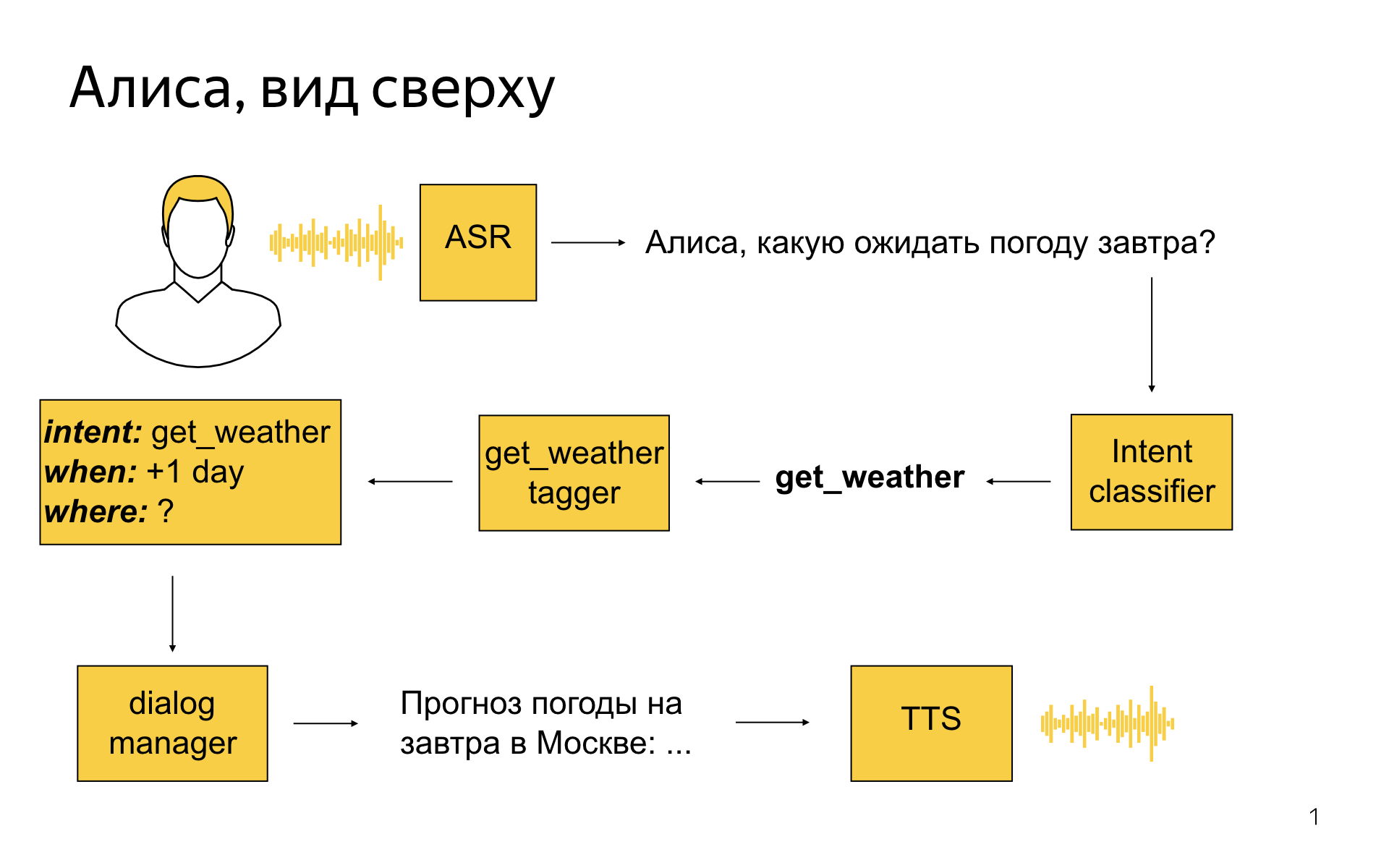
アリスは高レベルのように見えますか?
ユーザーは、「アリス、明日は天気はどうなるのか」と言います。
まず、スピーチを認識サーバーにストリーミングし、それをテキストに変換します。このテキストは、私のチームが開発しているサービス、意図の分類子などのエンティティに分類されます。 これは、ユーザーが自分のフレーズで何を言いたいかを判断することがタスクである、機械で訓練されたものです。 この例では、意図の分類子は次のように言うことができます:わかりました、おそらくユーザーは天気が必要です。
次に、各インテントに対して、セマンティックタガーと呼ばれる特別なモデルがあります。 モデルのタスクは、ユーザーが言ったことに役立つ情報を強調することです。 天気タガーは、明日がユーザーが天気を必要とする日付であると言うことができます。 そして、分析のこれらすべての結果を、フレームと呼ばれる構造化された表現に変換します。 それは意図的な天気であり、天気は現在の日から+ 1日間必要であり、どこが不明であると書かれています。 この情報はすべてダイアログマネージャーモジュールに分類され、これに加えて、ダイアログの現在のコンテキスト、この時点までに発生したことを認識します。 彼はレプリカを解析した結果を受け取り、それらをどうするかを決めなければなりません。 たとえば、彼はAPIにアクセスして、モスクワの明日の天気を調べることができます。ユーザーの地理的位置はモスクワであるためです。 そして言う-天気を説明するテキストを生成し、それを音声合成モジュールに送信します。音声合成モジュールは、アリスの美しい声でユーザーと話します。
ダイアログマネージャー。 機械学習、強化学習はなく、構成、スクリプト、ルールのみがあります。 予測どおりに機能し、必要に応じて変更する方法は明確です。 マネージャーが来て、変化を言ったら、すぐにそれをすることができます。
Dialog Managerの概念は、フォーム入力としてインタラクティブシステムに関係する人々に知られている概念に基づいています。 その発想は、発言のあるユーザーが何らかの仮想フォームに記入し、その中のすべての必須フィールドに記入すると、ユーザーのニーズを満たすことができるというものです。 イベント駆動型エンジン:ユーザーが何かをするたびに、サブスクライブしてPythonでハンドラーを記述し、ダイアログロジックを構築できるイベントがいくつか発生します。
スクリプトでフレーズを生成する必要がある場合-たとえば、ユーザーが天気について話していることを知り、天気について答える必要がある場合-これらのフレーズを作成できる強力なテンプレート言語があります。 これは見た目です。

これはささいなJinja2テンプレートエンジンのアドオンであり、あらゆる種類の言語ツールが追加されています。たとえば、単語を活用したり、数字や名詞を一致させたりして、一貫性のあるテキストを簡単に記述したり、テキストの一部をランダム化してアリスの音声のバリエーションを増やしたりできます

インテントの分類子では、ロジスティック回帰から勾配ブースティング、リカレントネットワークまで、さまざまなモデルを試すことができました。 その結果、他のモデルにはない優れたプロパティが多数あるため、最近傍に基づいた分類器を使用しました。
たとえば、多くの場合、インテントに対処する必要がありますが、その目的はほんの数例です。 このモードでは、通常のマルチクラス分類器を学習することはできません。 たとえば、5つしかないすべての例で、他の例にはない粒子「a」または「how」があり、分類子は最も単純な解決策を見つけます。 「方法」という単語が見つかった場合、これがまさにこの意図であると彼は判断します。 しかし、それはあなたが望むものではありません。 ユーザーがこの意図のために電車の中にあるフレーズに言ったことの意味的な近さを望みます。
その結果、2つのフレーズがどの程度意味的に近いかを示す大きなデータセットのメトリックを事前にトレーニングし、次にこのメトリックを使用して、トレーニングで最も近い隣人を探します。
このモデルのもう1つの優れた点は、すぐに更新できることです。 新しいフレーズがあり、アリスの行動がどのように変化するかを確認します。 必要なのは、最近傍の分類子に多くの潜在的な例を追加することだけです。モデル全体を再選択する必要はありません。 再帰モデルの場合、これには数時間かかったとします。 結果を確認するために何かを変更するとき、数時間待つことはあまり便利ではありません。

セマンティックタガー。 条件付きランダムフィールドとリカレントネットワークを試しました。 もちろん、ネットワークはより良く機能します;それは秘密ではありません。 そこにはユニークなアーキテクチャはありません。通常の双方向LSTMには注意が払われており、タグ付けタスクの最先端技術がプラスまたはマイナスされています。 誰もがそれを行い、私たちはそれを行います。
唯一のことは、N最良仮説を積極的に使用することです。最も可能性の高い仮説を必要としない場合があるため、最も可能性の高い仮説のみを生成しません。 たとえば、ダイアログマネージャーのダイアログの現在の状態に応じて、多くの場合、仮説を再評価します。
前のステップで何かについて質問したことがわかっている場合、タガーが何かを見つけたという仮説と、おそらく他のすべてのものが等しくないという仮説があり、おそらく最初のものがより可能性が高いです。 このようなトリックにより、品質をわずかに向上させることができます。
そして、機械で訓練されたタガーは時々間違えられ、スロットの意味はもっともらしい仮説で正確に見つけられません。 この場合、N-best仮説を検討しています。これは、スロットの種類について知っていることとより一致しており、これにより、さらに品質を高めることができます。
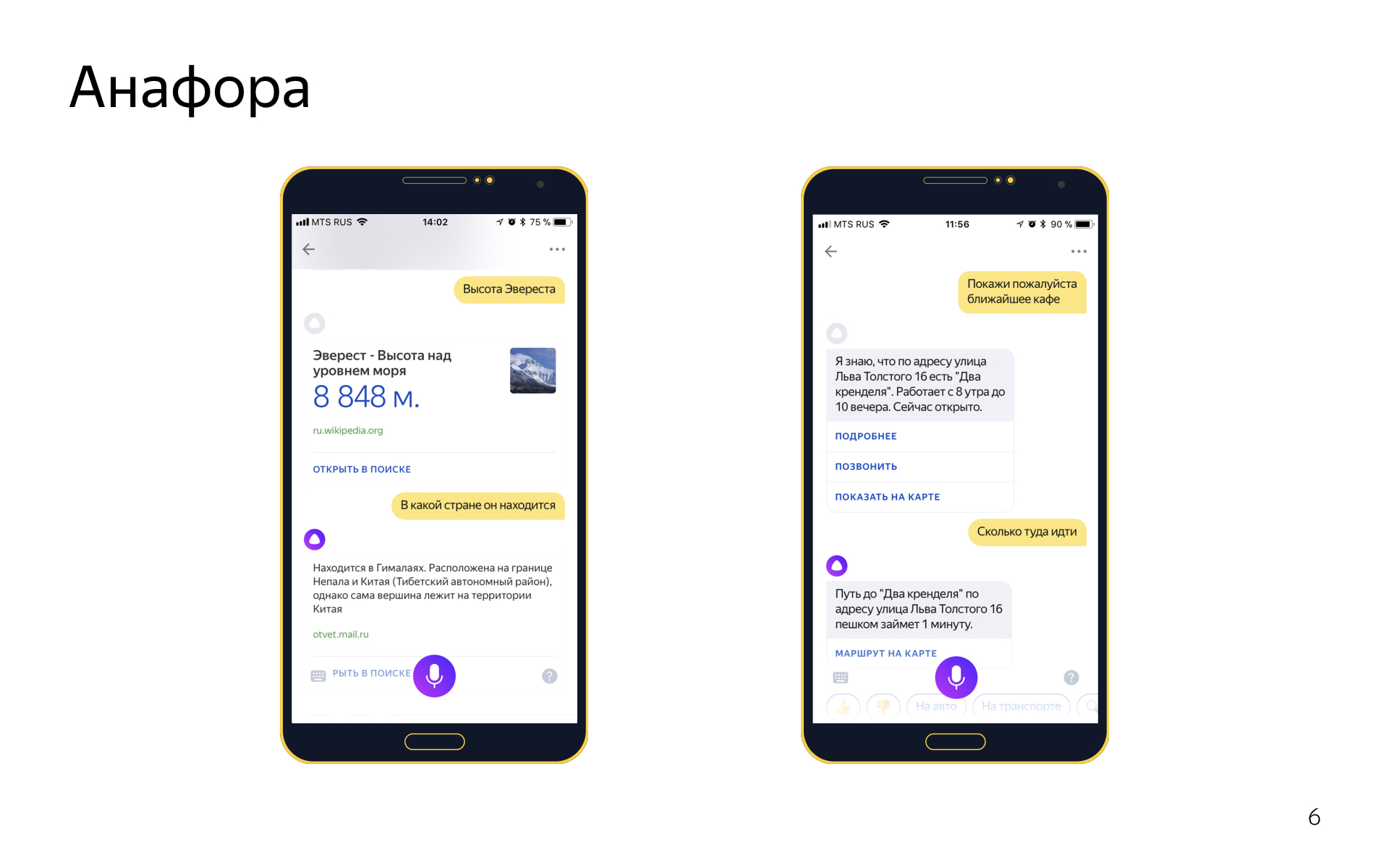
ダイアログでも、アナフォラというそのような現象があります。 これは、代名詞を使用して、以前にダイアログにあったオブジェクトを参照する場合です。 「エベレストの高さ」と言ってから、「それがどこの国にあるか」と言います。 照応を解決することができます。 このために、2つのシステムがあります。

任意のレプリカで実行できる1つの汎用システム。 すべてのユーザーレプリカの解析に加えて機能します。 現在のキューに代名詞が表示されている場合、彼が以前に言ったことで既知のフレーズを検索し、各フレーズの速度をカウントし、この代名詞に置き換えることができるかどうかを確認し、できれば最適なものを選択します。
また、フォーム入力に基づくアナフォア解決システムもあります。これは次のように機能します。以前のインテントにフォーム内にジオオブジェクトがあり、現在のオブジェクトにジオオブジェクト用のスロットがあり、それが満たされない場合、フレーズによって現在のインテントに到達します。 「そこ」という代名詞を使用すると、おそらく以前のジオオブジェクトをフォームからインポートして、ここで置き換えることができます。 これは単純なヒューリスティックですが、良い印象を与え、クールに動作します。 意図の一部で、1つのシステムが機能し、両方のシステムで機能します。 動作する場所、動作しない場所を確認し、柔軟にカスタマイズします。
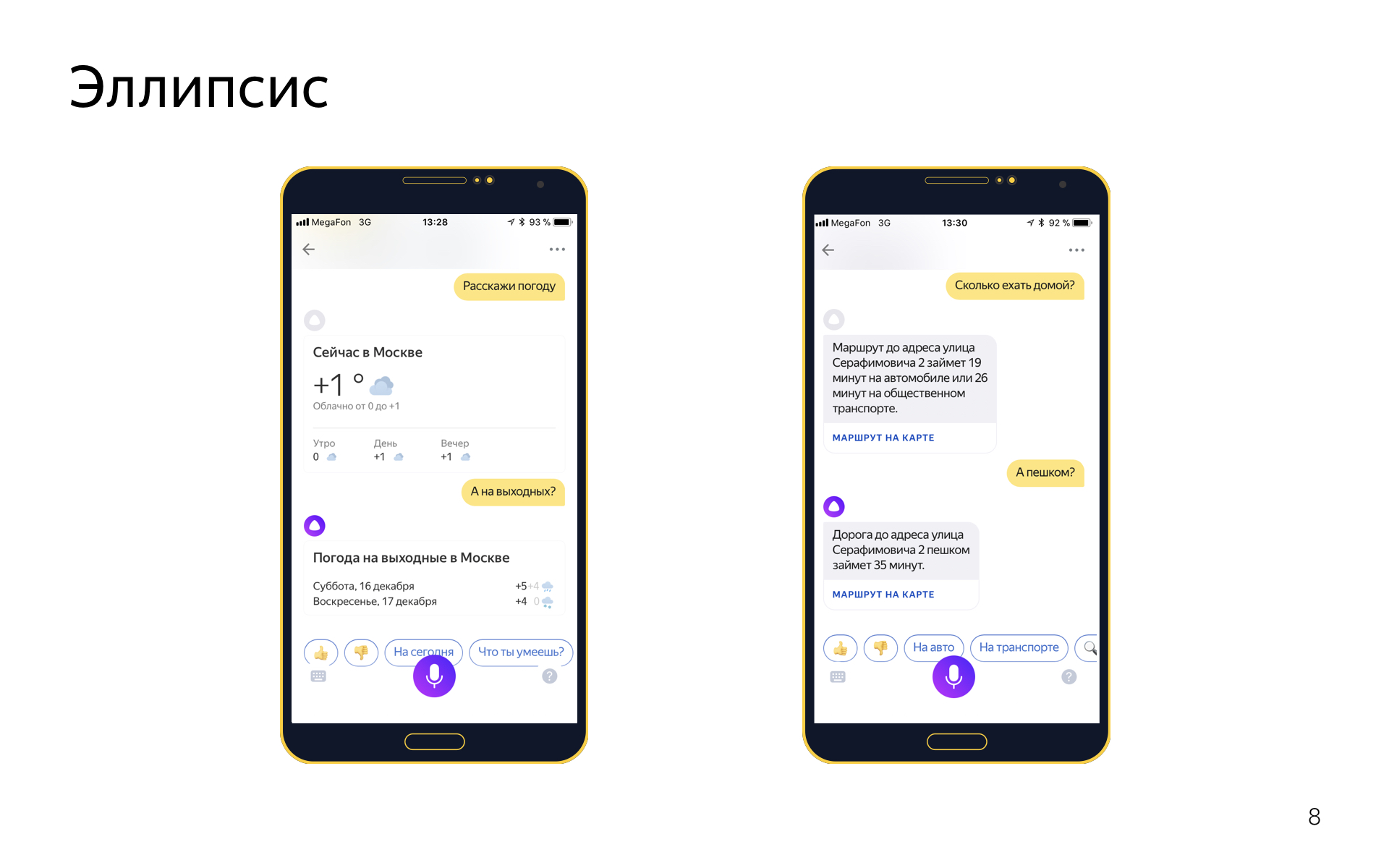
楕円があります。 これは、コンテキストから暗示されているため、ダイアログで一部の単語を省略した場合です。 たとえば、「天気を教えて」と言ってから、「週末に?」と言うと、「週末に天気を教えて」という意味になりますが、この言葉は役に立たないので繰り返したいと思っています。
楕円を使用すると、次のように作業する方法もわかります。 楕円または洗練されたフレーズは別の意図です。

「天気を伝える」、「今日の天気は何ですか」などのフレーズのget_weatherインテントがある場合、get_weather_ellipsisのペアのインテントがあり、あらゆる種類の天気の更新があります:「そして明日」、「そして週末」、およびソチにあるもの」など。 そして、インテントの分類子のこれらの楕円形のインテントは、親と同等の条件で競合します。 「モスクワで?」と言うと、たとえば、意図の分類子は、確率0.5では、これは天気の意図の改善であり、確率0.5では、組織を検索する意図の改善であると言います。 そして、対話エンジンは、現在の対話を考慮に入れて意図の分類子によって割り当てられたスコアによってリバランスされます。たとえば、彼は以前に天気に関する会話があったことを知っているため、これは組織の検索に関する説明ではなく、天気に関するものであった可能性が低いためです。
このアプローチにより、コンテキストなしで楕円を学習および定義できます。 以前に起こったことをせずにどこかから楕円形のフレーズの例を入力することができます。 これは、サービスのログにない新しいインテントを作成するときに非常に便利です。 空想するか、何かを発明するか、クラウドソーシングプラットフォームで長いダイアログを収集してみてください。 そして、そのような楕円形のフレーズの最初の繰り返しのために簡単に合成することができ、それらは何らかの形で機能し、ログを収集します。

これが私たちのコレクションの真珠です。私たちはそれを話者と呼びます。 これは、理解できない状況でアリスに代わって何かに応答し、アリスと頻繁に奇妙で頻繁に面白い対話を行うことができるのと同じニューラルネットワークです。

話し手は実際にはフォールバックです。 アリスでは、意図の分類子がユーザーが望むものを自信を持って決定できない場合、別のバイナリ分類子が最初に解決しようとします-これは検索クエリであり、検索に役立つものを見つけてそこに送信しますか? 分類子が「いいえ」と言った場合、これは検索クエリではなく、単なるおしゃべりであり、トーカへのフォールバックがトリガーされます。 トーカーは、ダイアログの現在のコンテキストを受け取るシステムであり、そのタスクは最も適切な応答を生成することです。 さらに、シナリオダイアログもコンテキストの一部になります。天気について話し、それから理解できないことを言った場合、話し手は動作します。

これにより、そのようなことができます。 あなたは天気について尋ねた後、話者はどういうわけかそれについてコメントしました。 動作すると、とてもクールに見えます。
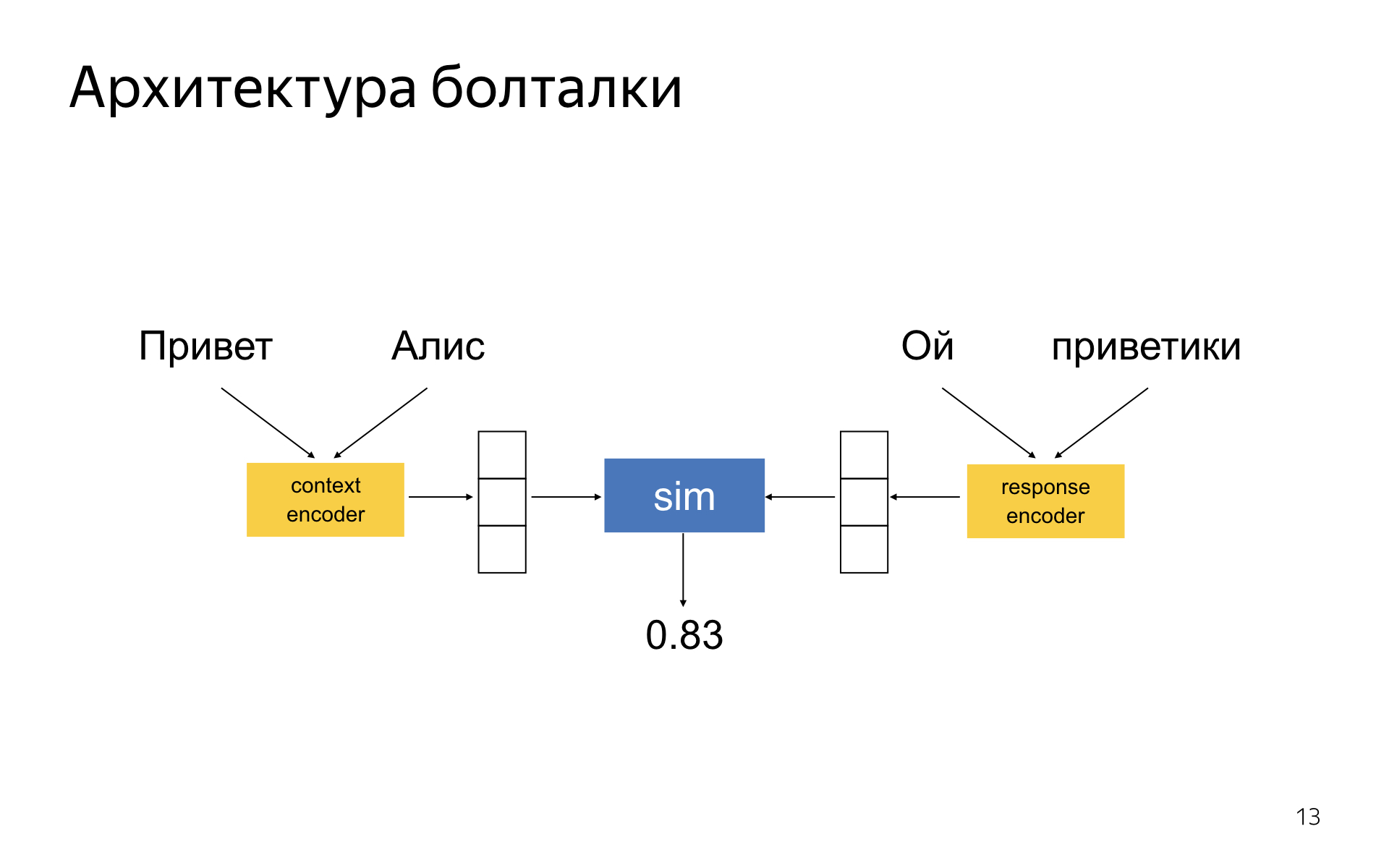
トーカーは、2つのエンコーダータワーがあるDSSMのようなニューラルネットワークです。 1つのエンコーダーはダイアログの現在のコンテキストをエンコードし、もう1つのエンコーダーは応答候補をエンコードします。 回答とコンテキストに対して2つの埋め込みベクトルを取得し、ネットワークはそれらの間の余弦距離が大きくなるほど学習します。コンテキスト内の指定された回答が適切であり、不適切であるほどです。 文献では、この考えは長い間知られていました。

なぜすべてが私たちにとって非常にうまく機能しているように見える-それは記事よりも少し良いように思えますか?
特効薬はありません。 急にクールなニューラルネットワークを作成する技術はありません。 私たちはどこでも少し勝ったので、良い品質を達成することができました。 私たちは、これらのタワーエンコーダーのアーキテクチャを長い間取り上げて、それらが最適に機能するようにしています。 トレーニングのネガティブな例については、適切なサンプリングスキームを選択することが非常に重要です。 インタラクティブなケースで学習する場合、そのようなコンテキストで誰かがかつて言ったポジティブな例しかありません。 しかし、否定的なものはありません-彼らは何らかの形でこの建物から生成される必要があります。 さまざまな手法があり、一部は他の手法よりも優れています。
上位候補者からどのように答えを選択するかが重要です。 モデルが提供する最も可能性の高い答えを選択できますが、これは常に最良の方法とは限りません。モデルをトレーニングするときに、製品の観点から存在する良い答えのすべての特性を考慮していなかったためです。
また、使用するデータセット、それらのフィルタリング方法も非常に重要です。

このすべての品質を少しずつ収集するためには、あなたが行うすべてを測定できなければなりません。 そして、ここで私たちの誇りは、ボタンによってクラウドソーシングプラットフォーム上のシステムの品質のすべての側面を測定できるという事実にあります。 結果を生成するための新しいアルゴリズムがある場合、数回クリックするだけで、特別なテストケースで新しいモデルの応答を生成できます。 そして-Tolokで得られたモデルの品質のあらゆる側面を測定します。 私たちが使用する主な指標は、文脈における回答の論理的関連性です。 この文脈とはまったく関係のないナンセンスな話をしないでください。
最適化を試みている追加のメトリックがいくつかあります。 これは、アリスがユーザーに「あなた」と呼びかけ、男性的な方法で自分のことを話し、あらゆる種類の無礼、汚物、愚かさを発音するときです。
高レベル、私は望んでいたすべてを語った。 ありがとう