こんにちは、Habr!
先日、Ren'Pyを使用して作成された1つのビジュアルノベルのリソースを取得したかった (はい、はい、同じ「Endless Summer」) 。 経験的に、それらはすべてarchive.rpaファイルに保存されていることがわかりました。 Githubで開梱用の既製のスクリプトを見つけましたが、Haskellが手伝ってくれるように自分で取得することにしました...
archive.rpa
まず、私たちが何を扱っているのか、つまり「アーカイブ」にリソースがどのように保存されているのかを把握しましょう。 dhexまたは同様のプログラムで開きます。
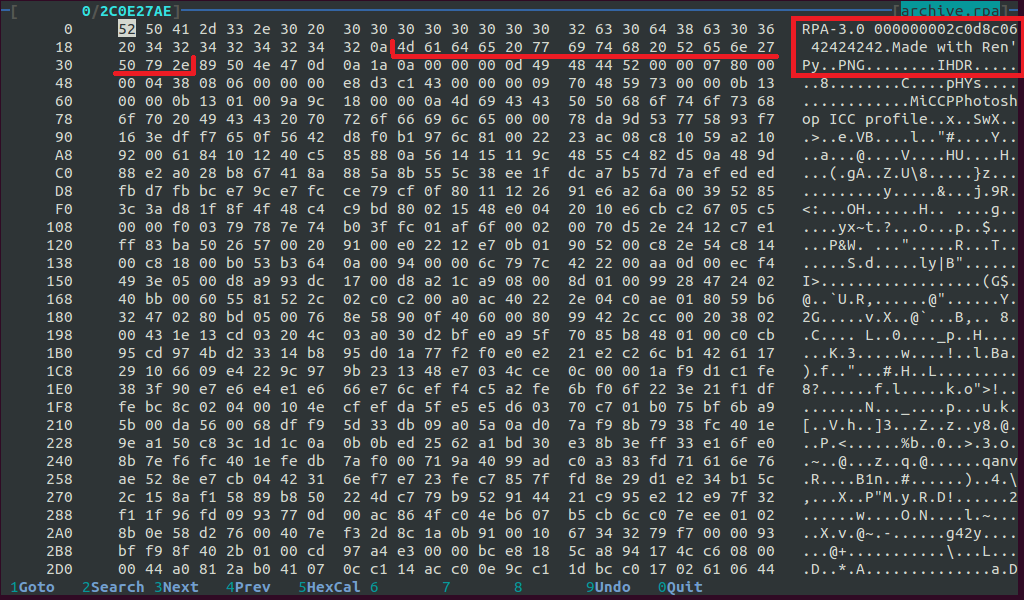
何が見えますか? まず、Ren'Pyに関するデータ、次に別のデータ、そしてPNGファイルの始まりです! ここにある!
最後のPNGまでスクロールします。
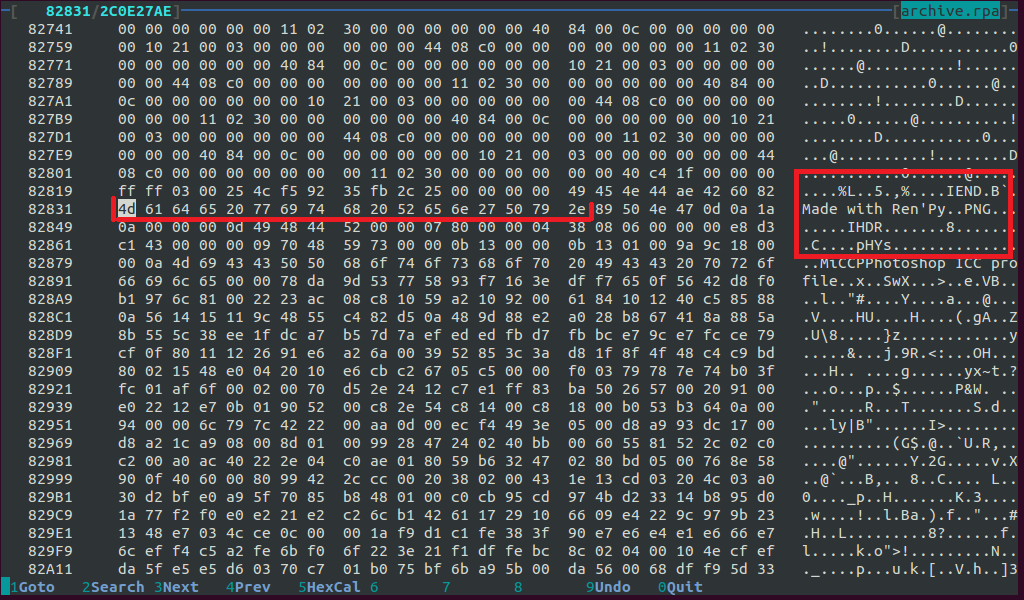
バイナリファイルのタイプは、その最初のバイト(いわゆる「マジックナンバー」)によって判別できます。 PNGマジックバイトは次のとおりです。8950 4e 47 0d 0a 1a 0a。 PNGファイルの末尾も常に同じです:49 45 4e 44 ae 42 60 82
他の形式の「マジックナンバー」のリストはこちらにあります。
うん! PNGは、バイト4d 61 64 65 20 77 69 74 68 20 52 65 6e 27 50 79 2e(ASCII: "Made with Ren'Py。")の後、その後-新しいPNGの始まり。 結論:.rpaアーカイブ内のリソースデータは、このバイトシーケンスで区切られています。 プログラムについて考える時間。
コードを書く
それでは、プログラムは正確に何をすべきでしょうか? ここにあります:
- ファイルを読む
- リソースファイルに分割する
- リソースファイルをユーザー定義フォルダーに書き込む
- 各ファイルに適切な拡張子を付けます
バラバラに
ファイル分割機能から始めましょう:
Extractor.hs:
module Extractor where import qualified Data.ByteString.Lazy as B import Data.List.Split extractRes :: B.ByteString -> [B.ByteString] extractRes bs = map B.pack $ splitOn magicSep $ B.unpack bs magicSep = [0x4d, 0x61, 0x64, 0x65, 0x20, 0x77, 0x69, 0x74, 0x68, 0x20, 0x52, 0x65, 0x6e, 0x27, 0x50, 0x79, 0x2e]
ここで、 magicSep
はリソースファイルを共有する同じ「マジック」バイトです。 extractRes
関数は、バイトの文字列をextractRes
してリストに変換し、ファイルのバイトのリストに分割します。これらの各リストは、バイトの文字列に変換されます。 1つの質問が残っています。なぜ遅延バイトを使用したのですか? すぐに回答が届きます。
拡張機能をインストールする
ExtensionId.hs:
module ExtensionId where import qualified Data.ByteString.Lazy as B import Data.List (isPrefixOf) import System.Directory type FileType = String readExtension :: FilePath -> IO (Maybe FileType) readExtension path = B.readFile path >>= (return . getExtension) writeExtension :: FilePath -> Maybe FileType -> IO () writeExtension _ Nothing = return () writeExtension path (Just ext) = renameFile path $ path ++ ext getExtension :: B.ByteString -> Maybe FileType getExtension = magicLookup magicMap magicLookup :: [(B.ByteString, FileType)] -> B.ByteString -> Maybe FileType magicLookup [] _ = Nothing magicLookup ((magic, fileType) : rest) bytes | (B.unpack magic) `isPrefixOf` (B.unpack bytes) = Just fileType | otherwise = magicLookup rest bytes magicMap = [(pngMagic, ".png"), (jpgMagic, ".jpg"), (oggMagic, ".ogg")] pngMagic = B.pack [0x89, 0x50, 0x4e, 0x47] jpgMagic = B.pack [0xff, 0xd8, 0xff] oggMagic = B.pack [0x4f, 0x67, 0x67, 0x53]
ここには、 readExtension
とwriteExtension
2つの主要な関数があります。 ファイルの最初のバイトを読み取り、それに基づいて拡張子を設定し、2番目のファイルがそれに応じてファイルの名前を変更すると推測するのは簡単です。 magicLookup
関数は、既知の「マジックナンバー」のリストを単純に調べ、それらをファイルの先頭と比較するだけで、拡張子を決定するという汚い作業をすべて行います。 magicMap
はバイトと拡張子の対応のリストですpngMagic
、 jpgMagic
およびoggMagic
はファイル形式のマジックナンバーです。 それらのリストは読者が拡張することができますが、これらのフォーマットを除いて、アーカイブには何も見つからないことは確かでした。
Ufff ...
親愛なるMain.hsのまま:
module Main where import qualified Data.ByteString.Lazy as B import System.Environment import System.Directory import System.FilePath import System.IO import ExtensionId import Extractor main :: IO () main = do args <- getArgs if (length args) /= 2 then usage else extractToFolder (args !! 0) (args !! 1) extractToFolder :: FilePath -> FilePath -> IO () extractToFolder input output = do b <- doesFileExist input if b then do b <- doesDirectoryExist output if b then do c <- confirm $ "Folder " ++ output ++ " already exists, overwrite it? (y/n): " if c then do removeDirectoryRecursive output createDirectory output extractToFolder' input output else return () else extractToFolder' input output else putStrLn $ "Input file " ++ input ++ " does not exist" extractToFolder' :: FilePath -> FilePath -> IO () extractToFolder' input output = do bytes <- B.readFile input let bs = extractRes bytes doNastyWork bs 0 where doNastyWork [] _ = putStrLn "Done." doNastyWork (bs : rest) n = do let path = output </> ("extraction_" ++ (show n)) B.writeFile path bs ext <- readExtension path writeExtension path ext putStrLn $ (show $ n + 1) ++ " files processed..." doNastyWork rest (n + 1) confirm :: String -> IO Bool confirm q = do putStr q hFlush stdout line <- getLine case head line of 'y' -> return True 'n' -> return False _ -> confirm q usage :: IO () usage = putStrLn "Usage: extractrpa [ARCHIVE] [OUTPUT FOLDER]"
ここは何ですか? main
関数は単に引数の数をチェックし、2つある場合、ダーティーな作業を委任します (あまりきれいではない) extractToFolder
関数、それ以外の場合は送信 喫煙マニュアル usage
読みください。
同じことextractToFolder
します。入力が正しいことを確認し(愚か者に対する保護)、出力するフォルダーが存在しないか、ユーザーがその内容を破棄することに同意した場合、彼はextractToFolder'
を呼び出します
他の言語では、データ処理方法はほぼ次のとおりです。すべてのデータを読み取り、それらを断片に分割した後、それぞれをファイルに書き込み、拡張子を付けます。 Haskellは、少し異なるアプローチを提供します。データが到着したときに処理します。 これは、遅延計算のおかげで可能です(だからこそ、遅延バイト文字列を使用しました)。 このアプローチにより、ユーザーは処理プロセスをよりよく見ることができますが、これはすでに悪くはありません。 extractToFolder'
は、アーカイブが処理される一種のコンベヤーです。ファイルを読み取り、パーツに分割し、パーツがなくなるまで、一意の名前でファイルに書き込みます。
それですべてです。ターミナルで大事なコマンドを入力します。
$ ghc --make Main.hs -o extractrpa ... $ extractrpa archive.rpa archive ... Done.
そして楽しむ 賢く恥ずかしがり屋 巧妙にマイニングされたコンテンツ!
質問、苦情、提案-コメントしてください!