何、どう、なぜ
フォーラムMista.ruは、1C専用の最も古く、最もアクティブなフォーラムの1つです。 最初のメッセージは2000年で、現在トピックカウンターは800,000を超え、メッセージの数は16,000,000を超えています。フォーラムは非常に人気があり、1Cの質疑応答のベースが含まれていたため、「ミラーリング」を試みました。フォーラム管理者が「ダウンロード保護」を追加しました。 この記事では、Google Cloud Platformを使用して、この(およびおそらく他の)フォーラムを比較的短時間でダウンロードする方法について説明します。
イントロ
興味深い(私の意見では) データセットを取得するための以前のミニプロジェクトの後、データエンジニアとして自分のスキルをトレーニングできる別の興味深いタスクが必要でした。 目標として、私は青年向けのMines.ru 広告フォーラムを選択し、いくつかの理由ですぐにそれを行いました。 まず、これはかなり古いフォーラムであり、長年にわたってさまざまなトピックに関する何百万もの投稿を蓄積してきました。 第二に、1Cプログラマーの間で最も人気のあるものの1つであり(少なくとも6〜7年前)、その活動は非常に高いです。 第三に、フォーラムユーザーの99.99%が現在の大統領の支持者であり、「頑固な言語的愛国者」の集中がちょうど転がり、これは、たとえば、有名な単語「###」、「プーチン」の使用頻度など、非常に興味深い分析を得る希望を与えますまたは「Putin ###」。 そして第四に、「保護」のおかげで、フォーラムをダウンロードするタスクがもう少し面白くなってきました。
つかみスクリプト
前のプロジェクトから残した既存のツールを使用してタスクにアプローチする最初の試みは失敗しました。 20回のGETリクエストの後、フォーラムは応答しなくなりました。 ウェブバックエンドでは強力ではありませんが、1つのIPからの頻繁なリクエストが監視されており、通常のユーザーからのリクエストのように見えるものはすべて禁止されていると思われます。 多数のソートされたダウンロードとグラバーサイトが同じレーキに出会い、バスケットに行きました。 新鮮なアイデアが必要でした。
そして彼女は見つかりました。 部分的に完了したRuby-on-Railsコースでは、ユーザーの動作をエンコードし、これらのエミュレータスクリプトをテストケースに使用できる自動テスト用のツールがあると聞きました。 セレンという言葉を思い出してグーグルを使用して、私はすぐに小さな例を見つけましたが、わずかなニュアンスがありました-それらはPython上にあり、私の武器には1CとRしかありませんでした。しかし、Pythonは数時間後に学ぶのが最も簡単なものの1つと考えられているすでにフォーラムにログインできました。
import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait driver = webdriver.Chrome("/usr/local/bin/chromedriver") base_url = 'http://www.forum.mista.ru/' driver.get(base_url) username = " " password = "11" uname = driver.find_element_by_name("user_name") uname.send_keys(username.decode('utf-8')) passw = driver.find_element_by_name("user_password") passw.send_keys(password) submit_button = driver.find_element_by_class_name("sendbutton").click()
そして、(かなり長い間言わなければならない)時間の後でも、そのようなMistaDownloaderクラスが登場し、初期化直後にフォーラムにログインし、その番号でフォーラムスレッドをダウンロードすることができました:
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 import base64 import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from bs4 import BeautifulSoup from urllib import quote import sys import codecs import binascii import os import datetime import subprocess import syslog reload(sys) sys.setdefaultencoding("utf-8") syslog.syslog("MistaDownloader class loaded.") print ("MistaDownloader class loaded.") class MistaDownloader: def print_to_log(self, message): syslog.syslog(message) print (message) def __init__(self): self.print_to_log("MistaDownloader initializing...") self.driver = webdriver.Chrome("/usr/local/bin/chromedriver") self.base_url = 'http://www.forum.mista.ru/' self.folder = '//home/gomista/files' if not os.path.exists(self.folder): os.makedirs(self.folder) self.print_to_log("MistaDownloader initialized.") def authenticate(self): self.driver.get(self.base_url) username = " " password = "11" uname = self.driver.find_element_by_name("user_name") uname.send_keys(username.decode('utf-8')) passw = self.driver.find_element_by_name("user_password") passw.send_keys(password) submit_button = self.driver.find_element_by_class_name("sendbutton") .click() self.print_to_log("Authentication done.") def download_by_id(self, topic_id): self.print_to_log("ID: " + topic_id) def write_source_to_file(topic_id, page_number, page_url, page_source, folder): filename = folder + '/' + '{0:0>7}'.format(topic_id) + '_' + '{0:0>2}'.format(page_number) + '_' + binascii.hexlify(page_url) + '.txt' file = open(filename,'w') page_source_to_save = page_source.replace('\t', ' ') .replace('\n', ' ') .replace('\r', ' ') res = '%s\t%s\t%s\t%s' % (topic_id, page_number, page_url, page_source_to_save) file.write(res) file.close() page_number = 1 current_url = '%s%s%s%s%s' % (self.base_url, 'topic.php?id=', topic_id, '&page=', page_number) self.print_to_log('getting page: ' + current_url) self.driver.set_page_load_timeout(240) try: self.driver.get(current_url) self.print_to_log('done') html = self.driver.page_source write_source_to_file(topic_id, page_number, current_url, html, self.folder) soup = BeautifulSoup(html, "lxml") pages_tag = soup.find('span', { 'class' : 'pages' }) additional_pages = set() if pages_tag: pages_tag = pages_tag.findAll('a', attrs = {'data-page' : True}) if pages_tag: for page_tag in pages_tag: additional_pages.add(page_tag['data-page']) additional_pages = list(sorted(additional_pages)) for additional_page in additional_pages: current_url = '%s%s%s%s%s' % (self.base_url, 'topic.php?id=', topic_id, '&page=', additional_page) self.print_to_log('getting page: '+current_url) self.driver.set_page_load_timeout(240) self.driver.get(current_url) self.print_to_log('done') html = self.driver.page_source write_source_to_file(topic_id, additional_page, current_url, html, self.folder) except Exception as e: write_source_to_file(topic_id, page_number, current_url, 'ERRORERRORERROR', self.folder)
ページ自体は、次の行を使用してダウンロードできます。
do = MistaDownloader() do.authenticate() topic_id = 1 do.download_by_id(topic_id) ... topic_id = 99 do.download_by_id(topic_id)
さらに、このスクリプトをデスクトップだけでなく、グラフィカルインターフェイスのないサーバーでも実行することを望みました。 これを行うために、Googleの助けを借りて、エミュレータの助けを借りてどこでも起動できる次のバージョンのスクリプトが生まれました。
from xvfbwrapper import Xvfb from mista_downloader import MistaDownloader vdisplay = Xvfb() vdisplay.start() do = MistaDownloader() ... vdisplay.stop()
そして今、1から1,000,000のサイクルを開始するのに十分であるように見えました(現在、すべての新しいブランチは811 1000を少し超えるインデックスで作成されています)。 しかし...予備的な測定では、喫煙は約2〜3週間かかり、フォーラム全体はハードドライブ上のファイルの形になることが示唆されました。 はい、実証済みの方法で自分のラップトップで複数のスレッドで実行することができましたが、最近、データエンジニア向けGoogle Cloud Platformコースを見ると新しいアイデアが提案されました。
並行して
Google Cloud Platformでは、タスクに対処した後、1分以内に仮想サーバーを作成し、すぐに削除できます。 すなわち アイデアによれば、1台の強力なサーバーを探して1週間動作させる必要はありませんでした。たとえば、10台の単純なサーバーを20台レンタルする方が簡単でした。 また、Hadoop、HDFS、MapReduceなどのコースも見ていたため、ブラックジャックとノードで独自のクラスターを作成することにしました。
クラスターの本質は、ダウンロードする必要があるリンクのリスト(つまり、フォーラムトピックのID)が含まれる中央サーバー(マスター)です。 稼働中のサーバー(ノード)、ウィザードに接続し、IDの一部を受け取り、それらをダウンロードし、受け取ったファイルをGCS(Google Cloud Storage)に追加し、タスクが完了したことをウィザードに通知し、IDの新しい部分を受け取ります。
Google Cloud Platformには非常に便利なものがあります-Google Cloud Shellです。 これは、ブラウザからいつでもアクセスできる小さな無料の仮想マシンであり、その助けを借りてクラウド全体を管理できます。 Webインターフェースを介したほぼすべてのアクションには、Google Cloud Shellを使用して実行できる同様のコマンドがあります。 記事の後半のすべてのスクリプトは、それを通して起動されます。
次のスクリプトを使用して、 cserver
という名前の仮想マシンを作成しました。
#! /bin/bash gcloud compute --project "new-mista-project" instances create cserver \ --zone "europe-west1-b" \ --machine-type "n1-standard-2" \ --subnet "default" \ --metadata-from-file startup-script=startupscript_server.sh \ --metadata "ssh-keys=gomista:ssh-rsa key-key-key gomista" \ --maintenance-policy "MIGRATE" \ --service-account "1007343160266-compute@developer.gserviceaccount.com" \ --scopes "https://www.googleapis.com/auth/cloud-platform" \ --min-cpu-platform "Automatic" \ --image "image-mista-node" \ --image-project "new-mista-project" \ --boot-disk-size "10" \ --boot-disk-type "pd-standard" \ --boot-disk-device-name cserver gcloud compute instances add-tags cserver --tags 'mysql-server' --zone \ "europe-west1-b"
これは、タイプn1-standard-2
サーバーであり、実際には2CPU 7.5Gbを意味します。 ハードドライブとして-10Gb標準ディスク。 ちなみに、楽しみ48.95 per month estimated. Effective hourly rate $0.067 (730 hours per month)
48.95 per month estimated. Effective hourly rate $0.067 (730 hours per month)
、つまり そのようなサーバーを使用するのに1時間は4ルーブル、1日は100ルーブル未満です。
サーバーは、ライブラリとアプリケーションがインストールされた、事前に準備されたUbuntu 16.04 LTSのイメージに基づいて作成されました。 実際、サーバーはベアUbuntuから作成することもでき、必要なすべてのプログラムを再インストールするコマンドを--metadata-from-file
パラメーターで渡す必要があります。たとえば、 sudo apt-get install xvfb x11-xkb-utils -y
ます。 転送されたコマンドまたはスクリプトは、VMの作成後すぐに起動され、必要なものがすべてインストールされます。 しかし、私はこのマシンを何度も作成/削除することを知っていたので、余分な10分間を費やしてイメージを準備することにしました(GCPを使用)。 また、サーバーの作成時に、startupscript_server.shスクリプトがstartupscript_server.sh
れstartupscript_server.sh
。これにより、リポジトリがコピーされ、スクリプトがcrontabに追加され、タスクがNodamに分散されました。
このスクリプトを使用してノードを作成しました。
#! /bin/bash gcloud compute --project "new-mista-project" instances create $1 \ --zone $2 \ --machine-type "n1-standard-1" \ --subnet "default" \ --metadata-from-file startup-script=startupscript.sh \ --metadata "ssh-keys=gomista:ssh-rsa key-keykey gomista" \ --no-restart-on-failure \ --maintenance-policy "TERMINATE" \ --preemptible \ --service-account "1007343160266-compute@developer.gserviceaccount.com" \ --scopes "https://www.googleapis.com/auth/cloud-platform" \ --min-cpu-platform "Automatic" \ --image "image-mista-node" \ --image-project "new-mista-project" \ --boot-disk-size "10" \ --boot-disk-type "pd-standard" \ --boot-disk-device-name $1 gcloud compute instances add-tags $1 --tags 'mysql-client' --zone $2
ノードはサーバーn1-standard-1
(1CPU 3.75Gb)であったため。--preemptible
とウィザードの主な違いは、--preemptible
パラメーターです。 このフラグを使用してサーバーを作成すると、このサーバーはいつでもGoogleによって強制的にオフにでき、サーバーの最大稼働時間は24時間になります。 そのようなサーバーをレンタルし、そのような条件に同意すると、Googleはその価格を月あたり24.67から月あたり7.70(1時間あたり0.011ドル)に引き下げます。これは1日あたり15ルーブルをわずかに超えます。 そして、「バッチジョブとフォールトトレラントワークロード用」のマシンが数ダース必要だったので、プリエンプティブマシンが良い選択肢になりました。 ところで、サーバーにタグを追加するために、この方法でサーバーにファイアウォールルールを追加しました(以前はこれらのタグに関連付けていました)。
1つのチームで20台の仮想マシンを作成し、1分で使用できるようにしますか お願い:
#! /bin/bash ./create_node_west.sh node01 europe-west1-b & ./create_node_west.sh node02 europe-west1-b & ./create_node_west.sh node03 europe-west1-b & ./create_node_west.sh node04 europe-west1-b & ./create_node_west.sh node05 europe-west1-b & ./create_node_west.sh node06 europe-west1-b & ./create_node_west.sh node07 europe-west2-b & ./create_node_west.sh node08 europe-west2-b & ./create_node_west.sh node09 europe-west2-b & ./create_node_west.sh node10 europe-west2-b & ./create_node_west.sh node11 europe-west2-b & ./create_node_west.sh node12 europe-west2-b & ./create_node_west.sh node13 europe-west2-b & ./create_node_west.sh node14 europe-west3-b & ./create_node_west.sh node15 europe-west3-b & ./create_node_west.sh node16 europe-west3-b & ./create_node_west.sh node17 europe-west3-b & ./create_node_west.sh node18 europe-west3-b & ./create_node_west.sh node19 europe-west3-b & ./create_node_west.sh node20 europe-west3-b &
ブラックジャックとノード
そして今、それがすべてどのように働いたか。
ウィザードを開始した後、MySQLをインストールし、必要なテーブルを作成するスクリプトを実行しました(ところで、筋肉の仕事の最初の経験)
#! /bin/bash sudo apt-get install mysql-server -y sudo sed -i -e "s/bind-address/#bind-address/g" \ /etc/mysql/mysql.conf.d/mysqld.cnf sudo service mysql restart echo "Please enter root user MySQL password!" read rootpasswd mysql -uroot -p${rootpasswd} \ -e "CREATE DATABASE mistadb DEFAULT CHARACTER SET utf8;" mysql -uroot -p${rootpasswd} \ -e "CREATE USER 'gomista'@'%' IDENTIFIED BY 'gomista';" mysql -uroot -p${rootpasswd} \ -e "GRANT ALL PRIVILEGES ON *.* TO 'gomista'@'%' WITH GRANT OPTION;" mysql -uroot -p${rootpasswd} -e "FLUSH PRIVILEGES;" mysql -ugomista -pgomista -e "CREATE TABLE server_statuses ( node_name VARCHAR(50) PRIMARY KEY, node_ip VARCHAR(15) NOT NULL, node_status TINYINT(50), updated_at TIMESTAMP );" mistadb mysql -ugomista -pgomista -e "CREATE TABLE server_commands ( id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY, node_name VARCHAR(50) NOT NULL, node_ip VARCHAR(15) NOT NULL, job_id VARCHAR(70), n_links INT(50), received TINYINT(50), updated_at TIMESTAMP, CONSTRAINT node_name_unique UNIQUE (node_name, job_id) );" mistadb mysql -ugomista -pgomista -e "CREATE TABLE links ( job_id VARCHAR(70), link VARCHAR(200), status TINYINT(50), updated_at TIMESTAMP, INDEX(job_id), INDEX(link), CONSTRAINT node_name_unique UNIQUE (job_id, link) );" mistadb python -c "exec(\"import sys\\nfor i in range(1,1000000): \ print ('\t'+'{0:0>6}'.format(str(i))+'\t0')\")" > numbers mysql -ugomista -pgomista -e "LOAD DATA LOCAL INFILE 'numbers' \ INTO TABLE links;" mistadb rm numbers
links
テーブルには、1から999999までの番号、番号が処理されたかどうかに関する情報(ステータス0-未処理、1-操作中、2-処理済み)、1つまたは別の番号を処理中または処理済みのジョブの識別子が格納されました。server_commands
テーブルserver_commands
は、マスターがノードに渡したジョブserver_commands
ます(受信0-発行、受信1-受信、受信2-完了)。 テーブルのserver_statuses
サーバーのステータス(node_status 0-フリー、node_status 1-ビジー)。
5秒ごとに、ウィザードで次のスクリプトが起動されました。
#!/usr/bin/env python import mysql.connector import socket import uuid import datetime import sys if len(sys.argv) == 2: number_of_links = int(sys.argv[1]) else: number_of_links = 500 cnx = mysql.connector.connect(user='gomista', password='gomista', host='cserver', database='mistadb') cursor = cnx.cursor() select_servers =("SELECT server_statuses.node_name, server_statuses.node_status," "server_commands.received " "FROM server_statuses " "LEFT JOIN server_commands " "ON server_statuses.node_name = server_commands.node_name and " "server_commands.received <> 2 " "WHERE server_statuses.node_status = %(node_status)s and " "server_commands.received IS NULL LIMIT 1") server_status = {'node_status': 0} cursor.execute(select_servers, server_status) row = cursor.fetchone() if row: node_name = row[0] print (node_name) cursor = cnx.cursor() new_job_id = node_name + "_" + datetime.datetime.now().strftime("%Y%m%d_%H%M%S") + "_" + str(uuid.uuid4()) received = 0 add_job_command = ("INSERT INTO server_commands " "(node_name, node_ip, job_id, n_links, received) " "VALUES (%(node_name)s, %(node_ip)s, %(job_id)s, %(n_links)s, %(received)s) " "ON DUPLICATE KEY UPDATE node_ip = %(node_ip)s, " "n_links = %(n_links)s, received = %(received)s, updated_at=now();" "UPDATE links " "SET job_id = %(job_id)s " "WHERE job_id = '' AND status = 0 LIMIT %(n_links)s;") server_job = {'node_name': str(node_name), 'node_ip': str(node_name), 'job_id': new_job_id, 'n_links': number_of_links, 'received': received} for result in cursor.execute(add_job_command, server_job, multi=True): pass cnx.commit() cursor.close() cnx.close() else: print ("no available worker found")
このスクリプトは、使用可能なサーバーのserver_statuses
テーブルをチェックし、見つかった場合は、server_commands
テーブルでそのジョブを作成し、links
テーブルからジョブに特定の数の番号を割り当てました。
ノードは、起動中に、1分ごとに実行される次のスクリプトをcrontabに追加しました。
#!/usr/bin/env python from xvfbwrapper import Xvfb from cserver_connector import CserverConnector from mista_downloader import MistaDownloader import sys import subprocess import syslog import datetime MAX_PROCESS_TIME = 40 # min def print_to_log(message): syslog.syslog(message) print (message) def get_process_time_in_min(connector): mod_time = datetime.datetime.fromtimestamp(connector.modified_time) current_time = datetime.datetime.now() delta = current_time - mod_time delta_min = delta.seconds / 60 return delta_min print_to_log("Creating connector...") connector = CserverConnector() print_to_log("Connector created. Working: "+str(connector.working)) if connector.working: process_time_in_min = get_process_time_in_min(connector) if process_time_in_min > MAX_PROCESS_TIME: print_to_log("Canceling job...") connector.cancel_job() connector.remove_file_flag() print_to_log("Updating 0 status on cserver...") connector.update_status_on_cserver(0) print_to_log("Exiting...") exit(0) else: connector.update_status_on_cserver(1) print_to_log("Exiting...") exit(0) else: print_to_log("Updating 0 status on cserver...") connector.update_status_on_cserver(0) print_to_log("Getting new job...") connector.get_new_job() if not connector.job_id: print_to_log("No assigned jobs found...") print_to_log("Exiting...") exit(0) print_to_log("Job found: "+connector.job_id) connector.create_file_flag() print_to_log("Updating 1 status on cserver...") connector.update_status_on_cserver(1) print_to_log("Getting list of links...") connector.get_links_list() print_to_log("Starting Xvfb...") vdisplay = Xvfb() vdisplay.start() print_to_log("Creating MistaDownloader...") try: do = MistaDownloader() except Exception as e: print_to_log(str(e)) raise print_to_log("Do authenticate...") do.authenticate() folder = do.folder print_to_log("Downloading links in loop...") for link in connector.links_list: do.download_by_id(link[0].lstrip('0')) vdisplay.stop() print_to_log("Moving files to GS...") move_command = "gsutil -m mv " + folder + "/* gs://mistabucket-west/files" subprocess.call([move_command], shell=True) print_to_log("Updating links on finish...") connector.update_links_on_finish() connector.remove_file_flag() print_to_log("Updating 0 status on cserver...") connector.update_status_on_cserver(0) print_to_log("Exiting...")
このスクリプトはserver_commands
接続し、server_commands
テーブルを調べました。 タスクが見つかった場合、ジョブの番号ごとに番号のリストを取得し、ダウンロードを開始して、マスターに仕事を引き受け、忙しいことを通知します。 ダウンロードが完了した後、Nodはserver_statuses
テーブル(現在は無料であると言った)、server_commands
(彼がタスクを完了したと言っている)、ダウンロードした番号を記載したlinks
更新しました。 マスターは、Nodが自由であるとわかるとすぐに、Nodが1分以内にこのタスクをピックアップして作業を開始できるように、未処理の番号を使用して新しいジョブを投げました...
Noda Masterとのすべての通信は、別個のクラスCServerConnector
もたらされました
#!/usr/bin/env python import mysql.connector import socket import os import syslog class CserverConnector: def print_to_log(self, message): syslog.syslog(message) print (message) def __init__(self): self.hostname = socket.gethostname() self.file_flag = '/home/gomista/WORKING' self.mysql_connector = mysql.connector.connect(user='gomista', password='gomista', host='cserver', database='mistadb', buffered=True) self.working = os.path.isfile(self.file_flag) if self.working: self.modified_time = os.path.getmtime(self.file_flag) with open(self.file_flag, 'r') as f: self.job_id = f.readline().strip() else: self.modified_time = None self.job_id = None self.n_links = 0 self.links_list = list() def create_file_flag(self): file_flag_to_write = open(self.file_flag, "w") file_flag_to_write.write(self.job_id) file_flag_to_write.close() def update_file_flag(self): self.create_file_flag() def remove_file_flag(self): if os.path.isfile(self.file_flag): os.remove(self.file_flag) def update_status_on_cserver(self, status): cursor = self.mysql_connector.cursor() add_server_status_query = ("INSERT INTO server_statuses " "(node_name, node_ip, node_status) " "VALUES (%(node_name)s, %(node_ip)s, %(node_status)s)" "ON DUPLICATE KEY UPDATE node_ip = %(node_ip)s, " "node_status = %(node_status)s, updated_at=now()") server_status = {'node_name': self.hostname, 'node_ip': self.hostname, 'node_status': status} cursor.execute(add_server_status_query, server_status) self.mysql_connector.commit() cursor.close() def get_new_job(self): cursor = self.mysql_connector.cursor() get_command_query = ("SELECT node_name, job_id, n_links " "FROM server_commands " "WHERE node_name = %(node_name)s AND job_id <> '' AND " "received = %(node_name)s LIMIT 1") server_status = {'node_name': self.hostname, 'node_ip': self.hostname, 'received': 0} cursor.execute(get_command_query, server_status) row = cursor.fetchone() if row: node_name = str(row[0]) self.job_id = str(row[1]) self.n_links = str(row[2]) else: self.job_id = None self.n_links = 0 cursor.close() def get_links_list(self): self.print_to_log("Getting coursor and prepare the query...") cursor = self.mysql_connector.cursor() update_job_command_query = ("UPDATE server_commands " "SET received = 1 " "WHERE job_id = %(job_id)s;") server_job = {'job_id': self.job_id} self.print_to_log("Executing query 1.") cursor.execute(update_job_command_query, server_job) self.print_to_log("Commiting query 1.") self.mysql_connector.commit() update_links_query = ("UPDATE links " "SET status = 1 " "WHERE job_id = %(job_id)s;") server_job = {'job_id': self.job_id} self.print_to_log("Executing query 2. with job_id: "+self.job_id) try: cursor.execute(update_links_query, server_job) except Exception as e: self.print_to_log(str(e)) self.print_to_log(cursor.statement) raise self.print_to_log("Commiting query 2.") self.mysql_connector.commit() cursor.close() cursor = self.mysql_connector.cursor() get_links_query = ("SELECT link FROM links WHERE job_id = %(job_id)s") self.print_to_log("Executing query 3.") cursor.execute(get_links_query, {'job_id': self.job_id}) for (link) in cursor: self.links_list.append(link) cursor.close() self.print_to_log("Finished.") def update_links_on_finish(self): cursor = self.mysql_connector.cursor() update_job_command_query = ("UPDATE server_commands " "SET received = 2 " "WHERE job_id = %(job_id)s;") server_job = {'job_id': self.job_id} cursor.execute(update_job_command_query, server_job) self.mysql_connector.commit() update_links_query = ("UPDATE links " "SET status = 2 " "WHERE job_id = %(job_id)s;") server_job = {'job_id': self.job_id} cursor.execute(update_links_query, server_job) self.mysql_connector.commit() cursor.close() def cancel_job(self): cursor = self.mysql_connector.cursor() update_job_command_query = ("DELETE FROM server_commands " "WHERE job_id = %(job_id)s;") server_job = {'job_id': self.job_id} cursor.execute(update_job_command_query, server_job) self.mysql_connector.commit() update_links_query = ("UPDATE links " "SET status = 0, job_id = '' " "WHERE job_id = %(job_id)s;") server_job = {'job_id': self.job_id} cursor.execute(update_links_query, server_job) self.mysql_connector.commit() cursor.close()
これはテーブルがプロセスでどのように見えるかです:
gomista@cserver:~/mista$ ./get_mysql_status.sh NODES: +-----------+---------+-------------+---------------------+ | node_name | node_ip | node_status | updated_at | +-----------+---------+-------------+---------------------+ | node01 | node01 | 1 | 2018-01-05 08:07:02 | | node02 | node02 | 1 | 2018-01-05 08:07:02 | | node03 | node03 | 1 | 2018-01-05 08:07:02 | | node04 | node04 | 1 | 2018-01-05 08:07:02 | | node05 | node05 | 1 | 2018-01-05 08:07:02 | | node06 | node06 | 1 | 2018-01-05 08:07:02 | | node07 | node07 | 1 | 2018-01-05 08:07:03 | | node08 | node08 | 1 | 2018-01-05 08:07:03 | | node09 | node09 | 1 | 2018-01-05 08:07:03 | | node10 | node10 | 1 | 2018-01-05 08:07:03 | | node11 | node11 | 0 | 2018-01-05 08:07:17 | | node12 | node12 | 1 | 2018-01-05 08:07:03 | | node13 | node13 | 1 | 2018-01-05 08:07:03 | | node14 | node14 | 1 | 2018-01-05 08:07:03 | | node15 | node15 | 1 | 2018-01-05 08:07:03 | | node16 | node16 | 1 | 2018-01-05 08:07:03 | | node17 | node17 | 0 | 2018-01-05 08:07:15 | | node18 | node18 | 1 | 2018-01-05 08:07:03 | | node19 | node19 | 1 | 2018-01-05 08:07:03 | | node20 | node20 | 1 | 2018-01-05 08:07:04 | | node21 | node21 | 1 | 2018-01-05 08:07:03 | | node22 | node22 | 1 | 2018-01-05 08:07:03 | +-----------+---------+-------------+---------------------+ JOBS DONE: +-----------+-----------+ | node_name | jobs_done | +-----------+-----------+ | node08 | 5 | | node10 | 5 | | node11 | 6 | | node07 | 6 | | node09 | 7 | | node22 | 8 | | node13 | 9 | | node06 | 9 | | node20 | 10 | | node17 | 10 | | node14 | 10 | | node21 | 10 | | node12 | 10 | | node18 | 11 | | node15 | 11 | | node02 | 12 | | node19 | 12 | | node04 | 12 | | node01 | 12 | | node05 | 13 | | node03 | 13 | | node16 | 15 | +-----------+-----------+ COMMANDS TO BE DONE: +-----+-----------+---------+-------+---------+----------+---------------------+ | id | node_name | node_ip | job_id| n_links | received | updated_at | +-----+-----------+---------+-------+---------+----------+---------------------+ | 266 | node17 | node17 | ad062 | 500 | 0 | 2018-01-05 08:07:17 | | 267 | node11 | node11 | ab531 | 500 | 0 | 2018-01-05 08:07:22 | +-----+-----------+---------+-------+---------+----------+---------------------+ COMMANDS IN PROGRESS: +-----+-----------+---------+-------+---------+----------+---------------------+ | id | node_name | node_ip | job_id| n_links | received | updated_at | +-----+-----------+---------+-------+---------+----------+---------------------+ | 244 | node14 | node14 | 5e1b6 | 500 | 1 | 2018-01-05 07:55:04 | | 245 | node06 | node06 | d0235 | 500 | 1 | 2018-01-05 07:56:02 | | 246 | node13 | node13 | c82fd | 500 | 1 | 2018-01-05 07:56:04 | | 249 | node09 | node09 | 1d553 | 500 | 1 | 2018-01-05 07:59:04 | | 250 | node12 | node12 | 9176f | 500 | 1 | 2018-01-05 07:59:03 | | 251 | node22 | node22 | 1c8ae | 500 | 1 | 2018-01-05 08:00:03 | | 252 | node15 | node15 | 3ca50 | 500 | 1 | 2018-01-05 08:01:04 | | 253 | node18 | node18 | 8836c | 500 | 1 | 2018-01-05 08:01:03 | | 254 | node21 | node21 | 091f7 | 500 | 1 | 2018-01-05 08:01:03 | | 255 | node16 | node16 | 6475d | 500 | 1 | 2018-01-05 08:02:04 | | 256 | node19 | node19 | 489b3 | 500 | 1 | 2018-01-05 08:03:04 | | 257 | node04 | node04 | 9fd5a | 500 | 1 | 2018-01-05 08:03:02 | | 258 | node05 | node05 | 49b9f | 500 | 1 | 2018-01-05 08:03:02 | | 259 | node01 | node01 | 579a7 | 500 | 1 | 2018-01-05 08:04:02 | | 260 | node20 | node20 | d3fe8 | 500 | 1 | 2018-01-05 08:05:03 | | 261 | node08 | node08 | ff1c7 | 500 | 1 | 2018-01-05 08:05:04 | | 262 | node03 | node03 | b1165 | 500 | 1 | 2018-01-05 08:06:02 | | 263 | node02 | node02 | 7d138 | 500 | 1 | 2018-01-05 08:06:02 | | 264 | node10 | node10 | 4ad65 | 500 | 1 | 2018-01-05 08:06:04 | | 265 | node07 | node07 | e6501 | 500 | 1 | 2018-01-05 08:06:04 | +-----+-----------+---------+-------+---------+----------+---------------------+ LINKS TO BE PROCESSED: +-------------+ | count(link) | +-------------+ | 881999 | +-------------+ LINKS IN PROCESS: +-------------+ | count(link) | +-------------+ | 10000 | +-------------+ LINKS DONE +-------------+ | count(link) | +-------------+ | 108000 | +-------------+ gomista@cserver:~/mista$
全体のプロセスには約20時間かかりました。 お金の面では、0.067ドル20時間+ 0.011ドル 20時間* 20台の車または敵の通貨の5.74、またはネイティブルーブルの約350です。 20時間を費やし、350ルーブルが30 GBの100万を超えるファイルの形で完済しました。
ユーザーのリストは、このスクリプトによってダウンロードされています。 実際、これは単に1〜200,000のユーザーページを検索するだけです。実際、ユーザーは少ないですが、何らかの理由で100,000を超えるIDを持つユーザーが見つかったため、余裕を持ってダウンロードすることにしました。
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 import base64 import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from bs4 import BeautifulSoup from urllib import quote from xvfbwrapper import Xvfb import sys import codecs import binascii import os import datetime print(sys.getdefaultencoding()) reload(sys) sys.setdefaultencoding("utf-8") print(sys.getdefaultencoding()) if len(sys.argv) == 3: N_START = int(sys.argv[1]) N_END = int(sys.argv[2]) else: N_START = 1 N_END = 2 URL_TO_SAVE = 'users' if not os.path.exists(URL_TO_SAVE): os.makedirs(URL_TO_SAVE) vdisplay = Xvfb() vdisplay.start() def _convert(param): if isinstance(param, str): return param.decode('utf-8') else: return param def get_driver(): url = "http://www.forum.mista.ru/index.php" driver = webdriver.Chrome() return driver def authenticate(url, driver): driver.get(url) username = " " password = "11" uname = driver.find_element_by_name("user_name") uname.send_keys(_convert(username)) passw = driver.find_element_by_name("user_password") passw.send_keys(password) submit_button = driver.find_element_by_class_name("sendbutton").click() url_edit = "http://www.forum.mista.ru/users.php?action=edit" driver.get(url_edit) a = driver.find_element_by_xpath("//a[@href='#tab3']") a.click() topics = driver.find_element_by_name("topics_per_page") topics.clear() topics.send_keys(99) section = driver.find_element_by_name("column_forum") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_replies") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_section") if not section.is_selected(): section.click() section = driver.find_element_by_name("show_topic_section") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_author") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_updated") if not section.is_selected(): section.click() submit_button = driver.find_element_by_name("Submit").click() base_url = 'http://www.forum.mista.ru/' print("getting driver") driver = get_driver() print("logging") authenticate(base_url, driver) def save_user_page(page, driver, n=0): links_list = list() print('getting page: '+page) driver.get(page) print('done') html = driver.page_source.replace('\t', ' ').replace('\n', ' ') .replace('\r', ' ') filename = URL_TO_SAVE + '/' + '{0:0>10}'.format(n) + '_' + binascii.hexlify(page) + '.txt' file = open(filename,'w') file.write(html + '\n') file.close() limit = 100 for i in range(N_START, N_END): current_url = 'http://www.forum.mista.ru/users.php?id=' + str(i) n = i save_user_page(current_url, driver, n) vdisplay.stop()
( ) .
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 import base64 import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from bs4 import BeautifulSoup from urllib import quote from xvfbwrapper import Xvfb import sys import codecs import binascii import os import datetime print(sys.getdefaultencoding()) reload(sys) sys.setdefaultencoding("utf-8") print(sys.getdefaultencoding()) URL_TO_SAVE = 'links_backward' if not os.path.exists(URL_TO_SAVE): os.makedirs(URL_TO_SAVE) vdisplay = Xvfb() vdisplay.start() def _convert(param): if isinstance(param, str): return param.decode('utf-8') else: return param def get_driver(): url = "http://www.forum.mista.ru/index.php" driver = webdriver.Chrome() return driver def authenticate(url, driver): driver.get(url) username = " " password = "11" uname = driver.find_element_by_name("user_name") uname.send_keys(_convert(username)) passw = driver.find_element_by_name("user_password") passw.send_keys(password) submit_button = driver.find_element_by_class_name("sendbutton").click() url_edit = "http://www.forum.mista.ru/users.php?action=edit" driver.get(url_edit) a = driver.find_element_by_xpath("//a[@href='#tab3']") a.click() topics = driver.find_element_by_name("topics_per_page") topics.clear() topics.send_keys(99) section = driver.find_element_by_name("column_forum") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_replies") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_section") if not section.is_selected(): section.click() section = driver.find_element_by_name("show_topic_section") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_author") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_updated") if not section.is_selected(): section.click() submit_button = driver.find_element_by_name("Submit").click() base_url = 'http://www.forum.mista.ru/' print("getting driver") driver = get_driver() print("logging") authenticate(base_url, driver) def save_links_list_on_page(page, driver, n=0): links_list = list() print('getting page: '+page) driver.get(page) print('done') html = driver.page_source soup = BeautifulSoup(html, "lxml") tr_list = soup.findAll('tr', attrs = {'data-topic_id' : True}) for tr_element in tr_list: topic_id = tr_element['data-topic_id'] tr_element_1 = tr_element.findAll('td', { 'class' : 'cc' }) section = tr_element_1[0].getText().replace('\t', '') length = tr_element_1[1].getText().replace('\t', '') tr_element_2 = tr_element.find('a', { 'class' : 'agb' }) title = tr_element_2.getText().replace('\t', '') tr_element_2_1 = tr_element.find('a', { 'class' : 'userlink' }) user_link = tr_element_2_1['href'] user_name = tr_element_2_1.getText().replace('\t', '') tr_element_2_2 = tr_element.find('a', { 'class' : 'sectionlink' }) subsection = '' if tr_element_2_2: subsection = tr_element_2_2.getText().replace('\t', '') classes = ' '.join(tr_element_2['class']).replace('\t', '') link = tr_element_2['href'].replace('\t', '') tr_element_3 = tr_element.find('a', { 'class' : 'sectionlink-gray' }) link_attributes = '%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s' % (topic_id, link, section, subsection, length, title, user_link, user_name, classes) links_list.append(link_attributes) next_link_tag = soup.find('a', text='<<') if next_link_tag: nex_page_link = base_url+next_link_tag['href'] else: nex_page_link = '' filename = URL_TO_SAVE + '/' + '{0:0>10}'.format(n) + '_' + binascii.hexlify(page) + '.txt' file = open(filename,'w') for link in links_list: file.write(link + '\n') file.close() return nex_page_link current_url = 'http://www.forum.mista.ru/index.php?id=30309&after=2000/07/06_14:17:00' n = 1 while current_url != '': current_url = save_links_list_on_page(current_url, driver, n) n += 1 print('next page to process: '+current_url) vdisplay.stop()
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 import base64 import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait from bs4 import BeautifulSoup from urllib import quote from xvfbwrapper import Xvfb import sys import codecs import binascii import os import datetime import re from dateutil import parser from pytz import timezone reload(sys) sys.setdefaultencoding("utf-8") URL_TO_SAVE = 'users_bans' if not os.path.exists(URL_TO_SAVE): os.makedirs(URL_TO_SAVE) vdisplay = Xvfb() vdisplay.start() def get_empty_ban(): empty_ban = {} empty_ban['ban_user_id'] = '' empty_ban['ban_type'] = '' empty_ban['ban_user_ip'] = '' empty_ban['ban_section'] = '' empty_ban['ban_subsection'] = '' empty_ban['ban_date'] = '' empty_ban['ban_end_date'] = '' empty_ban['ban_moderator_id'] = '' empty_ban['ban_reason'] = '' empty_ban['ban_topic_id'] = '' return empty_ban def get_list_of_users_on_page(source): tz = timezone('Europe/Moscow') fmt = '%Y-%m-%d %H:%M:%S %Z%z' def parse_message_time(str_message_time): message_time = parser.parse(str_message_time) message_time = tz.localize(message_time) return message_time.strftime(fmt) soup = BeautifulSoup(source, "html.parser") table = soup.find('table', { 'bgcolor' : '#CCCCCC' }) tr_elements = table.findAll('tr', { 'class' : 'active' }) ban_list = list() for user_element in tr_elements: ban = get_empty_ban() tds = user_element.findAll('td') ban['ban_user_id'] = tds[0].find('a')['data-user_id'] ban['ban_type'] = tds[1].getText() ban['ban_user_ip'] = tds[2].getText() ban['ban_section'] = tds[3].getText() ban['ban_subsection'] = tds[4].getText() ban['ban_date'] = parse_message_time(tds[8].getText()) ban['ban_end_date'] = parse_message_time(tds[5].getText()) ban['ban_moderator_id'] = tds[7].find('a')['href'].split('=')[1] ban['ban_reason'] = tds[9].getText() ban['ban_topic_id'] = tds[10].getText() print ('%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s' % ( ban['ban_user_id'].encode('utf-8') , ban['ban_type'].encode('utf-8') , ban['ban_user_ip'].encode('utf-8') , ban['ban_section'].encode('utf-8') , ban['ban_subsection'].encode('utf-8') , ban['ban_date'].encode('utf-8') , ban['ban_end_date'].encode('utf-8') , ban['ban_moderator_id'].encode('utf-8') , ban['ban_reason'].encode('utf-8') , ban['ban_topic_id'])) ban_list.append(ban) return ban_list def _convert(param): if isinstance(param, str): return param.decode('utf-8') else: return param def get_driver(): url = "http://www.forum.mista.ru/index.php" driver = webdriver.Chrome() return driver def authenticate(url, driver): driver.get(url) username = " " password = "11" uname = driver.find_element_by_name("user_name") uname.send_keys(_convert(username)) passw = driver.find_element_by_name("user_password") passw.send_keys(password) submit_button = driver.find_element_by_class_name("sendbutton").click() url_edit = "http://www.forum.mista.ru/users.php?action=edit" driver.get(url_edit) a = driver.find_element_by_xpath("//a[@href='#tab3']") a.click() topics = driver.find_element_by_name("topics_per_page") topics.clear() topics.send_keys(99) section = driver.find_element_by_name("column_forum") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_replies") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_section") if not section.is_selected(): section.click() section = driver.find_element_by_name("show_topic_section") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_author") if not section.is_selected(): section.click() section = driver.find_element_by_name("column_updated") if not section.is_selected(): section.click() submit_button = driver.find_element_by_name("Submit").click() base_url = 'http://www.forum.mista.ru/' driver = get_driver() authenticate(base_url, driver) def save_links_list_on_page(page, driver, n=0): driver.get(page) ban_list = get_list_of_users_on_page(driver.page_source) html = driver.page_source.replace('\t', ' ').replace('\n', ' ') .replace('\r', ' ').encode('utf-8') soup = BeautifulSoup(html, "html.parser") noindex_tag = soup.find('noindex') a_tag =noindex_tag.findAll('a') if len(a_tag) == 1: link_to_return = '' else: link_to_return = base_url+a_tag[1]['href'] return link_to_return current_url = 'http://www.forum.mista.ru/ban_list.php' n = 1 while current_url != '': current_url = save_links_list_on_page(current_url, driver, n) n += 1 if current_url == '' or current_url == 'http://www.forum.mista.ru/ban_list.php?next=': break vdisplay.stop()
4 — , - , .
" ", . 1 20 data . Google Cloud Storage , - , . , , , GCS .
, :
cat * > combo
:
-bash: /bin/cat: Argument list too long
, :
for f in *.txt; do (cat "${f}") >> ~/combo; done;
, - . , , :
echo * | xargs paste -s -d \n > ~/foo.txt
— . .
:
- 30
- 500 200 ( )
- 100
- 500
.
Parsing stage
:
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 from bs4 import BeautifulSoup from dateutil import parser from pytz import timezone import datetime import re import sys reload(sys) sys.setdefaultencoding("utf-8") def get_empty_message(): message = {} message['message_id'] = '' message['message_date_time'] = '' message['message_user_id'] = '' message['message_user_name'] = '' message['message_user_id'] = '' message['message_user_class'] = '' message['message_text'] = '' message['message_reply_to'] = '' message['message_external_links'] = '' return message def get_list_of_messages_on_page(source): tz = timezone('Europe/Moscow') fmt = '%Y-%m-%d %H:%M:%S %Z%z' def parse_message_time(str_message_time): str_message_time = '-'.join(str_message_time.split('-')[-2:]) message_time = parser.parse(str_message_time) message_time = tz.localize(message_time) return message_time.strftime(fmt) soup = BeautifulSoup(source, "html.parser") message_elements = soup.findAll('tr', id=re.compile("^message_\d+")) message_list = list() for message_element in message_elements: message = {} # message info message['message_id'] = int(re.sub("message_", "", message_element['id'])) message_date_time = message_element .find('div', { 'class' : 'message-info' }) .getText().replace(u'\xa0', u'') message['message_date_time'] = parse_message_time(message_date_time) # message user info user_info_element = message_element .find('td', id=re.compile("^tduser\d+")) .find('a', attrs = {'data-user_id' : True}) if user_info_element: message['message_user_id'] = user_info_element['data-user_id'] message['message_user_name'] = user_info_element['data-user_name'] .replace('\t','') message['message_user_id'] = user_info_element['href'] .replace('users.php?id=','') message['message_user_class'] = ' '.join(user_info_element['class']) .replace('\t','') else: user_info_element = message_element .find('span', { 'class' : 'anonym-user' }) message['message_user_id'] = '' message['message_user_name'] = user_info_element.getText() .replace('\t','') message['message_user_id'] = '' message['message_user_class'] = 'anonym-user' # message content message_text_element = message_element .find('div', { 'class' : 'message-text' }) if not message_text_element: message['message_text'] = '' message['message_reply_to'] = '' message['message_external_links'] = '' else: answer_link_elements = message_text_element .findAll('a', { 'class' : 'answer-link' }) for answer_link_element in answer_link_elements: answer_link_element.decompose() inner_link_elements = message_text_element .findAll('a', { 'class' : 'interlink', 'data-rel' : re.compile("^#\d+") }) inner_link_list = list() for inner_link_element in inner_link_elements: inner_link_list.append(inner_link_element.extract().getText() .encode('utf-8')) other_link_elements = message_text_element.findAll('a') other_link_list = list() for other_link_element in other_link_elements: other_link = other_link_element.extract()['href'] other_link_list.append(other_link.encode('utf-8')) message_text = message_text_element.getText() message_text = message_text.replace('\t',' ').replace('\n',' ') .replace('()','').strip() message['message_text'] = message_text message['message_reply_to'] = ' '.join(inner_link_list) message['message_external_links'] = ' '.join(other_link_list) message_list.append(message) return message_list if __name__ == "__main__": for line in sys.stdin: try: topic_id, page_number, link, source = line.strip().split('\t') except Exception as e: continue if source == '<html xmlns="http://www.w3.org/1999/xhtml"><head></head><body> .</body></html>': message_list = list() message = get_empty_message() message_list.append(message) else: try: message_list = get_list_of_messages_on_page(source) except Exception as e: message_list = list() message = get_empty_message() message['message_user_name'] = 'ERRORERRORERROR' message['message_text'] = str(e) message_list.append(message) for message in message_list: # 12 columns print ('%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s' % ( topic_id , page_number , link , message['message_id'] , message['message_date_time'].encode('utf-8') , message['message_user_name'].encode('utf-8') , message['message_user_id'].encode('utf-8') , message['message_user_class'].encode('utf-8') , message['message_text'].encode('utf-8') , message['message_reply_to'].encode('utf-8') , message['message_external_links'].encode('utf-8')))
, , tsv. BeautifulSoup. , , . .
:
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 from bs4 import BeautifulSoup from dateutil import parser from pytz import timezone import datetime import re import sys reload(sys) sys.setdefaultencoding("utf-8") def get_empty_user(): empty_user = {} empty_user['user_id'] = '' empty_user['user_name'] = '' empty_user['user_full_name'] = '' empty_user['user_email'] = '' empty_user['user_contacts'] = '' empty_user['user_url'] = '' empty_user['user_city_country'] = '' empty_user['user_dob'] = '' empty_user['user_timezone'] = '' empty_user['user_gender'] = '' empty_user['user_position'] = '' empty_user['user_achievement'] = '' empty_user['user_interests'] = '' empty_user['user_forum_role'] = '' empty_user['user_registration'] = '' empty_user['user_messages'] = '' empty_user['user_topics'] = '' return empty_user months_dic = {} months_dic[''] = 'January' months_dic[''] = 'February' months_dic[''] = 'March' months_dic[''] = 'April' months_dic[''] = 'May' months_dic[''] = 'June' months_dic[''] = 'July' months_dic[''] = 'August' months_dic[''] = 'September' months_dic[''] = 'October' months_dic[''] = 'November' months_dic[''] = 'December' def get_user_info_on_page(source): fmt = '%Y-%m-%d' def parse_str_date(str_date): if str_date == '': return ''; try: date_str = str_date.split(';')[0] if date_str[4:5] == ' ': dd = '01' mm = 'January' yy = date_str[:4] date = parser.parse(' '.join([dd, mm, yy])) else: dd, mm, yy = date_str.split(' ') date = parser.parse(' '.join([dd, months_dic[mm], yy])) return date.strftime(fmt) except Exception as e: return '' user = get_empty_user() soup = BeautifulSoup(source, "html.parser") id_tag = soup.find('a', href=re.compile('index.php\?user_id=\d+')) if id_tag: user['user_id'] = id_tag['href'].split('=')[1].encode('utf-8').strip() main_table = soup.findAll('table', { 'class' : 'table' }) main_table = main_table[len(main_table)-1] main_table_rows = main_table.findAll('tr') user['user_name'] = main_table_rows[0].findAll('td')[1].getText() .encode('utf-8').strip() user['user_full_name'] = main_table_rows[1].findAll('td')[1].getText() .encode('utf-8').strip() user['user_email'] = main_table_rows[3].findAll('td')[1].getText() .encode('utf-8').strip() user['user_contacts'] = main_table_rows[4].findAll('td')[1].getText() .encode('utf-8').strip() user['user_url'] = main_table_rows[5].findAll('td')[1].getText() .encode('utf-8').strip() user['user_city_country'] = main_table_rows[6].findAll('td')[1].getText() .encode('utf-8').strip() str_dob = main_table_rows[7].findAll('td')[1].getText().encode('utf-8').strip() user['user_dob'] = parse_str_date(str_dob) user['user_timezone'] = main_table_rows[8].findAll('td')[1].getText() .encode('utf-8').strip() user['user_gender'] = main_table_rows[9].findAll('td')[1].getText() .encode('utf-8').strip() user['user_position'] = main_table_rows[10].findAll('td')[1].getText() .encode('utf-8').strip() user['user_achievement'] = main_table_rows[11].findAll('td')[1].getText() .encode('utf-8').strip() user['user_interests'] = main_table_rows[12].findAll('td')[1].getText() .encode('utf-8').strip() user['user_forum_role'] = main_table_rows[13].findAll('td')[1].getText() .encode('utf-8').strip() str_reg = main_table_rows[14].findAll('td')[1].getText() .encode('utf-8').strip() user['user_registration'] = parse_str_date(str_reg) user['user_messages'] = main_table_rows[15].findAll('td')[1].getText() .encode('utf-8').strip() user['user_topics'] = main_table_rows[16].findAll('td')[1].getText() .encode('utf-8').strip() return user if __name__ == "__main__": for line in sys.stdin: try: source = line.strip() except Exception as e: continue if source == '' or source == '<html xmlns="http://www.w3.org/1999/xhtml"><head></head><body> : id .</body></html>': user = get_empty_user() else: user = get_empty_user() try: user = get_user_info_on_page(source) except Exception as e: user = get_empty_user() user['user_name'] = 'ERRORERRORERROR' user['user_full_name'] = str(e) print ('%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s' % ( user['user_id'] , user['user_name'] , user['user_full_name'] , user['user_email'] , user['user_contacts'] , user['user_url'] , user['user_city_country'] , user['user_dob'] , user['user_timezone'] , user['user_gender'] , user['user_position'] , user['user_achievement'] , user['user_interests'] , user['user_forum_role'] , user['user_registration'] , user['user_messages'] , user['user_topics']))
.
Hadoop and distributed computing
Hadoop MapReduce. MapReduce WordCount , , . GCP , distributed computing .
GCP DataProc. , ( High Availability) . 2-3 , (Hadoop, HDFS, Spark etc). . — job . , Hadoop c Google Storage Platform HDSF (.. HDFS ). — , job , . . すなわち 2 5 20 30 . , , ?
20 n1-standard-1
(1CPUs 3.75Gb), . :
#! /bin/bash gcloud dataproc clusters create cluster-west \ --region europe-west1 \ --zone europe-west1-b \ --bucket mistabucket-west \ --subnet default \ --master-machine-type n1-standard-1 \ --master-boot-disk-size 100 \ --num-workers 20 \ --worker-machine-type n1-standard-1 \ --worker-boot-disk-size 100 \ --scopes 'https://www.googleapis.com/auth/cloud-platform' \ --project new-mista-project \ --initialization-actions 'gs://mistabucket-europe/install_environment.sh'
preemptible
, hdfs .
3 ( , -).
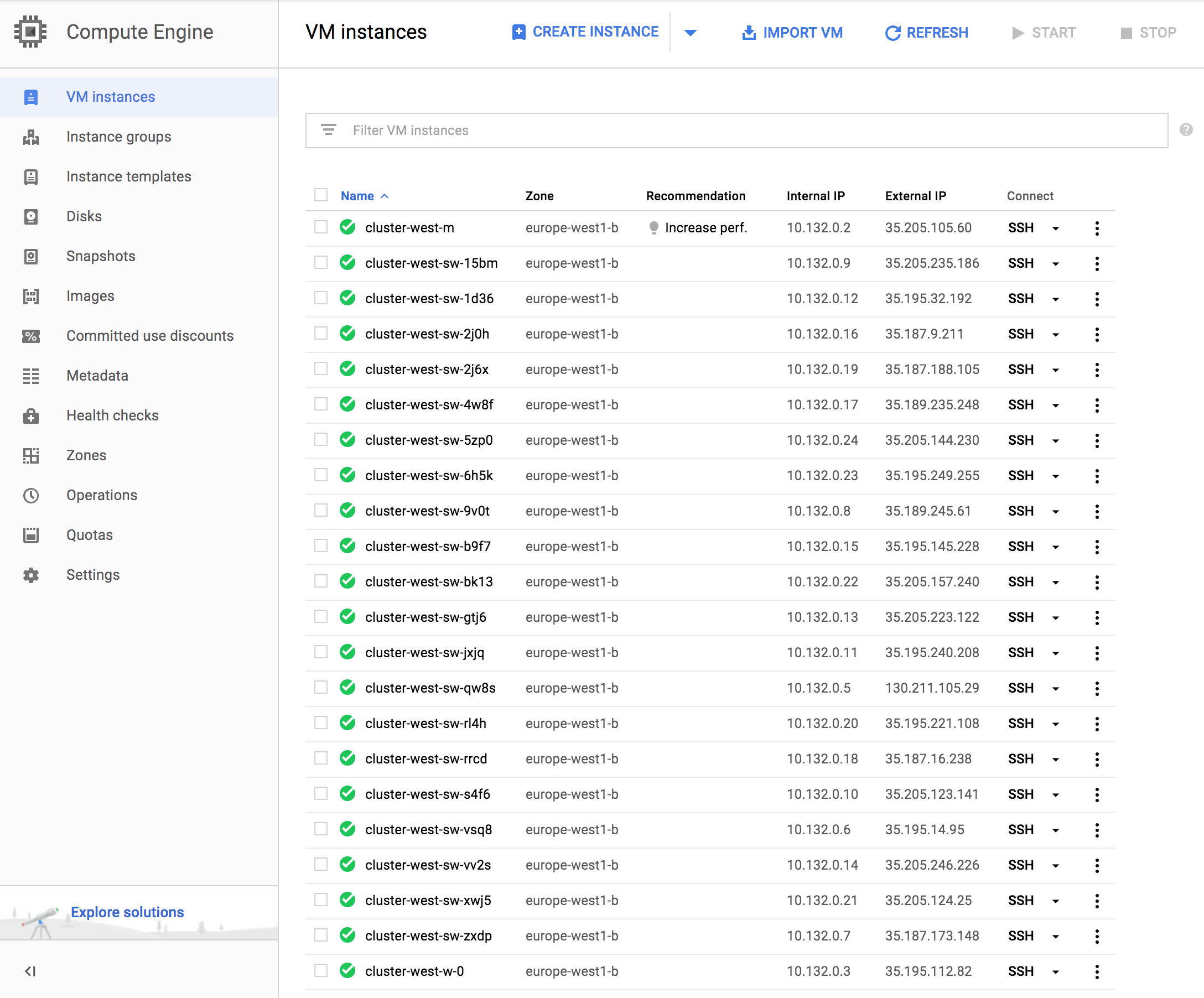
, Google Cloud Shell:
#!/bin/bash PARSER_FILE="gs://mistabucket-west/mapper_parser.py" IN_DIR="gs://mistabucket-west/grabbing_results_html/messages_big" OUT_DIR="gs://mistabucket-west/output_mid" gsutil rm -r ${OUT_DIR} > /dev/null gsutil cp mapper_parser.py ${PARSER_FILE} gcloud dataproc jobs submit hadoop \ --cluster cluster-west \ --region europe-west1 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -- \ -D mapred.jab.name="Parsing mista pages job 1 (parsing)" \ -files ${PARSER_FILE} \ -mapper mapper_parser.py \ -reducer 'cat' \ -input ${IN_DIR} \ -output ${OUT_DIR} IN_DIR="gs://mistabucket-west/output_mid" OUT_DIR="gs://mistabucket-west/grabbing_results_tsv/messages_dirty" gsutil rm -r ${OUT_DIR} > /dev/null gcloud dataproc jobs submit hadoop \ --cluster cluster-west \ --region europe-west1 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -- \ -D mapred.jab.name="Parsing mista pages job 2 (sorting)" \ -mapper 'cat' \ -reducer 'sort -k1,1n -k2,2n -k4,4n' \ -input ${IN_DIR} \ -output ${OUT_DIR} gsutil rm -r ${IN_DIR} > /dev/null
, — .
, :
#!/bin/bash IN_DIR="gs://mistabucket-west/grabbing_results_html/messages" OUT_DIR="gs://mistabucket-west/output_mid" OUT_LOG=out.$(date +"%s%6N").log gsutil rm -r ${OUT_DIR} > /dev/null hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapred.jab.name="Parsing mista pages job 1 (parsing)" \ -files mapper_parser.py \ -mapper mapper_parser.py \ -reducer 'cat' \ -input ${IN_DIR} \ -output ${OUT_DIR} > /dev/null 2>${OUT_LOG} IN_DIR="gs://mistabucket-west/output_mid" OUT_DIR="gs://mistabucket-west/grabbing_results_tsv/messages_dirty" gsutil rm -r ${OUT_DIR} > /dev/null hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapred.jab.name="Parsing mista pages job 2 (sorting)" \ -mapper 'cat' \ -reducer 'sort -k1,1n -k2,2n -k4,4n' \ -input ${IN_DIR} \ -output ${OUT_DIR} gsutil rm -r ${IN_DIR} > /dev/null
- .
:
:
CPU[######################################################################93.8%] Mem[|||||||||||||||||||||||||||||||||||||||||||#********** 2112/3711MB] Swp[ 0/0MB] PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command 10054 yarn 20 0 60432 36780 8224 R 25.0 1.0 3:04.25 python /hadoop... 10182 yarn 20 0 64908 41096 8156 R 25.0 1.1 2:28.96 python /hadoop... 10257 yarn 20 0 70280 46392 8288 R 25.0 1.2 2:17.99 python /hadoop... 10982 igab 20 0 25244 4376 2940 R 16.7 0.1 0:00.02 htop -C 10015 yarn 20 0 2420M 394M 26584 S 8.3 10.6 0:01.21 /usr/lib/jvm/j... 10039 yarn 20 0 2420M 394M 26584 R 8.3 10.6 0:00.85 /usr/lib/jvm/j... 10008 yarn 20 0 2420M 394M 26584 S 8.3 10.6 0:13.12 /usr/lib/jvm/j... 1 root 20 0 29640 5872 3104 S 0.0 0.2 0:06.54 /sbin/init 144 root 20 0 41524 6392 4012 S 0.0 0.2 0:00.40 /lib/systemd/s... 147 root 20 0 40808 3300 2772 S 0.0 0.1 0:00.07 /lib/systemd/s... 259 root 20 0 25400 7856 892 S 0.0 0.2 0:00.00 dhclient -v -p... 314 root 20 0 37080 2728 2296 S 0.0 0.1 0:00.00 /sbin/rpcbind ... 323 statd 20 0 37280 3060 2468 S 0.0 0.1 0:00.00 /sbin/rpc.stat... 337 root 20 0 23356 204 4 S 0.0 0.0 0:00.00 /usr/sbin/rpc.... 338 root 20 0 27476 2732 2500 S 0.0 0.1 0:00.01 /usr/sbin/cron... 355 root 20 0 252M 3344 2700 S 0.0 0.1 0:00.02 /usr/sbin/rsys... 356 root 20 0 252M 3344 2700 S 0.0 0.1 0:00.00 /usr/sbin/rsys... 357 root 20 0 252M 3344 2700 S 0.0 0.1 0:00.06 /usr/sbin/rsys... 339 root 20 0 252M 3344 2700 S 0.0 0.1 0:00.09 /usr/sbin/rsys... 343 messagebu 20 0 42120 3300 2920 S 0.0 0.1 0:00.27 /usr/bin/dbus-... 377 root 20 0 19856 2564 2296 S 0.0 0.1 0:00.11 /lib/systemd/s... 379 root 20 0 4256 1624 1480 S 0.0 0.0 0:00.00 /usr/sbin/acpi... 386 root 20 0 14416 1936 1784 S 0.0 0.1 0:00.00 /sbin/agetty -... 387 root 20 0 14236 2040 1888 S 0.0 0.1 0:00.00 /sbin/agetty -... 391 ntp 20 0 29168 4028 3452 S 0.0 0.1 0:00.62 /usr/sbin/ntpd... 425 root 20 0 55184 5400 4724 S 0.0 0.1 0:00.00 /usr/sbin/sshd... 431 root 20 0 53908 19460 7224 S 0.0 0.5 0:00.99 /usr/bin/pytho... 434 root 20 0 53484 19304 7224 S 0.0 0.5 0:00.43 /usr/bin/pytho... 435 root 20 0 55556 19192 7124 S 0.0 0.5 0:00.77 /usr/bin/pytho...
4 :
gomista@cluster-west-m:~/mista/mapreduce$ ./parser_pages_run.sh CommandException: No URLs matched: gs://mistabucket-west/output_mid 13/01/19 02:23:22 INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.6.2-ha... packageJobJar: [] [/usr/lib/hadoop-mapreduce/hadoop-streaming-2.8.2.jar] /tmp... 13/01/19 02:23:22 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 02:23:23 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 02:23:25 INFO mapred.FileInputFormat: Total input files to process :... 13/01/19 02:23:25 INFO mapreduce.JobSubmitter: number of splits:238 13/01/19 02:23:25 INFO mapreduce.JobSubmitter: Submitting tokens for job: job... 13/01/19 02:23:26 INFO impl.YarnClientImpl: Submitted application application... 13/01/19 02:23:26 INFO mapreduce.Job: The url to track the job: http://cluste... 13/01/19 02:23:26 INFO mapreduce.Job: Running job: job_1516327218763_0003 13/01/19 02:23:36 INFO mapreduce.Job: Job job_1516327218763_0003 running in u... 13/01/19 02:23:36 INFO mapreduce.Job: map 0% reduce 0% ... 13/01/19 02:56:09 INFO mapreduce.Job: map 10% reduce 0% ... 13/01/19 05:52:02 INFO mapreduce.Job: map 90% reduce 0% ... 13/01/19 06:06:53 INFO mapreduce.Job: map 98% reduce 0% ... 13/01/19 06:14:38 INFO mapreduce.Job: map 99% reduce 30% 13/01/19 06:14:47 INFO mapreduce.Job: map 100% reduce 30% ... 13/01/19 06:22:58 INFO mapreduce.Job: map 100% reduce 99% 13/01/19 06:23:09 INFO mapreduce.Job: map 100% reduce 100% 13/01/19 06:23:14 INFO mapreduce.Job: Job job_1516327218763_0003 completed su... 13/01/19 06:23:14 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=6430372113 FILE: Number of bytes written=12899232930 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 GS: Number of bytes read=31919556146 GS: Number of bytes written=6347504555 GS: Number of read operations=0 GS: Number of large read operations=0 GS: Number of write operations=0 HDFS: Number of bytes read=28798 HDFS: Number of bytes written=0 HDFS: Number of read operations=238 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Killed map tasks=10 Launched map tasks=248 Launched reduce tasks=22 Rack-local map tasks=248 Total time spent by all maps in occupied slots (ms)=3439064804 Total time spent by all reduces in occupied slots (ms)=144019192 Total time spent by all map tasks (ms)=859766201 Total time spent by all reduce tasks (ms)=18002399 Total vcore-milliseconds taken by all map tasks=859766201 Total vcore-milliseconds taken by all reduce tasks=18002399 Total megabyte-milliseconds taken by all map tasks=880400589824 Total megabyte-milliseconds taken by all reduce tasks=36868913152 Map-Reduce Framework Map input records=1062462 Map output records=16818747 Map output bytes=6372056899 Map output materialized bytes=6430403397 Input split bytes=28798 Combine input records=0 Combine output records=0 Reduce input groups=957787 Reduce shuffle bytes=6430403397 Reduce input records=16818747 Reduce output records=16818747 Spilled Records=33637494 Shuffled Maps =5236 Failed Shuffles=0 Merged Map outputs=5236 GC time elapsed (ms)=188467 CPU time spent (ms)=277329350 Physical memory (bytes) snapshot=115141345280 Virtual memory (bytes) snapshot=682591932416 Total committed heap usage (bytes)=89168744448 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=31919556146 File Output Format Counters Bytes Written=6347504555 13/01/19 06:23:14 INFO streaming.StreamJob: Output directory: gs://mistabucke... 13/01/19 06:23:17 INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.6.2-ha... packageJobJar: [] [/usr/lib/hadoop-mapreduce/hadoop-streaming-2.8.2.jar] /tmp... 13/01/19 06:23:17 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 06:23:18 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 06:23:19 INFO mapred.FileInputFormat: Total input files to process :... 13/01/19 06:23:19 INFO mapreduce.JobSubmitter: number of splits:198 13/01/19 06:23:20 INFO mapreduce.JobSubmitter: Submitting tokens for job: job... 13/01/19 06:23:20 INFO impl.YarnClientImpl: Submitted application application... 13/01/19 06:23:20 INFO mapreduce.Job: The url to track the job: http://cluste... 13/01/19 06:23:20 INFO mapreduce.Job: Running job: job_1516327218763_0004 13/01/19 06:23:29 INFO mapreduce.Job: Job job_1516327218763_0004 running in u... 13/01/19 06:23:29 INFO mapreduce.Job: map 0% reduce 0% ... 13/01/19 06:23:56 INFO mapreduce.Job: map 19% reduce 0% ... 13/01/19 06:24:48 INFO mapreduce.Job: map 93% reduce 0% 13/01/19 06:24:49 INFO mapreduce.Job: map 97% reduce 0% 13/01/19 06:24:52 INFO mapreduce.Job: map 99% reduce 0% 13/01/19 06:24:57 INFO mapreduce.Job: map 100% reduce 0% ... 13/01/19 06:25:15 INFO mapreduce.Job: map 100% reduce 100% 13/01/19 06:26:00 INFO mapreduce.Job: Job job_1516327218763_0004 completed su... 13/01/19 06:26:00 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=6430372113 FILE: Number of bytes written=12893310310 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 GS: Number of bytes read=6348254123 GS: Number of bytes written=6347504555 GS: Number of read operations=0 GS: Number of large read operations=0 GS: Number of write operations=0 HDFS: Number of bytes read=18810 HDFS: Number of bytes written=0 HDFS: Number of read operations=198 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Killed map tasks=2 Launched map tasks=199 Launched reduce tasks=22 Rack-local map tasks=199 Total time spent by all maps in occupied slots (ms)=17328576 Total time spent by all reduces in occupied slots (ms)=5680336 Total time spent by all map tasks (ms)=4332144 Total time spent by all reduce tasks (ms)=710042 Total vcore-milliseconds taken by all map tasks=4332144 Total vcore-milliseconds taken by all reduce tasks=710042 Total megabyte-milliseconds taken by all map tasks=4436115456 Total megabyte-milliseconds taken by all reduce tasks=1454166016 Map-Reduce Framework Map input records=16818747 Map output records=16818747 Map output bytes=6372056899 Map output materialized bytes=6430398117 Input split bytes=18810 Combine input records=0 Combine output records=0 Reduce input groups=957787 Reduce shuffle bytes=6430398117 Reduce input records=16818747 Reduce output records=16818747 Spilled Records=33637494 Shuffled Maps =4356 Failed Shuffles=0 Merged Map outputs=4356 GC time elapsed (ms)=104202 CPU time spent (ms)=849850 Physical memory (bytes) snapshot=99081195520 Virtual memory (bytes) snapshot=580507611136 Total committed heap usage (bytes)=78608355328 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=6348254123 File Output Format Counters Bytes Written=6347504555 13/01/19 06:26:00 INFO streaming.StreamJob: Output directory: gs://mistabucke...
, , , 4 20 4 . html/xml BeautifulSoup
, . , BeautifulSoup
lxml etree . . :
#!/usr/bin/env python # -*- coding: utf-8 -*- # export PYTHONIOENCODING=UTF-8 from bs4 import BeautifulSoup from dateutil import parser as parserDate from pytz import timezone import datetime import re import sys from lxml import etree from io import StringIO, BytesIO reload(sys) sys.setdefaultencoding("utf-8") def get_empty_message(): message = {} message['message_id'] = '' message['message_date_time'] = '' message['message_user_id'] = '' message['message_user_name'] = '' message['message_user_link'] = '' message['message_user_class'] = '' message['message_text'] = '' message['message_reply_to'] = '' message['message_external_links'] = '' return message def get_list_of_messages_on_page(source): tz = timezone('Europe/Moscow') fmt = '%Y-%m-%d %H:%M:%S %Z%z' def parse_message_time(str_message_time): str_message_time = '-'.join(str_message_time.split('-')[-2:]) message_time = parserDate.parse(str_message_time) message_time = tz.localize(message_time) return message_time.strftime(fmt) parser = etree.HTMLParser() tree = etree.parse(StringIO(source.decode('utf-8')), parser) message_elements = tree.xpath("//tr[starts-with(@id, 'message_')]") message_list = list() for message_element in message_elements: message = get_empty_message() message['message_id'] = int(re.sub("message_", "", message_element.attrib['id'])) message_date_time = message_element .xpath(".//div[@class = 'message-info']//text()")[0] .replace(u'\xa0', u'') message['message_date_time'] = parse_message_time(message_date_time) user_info_elements = message_element .xpath(".//td[starts-with(@id, 'tduser')]/a") if len(user_info_elements) == 1: user_info_element = user_info_elements[0] message['message_user_id'] = user_info_element.attrib['data-user_id'] message['message_user_name'] = user_info_element.attrib['data-user_name'] .replace('\t','') message['message_user_link'] = user_info_element.attrib['href'] message['message_user_class'] = user_info_element.attrib['class'] .replace('\t','') else: user_info_element = message_element .xpath(".//span[@class = 'anonym-user']/text()")[0] message['message_user_id'] = '' message['message_user_name'] = user_info_element.replace('\t','') message['message_user_link'] = '' message['message_user_class'] = 'anonym-user' message_text_elements = message_element .xpath(".//div[@class = 'message-text']") if len(message_text_elements) == 1: message_text_element = message_text_elements[0] message_text = message_text_element.xpath("table/tbody/tr/td/text()") + message_text_element.xpath("text()") message['message_text'] = ''.join(message_text).replace('\t',' ') .replace('\n',' ').replace('( )','') .replace('()','').strip() #answer_link_elements = message_text_element .xpath(".//a[@class='answer-link interlink']") inner_link_elements = message_text_element .xpath(".//a[@class='interlink']") inner_link_list = list() for inner_link_element in inner_link_elements: inner_link_list.append(inner_link_element.attrib['href'] .replace('#','')) other_link_elements = message_text_element .xpath(".//a[not(@class='interlink') and not(@class='answer-link interlink')]") other_link_list = list() for other_link_element in other_link_elements: other_link_list.append(other_link_element.attrib['href']) message['message_reply_to'] = ' '.join(inner_link_list) message['message_external_links'] = ' '.join(other_link_list) else: message['message_text'] = '' message['message_user_name'] = 'HIDDEN MESSAGE' message['message_reply_to'] = '' message['message_external_links'] = '' message_list.append(message) return message_list if __name__ == "__main__": for line in sys.stdin: try: topic_id, page_number, link, source = line.strip().split('\t') except Exception as e: continue if source == '<html xmlns="http://www.w3.org/1999/xhtml"><head></head><body> .</body></html>': message_list = list() message = get_empty_message() message_list.append(message) else: try: message_list = get_list_of_messages_on_page(source) except Exception as e: message_list = list() message = get_empty_message() message['message_user_name'] = 'ERRORERRORERROR' message['message_text'] = str(e) message_list.append(message) for message in message_list: # 12 columns print ('%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s\t%s' % ( topic_id , page_number , link , message['message_id'] , message['message_date_time'] , message['message_user_name'] , message['message_user_id'] , message['message_user_class'] , message['message_text'] , message['message_reply_to']
Hadoop Streaming job . 12 :
gomista@cluster-west-m:~/mista/mapreduce$ ./parser_pages_lxml_run.sh Removing gs://mistabucket-west/output_mid/#1516326888923617... Removing gs://mistabucket-west/output_mid/_temporary/#1516326889037377... Removing gs://mistabucket-west/output_mid/_temporary/1/#1516326889036731... / [3 objects] Operation completed over 3 objects. 13/01/19 02:03:41 INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.6.2-ha... packageJobJar: [] [/usr/lib/hadoop-mapreduce/hadoop-streaming-2.8.2.jar] /tmp... 13/01/19 02:03:42 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 02:03:42 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 02:03:46 INFO mapred.FileInputFormat: Total input files to process :... 13/01/19 02:03:48 INFO mapreduce.JobSubmitter: number of splits:238 13/01/19 02:03:48 INFO mapreduce.JobSubmitter: Submitting tokens for job: job... 13/01/19 02:03:49 INFO impl.YarnClientImpl: Submitted application application... 13/01/19 02:03:49 INFO mapreduce.Job: The url to track the job: http://cluste... 13/01/19 02:03:49 INFO mapreduce.Job: Running job: job_1516327218763_0001 13/01/19 02:04:07 INFO mapreduce.Job: Job job_1516327218763_0001 running in u... 13/01/19 02:04:07 INFO mapreduce.Job: map 0% reduce 0% ... 13/01/19 02:05:24 INFO mapreduce.Job: map 9% reduce 0% 13/01/19 02:05:30 INFO mapreduce.Job: map 10% reduce 0% ... 13/01/19 02:13:04 INFO mapreduce.Job: map 90% reduce 0% ... 13/01/19 02:14:12 INFO mapreduce.Job: map 99% reduce 0% 13/01/19 02:14:22 INFO mapreduce.Job: map 100% reduce 0% 13/01/19 02:14:29 INFO mapreduce.Job: map 100% reduce 2% ... 13/01/19 02:14:52 INFO mapreduce.Job: map 100% reduce 99% 13/01/19 02:14:53 INFO mapreduce.Job: map 100% reduce 100% 13/01/19 02:15:00 INFO mapreduce.Job: Job job_1516327218763_0001 completed su... 13/01/19 02:15:01 INFO mapreduce.Job: Counters: 56 File System Counters FILE: Number of bytes read=6193967355 FILE: Number of bytes written=12426341774 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 GS: Number of bytes read=31919556146 GS: Number of bytes written=6110532053 GS: Number of read operations=0 GS: Number of large read operations=0 GS: Number of write operations=0 HDFS: Number of bytes read=28798 HDFS: Number of bytes written=0 HDFS: Number of read operations=238 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Killed map tasks=8 Killed reduce tasks=1 Launched map tasks=246 Launched reduce tasks=23 Rack-local map tasks=246 Total time spent by all maps in occupied slots (ms)=143665988 Total time spent by all reduces in occupied slots (ms)=5776576 Total time spent by all map tasks (ms)=35916497 Total time spent by all reduce tasks (ms)=722072 Total vcore-milliseconds taken by all map tasks=35916497 Total vcore-milliseconds taken by all reduce tasks=722072 Total megabyte-milliseconds taken by all map tasks=36778492928 Total megabyte-milliseconds taken by all reduce tasks=1478803456 Map-Reduce Framework Map input records=1062462 Map output records=16828105 Map output bytes=6135355287 Map output materialized bytes=6193998639 Input split bytes=28798 Combine input records=0 Combine output records=0 Reduce input groups=957787 Reduce shuffle bytes=6193998639 Reduce input records=16828105 Reduce output records=16828105 Spilled Records=33656210 Shuffled Maps =5236 Failed Shuffles=0 Merged Map outputs=5236 GC time elapsed (ms)=120521 CPU time spent (ms)=10644810 Physical memory (bytes) snapshot=111635165184 Virtual memory (bytes) snapshot=682604023808 Total committed heap usage (bytes)=89146138624 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=31919556146 File Output Format Counters Bytes Written=6110532053 13/01/19 02:15:01 INFO streaming.StreamJob: Output directory: gs://mistabucke... packageJobJar: [] [/usr/lib/hadoop-mapreduce/hadoop-streaming-2.8.2.jar] /tmp... 13/01/19 02:15:05 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 02:15:06 INFO client.RMProxy: Connecting to ResourceManager at clust... 13/01/19 02:15:06 INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.6.2-ha... 13/01/19 02:15:08 INFO mapred.FileInputFormat: Total input files to process :... 13/01/19 02:15:08 INFO mapreduce.JobSubmitter: number of splits:199 13/01/19 02:15:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job... 13/01/19 02:15:09 INFO impl.YarnClientImpl: Submitted application application... 13/01/19 02:15:09 INFO mapreduce.Job: The url to track the job: http://cluste... 13/01/19 02:15:09 INFO mapreduce.Job: Running job: job_1516327218763_0002 13/01/19 02:15:19 INFO mapreduce.Job: Job job_1516327218763_0002 running in u... 13/01/19 02:15:19 INFO mapreduce.Job: map 0% reduce 0% ... 13/01/19 02:15:48 INFO mapreduce.Job: map 17% reduce 0% ... 13/01/19 02:16:43 INFO mapreduce.Job: map 91% reduce 0% ... 13/01/19 02:17:11 INFO mapreduce.Job: map 100% reduce 100% 13/01/19 02:17:28 INFO mapreduce.Job: Job job_1516327218763_0002 completed su... 13/01/19 02:17:29 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=6193967355 FILE: Number of bytes written=12420328221 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 GS: Number of bytes read=6111257045 GS: Number of bytes written=6110532053 GS: Number of read operations=0 GS: Number of large read operations=0 GS: Number of write operations=0 HDFS: Number of bytes read=18905 HDFS: Number of bytes written=0 HDFS: Number of read operations=199 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Killed map tasks=2 Launched map tasks=200 Launched reduce tasks=22 Rack-local map tasks=200 Total time spent by all maps in occupied slots (ms)=18822720 Total time spent by all reduces in occupied slots (ms)=5538912 Total time spent by all map tasks (ms)=4705680 Total time spent by all reduce tasks (ms)=692364 Total vcore-milliseconds taken by all map tasks=4705680 Total vcore-milliseconds taken by all reduce tasks=692364 Total megabyte-milliseconds taken by all map tasks=4818616320 Total megabyte-milliseconds taken by all reduce tasks=1417961472 Map-Reduce Framework Map input records=16828105 Map output records=16828105 Map output bytes=6135355287 Map output materialized bytes=6193993491 Input split bytes=18905 Combine input records=0 Combine output records=0 Reduce input groups=957787 Reduce shuffle bytes=6193993491 Reduce input records=16828105 Reduce output records=16828105 Spilled Records=33656210 Shuffled Maps =4378 Failed Shuffles=0 Merged Map outputs=4378 GC time elapsed (ms)=116848 CPU time spent (ms)=914030 Physical memory (bytes) snapshot=98494140416 Virtual memory (bytes) snapshot=583041585152 Total committed heap usage (bytes)=78180368384 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=6111257045 File Output Format Counters Bytes Written=6110532053 13/01/19 02:17:29 INFO streaming.StreamJob: Output directory: gs://mistabucke...
, 20 ...
, Spark job. ( ) , :
from pyspark import SparkContext, SparkConf sc =SparkContext() def clear_user_id(line): line[6]=line[6].replace('users.php?id=','') return line rdd = sc.textFile("gs://mistabucket-west/grabbing_results_tsv/messages_dirty/*") \ .map(lambda line: str(line.encode('utf-8')).split("\t")) \ .filter(lambda line: line[3]<>'') \ .map(lambda line: clear_user_id(line)) \ .sortBy(lambda line: (int(line[0]), int(line[1]), int(line[3]))) \ .repartition(100) \ .map(lambda line: '\t'.join(line)) \ .saveAsTextFile("gs://mistabucket-west/grabbing_results_tsv/messages")
Shell :
#!/bin/bash OUT_DIR="gs://mistabucket-west/grabbing_results_tsv/messages" gsutil -m rm -r ${OUT_DIR} > /dev/null gcloud dataproc jobs submit pyspark \ file:///home/gomista/mista/pyspark/clear_messages.py \ --cluster cluster-west \ --region europe-west1
20 2 .
Making a sense
( -) Hive.
:
#!/bin/bash gcloud dataproc jobs submit hive \ --cluster cluster-west \ --region europe-west1 \ --file $1
:
CREATE EXTERNAL TABLE IF NOT EXISTS messages (topic_id INT, page_number INT, link STRING, message_id INT, message_date_time TIMESTAMP, message_user_name STRING, message_user_id STRING, message_user_class ARRAY<STRING>, message_text STRING, message_reply_to ARRAY<STRING>, message_external_links ARRAY<STRING>) COMMENT 'Data contains users messages' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION 'gs://mistabucket-west/grabbing_results_tsv/messages';
:
SELECT COUNT(*) FROM messages;
結果:
+-----------+--+ | c0 | +-----------+--+ | 16576543 | +-----------+--+ 1 row selected (51.307 seconds)
" " :
SELECT DATE_FORMAT(message_date_time,'yyyy') AS year, COUNT(message_id) AS total_messages FROM messages GROUP BY DATE_FORMAT(message_date_time,'yyyy') ORDER BY year;
結果:
+-------+-----------------+--+ | year | total_messages | +-------+-----------------+--+ | 2000 | 3412 | | 2001 | 4900 | | 2003 | 5854 | | 2004 | 248704 | | 2005 | 834114 | | 2006 | 1319828 | | 2007 | 1077894 | | 2008 | 1071649 | | 2009 | 1650880 | | 2010 | 1704566 | | 2011 | 1821790 | | 2012 | 2041743 | | 2013 | 1471078 | | 2014 | 1218941 | | 2015 | 834300 | | 2016 | 726237 | | 2017 | 529598 | | 2018 | 11055 | +-------+-----------------+--+ 18 rows selected (100.316 seconds)
. , , 1 8.0. . 2007-2008 . , , 2009 35 . " " , " , " , " " . ( ) , , 2012 .
. 2011 , 2012, , . ? . , 2012 , "" . - , , - " ", "" ( , ). — 2013 . , , , , , , .
2014 , . ? . . 1 , . ( 10 ) " ", , - " " " ", .
— : 500 2017 ( 10 ). , 5% , , , , . :
gomista@cluster-west-m:~$ cat data4 | python bar_chart.py -A # each ∎ represents a count of 665. total 531754 201701 [ 48446] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201702 [ 39747] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201703 [ 49150] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201704 [ 42766] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201705 [ 47175] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201706 [ 43566] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201707 [ 45087] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201708 [ 40789] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201709 [ 40850] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201710 [ 45386] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201711 [ 43041] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201712 [ 43595] ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎ 201801 [ 2156] ∎
, , 50 100 . , , , 20 5.
— SparkSQL. SparkSQL, , Hive , hive
spark-sql
gcloud dataproc jobs submit hive
. , :
2000 3412 2001 4900 2003 5854 2004 248704 2005 834114 2006 1319828 2007 1077894 2008 1071649 2009 1650880 2010 1704566 2011 1821790 2012 2041743 2013 1471078 2014 1218941 2015 834300 2016 726237 2017 529598 2018 11055 Time taken: 22.113 seconds, Fetched 18 row(s)
— 22 SparkSQL 100 Hive. , in-memory computation MapReduce.
, — BigQuery. Google Cloud Storage, Standard SQL . BigQuery SQL . — ( , GCS) ( ). 1 10 — .
, , ( ) , BigQuery supports loading and exporting nested and repeated data in the form of JSON and Avro files
. すなわち message_user_class
, message_reply_to
, message_external_links
, , . 5 :
#!/bin/bash bq load \ --field_delimiter "\t" \ --quote '' \ --source_format CSV mistadataset.messages \ gs://mistabucket-west/grabbing_results_tsv/messages/part-* \ topic_id:INTEGER,\ page_number:INTEGER,\ link:STRING,\ message_id:INTEGER,\ message_date_time:TIMESTAMP,\ message_user_name:STRING,\ message_user_id:STRING,\ message_user_class:STRING,\ message_text:STRING,\ message_reply_to:STRING,\ message_external_links:STRING
:
gomista@cluster-west-m:~$ bq show mistadataset.messages Table new-mista-project:mistadataset.messages Last modified Schema Total Rows Total Bytes ----------------- ----------------------------------- ------------ ------------ 20 Jan 06:31:57 |- topic_id: integer 16576543 6013007928 |- page_number: integer |- link: string |- message_id: integer |- message_date_time: timestamp |- message_user_name: string |- message_user_id: string |- message_user_class: string |- message_text: string |- message_reply_to: string |- message_external_links: string
, :
gomista@cluster-west-m:~$ bq query 'SELECT COUNT(*) FROM mistadataset.messages' Waiting on bqjob_r3390fd1a48d7adbf_000001611c99d989_1 ... (0s) Current status: D +----------+ | f0_ | +----------+ | 16576543 | +----------+
, :
gomista@cluster-west-m:~$ bq query 'SELECT YEAR(message_date_time) AS year, COUNT(message_id) AS total_messages FROM [new-mista-project:mistadataset.messages] GROUP BY year ORDER BY year, total_messages' Waiting on bqjob_rbad1e81f2c9554d_000001611c9c09eb_1 ... (0s) Current status: DONE +------+----------------+ | year | total_messages | +------+----------------+ | 2000 | 3412 | | 2001 | 4900 | | 2003 | 5854 | | 2004 | 248704 | | 2005 | 834114 | | 2006 | 1319828 | | 2007 | 1077894 | | 2008 | 1071649 | | 2009 | 1650880 | | 2010 | 1704566 | | 2011 | 1821790 | | 2012 | 2041743 | | 2013 | 1471078 | | 2014 | 1218941 | | 2015 | 834300 | | 2016 | 726237 | | 2017 | 529598 | | 2018 | 11055 | +------+----------------+
早く。 Hive MapReduce 20 . , ( , ) .
20 ? :
WITH top_flooders AS ( SELECT message_user_id, COUNT(1) AS num FROM mistadataset.messages WHERE message_user_id <> '' GROUP BY message_user_id ORDER BY num DESC LIMIT 20) SELECT users.user_name, top.num FROM top_flooders AS top INNER JOIN mistadataset.users AS users ON CAST(top.message_user_id AS INT64) = users.user_id ORDER BY num DESC
170 ( ) .
Waiting on bqjob_r37d1101a64142e8e_000001612d891e10_1 ... (2s) Current status: DONE +-------------------+--------+ | user_name | num | +-------------------+--------+ | | 170049 | | | 116586 | | zak555 | 115577 | | Guk | 101166 | | IamAlexy | 99148 | | mishaPH | 94991 | | Mikeware | 89538 | | | 84311 | | skunk | 82373 | | | 80978 | | Aleksey | 71176 | | 1 | 71161 | | mikecool | 70260 | | | 69461 | | NS | 69360 | | | 69062 | | | 64987 | | Fragster | 64890 | | | 63229 | | HADGEHOG s | 60784 | +-------------------+--------+
- — , , .
() . - — , . .
:
gomista@cluster-west-m:~$ bq query 'SELECT topic_id, message_id, message_user_id, message_reply_to FROM [new-mista-project:mistadataset.messages] WHERE message_user_id <> "" LIMIT 10' Waiting on bqjob_r58c79111c4f526bd_000001612d23cda6_1 ... (0s) Current status: DONE +----------+------------+-----------------+------------------+ | topic_id | message_id | message_user_id | message_reply_to | +----------+------------+-----------------+------------------+ | 415686 | 154 | 4810 | 151 | | 420305 | 53 | 16570 | 51 | | 422260 | 164 | 22278 | 160 159 161 163 | | 424934 | 106 | 1906 | 103 | | 628534 | 61 | 66521 | 56 | | 628735 | 21 | 85082 | NULL | | 629695 | 704 | 39974 | 702 | | 415376 | 23 | 3467 | 19 | | 385506 | 95 | 12832 | NULL | | 392876 | 95 | 12204 | 94 | +----------+------------+-----------------+------------------+
message_id
, message_user_id
ID , , message_reply_to
, . message_reply_to
. SQL , Hadoop Streaming ( BigQuery , MapReduce ).
, , :
#!/bin/bash # CREATE CLUSTER bash ../dataproc/create_cluster.sh # SUBMIT JOB BUCKET="gs://mistabucket-west/" MAPPER_FILE="mapper.py" REDUCER_FILE="reducer.py" IN_DIR=${BUCKET}"grabbing_results_tsv/messages" OUT_DIR=${BUCKET}"grabbing_results_tsv/users_to_users" OUT_LOG=out.$(date +"%s%6N").log gsutil rm -r ${OUT_DIR} > /dev/null gsutil cp ${MAPPER_FILE} ${BUCKET}${MAPPER_FILE} gsutil cp ${REDUCER_FILE} ${BUCKET}${REDUCER_FILE} gcloud dataproc jobs submit hadoop \ --cluster cluster-west \ --region europe-west1 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -- \ -D mapred.jab.name="Users to users job" \ -files ${BUCKET}${MAPPER_FILE},${BUCKET}${REDUCER_FILE} \ -mapper ${MAPPER_FILE} \ -reducer ${REDUCER_FILE} \ -input ${IN_DIR} \ -output ${OUT_DIR} > /dev/null 2>${OUT_LOG} gsutil cp ${OUT_LOG} ${BUCKET}"logs/"${OUT_LOG} gsutil rm ${BUCKET}${MAPPER_FILE} gsutil rm ${BUCKET}${REDUCER_FILE} # DELETE CLUSTER bash ../dataproc/delete_cluster.sh
streaming - Benjamin Bengfort :
import os import sys from itertools import groupby from operator import itemgetter SEPARATOR = "\t" class Streaming(object): @staticmethod def get_job_conf(name): name = name.replace(".", "_").upper() return os.environ.get(name) def __init__(self, infile=sys.stdin, separator=SEPARATOR): self.infile = infile self.sep = separator def status(self, message): sys.stderr.write("reporter:status:{0}\n".format(message)) def counter(self, counter, amount=1, group="Python Streaming"): sys.stderr.write("reporter:counter:{0},{1},{2}\n".format(group, counter, amount)) def emit(self, key, value): sys.stdout.write("{0}{1}{2}\n".format(key, self.sep, value)) def read(self): for line in self.infile: yield line.rstrip('\n') def __iter__(self): for line in self.read(): yield line class Mapper(Streaming): def map(self): raise NotImplementedError("Mappers must implement a map method") class Reducer(Streaming): def reduce(self): raise NotImplementedError("Reducers must implement a reduce method") def __iter__(self): generator = (line.split(self.sep, 1) for line in self.read()) for item in groupby(generator, itemgetter(0)): yield item
. Mapper:
#!/usr/bin/env python import re import os import sys from itertools import groupby from operator import itemgetter from framework import Streaming class Mapper(Streaming): def map(self): for line in self: line = line.split(self.sep) for reply_to_id in line[9].split(' '): if line[6] <> '': # topic_id, message_id, user_id, reply_to self.emit(line[0], '\t'.join((line[3], line[6], reply_to_id))) if __name__ == '__main__': mapper = Mapper(sys.stdin) mapper.map()
Reducer:
#!/usr/bin/env python import re import os import sys from itertools import groupby from operator import itemgetter from framework import Streaming class Reducer(Streaming): def reduce(self): for line in self: try: for key, group in self: message_user = {} for item in group: # extract message_id, user_id, reply_to user_line = item[1].split(self.sep) # put topic_id, user_id, reply_to in dict with message_id message_user[user_line[0]] = (item[0], user_line[1], user_line[2]) iterator = sorted(message_user.iteritems(), key=lambda t: int(t[0])) for message_id, user_line in iterator: # emit topic_id, message_id, user_id, reply_to, user_id_to # (message_id, user_line[1], user_line[2], message_user[user_line[2]]) reply_to = user_line[2] if reply_to <> '' and reply_to in message_user.keys(): user_id = user_line[1] user_id_to = message_user[reply_to][1] if int(user_id) <= int(user_id_to): self.emit(user_line[0], '\t'.join((user_id, user_id_to, message_id, reply_to, '1', '0'))) else: self.emit(user_line[0], '\t'.join((user_id_to, user_id, message_id, reply_to, '0', '1'))) except Exception as e: self.emit("ERROR", str(e)) def __iter__(self): generator = (line.split(self.sep, 1) for line in self.read()) for item in groupby(generator, itemgetter(0)): yield item if __name__ == '__main__': reducer = Reducer(sys.stdin) reducer.reduce()
quick-review BigQuery:
gomista@cluster-west-m:~$ bq query 'SELECT topic_id, user1, user2, mes1, mes2, sender1, sender2 FROM [new-mista-project:mistadataset.users_to_users] LIMIT 10' Waiting on bqjob_r62adcfd4b0bc4e83_000001612d362bc9_1 ... (0s) Current status: DONE +----------+-------+-------+------+------+---------+---------+ | topic_id | user1 | user2 | mes1 | mes2 | sender1 | sender2 | +----------+-------+-------+------+------+---------+---------+ | 102028 | 4810 | 5948 | 110 | 101 | 1 | 0 | | 119073 | 2811 | 4530 | 81 | 78 | 1 | 0 | | 128776 | 5561 | 6398 | 58 | 49 | 1 | 0 | | 131529 | 3566 | 4810 | 42 | 39 | 1 | 0 | | 133787 | 2126 | 10705 | 46 | 38 | 1 | 0 | | 103025 | 3312 | 6101 | 92 | 90 | 0 | 1 | | 116500 | 69 | 8311 | 53 | 52 | 0 | 1 | | 117521 | 69 | 6789 | 52 | 50 | 0 | 1 | | 119073 | 4530 | 4810 | 123 | 121 | 0 | 1 | | 133787 | 2035 | 5985 | 209 | 208 | 0 | 1 | +----------+-------+-------+------+------+---------+---------+
, 69 6789 6789 69 , 69->6789
6789->69
69 6789 1 0
69 6789 0 1
. — 5948, 6789 69.
+----------+-------+-------+------+------+---------+---------+ | topic_id | user1 | user2 | mes1 | mes2 | sender1 | sender2 | +----------+-------+-------+------+------+---------+---------+ | 102028 | 4810 | 5948 | 110 | 101 | 1 | 0 | | 117521 | 69 | 6789 | 52 | 50 | 0 | 1 | +----------+-------+-------+------+------+---------+---------+
, 20 , . . . , (77) , (43)
:
WITH self_messaging AS ( SELECT topic_id, user1, mes1, SUM(CASE WHEN user1=user2 THEN 1 ELSE -1 END) AS num FROM `mistadataset.users_to_users` GROUP BY topic_id, user1, mes1 HAVING SUM(CASE WHEN user1=user2 THEN 1 ELSE -1 END) >= 1), top_fools AS( SELECT user1, SUM(num) AS num FROM self_messaging GROUP BY user1 ORDER BY num DESC LIMIT 20) SELECT users.user_name, top.num FROM top_fools AS top INNER JOIN mistadataset.users AS users ON top.user1 = users.user_id ORDER BY num DESC
結果:
Waiting on bqjob_r22370ed3190e5fd8_000001612d7d126a_1 ... (16s) Current status: DONE +-------------------+------+ | user_name | num | +-------------------+------+ | Garykom | 6066 | | bushd | 4080 | | IamAlexy | 3883 | | Fragster | 3565 | | Guk | 3237 | | Rie | 3219 | | wPa | 3139 | | | 2594 | | smaharbA | 2544 | | trdm | 2321 | | Wobland | 2245 | | opty | 2230 | | Looking | 2120 | | | 2044 | | zak555 | 1955 | | | 1936 | | ado | 1925 | | | 1899 | | Fish | 1818 | | vde69 | 1809 | +-------------------+------+
20 . , . リクエスト:
WITH top_opponents AS( SELECT user1, user2, SUM( sender1) AS sent_by_1, SUM( sender2) AS sent_by_2, SUM( sender1) + SUM( sender2) AS sent_total FROM `mistadataset.users_to_users` WHERE user1 <> user2 GROUP BY user1, user2 ORDER BY sent_total DESC LIMIT 20) SELECT users1.user_name AS user1, users2.user_name AS user2, top.sent_by_1, top.sent_by_2 FROM top_opponents AS top INNER JOIN mistadataset.users AS users1 ON top.user1 = users1.user_id INNER JOIN mistadataset.users AS users2 ON top.user2 = users2.user_id ORDER BY top.sent_total DESC
結果:
Waiting on bqjob_r6ead7fb755f1ff06_000001612d98c243_1 ... (16s) Current status: DONE +------------------+------------------+-----------+-----------+ | user1 | user2 | sent_by_1 | sent_by_2 | +------------------+------------------+-----------+-----------+ | mikecool | Vinianel | 2775 | 2972 | | | | 2870 | 2366 | | | Vinianel | 1921 | 2787 | | Mikeware | | 2614 | 1561 | | | | 2272 | 1743 | | Oftan_Idy | opty | 2003 | 1841 | | NS | opty | 1832 | 1977 | | | Trigg | 1943 | 1791 | | Amra | rphosts | 1593 | 1614 | | Sakura | Amra | 1487 | 1712 | | | Asmody | 1511 | 1665 | | Wobland | | 1627 | 1500 | | mishaPH | zak555 | 1531 | 1516 | | IamAlexy | zak555 | 1361 | 1622 | | romix | opty | 1381 | 1565 | | | Mikk | 1246 | 1663 | | insider | | 1687 | 1138 | | | gr13 | 1111 | 1697 | | | Mikk | 1448 | 1289 | | Guk | | 1220 | 1509 | +------------------+------------------+-----------+-----------+
. , . , . 例:
, , , 1000 , , , 1000 50 50
, , , , , ( ). , ( ) . , , . 2011-2012 ( )… . .
. MyStem — . - pymystem3 , — . . , , mystem = Mystem()
, Spark MapReduce. ( mystem = Mystem()
, mystem
), mystem
MapReduce. .
, ( , ):
#!/bin/bash # SUBMIT JOB BUCKET="gs://mistabucket-west/" MAPPER_FILE="mapper.py" REDUCER_STEM_FILE="reducer_stem.py" IN_DIR=${BUCKET}"grabbing_results_tsv/messages" OUT_DIR=${BUCKET}"grabbing_results_tsv/messages_stemed_pre" gsutil rm -r ${OUT_DIR} > /dev/null gsutil cp ${MAPPER_FILE} ${BUCKET}${MAPPER_FILE} gsutil cp ${REDUCER_STEM_FILE} ${BUCKET}${REDUCER_STEM_FILE} gcloud dataproc jobs submit hadoop \ --cluster cluster-west \ --region europe-west1 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -- \ -D mapred.jab.name="Stem job 1" \ -files ${BUCKET}${MAPPER_FILE},${BUCKET}${REDUCER_FILE} \ -mapper ${MAPPER_FILE} \ -reducer 'cat' \ -input ${IN_DIR} \ -output ${OUT_DIR} gsutil rm ${BUCKET}${MAPPER_FILE} IN_DIR=${BUCKET}"grabbing_results_tsv/messages_stemed_pre" OUT_DIR=${BUCKET}"grabbing_results_tsv/messages_stemed" gsutil rm -r ${OUT_DIR} > /dev/null gcloud dataproc jobs submit hadoop \ --cluster cluster-west \ --region europe-west1 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -- \ -D mapred.jab.name="Stem job 2" \ -files ${BUCKET}${REDUCER_STEM_FILE} \ -mapper '/tmp/mystem -lc' \ -reducer ${REDUCER_STEM_FILE} \ -input ${IN_DIR} \ -output ${OUT_DIR} gsutil rm -r ${IN_DIR} > /dev/null gsutil rm ${BUCKET}${REDUCER_STEM_FILE}
, :
class Mapper(Streaming): def map(self): for line in self: line = line.split(self.sep) # topic_id, message_id, user_id, is link, text self.emit(line[0], '\t'.join((line[3], line[6], str(len(line[10])), line[8]))) if __name__ == '__main__': mapper = Mapper(sys.stdin) mapper.map()
, :
class Reducer(Streaming): def reduce(self): for key, group in self: for item in group: message_id, user_id, islink, words = item[1].split('\t') words = re.sub("[{}]", "", words) words = re.sub("(\\|[^ ]+)", "", words) words = re.sub("\\?", "", words) words = re.sub("\xc2\xa0+", " ", words) words = words.translate(None, string.punctuation) words = re.sub("\\s+", " ", words) self.emit(item[0], '\t'.join((message_id, user_id, islink, words))) def __iter__(self): generator = (line.split(self.sep, 1) for line in self.read()) for item in groupby(generator, itemgetter(0)): yield item if __name__ == '__main__': reducer = Reducer(sys.stdin) reducer.reduce()
10 :
igab@new-mista-project:~$ gsutil cat gs://mistabucket-west/grabbing_results_tsv/messages_stemed/* | head -n 10 119048 4 8519 0 ... 119048 5 2358 0 119048 8 8487 18 119048 6 8487 0 119048 7 2358 0 119073 36 482 0 ... 119073 113 0 ... 119073 112 4530 0 ... 119073 111 4810 0 119073 110 4530 0 5
wordcount:
from collections import namedtuple from pyspark import SparkContext, SparkConf import codecs sc =SparkContext() stopwords_list = sc.textFile('gs://mistabucket-west/stopwords-ru.txt') \ .map(lambda line: line.encode('utf-8')) \ .collect() stopwords_list = [elem.strip() for elem in stopwords_list] stopwords_list = sc.broadcast(stopwords_list) def split_messages(row): words = list() for word in row[4].split(' '): if not word in stopwords_list.value and not word.isdigit() and word != '': word_lower = codecs.encode(codecs.decode(word, 'utf-8').lower(), 'utf-8') words.append((row[0], row[1], row[2], row[3], word_lower)) return words rdd = sc.textFile("gs://mistabucket-west/grabbing_results_tsv/messages_stemed/part-*") \ .map(lambda line: str(line.encode('utf-8')).split("\t")) \ .flatMap(split_messages) \ .map(lambda x:(x[4],1)) \ .reduceByKey(lambda x,y: x+y) \ .map(lambda x: (x[1], x[0])) \ .sortByKey(False) \ .cache() lines = rdd.top(20) for i in lines: print ("{0},{1}".format(i[0], i[1]))
20 (
4 ))):
731312, 560621,1 486599, 398495, 374898, 372843, 367060, 353019, 330404, 325460, 283849, 283676, 277181, 273841, 266892, 265753, 265676, 259497, 257067, 254932, 251058,
"" . , . . , . — / . 4500 , , . , :
WITH top_fuckers AS( SELECT user_id, ARRAY_AGG(DISTINCT(word)) AS word, COUNT(1) AS num FROM mistadataset.words WHERE (word IN ( SELECT word FROM mistadataset.mat)) AND user_id <> '' GROUP BY user_id ORDER BY num DESC LIMIT 100) SELECT ROW_NUMBER() OVER(ORDER BY num DESC) AS tt, users.user_name, CASE WHEN users.user_forum_role = ' ' THEN '' ELSE SUBSTR(users.user_forum_role,1,14) END AS forum_role, top.num, SUBSTR(ARRAY_TO_STRING(top.word, " "), 1, 50) AS words FROM top_fuckers AS top INNER JOIN mistadataset.users AS users ON CAST(top.user_id AS INT64) = users.user_id ORDER BY num DESC LIMIT 20
20 ( ):
igab@new-mista-project:~/mista/bigquery$ cat top_fuckers.q | bq query --use_legacy_sql=false Waiting on bqjob_r72bb841a2e6c91dd_000001613ad70b72_1 ... (5s) Current status: DONE +----+-------------------+----------------+------+------------------------------+ | tt | user_name | forum_role | num | words | +----+-------------------+----------------+------+------------------------------+ | 1 | IamAlexy | | 5218 | ...| | 2 | 1 | | 4305 | ##### ...| | 3 | | - | 3969 | ####### ...| | 4 | Mikeware | | 3931 | ######### ...| | 5 | | | 3785 | ####...| | 6 | mishaPH | - | 3439 | ##### ##########...| | 7 | Guk | - | 3333 | ...| | 8 | | | 3122 | ######...| | 9 | | | 3071 | ##### ...| | 10 | | - | 2967 | ######## ...| | 11 | Oftan_Idy | | 2883 | ###### ...| | 12 | | | 2724 | ##### ...| | 13 | skunk | | 2124 | ...| | 14 | | | 2114 | ########## ######## ######...| | 15 | Maniac | | 2091 | ...| | 16 | | | 2057 | ####### ########...| | 17 | - | | 2042 | ### ...| | 18 | Fragster | - | 2016 | ##### ...| | 19 | | - | 1985 | ########### ##### ...| | 20 | Defender aka LINN | | 1929 | ######### ...| +----+-------------------+----------------+------+------------------------------+
, — ( 1 Mikeware -), . はい .
, ismat
, . リクエスト:
SELECT words.topic_id, words.message_id, words.user_id, words.word, mat.word IS NULL AS ismat FROM mistadataset.words AS words LEFT JOIN mistadataset.mat AS mat ON words.word = mat.word
:
Query Failed Error: Response too large to return. Consider setting destinationTable or (for legacy SQL queries) setting allowLargeResults to true in your job configuration. For more details, see https://cloud.google.com/bigquery/troubleshooting-errors
152107955
4766
. PySpark job :
sc =SparkContext() mat_list = sc.textFile('gs://mistabucket-west/mat.txt') \ .map(lambda line: line.encode('utf-8')) \ .collect() mat_list = [elem.strip() for elem in mat_list] mat_list = sc.broadcast(mat_list) def check_word(row): if row[4] in mat_list.value: return (row[0], row[1], row[2], row[3], row[4], '1') else: return (row[0], row[1], row[2], row[3], row[4], '0') rdd = sc.textFile("gs://mistabucket-west/grabbing_results_tsv/words/part-*") \ .map(lambda line: str(line.encode('utf-8')).split("\t")) \ .map(check_word) \ .map(lambda line: '\t'.join(line)) \ .saveAsTextFile("gs://mistabucket-west/grabbing_results_tsv/words_with_mats")
:
bq load \ --field_delimiter "\t" \ --quote '' \ --source_format CSV mistadataset.words_with_mats \ gs://mistabucket-west/grabbing_results_tsv/words_with_mats/part-* \ topic_id:INTEGER,\ message_id:STRING,\ user_id:STRING,\ islink:STRING,\ word:STRING,\ ismat:INTEGER
, :
WITH mes AS ( SELECT topic_id, message_id, user_id, ARRAY_AGG(word) words, ARRAY_AGG(DISTINCT(word)) words_distinct FROM mistadataset.words_with_mats WHERE ismat = 1 OR word = '' GROUP BY topic_id, message_id, user_id HAVING ARRAY_LENGTH(words_distinct) > 1 AND EXISTS ( SELECT * FROM UNNEST(words) AS x WHERE x = '')), mats_words AS ( SELECT mes.topic_id AS topic_id, mes.message_id AS message_id, mes.user_id AS user_id, flattened_words AS word, 1 AS num FROM mes CROSS JOIN UNNEST(mes.words) AS flattened_words), results AS ( SELECT mats_words.user_id AS user_id, SUM(mats_words.num) AS num, ARRAY_TO_STRING(ARRAY_AGG(DISTINCT(mats_words.word)), " ") AS words FROM mats_words WHERE mats_words.word <> '' GROUP BY user_id ORDER BY num DESC) SELECT ROW_NUMBER() OVER(ORDER BY num DESC) AS tt, users.user_name, CASE WHEN users.user_forum_role = ' ' THEN '' ELSE SUBSTR(users.user_forum_role,1,14) END AS forum_role, top.num, SUBSTR(top.words, 1, 50) AS words FROM results AS top INNER JOIN mistadataset.users AS users ON CAST(top.user_id AS INT64) = users.user_id ORDER BY num DESC LIMIT 20
20 , :
igab@new-mista-project:~/mista/bigquery$ cat top_fuckers_putin.q | bq query --use_legacy_sql=false Waiting on bqjob_r45a530f3ec9955b5_000001613b5f9437_1 ... (0s) Current status: DONE +----+------------------+----------------+-----+--------------------------------+ | tt | user_name | forum_role | num | words | +----+------------------+----------------+-----+--------------------------------+ | 1 | Mikeware | | 143 | #####...| | 2 | | | 116 | ...| | 3 | | - | 100 | ###### ## ### ...| | 4 | | - | 85 | ...| | 5 | Oftan_Idy | | 71 | ######### ...| | 6 | 1 | | 67 | ###### #####...| | 7 | | | 58 | ...| | 8 | Guk | - | 56 | ########### ...| | 9 | | | 49 | ###### ...| | 11 | bushd | | 45 | #### ...| | 10 | IamAlexy | | 45 | ...| | 12 | | | 43 | ...| | 14 | dimoff | | 28 | ######## ...| | 13 | | | 28 | ########## ## ...| | 15 | kot_bcc | - | 27 | #### ...| | 18 | Trigg | | 26 | ## ######## ...| | 17 | Mikk | | 26 | ...| | 16 | | | 26 | ...| | 19 | | | 25 | ...| | 20 | trdm | | 21 | ...| +----+------------------+----------------+-----+--------------------------------+
, . , , . "", " * *** ** , ** ** etc". .
共有する
, , , , - , . . , . , . , - .
:
messages_html — html .
messages — (tsv).
users_html — html .
users — (tsv).
topics — c (tsv).
user_bans — c (tsv).
words — (tsv).
mats — (txt).
stopwords — -(txt).