適切なアーキテクチャで大規模なアプリケーションを作成したくないのはどれですか? 誰もが望んでいます。
ロジックの柔軟性、再利用性、明確性のため。 ドメイン、サービス、それらの相互作用があったこと。
そして時々、私はそれをアーランのようにしたいです。
NodeJのマイクロサービスのフレームワークを作成するというアイデアは、2回以上正常に実装されました。したがって、少なくともSenecaとStudio.jsがあります。これらは確かに優れていますが、大きな論理ユニットを定義します。 一方、 依存性注入または同様の手法によってシステムで共有される通常のオブジェクトがありますが、境界の必要な明確さは提供されません。
時々、「ナノサービス」が必要です。
「ナノサービス」という用語については、この定義を修正します- 「ネットワークを使用せずに、契約の下で同じプロセス内で互いに対話する独立したコンポーネント」 。
実際、これらは最も一般的なオブジェクトですが、まだ違いがあります。「ナノサービス」コンポーネントは、必要な他のサービスの機能を明示的に記述し、エクスポートされたすべての機能を明確にリストします。 コンポーネントは、契約外の何かを行うために別のコンポーネントを要求することはできません。
すべての依存関係は、要求されたものと順序を気にしないフレームワークによって解決されます。唯一の条件は、依存関係グラフが循環してはならず、必要なすべてのサービスがシステム起動前に登録されることです。
「-やめろ!-あなたは言うだろう-そしてマイクロサービスの何が問題なの?
マイクロサービスは、モノリシックアプリケーションを分割するための優れたソリューションであり、タスクを複数のプロセスに分散するのに役立ちます。 ただし、インタラクションにネットワークを使用すると、パフォーマンスが低下し、オーバーヘッドが追加され、インタラクションスタイルに制限が課され、安全でなくなる可能性があります。
さらに-サービスを利用できない状況では、各コンシューマにハンドラが必要です。 さらに、誰が何十ものサービス(プロセス)のインフラストラクチャにサービスを提供し、それらのステータスを監視し、それらの再起動、廃棄などのシナリオは何かという疑問がすぐに生じます。
たとえば、通常のアプリケーションをコンポーネントに分割する場合、マイクロサービスは機能しません。ロギングモジュールの割り当て、データベースへのアクセス、およびバリデーターの個別のマイクロサービスへの割り当ては、問題の間違った解決策のように見えます。 マイクロサービスは、このようなタスクには大きすぎて高価です。
「それでは、なぜ古典的なDIではないのですか?」
はい、依存関係の反転により、オブジェクトの作成作業をフレームワークに移行できますが、使用を制限することはできません。 さらに、かなり頻繁に、コンテナ自体が特定のサービスではなく依存関係であることが判明する場合があります。特定のサービスからは、何かを動的に要求できます。 このようなスタイルは、システム内のコンポーネントを厳密にブロックし、その削除と再利用を事実上不可能にします。
「-代替手段はナノサービスですか?」
確かに、ナノサービスは適切なサイズのツールである可能性があります。
最初に、このアプローチを実装するために作成されたAntiniteフレームワークについて簡単に説明し、次にコードを提供します。
概念的には、概念は次のとおりです。
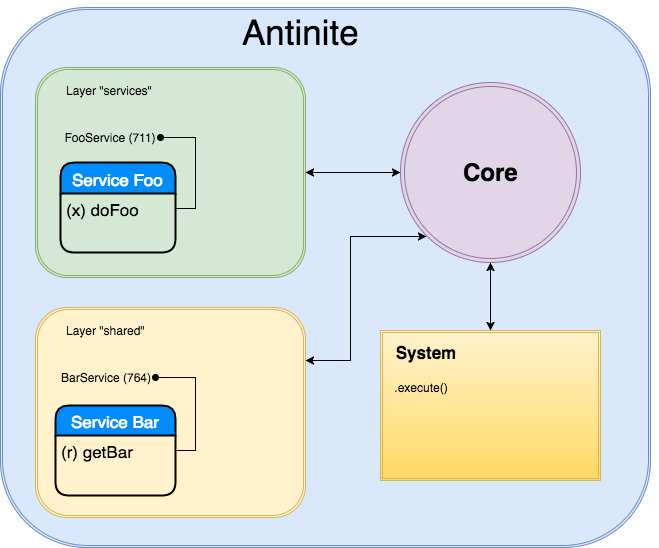
FooおよびBarコンポーネントがあり、それぞれサービスおよび共有ドメインにあります。 コンポーネントは、他のコンポーネントから要求される可能性のあるdoFooおよびgetBarメソッドをエクスポートします。
同様に、ドメインはフレームワークによって登録され、プロセス内で使用可能になりますが、すべての相互作用はコアを通じて発生します。
さらに、フレームワークは、外部からコンポーネントにアクセスする方法を提供し、アプリケーションの中央起動ポイントがコンポーネントと対話できるようにします。
また、コンポーネントメソッドへのアクセス権を共有するためのメカニズムがありますが、それについては後で説明します。
// first service file aka 'foo_service' class FooService { getServiceConfig () { return ({ require: { BarService: ['getBar'] }, export: { execute: ['doFoo'] }, options: { injectRequire : true } }) } doFoo (where) { let bar = this.BarService.getBar() return `${where} ${bar} and foo` } } export default FooService
// first layer file aka 'services_layer' import { Layer } from 'antinite' import FooService from './foo_service' const LAYER_NAME = 'service' const SERVICES = [ { name: 'FooService', service: new FooService(), acl: 711 } ] let layerObj = new Layer(LAYER_NAME) layerObj.addServices(SERVICES)
// second service file aka 'bar_service' class BarService { getServiceConfig () { return ({ export: { read: ['getBar'] } }) } getBar () { return 'its bar' } } export default BarService
// second layer file aka 'shared_layer' import { Layer } from 'antinite' import BarService from './bar_service' const LAYER_NAME = 'shared' const SERVICES = [ { name: 'BarService', service: new BarService(), acl: 764 } ] let layerObj = new Layer(LAYER_NAME) layerObj.addServices(SERVICES)
// main start point aka 'index' import { System } from 'antinite' // load layers, in ANY orders import './services_layer' import './shared_layer' let antiniteSys = new System('mainSystem') antiniteSys.onReady() .then(function() { let res = antiniteSys.execute('service', 'FooService', 'doFoo', 'here') console.log(res) // -> `here its bar and foo` })
コードからわかるように、コンポーネントは通常のオブジェクトであり、いくつかの追加メソッドがあり、ドメインはコンポーネントインスタンスを使用し、中心点はレイヤーをインポートし、システムコールを介して特定のドメインの特定のコンポーネントにアクセスします。
さらに、依存関係コンポーネントのメソッドの呼び出しは、オブジェクトが同期の場合はオブジェクトの単純なメソッド呼び出しです-非同期の場合は同期的に呼び出すことができます-メソッドの実装に応じて、フレームワークはこの点で制限を課しません
「-オーバーヘッドはどうですか?」
フレームワークの主な作業は、すべての依存関係が解決されるアプリケーションの起動時に発生します。 遅延時間はシステムのサイズに依存しますが、一般的には感知できません。 コンポーネントの非同期初期化では追加の遅延が可能です。ここで、遅延はタスクの速度(データベースへの接続、ポートを開くなど)によって決まります。
起動システムのオーバーヘッドは最小限です。 別のコンポーネントのメソッドの実行は、ディクショナリ内のキーによるラッパー関数の検索として発生し、その後、ラッパー関数からのコンポーネントメソッドが直接実行されます。
次に、アクセス権のメカニズムについて説明します。 最初に、コンポーネントは、メソッドをエクスポートする際に、エクスポートカテゴリ-'read'、 'write'、 'execute'を明示的に示すため、システムへの影響の程度に応じてそれらを分離できます。 次に、コンポーネントを登録するとき、レイヤーはコンポーネントのアクセスマスクを示します。たとえば、 「174」 -同じドメインにあるコンポーネントの「実行」カテゴリのメソッドのみがシステムコールで使用できることを示します- 「読み取り」、「 '、' executeと他のドメインのコンポーネントを書き込みます-'read 'カテゴリのメソッドのみ。
したがって、あるドメインのコンポーネントによってエクスポートされた書き込みメソッドは、別のドメインのコンポーネントから呼び出すことはできません。 それに応じて誤って同様のスキームを記述した場合、フレームワークはそれを解決することを拒否します。
このフレームワークには、コードの移植プロセスを容易にするレガシーコードのアシスタントがあります。
さらに、フレームワークの設計は、システムのデバッグを簡素化するのに役立ちます。 すべての依存関係を解決するプロセス用のデバッガーがあり、その助けにより、依存関係の解決がエラーを与える場所が明確になります。
フレームワークの重要な機能は、いつでもシステム監査を有効にし、どのコンポーネントが相互作用し、どのパラメータが転送されるかについての詳細情報を受信できることです。
また、すべてに加えて、システムは現在の依存関係グラフを提供でき、視覚化が容易です。
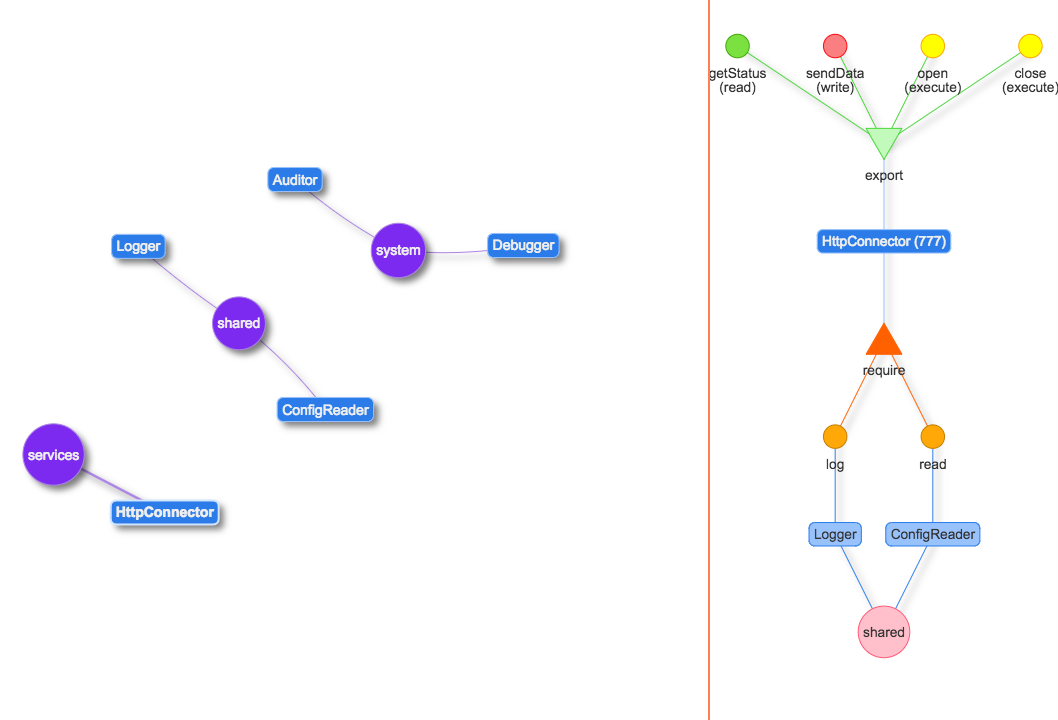
Antinite Visual Toolkitという単純な視覚化アシスタントがあります 。 このライブラリは、おそらく最も成功していない可能性のある視覚化の例として作成されました。
これは、ナノサービスの概念、フレームワークの実装、およびそのためのツールキットが簡単に見える方法です。
質問、提案、追加、批判、提案がある場合は、コメントに反映してください。 さらに、プロジェクトには、 雑談があります。 この時点で、プロトタイプを改善するためのフィードバックが本当に必要です。
Antiniteはgithubで利用可能で、 MITライセンスの下でnpmを介してインストールできます。 このプロジェクトには、詳細なドキュメントと一連のテストが含まれています。
PS。 現在、このフレームワークを使用して作業ドラフトが積極的に開発されていますが、詳細は明らかにできませんが、この段階では問題は特定されていません。
このアーキテクチャにより、リソースを大量に消費するタスクを別のプロセスに実行し、一般的なコードの一部を完全に再利用し、プロセスに応じてプロセス間通信を隠してサービスモックを導入できました。