
過去1年間でTOP 30(0.3%のみ)を選択するために、Mybridgeチームはほぼ8,800のオープンソース機械学習プロジェクトを比較しました。
これは非常に競争の激しいリストであり、2017年1月から12月の間に公開された機械学習、データセット、およびアプリケーションに最適なオープンソースライブラリが含まれています。 プロジェクトの品質を把握するために、Githubスターの平均数は3558であることに注意してください。
オープンソースプロジェクトは、科学者だけでなく役に立つこともあります。 既存のプロジェクトの上に素晴らしいものを追加できます。 昨年見逃したかもしれないプロジェクトをチェックしてください。

注意、カットの下にたくさんの写真とgifがあります。
1. FastText
fastTextは、単語表現を教え、文章を分類するためのライブラリです。これにより、機械学習法を使用して、任意のテキストにカテゴリを自動的に割り当てることができます。 [Githubの星11786]。 Facebook Researchのご厚意によります。

[ ミューズ :高速テキストに基づいた多言語の教師なしまたは教師付きの単語埋め込み。 Githubの星695個]

2.ディープフォトスタイルの転送
科学研究用のコードとデータDeep Photo Style Transfer [Githubの星9747] 。 時刻、天気、季節、芸術的変化の特徴の伝達を含む、さまざまなシナリオでの歪みの抑制とフォトリアリズムの保存に成功した、ある画像から別の画像への写真スタイルの転送のアプローチについて説明します。 メリットフジュンルアン博士 コーネル大学で。

3.顔認識
Python用の世界で最も簡単な顔認識API。 このモデルは、 Labeled Faces in the Wildベンチマークで99.38%の精度を持っています。 また、コマンドラインを使用してフォルダー内の画像から顔を認識することができるシンプルなツールも提供します。 開発者-Adam Geitgey [Githubの星8672] 。

4.マゼンタ
機械学習[Githubの星8113]でアートと音楽を生成します。
5.ソネット
Sonnetは、複雑なニューラルネットワークを構築するためのTensorFlowベースの機械学習ライブラリです。 [Githubの星5731] 。 ディープマインドのマルコム・レイノルズの厚意による

6. deeplearn.js
deeplearn.jsは、Google BrainのNikhil ThoratによるWebGLで高速化されたJavaScriptオープンソースの機械学習ライブラリです。

7. TensorFlowでの高速スタイル転送
TensorFlow [Githubの4843つ星]による高速スタイル転送。 MITのLogan Engstrom。

有名アーティストのスタイルを一瞬で写真に追加しましょう! ビデオを作成することもできます。
8. Pysc2:StarCraft II Learning Environment [3683つ星のGithub] 、DeepMindのTimo Ewalds提供

9. AirSim
AirSimは、Unreal Engineで作成された無人航空機、自動車、その他の車両用のシミュレータです。 物理的および視覚的に現実的なシミュレーションのためのオープンソースプラットフォームです。 目標は、ディープラーニング、コンピュータービジョン、自律型車両システムの誘導学習のアルゴリズムを使用したAIの研究と実験のためのプラットフォームを開発することです。 [Githubの星3861] 。 開発者-MicrosoftのShital Shah
10.ファセット
機械学習の力は、大量のデータのパターンを研究する能力に関連しています。 強力な機械学習システムを作成するには、データを理解することが重要です。 ファセットプロジェクトは、データセットの理解と分析に役立つ信頼性の高い2種類の視覚化を提供します。ファセット概要とファセットダイブです。
可視化は、JupyterノートブックレポートまたはWebページ(TypescriptコードでサポートされているPolymer Webコンポーネント)に簡単に統合できます。
[Githubの星3337] 。 Google Brain提供

FACETS概要レポートのサンプル
11. Style2Paints
画像のAI-coloring [Githubの3310個の星]は、特定の色スタイルに従って色付けしたり、描画用に独自のスタイルを作成したり、サンプルイラストのスタイルを伝えたりできます。

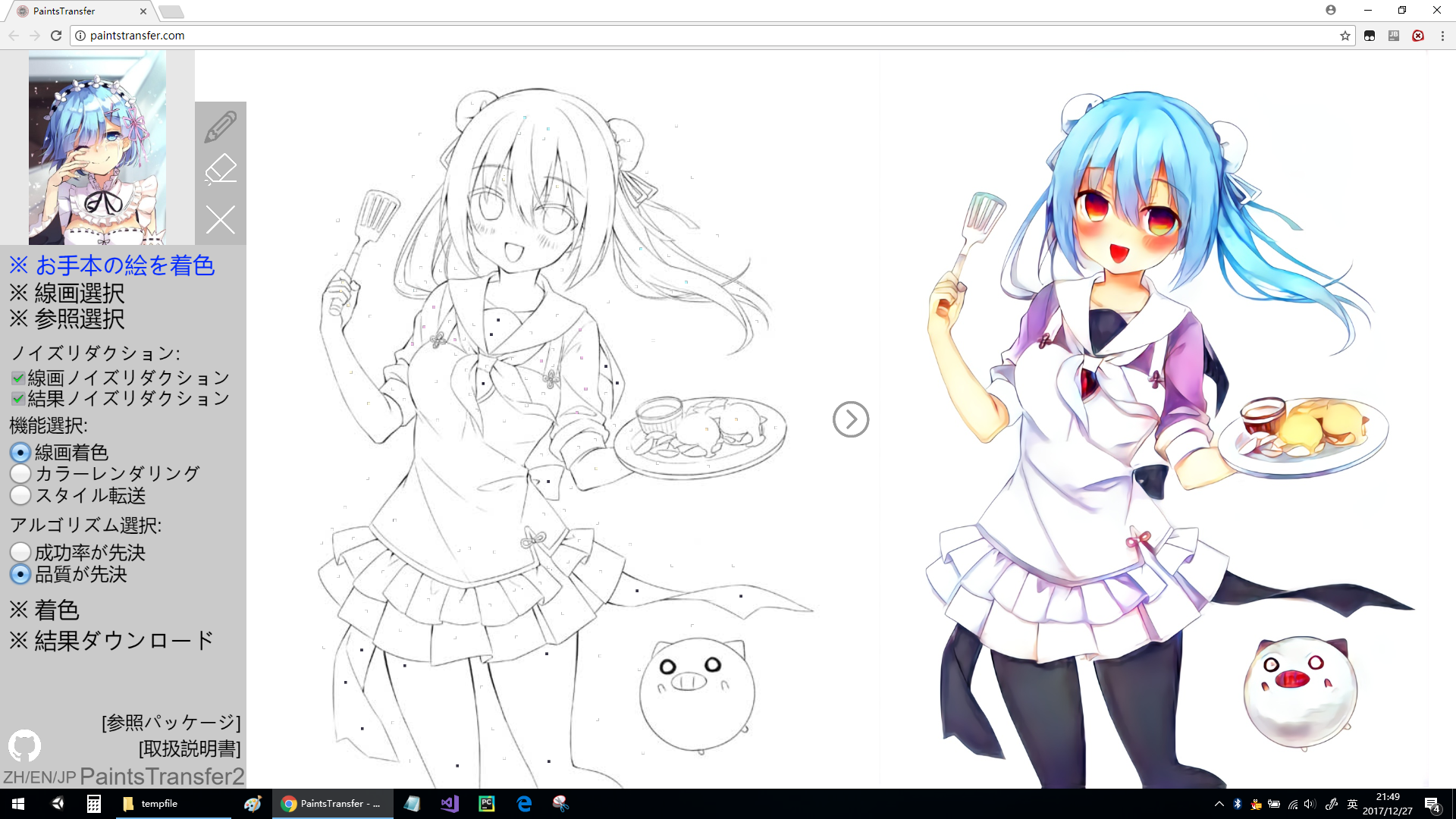

12. Tensor2Tensor
Google Brainチームグループの科学作品「すべてを学習するための1つのモデル」の著者は、「さまざまな分野の問題を解決する深層学習の統一モデルを作成できますか?」
Googleがこれを行い、Tensor2Tensorを公開しました 。コードはGitHubで公開されています 。 [Githubで3087つ星 。
科学記事では、MultiModelのアーキテクチャについて説明しています。これは、異なるドメインからタスクを同時に学習できる深層学習の単一の汎用モデルです。
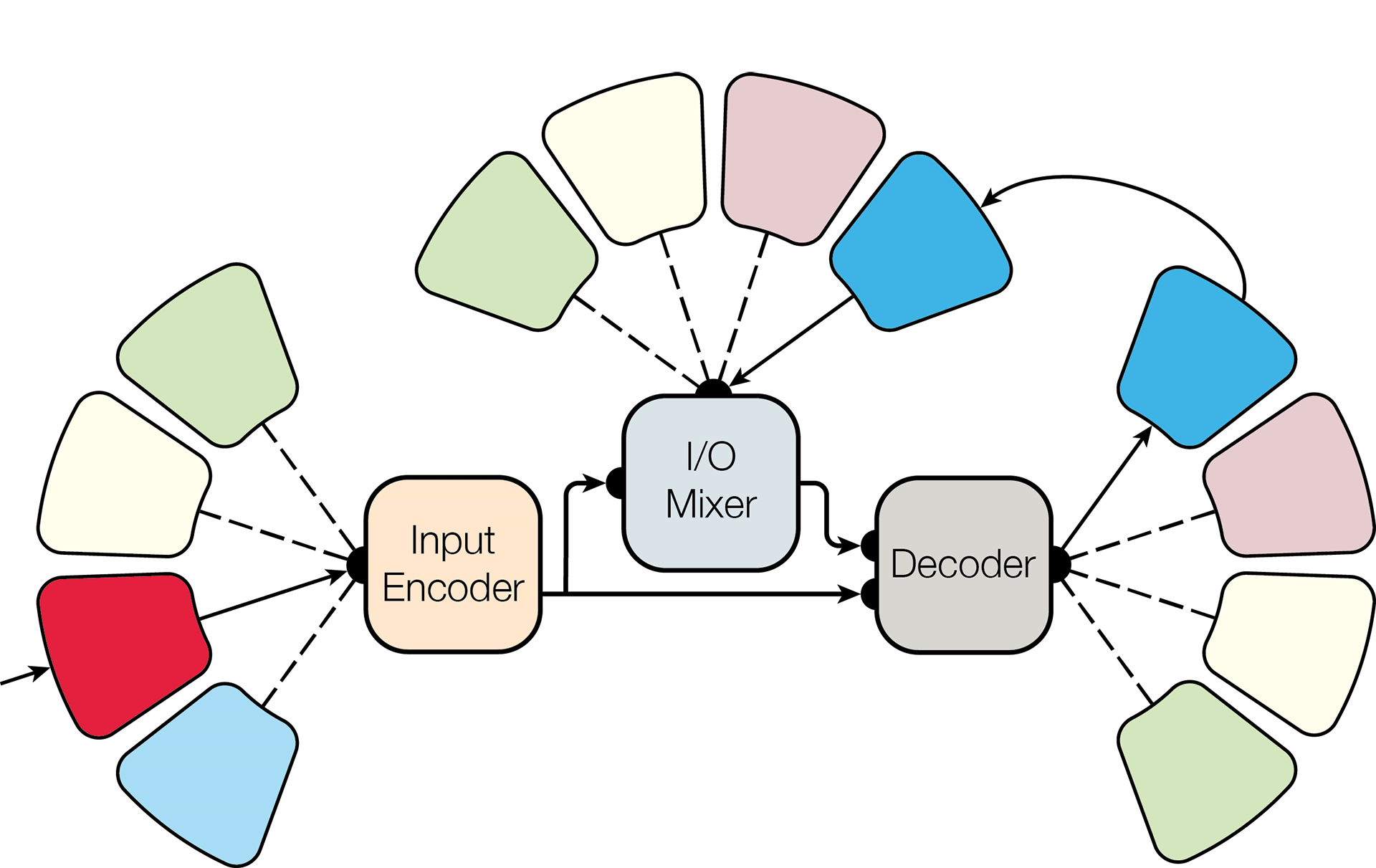
MultiModelアーキテクチャ
特に、研究者はMultiModelをトレーニングして、8つのデータセットを同時にテストしました。
- WSJ音声認識エンクロージャー
- ImageNet画像データベース
- COCOのコンテキストでの通常のオブジェクトのベース
- WSJ解析ベース
- 英語からドイツ語への翻訳隊
- 逆前:ドイツ語から英語への翻訳コーパス
- 英語からフランス語への翻訳コーパス
- 逆前:フランス語から英語への翻訳コーパス
詳細はこちら 。
13. PyTorchでの画像から画像への変換(たとえば、horse2zebra、edges2catsなど)
[Githubの星2847] 。 提供:Jun-Yan Zhu博士、バークレー校

14.フェイス
Faissは、類似性とクラスタリングベクトル[Githubの2629つ星]を効率的に検索するためのライブラリです。 データサイエンスの分野のプログラマや専門家は、よく似たユーザープロファイルを見つけるか、似たような音楽を選択するという課題に直面することがよくあります。 ソリューションは、オブジェクトをベクトル形式に変換し、最も近いものを見つけることに還元できます。 Habréの詳細をご覧ください。

最初と最後の画像が与えられると、アルゴリズムはYFCC100M(9500万枚の画像)からそれらの間の「最もスムーズなパス」を計算します。 ここで撮影。
15.ファッション・ムニスト、ハン・シャオ、研究科学者Zalando Tech
Fashion-MNIST [Githubの2780スター]は 、MNISTが単純すぎるため、MNISTデータベース(「Mixed National Institute of Standards and Technology」の略)の代わりとして提案されています。 Fashion-MNISTのトレーニングとテスト用の画像サイズと構造は同じです。
MNISTは、手書きの数字サンプルの膨大なデータベースです。 このデータベースは、主にニューラルネットワークに基づく機械学習を使用して画像認識方法を調整および比較するために、米国国立標準技術研究所によって提案された標準です。 データは、事前に準備された画像の例で構成され、それに基づいてシステムのトレーニングとテストが実行されます。 データベースは、サイズが20x20ピクセルのNISTの元の白黒サンプルのセットを処理した後に作成されました。 NISTデータベースの作成者は、米国国勢調査局のサンプルセットを使用し、そこにアメリカの大学の学生が書いたテストサンプルを追加しました。 NISTセットのサンプルは正規化され、アンチエイリアス処理され、28x28ピクセルのグレーのハーフトーン画像に縮小されました。
MNISTデータベースには、トレーニング用の60,000個の画像とテスト用の10,000個の画像が含まれています。 トレーニングおよびテストサンプルの半分はNISTトレーニングキットから、残りの半分はNISTテストキットから採取しました。
科学文献で議論されているように、MNISTデータベースのトレーニング後、最小限のエラーを達成するために多くの試みが行われました。 記録的な結果は、畳み込みニューラルネットワークの使用を専門とする出版物に示されており、エラーレベルは0.23%になりました。 データベースの作成者自身がいくつかのテスト方法を提供しています。 元の作業では、サポートベクターメソッドを使用すると、エラーレベル0.8%を達成できることが示されています。

ファッションミスト
16. ParlAI
ParlAIは、さまざまなダイアログ[Githubの星2578]からのデータセットでAIモデルをトレーニングおよび評価するための基盤です。 Facebook ResearchのAlexander Millerのご厚意による

17. Fairseq:Facebook AIリサーチシーケンスツーシーケンスツールキット[Githubの2571つ星]
Facebook AI Research(FAIR)チームは、機械翻訳のための畳み込みニューラルネットワークの実装に関する印象的な結果を公開しています。 彼女は、新しいツールであるfairseqは、従来のリカレントニューラルネットワークよりも9倍高速に動作しますが、精度はわずかに劣っていると主張します。

18. Pyro:PythonとPyTorch [Githubの2387つ星]を使用したディープユニバーサル確率的プログラミング。 Uber AI Labs提供

19. iGAN
インタラクティブな画像生成[Githubの星2369] 。

20.ディープイメージ優先
トレーニングなしのニューラルネットワークを使用した画像回復[Githubの2188個の星 ]。 Skoltechの博士課程Dmitry Ulyanov提供

21. B-IT-BOTSロボットチームによる顔の分類と検出
fer2013 / IMDBデータセット[Githubの1967つ星]を使用した、リアルタイムの顔検出と感情+性別の分類。
性別分類精度(IMDB):96%。
感情の分類の精度(fer2013):66%。

22. Kakao BrainのKim NamjuによるSpeech-to-Text-WaveNet
DeepMindのWaveNetとtensorflowを使用した英語のエンドツーエンドの音声認識[1961 Githubの星] 。

23. StarGAN:マルチドメインの画像から画像への変換のための統合された生成的敵対ネットワーク[Githubの星1954] 。 高麗大学のチェ・ユンジェイ
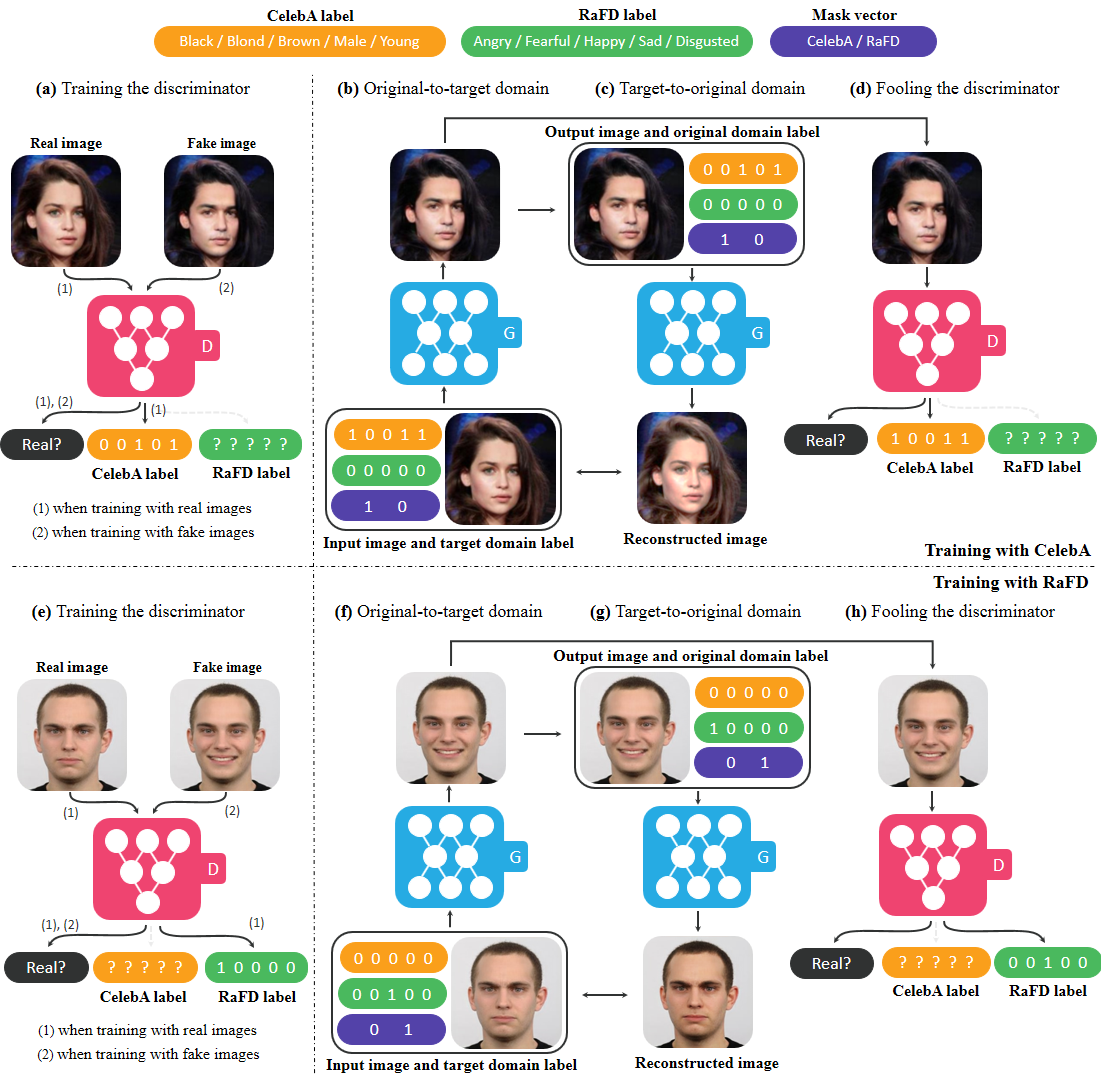

24. Ml-agents:Unity Machine Learning Agent [Githubの星1658] 。 Unity3Dのディープラーニング、アーサージュリアーニ提供
Unity Machine Learning Agentsを使用すると、研究者と開発者は、使いやすいPython APIを使用したUnityエディターを使用して、機械学習用のゲームとシミュレーション環境を作成できます。

25. DeepVideoAnalytics [Githubの星1494] 。 提供:コーネル大学Akshay Bhat博士
視覚データの検索と分析のためのプラットフォーム。

26. OpenNMT:トーチでのオープンソースのニューラル機械翻訳[Githubの1490つ星] 。

27. Pix2pixHD: [Githubの星1283] 。 NvidiaのAIリサーチサイエンティストのMing-Yu Liu
Pix2pixHDは、フォトリアリスティックな合成または高解像度画像(2048x1024など)の変換用に設計されています。 セマンティックラベルカードをフォトリアリスティックな画像に変換したり、顔タグマップを使用してポートレートを合成するために使用できます。

28. Horovod:TensorFlowの分散トレーニングフレームワーク。 [Githubの星1188] 。 Uber Engineering提供

29. AIブロック[Githubの899スター]
誰でも機械学習用のモデルを作成できる、強力で直感的なWYSIWYGインターフェイス。
30. Tensorflowの音声変換(音声スタイル転送)用のディープニューラルネットワーク[Githubの星845個]。 ダビ・アン、Kakao BrainのAI研究

プロジェクトの目標は、音声のスタイルを送信するか、誰かの声を特定の人の声に変換することです。 このプロジェクトの仕事は、有名な英国の女優ケイト・ウィンスレットを声に変えることを目的としました。
免責事項
上記の資料は研究目的のみです。 結果を使用して違法な目標を達成するには、刑事責任、行政責任、および(または)民事責任が伴う場合があります。 著者は、そのような事件について責任を負いません。
