
アロハ、人々! 私の名前はオレグ・アナスタシエフです。プラットフォームチームのオドノクラシニキで働いています。 そして、私以外にも、オドノクラスニキでは多くの鉄が働いています。 4つのデータセンターがあり、約500台のラックと8,000台を超えるサーバーがあります。 ある時点で、新しい管理システムの導入により、機器のより効率的なロード、アクセス制御の促進、コンピューティングリソースの(再)配布の自動化、新しいサービスの立ち上げの加速、大規模な事故に対する反応の加速が可能になることがわかりました。
これは何から来たのですか?
私とたくさんの鉄に加えて、この鉄で働く人々はまだいます。データセンターに直接いるエンジニア。 ネットワークソフトウェアを構成するネットワーク担当者。 インフラストラクチャの復元力を提供する管理者、またはSRE。 開発チームがそれぞれポータルの機能の一部を担当します。 彼らが作成するソフトウェアは次のように機能します。

ユーザーリクエストは、メインポータルwww.ok.ruのフロントと、たとえば音楽APIのフロントの両方で受信されます。 ビジネスロジックを処理するには、アプリケーションサーバーを呼び出します。アプリケーションサーバーは、要求を処理するときに、必要な特殊なマイクロサービス(ワングラフ(ソーシャルコネクションのグラフ)、ユーザーキャッシュ(ユーザープロファイルのキャッシュ)など)を呼び出します。
これらの各サービスは多くのマシンに展開され、各サービスにはモジュールの操作、操作、技術開発を担当する責任ある開発者がいます。 これらのサービスはすべて鉄のサーバーで起動され、最近までサーバーごとに1つのタスク、つまり特定のタスクに特化したタスクを開始しました。
なぜそう このアプローチにはいくつかの利点がありました。
- 大量管理が容易になります。 タスクにいくつかのライブラリ、いくつかの設定が必要だとします。 そして、サーバーは特定の1つのグループに正確に割り当てられ、このグループのcfengineポリシーが記述され(または既に記述されています)、この構成はこのグループのすべてのサーバーに一元的かつ自動的に展開されます。
- 診断が簡素化されます。 中央処理装置の増加した負荷を見て、この鉄製プロセッサで実行されるタスクのみがこの負荷を生成できることを理解するとします。 有罪の調査は非常に迅速に終了します。
- 監視が簡素化されます。 サーバーに何か問題がある場合、モニターはこれを報告し、誰が責任を負うかを正確に把握します。
複数のレプリカで構成されるサービスには、それぞれに1つずつ、複数のサーバーが割り当てられます。 次に、サービスの計算リソースが非常に簡単に割り当てられます。つまり、サービスにいくつのサーバーがあり、可能な限りリソースを消費できるかです。 ここでいう「シンプル」とは、使いやすいという意味ではなく、リソースの割り当てが手動で行われるという意味です。
また、このアプローチにより、このサーバーで実行するタスクに特化した鉄の構成を作成できました。 タスクが大量のデータを保存する場合、38ディスクのシャーシを持つ4Uサーバーを使用します。 タスクが純粋に計算である場合、安価な1Uサーバーを購入できます。 コンピューティングリソースの点で効率的です。 このアプローチを含めると、1つの友好的なソーシャルネットワークに匹敵する負荷で4倍少ない自動車を使用できます。
コンピューティングリソースの使用におけるこのような効率は、最も高価なものがサーバーであるという前提に基づいて、経済的な効率も確保する必要があります。 長い間、最も高価だったのはハードウェアでした。鉄の価格を下げるために多くのエネルギーを投資し、フォールトトレランスを確保して機器の信頼性の要件を減らすアルゴリズムを考案しました。 そして今日、サーバーの価格が決定的ではなくなった段階に到達しました。 新鮮なエキゾチックを考慮しない場合、ラック内のサーバーの特定の構成は重要ではありません。 現在、別の問題があります。データセンターのサーバー占有スペースの価格、つまりラックスペースです。
そのため、ラックの使用効率を計算することにしました。
最も強力なサーバーの価格を経済的に実行可能なサーバーから取得し、ラックに設置できるサーバーの数、「1サーバー= 1タスク」という古いモデルに基づいてそれらで実行するタスクの数、およびそのようなタスクが機器を利用できる量を計算しました。 彼らは泣いていると思った。 ラックを使用した場合の効率は約11%でした。 結論は明らかです。データセンターの使用効率を高める必要があります。 解決策は明らかであるように思われます。同じサーバーで複数のタスクを一度に実行する必要があります。 しかし、ここから困難が始まります。
一括設定は非常に複雑になっています-現在、1つのグループをサーバーに割り当てることはできません。 実際、異なるチームの複数のタスクを1つのサーバーで起動できます。 さらに、異なるアプリケーションでは構成が競合する場合があります。 診断も複雑です。サーバー上のプロセッサまたはディスクの消費量が増えている場合、どのタスクが問題を引き起こしているかわかりません。
しかし、主なことは、同じマシンで実行されているタスク間で分離がないことです。 これは、たとえば、最初のアプリケーションと接続されていない別の計算アプリケーションが同じサーバーで起動された前後のサーバータスクの平均応答時間のグラフです-メインタスクから応答を受信する時間が大幅に増加しました。

明らかに、コンテナまたは仮想マシンでタスクを実行する必要があります。 ほぼすべてのタスクが1つのOS(Linux)の制御下で実行されるか、それに適合しているため、多くの異なるオペレーティングシステムをサポートする必要はありません。 したがって、追加のオーバーヘッドのため、仮想化は必要ありません。コンテナ化よりも効率が低下します。
Dockerサーバーでタスクを直接起動するためのコンテナー実装として、これは良い候補です。ファイルシステムイメージは、構成の競合に関する問題を適切に解決します。 イメージを複数のレイヤーで構成できるという事実により、インフラストラクチャにイメージを展開するために必要なデータ量を大幅に削減し、別々のベースレイヤーの共通部分を強調できます。 その後、ベース(および最も容量の大きい)レイヤーがインフラストラクチャ全体にすばやくキャッシュされ、さまざまな種類のアプリケーションやバージョンを配信するために、小さなサイズのレイヤーのみを転送する必要があります。
さらに、既製のレジストリとDockerのタグ付けイメージは、バージョン管理と本番環境へのコード配信のための既製のプリミティブを提供します。
Dockerは、他の同様のテクノロジーと同様に、コンテナをすぐに使用できる一定レベルの分離を提供します。 たとえば、メモリの分離-各コンテナにはマシンメモリの使用制限が与えられ、それを超えるとメモリは消費されません。 CPUを使用してコンテナを分離することもできます。 確かに、標準的な分離では不十分でした。 しかし、それについては以下で詳しく説明します。
サーバー上でコンテナを直接実行することは、問題の一部にすぎません。 他の部分は、サーバー上のコンテナの配置に関連しています。 どのコンテナーをどのサーバーに配置できるかを理解する必要があります。 これはそれほど簡単な作業ではありません。コンテナをできるだけ密にサーバーに配置する必要がある一方で、作業の速度を低下させないためです。 この配置は、耐障害性の観点から難しい場合があります。 多くの場合、同じサービスのレプリカを異なるラックに配置したり、データセンターの異なるホールに配置したりするため、ラックまたはホールに障害が発生しても、サービスのすべてのレプリカがすぐに失われることはありません。
8000個のサーバーと8〜16,000個のコンテナーがある場合、コンテナーを手動で配布することはできません。
さらに、開発者が管理者の助けを借りずに自分たちでサービスを運用できるように、開発者にリソースの割り当ての自律性を高めたいと考えました。 同時に、一部のマイナーサービスがデータセンターのすべてのリソースを消費しないように、制御を維持したかったのです。
明らかに、これを自動的に行うコントロールレイヤーが必要です。
だから私たちは、すべての建築家が愛するシンプルで理解しやすい画像に到達しました。3つの小さな正方形です。
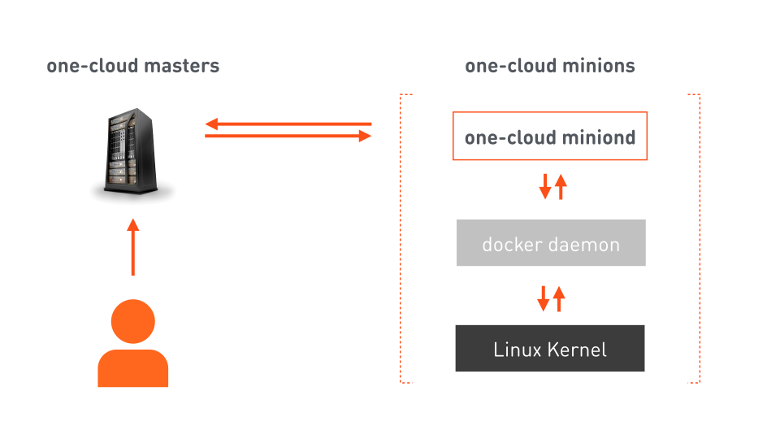
one-cloud mastersは、クラウドオーケストレーションを担当するフェールオーバークラスターです。 開発者は、サービスを配置するために必要なすべての情報を含むマニフェストをマスターに送信します。 それに基づいて、マスターは選択したミニオン(コンテナを起動するように設計されたマシン)にコマンドを提供します。 手先には、コマンドを受け取り、すでにDockerコマンドを提供しているエージェントがいます。Dockerは、対応するコンテナーを起動するようにLinuxカーネルを構成します。 コマンドの実行に加えて、エージェントは、ミニオンマシンとその上で実行されているコンテナの両方の状態の変化についてマスターに継続的に通知します。
リソース割り当て
そして今、私たちは多くの手先のリソースのより複雑な割り当てのタスクを扱います。
ワンクラウドのコンピューティングリソースは次のとおりです。
- 特定のタスクによって消費される計算プロセッサの電力。
- タスクで使用可能なメモリの量。
- ネットワークトラフィック。 各ミニオンには帯域幅が制限された特定のネットワークインターフェイスがあるため、ネットワークを介して送信されたデータ量を考慮せずにタスクを分散することはできません。
- ディスク。 さらに、明らかに、これらのタスクのために、ディスクの種類としてHDDまたはSSDの領域も割り当てます。 ディスクは1秒あたり有限数のリクエストを処理できます-IOPS。 したがって、1つのディスクで処理できる以上のIOPSを生成するタスクの場合、「スピンドル」、つまりタスク専用に予約する必要があるディスクデバイスも選択します。
次に、ユーザーキャッシュなどの一部のサービスでは、消費されたリソースを次の方法で記録できます。400プロセッサコア、2.5 TBのメモリ、両側の50 Gb /秒のトラフィック、100スピンドルにあるHDDの6 TBのスペース。 または、次のようなより馴染みのある形式で:
alloc: cpu: 400 mem: 2500 lan_in: 50g lan_out: 50g hdd:100x6T
ユーザーキャッシュサービスのリソースは、運用インフラストラクチャで利用可能なすべてのリソースのほんの一部を消費します。 したがって、オペレーターのエラーが原因で突然、ユーザーキャッシュが割り当てられたより多くのリソースを消費しないようにしたいと思います。 つまり、リソースを制限する必要があります。 しかし、なぜクォータを割り当てることができますか?
非常に単純化されたコンポーネントインタラクションダイアグラムに戻り、次のように詳細を再描画しましょう。
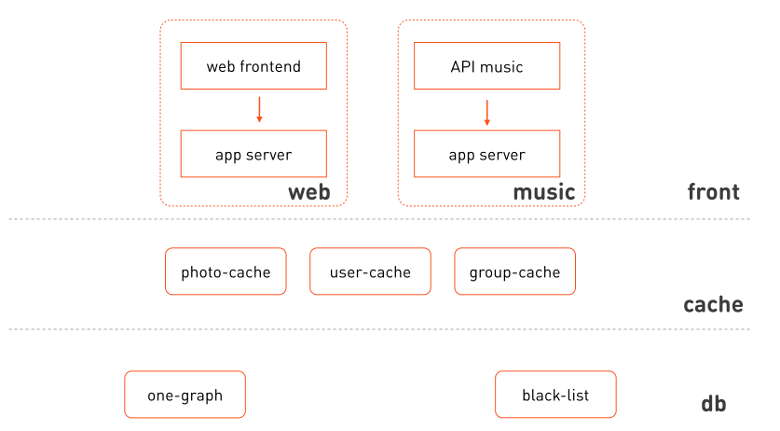
あなたの目を引くもの:
- Webフロントエンドと音楽は、同じアプリケーションサーバーの分離されたクラスターを使用します。
- これらのクラスターが属する論理レイヤー、フロント、キャッシュ、ストレージ、データ管理レイヤーを区別できます。
- フロントエンドは異種であり、これらは異なる機能サブシステムです。
- キャッシュは、キャッシュするデータのサブシステムによって分散することもできます。
もう一度絵を描き直しましょう。
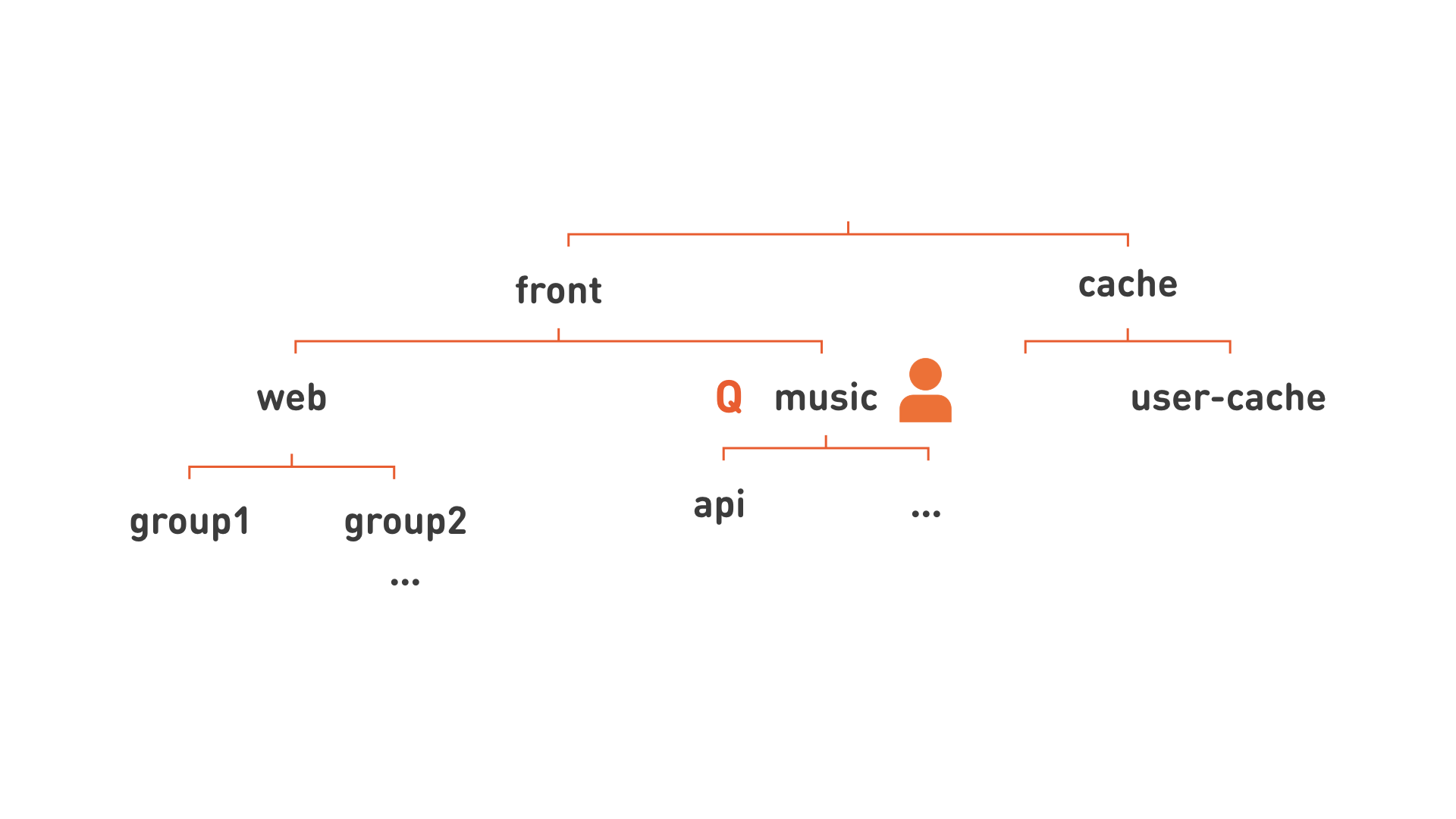
ああ! はい、階層があります! したがって、リソースをより大きな部分に分散できます。機能サブシステム(図の「音楽」など)に対応するこの階層のノードに責任のある開発者を割り当て、同じ階層レベルにクォータを割り当てます。 このような階層により、管理を容易にするためにサービスをより柔軟に編成することもできます。 たとえば、すべてのWebはサーバーの非常に大きなグループ化であるため、図にgroup1、group2として示されているいくつかの小さなグループに分割します。
余分な行を削除したので、画像の各ノードをよりフラットな形式で記述することができます: group1.web.front 、 api.music.front 、 user-cache.cache 。
そこで、「階層型キュー」の概念に取り組みます。 彼女の名前は「group1.web.front」です。 リソースとユーザー権利のクォータが割り当てられます。 DevOpsの人にサービスをキューに送信する権利を与えます。そのような従業員はキューで何かを実行でき、OpsDevの人-管理者権限、そして今、彼はキューを管理し、そこで人を指名し、これらの人に権利を与えることができます。このキューで起動されたサービスは、キュークォータの一部として実行されます。 キューの計算クォータがすべてのサービスの同時実行に十分でない場合、それらは順次実行されるため、キュー自体が形成されます。
サービスをより詳細に検討してください。 サービスには完全修飾名があり、常にキュー名が含まれます。 その場合、フロントWebサービスの名前はok-web.group1.web.frontになります。 そして、彼が参照するアプリケーションサーバーサービスはok-app.group1.web.frontと呼ばれます。 各サービスには、特定のマシンに配置するために必要なすべての情報が示されているマニフェストがあります:このタスクが消費するリソースの数、サービスに必要な構成、レプリカの数、このサービスの障害を処理するためのプロパティ。 そして、サービスをマシンに直接配置すると、そのインスタンスが表示されます。 また、インスタンス番号とサービス名として一意に名前が付けられます: 1.ok-web.group1.web.front、2.ok-web.group1.web.front、...
これは非常に便利です。実行中のコンテナの名前だけを見ると、すぐに多くのことがわかります。
次に、これらのインスタンスが実際に行うこと、つまりタスクについて詳しく見ていきます。
タスク分離クラス
OKのすべてのタスク(およびおそらくどこでも)はグループに分割できます。
- 短遅延タスク-製品 。 このようなタスクとサービスでは、待ち時間が非常に重要です。これは、システムが各要求を処理する速度です。 タスクの例:Webフロント、キャッシュ、アプリケーションサーバー、OLTPストレージなど
- 決済タスク-バッチ 。 ここでは、特定の各リクエストの処理速度は重要ではありません。 彼らにとって、このタスクが一定の(長い)期間に何回計算するか(スループット)が重要です。 これは、MapReduce、Hadoop、機械学習、統計などのタスクになります。
- バックグラウンドタスク-アイドル状態 。 このようなタスクでは、待ち時間もスループットも非常に重要ではありません。 これには、さまざまなテスト、移行、翻訳、ある形式から別の形式へのデータ変換が含まれます。 一方で、それらは決済のものと似ていますが、他方では、それらがどれほど迅速に完了するかはあまり重要ではありません。
そのようなタスクが、たとえば中央処理装置のリソースをどのように消費するかを見てみましょう。
短い遅延のあるタスク。 このようなタスクの場合、CPU消費パターンは次のようになります。
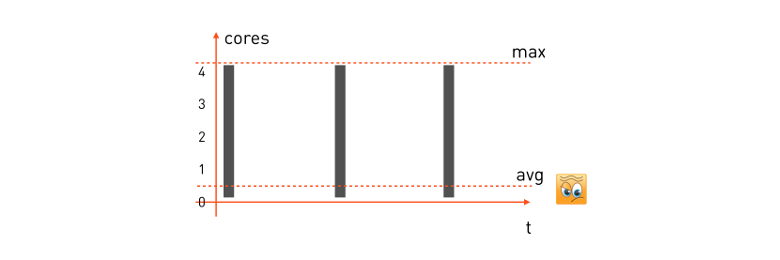
ユーザーが処理のリクエストを受信すると、タスクは使用可能なすべてのCPUコアの使用を開始し、処理し、応答を返し、次のリクエストを待機し、コストをかけます。 次のリクエストが届きました-再び彼らはすべてを選択し、計算し、次を待っています。
このようなタスクの最小遅延を保証するには、消費する最大リソースを取得し、ミニオン(タスクを実行するマシン)で必要な数のコアを予約する必要があります。 次に、タスクの予約式は次のようになります。
alloc: cpu = 4 (max)
16コアのミニオンマシンがある場合、そのようなタスクを正確に4つ配置できます。 そのようなタスクの平均プロセッサ消費は非常に低いことが多いことを強調します。これは、タスクがリクエストを待機して何もしない時間のかなりの部分を占めるためです。
決済タスク。 それらはわずかに異なるパターンを持ちます:

このようなタスクのプロセッサリソースの平均消費量は非常に高くなります。 多くの場合、一定の時間内に計算タスクを完了する必要があるため、許容時間内に計算を完了するために必要な最小数のプロセッサーを予約する必要があります。 彼女の予約式は次のようになります。
alloc: cpu = [1,*)
「少なくとも1つの空きコアがあるミニオンに配置してください。そこにどれだけあると、すべてが飲み込んでしまいます。」
ここでは、使用の効率はすでに、短い遅延のタスクよりもはるかに優れています。 ただし、同じマシンミニオンで両方のタイプのタスクを組み合わせて、外出先でそのリソースを分散すると、ゲインはさらに大きくなります。 短い遅延のタスクにプロセッサが必要な場合-すぐにそれを受け取り、リソースが不要になった場合-計算タスクに転送されます。つまり、次のようなものです。

しかし、それを行う方法は?
最初に、prodとそのallocを見てみましょう:cpu =4。4つのコアを予約する必要があります。 Docker実行では、これは2つの方法で実行できます。
- オプション
--cpuset=1-4
を使用して、つまり、マシン上の4つの特定のカーネルをタスクに割り当てます。 -
--cpuquota=400_000 --cpuperiod=100_000
を使用して、プロセッサ時間のクォータを割り当てます。つまり、リアルタイムが100ミリ秒ごとにタスクがプロセッサ時間を400ミリ秒しか消費しないことを示します。 同じ4つのコアが判明しました。
しかし、これらの方法のどれが適していますか?
かなりかわいいcpusetに見えます。 このタスクには4つの専用コアがあります。つまり、プロセッサキャッシュは可能な限り効率的に動作します。 これには裏返しもあります:OSの代わりにマシンのアンロードされたカーネルに計算を分散するタスクを引き受ける必要があります。これは、特にそのようなマシンにバッチタスクを配置しようとする場合、かなり重要なタスクです。 テストでは、クォータオプションの方が適していることが示されています。オペレーティングシステムは現時点でタスクのカーネルを選択する自由度が高く、プロセッサ時間がより効率的に割り当てられます。
最小数のコアをdockerで予約する方法を見つけます。 最大値を制限する必要はなく、最小値を保証するのに十分であるため、バッチタスクのクォータは適用されなくなりました。 そして、ここでdocker run --cpushares
オプションdocker run --cpushares
。
バッチで少なくとも1つのコアの保証が必要な場合は--cpushares=1024
を指定し、少なくとも2つのカーネルの場合は--cpushares=2048
指定することに--cpushares=2048
。 CPUシェアは、プロセッサ時間の割り当てに十分であれば干渉しません。 したがって、prodが現在4つのコアのすべてを使用していない場合、バッチタスクを制限するものはなく、追加のプロセッサ時間を使用できます。 しかし、プロセッサが不足している状況で、prodが4つのコアすべてを消費してクォータに達した場合、残りのプロセッサ時間はcpusharesに比例して分割されます。 cpushares。
ただし、クォータと共有を使用するだけでは不十分です。 プロセッサ時間の割り当てにおいて、バッチタスクよりも短い遅延のタスクを優先させる必要があります。 このような優先順位付けがないと、バッチタスクは、prodが必要な瞬間にすべてのプロセッサ時間を消費します。 Dockerの実行にはコンテナの優先順位付けオプションはありませんが、Linux CPUスケジューラポリシーが役立ちます。 それらについてはこちらで読むことができますが、この記事の一部としてそれらについて簡単に説明します。
- SCHED_OTHER
デフォルトでは、Linuxマシン上のすべての通常のユーザープロセスが受信されます。 - SCHED_BATCH
要求の厳しいプロセス向けに設計されています。 プロセッサにタスクを配置すると、いわゆるアクティベーションペナルティが導入されます。このようなタスクは、SCHED_OTHERを持つタスクによって現在使用されている場合、プロセッサリソースを受け取る可能性が低くなります。 - SCHED_IDLE
nice –19よりも低い、非常に低い優先度のバックグラウンドプロセス。 呼び出してコンテナを起動するときに必要なポリシーを設定するために、 one-nioオープンソースライブラリを使用します
one.nio.os.Proc.sched_setscheduler( pid, Proc.SCHED_IDLE )
ただし、Javaでプログラミングしていない場合でも、chrtコマンドで同じことができます。
chrt -i 0 $pid
明確にするために、すべての断熱レベルを1つのプレートにまとめましょう。
| 絶縁クラス | 割り当ての例 | Docker実行オプション | sched_setscheduler chrt * |
|---|---|---|---|
| 製品 | CPU = 4 | --cpuquota=400000
--cpuperiod=100000
| SCHED_OTHER |
| バッチ | CPU = [1、*) | --cpushares=1024
| SCHED_BATCH |
| アイドル状態 | CPU = [2、*) | --cpushares=2048
| SCHED_IDLE |
*コンテナ内でchrtを実行する場合、sys_nice機能が必要になる場合があります。これは、デフォルトでは、Dockerがコンテナの起動時にこの機能を無効にするためです。
しかし、タスクはプロセッサだけでなくトラフィックも消費します。これは、ネットワークリソースの遅延に、プロセッサリソースの不適切な割り当て以上に影響を与えます。 したがって、トラフィックについてはまったく同じ状況を取得したいのです。 つまり、prod-taskがネットワークにパケットを送信するとき、prodがこれを実行できる最大速度( alloc:lan = [*、500mbps) )を引用します。 バッチの場合、最小帯域幅のみを保証しますが、最大帯域幅は制限しません( alloc:lan = [10Mbps、*)式)この場合、prodトラフィックはバッチタスクよりも優先されます。
ここで、Dockerには使用できるプリミティブがありません。 しかし、 Linux Traffic Controlは私たちの助けになります。 分野の階層的公正サービス曲線を使用して、望ましい結果を達成することができました。 その助けにより、トラフィックの2つのクラスを区別します。高優先度の製品と低優先度のバッチ/アイドルです。 その結果、発信トラフィックの構成は次のとおりです。

ここで1:0はhsfc分野の「ルートqdisc」です。 1:1-合計帯域幅制限が8 Gbit / sの子クラスhsfc。その下にすべてのコンテナの子クラスが配置されます。 1:2-すべてのバッチおよびアイドルタスクに共通の子クラスhsfcで、「動的」制限があります。 残りのhsfc子クラスは、現在動作しているprodコンテナ専用のクラスであり、マニフェストに対応する制限があります-450および400 Mbit / s。 各hsfcクラスには、Linuxカーネルのバージョンに応じてfqまたはfq_codelに割り当てられたqdiscキューがあり、トラフィックの急増時のパケット損失を防ぎます。
通常、tc分野はアウトバウンドトラフィックのみを優先します。 ただし、着信トラフィックにも優先順位を付ける必要があります。結局、バッチタスクは、たとえばmap&reduceの入力データの大きなパケットを受信して、着信チャネル全体を簡単に選択できます。 これを行うには、 ifbモジュールを使用します。このモジュールは、各ネットワークインターフェイスに仮想ifbXインターフェイスを作成し、インターフェイスからの着信トラフィックをifbXの発信トラフィックにリダイレクトします。 さらに、ifbXの場合、発信トラフィックを制御するために同じ分野がすべて機能します。hsfcの構成は非常に似ています。
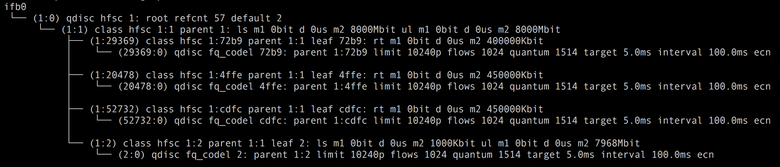
実験の過程で、非優先バッチ/アイドルトラフィックのクラス1:2がミニオンマシンで特定の空き帯域以下に制限されている場合、hsfcが最良の結果を示すことがわかりました。 それ以外の場合、非優先トラフィックはprodタスクの遅延に大きな影響を与えます。 フリーバンドminiondの現在の値は1秒ごとに決定され、このミニオンのすべてのprodタスクによる平均トラフィック消費量を測定します そして、ネットワークインターフェース帯域幅からそれを引きます 小さなマージンで、すなわち
帯域は、着信トラフィックと発信トラフィックに対して個別に決定されます。 そして、新しい値に従って、miniondは非優先クラスの制限1:2を再構成します。
したがって、3つの分離クラス(prod、batch、およびidle)をすべて実装しました。 これらのクラスは、タスクのパフォーマンスに大きく影響します。 したがって、この機能を階層の最上部に配置することにしました。これにより、階層キューの名前を見ると、処理対象がすぐに明確になります。
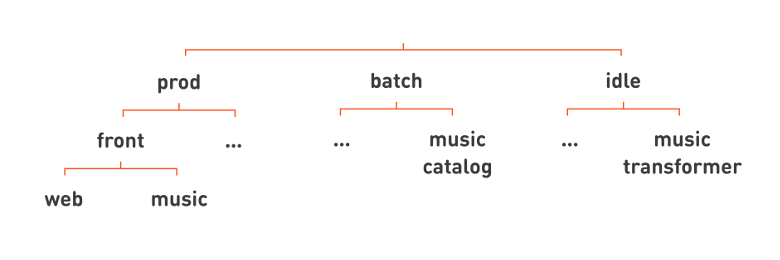
その後、おなじみのウェブと音楽の面はすべて、prodの下の階層に配置されます。 たとえば、バッチの下に、Odnoklassnikiにアップロードされた一連のmp3ファイルからトラックのカタログを定期的にコンパイルする音楽カタログサービスを配置しましょう。 また、アイドル状態のサービスの例は、 音楽の音量レベルを正規化する音楽トランスフォーマーです。
余分な行を再度削除したら 、サービスの名前をよりフラットに記述し、完全なサービス名の最後にタスクの分離クラスを追加できます: web.front.prod 、 catalog.music.batch 、 transformer.music.idle 。
そして今、サービスの名前を見ると、サービスが実行する機能だけでなく、その重要性などを意味する分離クラスも理解しています。
すべてが素晴らしいですが、一つの厳しい真実があります。 同じマシンで実行されているタスクを完全に分離することは不可能です。
私たちが何とか達成したのは、バッチがプロセッサリソースのみを集中的に消費する場合、組み込みのLinux CPUスケジューラがその仕事を非常にうまく行い、prodタスクに実質的に影響がないことです。 しかし、このバッチタスクがメモリでアクティブに動作し始めた場合、相互の影響はすでに現れています。 これは、prodタスクがプロセッサのメモリキャッシュを「洗い流した」ためです。その結果、キャッシュの増加を見逃し、プロセッサがprodタスクをよりゆっくりと処理します。 このようなバッチタスクにより、一般的なprodコンテナの遅延が10%増加する可能性があります。
最新のネットワークカードには内部パケットキューがあるため、トラフィックの分離はさらに困難です。 バッチタスクからのパケットが最初に到着した場合、それが最初であり、ケーブルで送信され、何もする必要はありません。
さらに、これまでのところ、TCPトラフィックの優先順位付けのタスクのみを解決できました。UDPの場合、hsfcアプローチは機能しません。 また、TCPトラフィックの場合でも、バッチタスクで大量のトラフィックが生成されると、prodタスクの遅延が約10%増加します。
耐障害性
ワンクラウドの開発における目標の1つは、Odnoklassnikiの回復力を向上させることでした。 したがって、さらに障害や事故の可能性のあるシナリオをさらに詳しく調べたいと思います。 単純なシナリオから始めましょう-コンテナーの障害。
コンテナ自体はいくつかの方法で失敗する場合があります。 これは、ある種の実験、バグ、またはマニフェストのエラーである可能性があります。そのため、prod-taskはマニフェストに示されているよりも多くのリソースを消費し始めます。 開発者が1つの複雑なアルゴリズムを実装し、何度も作り直し、自分自身を覆い隠して混乱させたため、最終分析でタスクが非常に重要なループになりました。 また、prodタスクは同じミニオンの他のすべてのタスクよりも優先度が高いため、使用可能なすべてのプロセッサリソースを消費し始めました。 この状況では、分離が保存されるか、プロセッサ時間のクォータが節約されます。 タスクにクォータが割り当てられている場合、タスクはそれ以上消費しません。 したがって、同じマシンで動作するバッチおよびその他のprodタスクは何も気付きませんでした。
2番目の可能性のある迷惑は、コンテナの落下です。 そして、ここで政治家が私たちを救ってくれます、誰もが知っています、Dockerは非常にうまくやっています。 ほとんどすべてのprodタスクには、常に再起動ポリシーがあります。 バッチタスクやprodコンテナのデバッグにon_failureを使用する場合があります。
そして、ミニオン全体にアクセスできない場合、何ができますか?
明らかに、コンテナを別のマシンで実行します。 ここで最も興味深いのは、コンテナに割り当てられたIPアドレスがどうなるかです。
これらのコンテナが実行されるミニオンマシンと同じIPアドレスをコンテナに割り当てることができます。 次に、コンテナが別のマシンで起動すると、そのIPアドレスが変更され、すべてのクライアントがコンテナが移動したことを理解する必要があります。今度は別のアドレスに移動する必要があります。
サービス検出は便利です。 サービスのレジストリを整理するためのさまざまな程度のフォールトトレランスを備えた市場には多くのソリューションがあります。 多くの場合、このようなソリューションでは、ロードバランサーのロジックが実装され、KVストアの形式で追加の構成が保存されます。
ただし、個別のレジストリを実装する必要はありません。これは、本番環境のすべてのサービスで使用される重要なシステムの導入を意味するためです。 これは、これが潜在的な障害点であり、非常に耐障害性のあるソリューションを選択または開発する必要があることを意味します。
もう1つの大きな欠点は、古いインフラストラクチャが新しいインフラストラクチャと連動するために、何らかの種類のサービスディスカバリシステムを使用するためのすべてのタスクを完全に書き直す必要があることです。 たくさんの作業があり、OSのカーネルレベルまたはハードウェアで直接動作する低レベルのデバイスに関しては不可能な場合があります。 サイドカーなどの十分に確立された決定パターンの助けを借りてこの機能を実現すると、場所によっては負荷が増え、場所によっては操作が複雑になり、障害シナリオが増えます。 複雑にしたくなかったので、Service Discoveryの使用をオプションにすることにしました。
one-cloud IP , . . IP-. «»: . — IP-, .
: production. IP- . , .
, IP- . , ( 1.ok-web.group1.web.front.prod, 2.ok-web.group1.web.front.prod, … ), , FQDN, DNS. , IP- DNS-. DNS IP- — , (, , — ). , , — , . , DNS, Service Discovery, , . , , , DNS, IP-.
IP — , , :
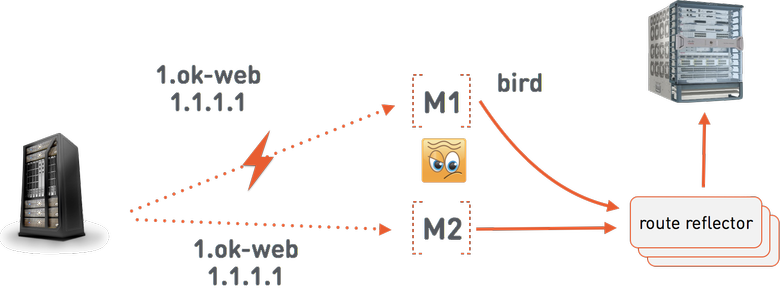
, one-cloud M1 1.ok-web.group1.web.front.prod 1.1.1.1. BIRD , route reflector . BGP- , 1.1.1.1 M1. M1 Linux. route reflector , one-cloud — one-cloud . , -, .
, one-cloud 1 . one-cloud , , 1 . 2 web.group1.web.front.prod 1.1.1.1. 1.1.1.1: 1 2. , Multi Exit Discriminator, BGP-. , . MED. one-cloud MED IP- . MED = 1 000 000. MED, 2 1.1.1.1 c MED = 999 999. , M1, , , .
- . — .
, , -.
-? , . , , , - 100 % .
. - , - , , .
?
, , . - , , . . , .
, .
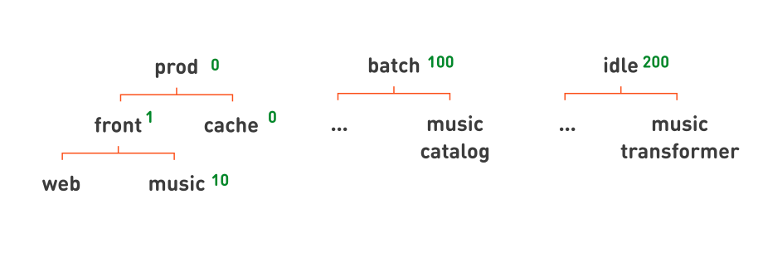
, , , . . prod. — , . - , .
prod , 0; batch — , 100; idle — , 200. . . , prod , cache = 0 front = 1. , , , , music , — 10.
— . , , -, , . , , .
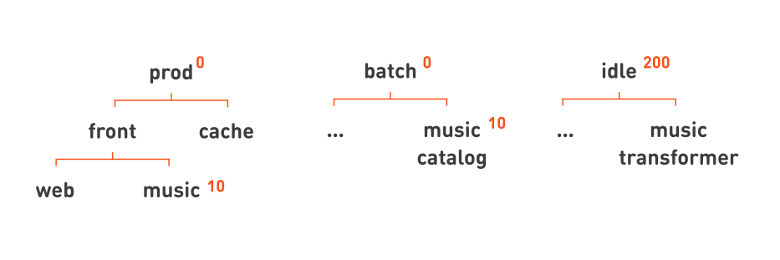
, batch-, . . , . . , . , , , . . .
, prod- batch- idle-, , idle , 200. , , , . , , , -, : 10.
-? . , - . , - , - . : , - . - . , - — . .
, # .
— . one-cloud -. - — -. : , -. .
-, , one-cloud.
, .
? - , , , . , - — , .

まとめ
one-cloud:
- , , , .
- prod- batch- , . cpuset CPU quotas, shares, CPU Linux QoS.
- , , , 20 %.
- .
.
- . prod- , batch idle , -.
- , :
- ;
- «» .
- , , one-cloud.
- Service Discovery; , , — , «» IP-, , , , .
, , , , . — , .
, , — !