以前の記事では、PostgreSQLのインデックス作成メカニズム 、 アクセスメソッドインターフェイス、およびハッシュインデックス 、 Bツリー 、 GiST 、 SP-GiST 、 GIN、 RUMの各メソッドについて見てきました 。 この記事のトピックは、BRINインデックスです。
ブリン
一般的な考え方
すでに会ったインデックスとは異なり、BRINのアイデアは、必要な行をすばやく見つけることではなく、明らかに不要な行を見ることを避けることです。 これは常に不正確なインデックスです。テーブル文字列のTIDはまったく含まれていません。
簡単に言えば、BRINは、値がテーブル内の物理的な場所と相関する列に対して適切に機能します。 つまり、ORDER BY句のないクエリが列の値をほぼ昇順または降順で返す場合(および列にインデックスが存在しない場合)。
このアクセス方法は、ユニットのサイズと数十テラバイトのテーブルに注目して、 Axleの超大規模分析データベースに関する欧州プロジェクトの一環として作成されました。 このようなテーブルにインデックスを作成できるBRINの重要なプロパティは、サイズが小さく、メンテナンスのオーバーヘッドが最小限であることです。
次のように機能します。 テーブルは、いくつかのページ(またはブロック、同じ)のサイズのゾーン (範囲)に分割されます。そのため、名前はBlock Range Index、BRINです。 インデックスの各ゾーンには、このゾーンのデータに関する要約情報が保存されます。 原則として、これは最小値と最大値ですが、後で見るように、異なる方法で発生します。 列の条件を含むクエリを実行するときに、目的の値が範囲内に収まらない場合、ゾーン全体を安全にスキップできます。 その場合、ゾーンのすべてのブロック内のすべての行をレビューして選択する必要があります。
BRINを通常の意味でのインデックスとしてではなく、シーケンシャルテーブルスキャンのアクセラレータとして考えることは間違いではありません。 各ゾーンが個別の「仮想」セクションと見なされる場合、パーティション化の代替として見ることができます。
次に、インデックスデバイスをさらに詳しく見てみましょう。
装置
インデックスの最初の(より正確にはゼロ)は、メタデータのあるページです。
メタデータからある程度のマージンがあるのは、要約情報のあるページです。 各インデックス行には、単一のゾーンの概要が含まれています。
また、メタページと概要データの間には、逆方向範囲マップ(略称revmap)を持つページがあります。 本質的に、これは対応するインデックス行へのポインター(TID)の配列です。
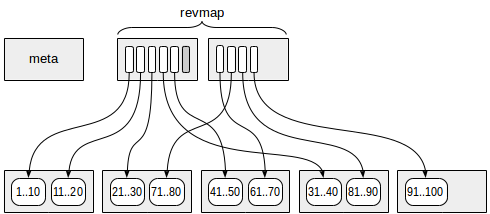
一部のゾーンでは、revmapのポインターがインデックス行につながっていない場合があります(図のグレーで表示)。 この場合、このゾーンの統合情報はまだないと見なされます。
インデックススキャン
テーブル行への参照が含まれていない場合、インデックスはどのように使用されますか? もちろん、このアクセス方法は文字列を1つずつ返すことはできませんが、ビットマップを作成することはできます。 ビットマップページには、正確-行に対して-および不正確-ページに対して2つのタイプがあります。 使用されるのは不正確なビットマップです。
アルゴリズムは簡単です。 ゾーンのマップは順次スキャンされます(つまり、ゾーンはテーブル内の位置の順にソートされます)。 ポインターを使用して、各ゾーンのサマリー情報を含むインデックス行が定義されます。 ゾーンに目的の値が正確に含まれていない場合、スキップされます。 含めることができる場合(または要約情報がない場合)-ゾーンのすべてのページがビットマップに追加されます。 結果のビットマップは、通常どおりさらに使用されます。
インデックスの更新
さらに興味深いのは、テーブルを変更するときにインデックスを更新する状況です。
行の新しいバージョンを表形式ページに追加するとき 、その行が属するゾーンを特定し、ゾーンマップでサマリー情報を含むインデックス行を見つけます。 これらはすべて単純な算術演算です。 たとえば、ゾーンのサイズが4ページで、13ページに値「42」の行のバージョンが表示されるとします。 ゾーン番号(ゼロから始まる)は13/4 = 3です。これは、revmapでオフセットが3(行の4番目)のポインターを取ることを意味します。
このゾーンの最小値は31、最大値は40です。新しい値42はこれらの制限を超えているため、最大値を更新します(図を参照)。 新しい値が既存のフレームワークに適合する場合、インデックスを更新する必要はありません。
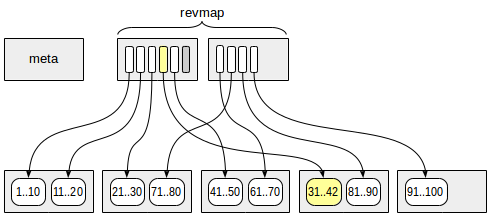
これはすべて、すでに要約情報が存在するゾーンに新しいバージョンのラインが表示される場合に関するものです。 インデックスを作成すると、既存のすべてのゾーンのサマリー情報が計算されますが、テーブルがさらに大きくなると、この範囲を超える新しいページが表示される場合があります。 ここでは2つのオプションが可能です。
- 通常、インデックスの即時更新は行われません。 それには何の問題もありません。 前述したように、インデックスをスキャンすると、ゾーン全体がスキャンされます。 実際、更新はクリーニング中(バキューム)に実行されますが、brin_summarize_new_values関数を呼び出して手動で実行することもできます。
- autosummarizeパラメーターを使用してインデックスを作成すると、更新はすぐに行われます。 ただし、ゾーンページに新しい値を入力すると、更新が非常に頻繁に実行される可能性があるため、このオプションはデフォルトでオフになっています。
新しいゾーンが表示されると、revmapサイズが増加する場合があります。 このカードが割り当てられたページに収まらなくなると、次のカードが「キャプチャ」され、そこにあった行のすべてのバージョンが他のページに移動します。 したがって、ゾーンマップは常にメタページと要約データの間に配置されます。
行を削除するとき ...何も起こりません。 場合によっては、最小値または最大値が削除され、範囲が縮小されることがあります。 しかし、これを判断するには、ゾーン内のすべての値を読み取る必要があり、これは採算が取れません。
インデックスの正確さはこれに影響されませんが、検索時には、実際に必要な数よりも多くのゾーンを調べる必要がある場合があります。 原則として、このようなゾーンでは、サマリー情報を手動で再構成できます(brin_desummarize_rangeおよびbrin_summarize_new_values関数を呼び出します)が、そのような必要性を検出する方法はありますか? いずれにせよ、このための通常の手順は提供されていません。
さて、 行を更新すると、古いバージョンが削除され、新しいバージョンが追加されます。
例
デモデータベースのテーブルに基づいてミニデータウェアハウスを構築してみましょう。 BIレポートの必要性のために、空港から出発するフライトまたは空港に着陸するフライトをキャビン内の場所に正確に反映する非正規化テーブルが必要だとします。 各空港のデータは、適切なタイムゾーンの深夜に到着するとすぐに、1日に1回テーブルに追加されます。 データは変更も削除もされません。
テーブルは次のようになります。
demo=# create table flights_bi(
airport_code char(3), --
airport_coord point, --
airport_utc_offset interval, --
flight_no char(6), --
flight_type text. -- : departure () / arrival ()
scheduled_time timestamptz, -- /
actual_time timestamptz, --
aircraft_code char(3), --
seat_no varchar(4), --
fare_conditions varchar(10), --
passenger_id varchar(20), --
passenger_name text --
);
CREATE TABLE
データのロード手順はネストされたサイクルでシミュレートできます。日単位の外部( 大規模データベースを使用するため、365日かかります)、内部のタイムゾーン(UTC + 02〜UTC + 12)です。 リクエストは非常に長く、あまり関心がないため、ネタバレの下に隠します。
ストレージへのデータ読み込みのシミュレーション
DO $$
<<local>>
DECLARE
curdate date := (SELECT min(scheduled_departure) FROM flights);
utc_offset interval;
BEGIN
WHILE (curdate <= bookings.now()::date) LOOP
utc_offset := interval '12 hours';
WHILE (utc_offset >= interval '2 hours') LOOP
INSERT INTO flights_bi
WITH flight (
airport_code,
airport_coord,
flight_id,
flight_no,
scheduled_time,
actual_time,
aircraft_code,
flight_type
) AS (
--
SELECT a.airport_code,
a.coordinates,
f.flight_id,
f.flight_no,
f.scheduled_departure,
f.actual_departure,
f.aircraft_code,
'departure'
FROM airports a,
flights f,
pg_timezone_names tzn
WHERE a.airport_code = f.departure_airport
AND f.actual_departure IS NOT NULL
AND tzn.name = a.timezone
AND tzn.utc_offset = local.utc_offset
AND timezone(a.timezone, f.actual_departure)::date = curdate
UNION ALL
--
SELECT a.airport_code,
a.coordinates,
f.flight_id,
f.flight_no,
f.scheduled_arrival,
f.actual_arrival,
f.aircraft_code,
'arrival'
FROM airports a,
flights f,
pg_timezone_names tzn
WHERE a.airport_code = f.arrival_airport
AND f.actual_arrival IS NOT NULL
AND tzn.name = a.timezone
AND tzn.utc_offset = local.utc_offset
AND timezone(a.timezone, f.actual_arrival)::date = curdate
)
SELECT f.airport_code,
f.airport_coord,
local.utc_offset,
f.flight_no,
f.flight_type,
f.scheduled_time,
f.actual_time,
f.aircraft_code,
s.seat_no,
s.fare_conditions,
t.passenger_id,
t.passenger_name
FROM flight f
JOIN seats s
ON s.aircraft_code = f.aircraft_code
LEFT JOIN boarding_passes bp
ON bp.flight_id = f.flight_id
AND bp.seat_no = s.seat_no
LEFT JOIN ticket_flights tf
ON tf.ticket_no = bp.ticket_no
AND tf.flight_id = bp.flight_id
LEFT JOIN tickets t
ON t.ticket_no = tf.ticket_no;
RAISE NOTICE '%, %', curdate, utc_offset;
utc_offset := utc_offset - interval '1 hour';
END LOOP;
curdate := curdate + 1;
END LOOP;
END;
$$;
demo=# select count(*) from flights_bi;
count
----------
30517076
(1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty
----------------
4127 MB
(1 row)
3000万行と4 GBが判明しました。 神はその量を知っていますが、ラップトップに適しています。フルスキャンには約10秒かかります。
インデックスを構築する列
BRINインデックスは小さく、オーバーヘッドコストが低く、更新は頻繁に行われないため、たとえば分析ユーザーが作成できるすべてのフィールドに対して、「念のため」多くのインデックスを作成できるのはまれな状況ですアドホックリクエスト。 役に立たない-わかりました、そしてあまり効果的ではないインデックスでさえ、確実にフルスキャンよりもうまく動作します。 もちろん、インデックスがまったく役に立たないフィールドもあります。 単純な常識はそれらを伝えます。
しかし、そのようなアドバイスに自分自身を制限するのは奇妙なことなので、より正確な基準を策定しようとします。
データは、何らかの方法で物理的な場所と相関する必要があると述べました。 ここで、PostgreSQLはテーブルのフィールドに関する統計を収集し、これには相関値も含まれることを思い出してください。 この値は、スケジューラが従来のインデックススキャンとビットマップスキャンのいずれかを選択するために使用され、BRINインデックスの適合性を評価するために使用できます。
この例では、データは明らかに日ごとに並べられています(schedule_timeとactual_timeの両方-差はわずかです)。 これは、テーブルに行を追加するとき(削除および更新がない場合)、それらが順番にファイルに配置されるためです。 負荷のシミュレーションでは、ORDER BY句を使用しませんでした。したがって、原則として、1日以内に日付を好きなように混在させることができますが、順序が存在する必要があります。 チェック:
demo=# analyze flights_bi;
ANALYZE
demo=# select attname, correlation from pg_stats where tablename='flights_bi'
order by correlation desc nulls last;
attname | correlation
--------------------+-------------
scheduled_time | 0.999994
actual_time | 0.999994
fare_conditions | 0.796719
flight_type | 0.495937
airport_utc_offset | 0.438443
aircraft_code | 0.172262
airport_code | 0.0543143
flight_no | 0.0121366
seat_no | 0.00568042
passenger_name | 0.0046387
passenger_id | -0.00281272
airport_coord |
(12 rows)
ゼロに近すぎない値(理想的には、この場合のようにプラスまたはマイナス1程度)は、BRINインデックスが適切であることを示します。
2番目と3番目の場所では、fare_conditionサービスクラス(列に3つの一意の値が含まれています)とフライトタイプflight_type(2つの一意の値)が予期せず見つかりました。 これはトリックです。正式には相関は高いですが、実際には、連続して取られたいくつかのページで、考えられるすべての意味が見つかる可能性があります。つまり、BRINには意味がありません。
次に、airport_utc_offsetタイムゾーンがあります。この例では、同じ日サイクル内で、「建設中」の空港がタイムゾーン順に並べられます。
これら2つのフィールド(時間とタイムゾーン)を使用して、実験を続けます。
相関違反の可能性
データを変更することにより、既存の「構造別」相関を簡単に破ることができます。 ここでのポイントは、特定の値の変更ではなく、マルチバージョンデバイスの場合です。古いバージョンの行は1ページで削除されますが、新しいバージョンは空きスペースがあればどこにでも挿入できます。 このため、更新は行全体を完全にシャッフルします。
部分的に、この現象は、ストレージファクターfillfactorの値を減らすことで対処できます。これにより、将来の更新のためにページ上のスペースのマージンを残します。 しかし、すでに巨大なテーブルのボリュームを増やしたいだけですか? さらに、これは削除の問題を解決しません。新しい行の「トラップを準備」し、既存のページ内のどこかにスペースを解放します。 このため、本来ならファイルの終わりになってしまう行は、任意の場所に挿入されます。
ところで、面白い事実。 BRINインデックスにはテーブル行への参照がないため、その存在はHOT更新を妨げることはありませんが、干渉します。
そのため、まず、BRINは、サイズが大きくて巨大なテーブル用に設計されており、まったく更新されないか、わずかに更新されます。 ただし、(テーブルの最後に)新しい行を追加すると、すばらしい結果が得られます。 このアクセス方法は、データウェアハウスと分析レポートに注目して作成されたため、これは驚くことではありません。
選択するサイズゾーン
テラバイトのテーブルを扱っている場合、おそらくゾーンのサイズを選択する際の主な関心事は、BRINインデックスが大きくなりすぎないようにすることです。 この場合、データをより正確に分析する余裕があります。
これを行うには、一意の列値を選択し、これらの値が表示されるページ数を確認します。 値のローカライズは、BRINインデックスの使用が成功する可能性を高めます。 さらに、見つかったページ数は、ゾーンのサイズを決定するためのヒントとして機能します。 値がテーブルのすべてのページに「広がっている」場合、BRINは役に立ちません。
もちろん、この手法は内部データ構造に公正な目で適用する必要があります。 たとえば、各日付(または、時間を含むタイムスタンプ)を一意の値と考えることは意味がありません。これを日数に丸める必要があります。
純粋に技術的には、このような分析は非表示のctid列の値を調べることで実行でき、行バージョン(TID)へのポインターを提供します:ページ内のページ番号と行番号。 残念ながら、TIDを2つのコンポーネントに分解する通常の方法はないため、テキスト表現を介して型をキャストする必要があります。
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk)
from (
select count(distinct (ctid::text::point)[0]) numblk
from flights_bi
group by scheduled_time::date
) t;
min | avg | max
------+------+------
1192 | 1500 | 1796
(1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages
----------
528172
(1 row)
毎日がページ全体にほぼ均等に分散されており、日がわずかに混ざっていることがわかります(1500×365 =547500。これは、表528172のページ数を大きく上回っていません)。 実際、これはすでに「建設中」に理解できます。
ここで重要な情報は、特定のページ数です。 標準のゾーンサイズは128ページで、毎日9〜14個のゾーンを占有します。 これは適切だと思われます。特定の日をリクエストすると、10%程度のエラーが予想されます。
試してみましょう:
demo=# create index on flights_bi using brin(scheduled_time);
CREATE INDEX
インデックスサイズは184 KBのみです。
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty
----------------
184 kB
(1 row)
この場合、精度を犠牲にしてゾーンのサイズを大きくすることはほとんど意味がありません。 必要に応じて値を減らすことができます。逆に、インデックスのサイズとともに精度が向上します。
次に、タイムゾーンを見てみましょう。 ここでも、「真正面から」行動することはできません。すべての値は毎日の「サイクル」の数で除算する必要があります。これは、分配が毎日繰り返されるためです。 さらに、タイムゾーンがあまりないため、分布全体を確認できます。
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk
from flights_bi
group by airport_utc_offset
order by 2;
airport_utc_offset | numblk
--------------------+--------
12:00:00 | 6
06:00:00 | 8
02:00:00 | 10
11:00:00 | 13
08:00:00 | 28
09:00:00 | 29
10:00:00 | 40
04:00:00 | 47
07:00:00 | 110
05:00:00 | 231
03:00:00 | 932
(11 rows)
平均して、各タイムゾーンのデータは1日あたり133ページを占有しますが、分布は非常に不均一です。ペトロパブロフスク-カムチャツキーとアナディルは6ページのみに収まり、モスクワとその周辺地域では900枚必要です。 ここでは、デフォルトのゾーンサイズは間違いなく適切ではありません。 例として4ページを配置しましょう。
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4);
CREATE INDEX
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty
----------------
6528 kB
(1 row)
実行計画
次に、インデックスの仕組みを見てみましょう。 ある日、たとえば1週間前を選択してみましょう(「今日」はデモデータベースでbookings.now関数によって決定されます)。
demo=# \set d 'bookings.now()::date - interval \'7 days\''
demo=# explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows= 83954 loops=1)
Recheck Cond: ...
Rows Removed by Index Recheck: 12045
Heap Blocks: lossy= 1664
-> Bitmap Index Scan on flights_bi_scheduled_time_idx
(actual time=3.013..3.013 rows= 16640 loops=1)
Index Cond: ...
Planning time: 0.375 ms
Execution time: 97.805 ms
ご覧のとおり、スケジューラは作成されたインデックスを使用しました。 どれくらい正確ですか? これは、サンプリング条件(ビットマップヒープスキャンノードの行)を満たす行の数と、インデックスを使用して取得された行の合計数(同じとインデックスの再チェックによって削除された行)の比率によって証明されます。 私たちの場合、83954 /(83954 + 12045)は予想どおり約90%です(この値は日々変化します)。
ビットマップインデックススキャンノードの実際の行のどこに番号16640が表示されましたか? 実際、計画のこのノードは不正確な(ページ)ビットマップを構築しており、それが何行影響するかはわかりませんが、何かを表示する必要があります。 したがって、絶望から、各ページに10行あると考えられています。 合計で、ビットマップには1664ページが含まれます(この値は「ヒープブロック:lossy = 1664」から確認できます)-判明したのは16640だけです。一般に、これは無意味な数字であり、注意する必要はありません。
空港はどうですか? たとえば、1日あたり28ページを占有するウラジオストクタイムゾーンを使用します。
demo=# explain (costs off,analyze)
select *
from flights_bi
where airport_utc_offset = interval '8 hours';
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows= 587353 loops=1)
Recheck Cond: (airport_utc_offset = '08:00:00'::interval)
Rows Removed by Index Recheck: 191318
Heap Blocks: lossy=13380
-> Bitmap Index Scan on flights_bi_airport_utc_offset_idx
(actual time=74.999..74.999 rows=133800 loops=1)
Index Cond: (airport_utc_offset = '08:00:00'::interval)
Planning time: 0.168 ms
Execution time: 212.278 ms
繰り返しますが、スケジューラーは作成されたBRINインデックスを使用します。 精度は悪くなりますが(この場合は約75%)、これは予想されます。相関は低くなります。
もちろん、いくつかのBRINインデックス(他のインデックスと同様)は、ビットマップレベルで結合できます。 たとえば、選択した月のタイムゾーンのデータ:
demo=# \set d 'bookings.now()::date - interval \'60 days\''
demo=# explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '30 days'
and airport_utc_offset = interval '8 hours';
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1)
Recheck Cond: ...
Rows Removed by Index Recheck: 18856
Heap Blocks: lossy=1152
-> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1)
-> Bitmap Index Scan on flights_bi_scheduled_time_idx
(actual time=5.490..5.490 rows=435200 loops=1)
Index Cond: ...
-> Bitmap Index Scan on flights_bi_airport_utc_offset_idx
(actual time=55.068..55.068 rows=133800 loops=1)
Index Cond: ...
Planning time: 0.408 ms
Execution time: 115.475 ms
Bツリーとの比較
BRINと同じフィールドに通常のBツリーインデックスを作成するとどうなりますか?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time);
CREATE INDEX
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty
----------------
654 MB
(1 row)
それは私たちのBRINの数千倍以上になりました! 確かに、クエリの実行速度はわずかに増加しました-統計によると、スケジューラはデータが物理的に順序付けられ、ビットマップを構築する必要がないことを理解し、最も重要なのは、インデックス条件を再確認する必要がないことです:
demo=# explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN
----------------------------------------------------------------
Index Scan using flights_bi_scheduled_time_btree on flights_bi
(actual time=0.099..79.416 rows=83954 loops=1)
Index Cond: ...
Planning time: 0.500 ms
Execution time: 85.044 ms
それがBRINの美しさです。効率を犠牲にしつつ、多くのスペースを獲得しています。
演算子クラス
最小値
値を相互に比較できるデータ型の場合、要約情報は最小値と最大値で構成されます。 対応する演算子クラスには、minmaxという名前が含まれています(例:date_minmax_ops)。 実際、私たちはまだそれらとほとんどを考慮しました。
包括的
すべてのデータ型に比較演算が定義されているわけではありません。 たとえば、空港の座標を表すポイント(タイプポイント)用ではありません。 ところで、これが統計がこの列の相関を示さない理由です:
demo=# select attname, correlation
from pg_stats
where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation
---------------+-------------
airport_coord |
(1 row)
しかし、これらのタイプの多くでは、「境界領域」の概念を導入できます。たとえば、幾何学的形状の境界ボックスです。 このプロパティがGiSTインデックスでどのように使用されるかについて詳しく説明しました。 同様に、BRINを使用すると、次のタイプの列に関するサマリー情報を収集できます。 ゾーン内のすべての値の境界領域はサマリー値です。
GiSTとは異なり、BRINの集計値はインデックス付きデータと同じタイプである必要があります。 そのため、たとえば、ポイントのインデックスを作成することはできませんが、BRINで座標が機能することは明らかですが、経度はタイムゾーンとかなり密接に関連しています。 幸いなことに、式によってインデックスを作成し、ポイントを縮退した長方形に変換する手間はありません。 同時に、極端な場合を示すために、ゾーンのサイズを1ページに設定します。
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
CREATE INDEX
この極端なシナリオでも、インデックスはわずか30 MBしか使用しません。
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty
----------------
30 MB
(1 row)
これで、空港を座標に制限してクエリを作成できます。 たとえば、次のように:
demo=# select airport_code, airport_name
from airports
where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name
--------------+-----------------
KHV | -
VVO |
(2 rows)
確かに、プランナーはインデックスの使用を拒否します。
demo=# analyze flights_bi;
ANALYZE
demo=# explain select * from flights_bi
where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111)
Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
なんで? 完全なスキャンを禁止して見てみましょう。
demo=# set enable_seqscan = off;
SET
demo=# explain select * from flights_bi
where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111)
Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
-> Bitmap Index Scan on flights_bi_box_idx
(cost=0.00..14072.04 rows= 30517076 width=0)
Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
インデックスは使用できますが、スケジューラはビットマップをテーブル全体に構築する必要があると考えています。この場合、フルスキャンを好むことは驚くことではありません。 ここでの問題は、ジオメトリタイプの場合、PostgreSQLが統計を収集しないため、スケジューラが盲目的に動作する必要があることです。
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+-------------------
schemaname | bookings
tablename | flights_bi_box_idx
attname | box
inherited | f
null_frac | 0
avg_width | 32
n_distinct | 0
most_common_vals |
most_common_freqs |
histogram_bounds |
correlation |
most_common_elems |
most_common_elem_freqs |
elem_count_histogram |
ああ。 しかし、インデックス自体について不満はなく、機能しますが、悪くはありません。
demo=# explain (costs off,analyze)
select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows= 781790 loops=1)
Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Rows Removed by Index Recheck: 70726
Heap Blocks: lossy=14772
-> Bitmap Index Scan on flights_bi_box_idx
(actual time=158.083..158.083 rows=147720 loops=1)
Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Planning time: 0.137 ms
Execution time: 340.593 ms
結論は、明らかに、これは次のとおりです。ジオメトリに少なくとも重要でないものが必要な場合、PostGISが必要です。 いずれにせよ、彼は統計の収集方法を知っています。
内側
BRINインデックス内を覗くと、通常のpageinspect拡張が可能になります。
まず、メタ情報はゾーンのサイズとrevmap用に予約されているページ数を示します。
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 128 | 3
(1 row)
ここで、ページ1から3はrevmapであり、残りは要約データです。 revmapから各ゾーンの要約データへのリンクを取得できます。 テーブルの最初の128ページをカバーする最初のゾーンに関する情報は次のとおりです。
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages
---------
(6,197)
(1 row)
そして、ここに要約データ自体があります:
demo=# select allnulls, hasnulls, value
from brin_page_items(get_raw_page('flights_bi_scheduled_time_idx', 6 ), 'flights_bi_scheduled_time_idx')
where itemoffset = 197 ;
allnulls | hasnulls | value
----------+----------+----------------------------------------------------
f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03}
(1 row)
次のゾーン:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages
---------
(6,198)
(1 row)
demo=# select allnulls, hasnulls, value from brin_page_items(get_raw_page('flights_bi_scheduled_time_idx', 6 ), 'flights_bi_scheduled_time_idx') where itemoffset = 198 ;
allnulls | hasnulls | value
----------+----------+----------------------------------------------------
f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03}
(1 row)
などなど。
包含クラスの場合、値フィールドには次のように表示されます
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
最初の値は四角形を囲み、末尾の文字「f」は空の要素がないこと(最初)と結合できない値がないこと(2番目)を意味します。 実際、連結されていない値の唯一のケースは、IPv4およびIPv6アドレス(inetデータ型)です。
プロパティ
関連するリクエストが以前に与えられたことを思い出させてください。
メソッドのプロパティ:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
brin | can_order | f
brin | can_unique | f
brin | can_multi_col | t
brin | can_exclude | f
インデックスは複数の列にわたって作成できます。 この場合、列ごとに個別の要約情報が収集されますが、ゾーンごとにまとめて保存されます。 もちろん、同じゾーンサイズがすべての列に適している場合、このようなインデックスは意味があります。
インデックスプロパティ:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f
明らかに、ビットマップスキャンのみがサポートされています。
しかし、クラスタリングの欠如は戸惑う可能性があります。 BRINインデックスは行の物理的な順序の影響を受けやすいため、その上でデータをクラスタ化できるのは論理的でしょうか? ただし、「通常の」インデックス(データの種類に応じてBツリーまたはGiST)を作成し、それをクラスター化できる場合を除きます。 しかし、ところで、再構築中の排他ロック、アップタイム、およびディスク領域の消費を考慮して、おそらく巨大なテーブルをクラスター化したいですか?
列レベルのプロパティ:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | t
不確実な値を扱う可能性に加えて、連続した「ダッシュ」があります。
終了