新年のOlivierが終わったとき、私は何もすることがなかったので、Habrahabr(および関連するプラットフォーム)からすべての記事をコンピューターにダウンロードして調査することにしました。
興味深い話がいくつかありました。 これらの最初のものは、サイトの存在の12年にわたる記事の形式と主題の開発です。 たとえば、一部のトピックのダイナミクスは非常に示唆的です。 継続-カットの下。

解析プロセス
Habrがどのように開発されているかを理解するには、彼のすべての記事を調べて、そこからメタ情報(日付など)を抽出する必要がありました。 すべての記事へのリンクは「habrahabr.ru/post/337722/」という形式であり、番号は厳密に順番に指定されているため、バイパスは簡単でした。 最後の投稿の数が350万をわずかに下回ることを知って、ループ(Pythonコード)を使用してすべての可能なidドキュメントを調べました。
import numpy as np from multiprocessing import Pool with Pool(100) as p: docs = p.map(download_document, np.arange(350000))
download_document
関数は、対応するIDを持つページをロードしようとし、html構造から有益な情報を引き出します。
import requests from bs4 import BeautifulSoup def get_doc_by_id(pid): """ Download and process a Habr document and its comments """ # r = requests.get('https://habrahabr.ru/post/' +str(pid) + '/') # soup = BeautifulSoup(r.text, 'html5lib') # instead of html.parser doc = {} doc['id'] = pid if not soup.find("span", {"class": "post__title-text"}): # , doc['status'] = 'title_not_found' else: doc['status'] = 'ok' doc['title'] = soup.find("span", {"class": "post__title-text"}).text doc['text'] = soup.find("div", {"class": "post__text"}).text doc['time'] = soup.find("span", {"class": "post__time"}).text # create other fields: hubs, tags, views, comments, votes, etc. # ... # fname = r'files/' + str(pid) + '.pkl' with open(fname, 'wb') as f: pickle.dump(doc, f)
解析の過程で、いくつかの新しいポイントを発見しました。
まず、プロセッサのコアよりも多くのプロセスを作成することは役に立たないと言います。 しかし、私の場合、制限リソースはプロセッサーではなくネットワークであり、100個のプロセスが4個、たとえば20個よりも高速に実行されることが判明しました。
第二に、いくつかの投稿では、特殊文字の組み合わせがありました-例えば、「%&#@」のようなup曲表現。 私が最初に使用したhtml.parser
は、それがhtmlエンティティの始まりであると考えて、 &#
組み合わせに苦痛に反応したことが判明しました。 私はブラックマジックをしようとしていましたが、フォーラムでは、パーサーを変更することを提案しました。
第三に、3つを除くすべての出版物をアンロードできました。 番号が65927、162075、および275987のドキュメントで、ウイルス対策ソフトウェアがすぐに削除されました。 これらはそれぞれ、悪意のあるpdfをダウンロードするjavascriptのチェーン、ブラウザー用のプラグインの形式でのSMSランサムウェア、およびiPhoneを再起動するために送信するCrashSafari.comサイトに関する記事です。 アンチウイルスは、後でシステムスキャン中に別の記事を発見しました。ユーザーのプロセッサを使用して暗号通貨をマイニングするペットストアWebサイトのスクリプトに関する338586の投稿。 したがって、アンチウイルスの動作は非常に適切であると考えることができます。
潜在的な最大の166,307個のライブ記事の半分のみが判明しました。 残りについてHabrは、「ページが古いか、削除されたか、まったく存在しませんでした」というオプションを提供します。 まあ、何が起こる可能性があります。
技術的な作業は記事のアンロードに続きました。たとえば、発行日を「2006年12月21日10時47分」の形式から標準datetime
に転送する必要があり、「12.8k」ビューを12800に変換する必要がありました。 最もおかしいのは、投票とデータ型のカウントに関連しています。一部の古い投稿では、intのオーバーフローがあり、65,535票を受け取りました。

その結果、記事のテキスト(写真なし)には1.5ギガバイト、メタ情報付きのコメント(さらに3つ)、記事に関するメタ情報(約100メガバイト)が必要でした。 これはRAMに完全に保存でき、これは私にとって嬉しい驚きでした。
私はテキスト自体からではなく、メタ情報から記事の分析を始めました:日付、タグ、ハブ、ビュー、および「いいね」。 彼女は多くを語ることができることが判明した。
ハブラハブの開発動向
サイト上の記事は2006年から公開されています。 最も集中的に-2008-2016年。
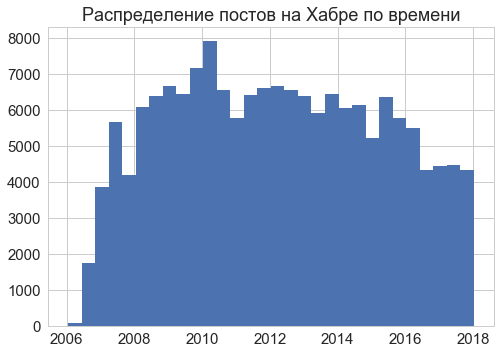
これらの記事が異なる時期にどれだけ活発に読まれたかを評価するのはそれほど簡単ではありません。 2012年以下のテキストは、より積極的にコメントおよび評価されていますが、新しいテキストにはより多くのビューとブックマークがあります。 同じ動作(半分)、これらのメトリックは2015年に1回のみ。 おそらく、経済的および政治的危機の状況では、読者の注意はITブログからより苦痛な問題に移りました。
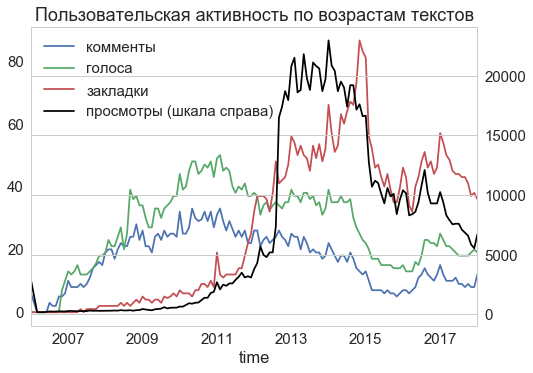
記事自体に加えて、私はそれらに関するコメントをさらに削除しました。 600万件のコメントが判明しましたが、そのうち24万件が禁止されました(「UFOが飛び込んで、この碑文をここに公開しました」)。 コメントの便利な機能は、タイムスタンプが付けられることです。 コメントの時間を調べると、大まかに理解でき、記事が一般的に読まれる時期がわかります。
ほとんどの記事は10時間から20時間のどこかに書かれ、コメントされていることが判明しました。 典型的なモスクワの営業日。 これは、Habrが職業上の目的で読まれていること、そしてこれが職場での先延ばしの良い方法であることを意味するかもしれません。 ところで、この時刻の分布は、Habrirの基礎から現在まで安定しています。

ただし、コメントのタイムスタンプの主な利点は時刻ではなく、記事の「アクティブライフ」の期間です。 記事の公開からコメントまでの時間の割り当て方法を計算しました。 これで、中央値コメント(緑色の線)が約20時間で届くことがわかりました。 出版後の最初の日に、平均して、記事に関するすべてのコメントの半分以上を残します。 そして2日で、彼らはすべてのコメントの75%を残します。 さらに、以前の記事はさらに速く読まれたため、2010年にはコメントの半分が最初の6時間で届きました。

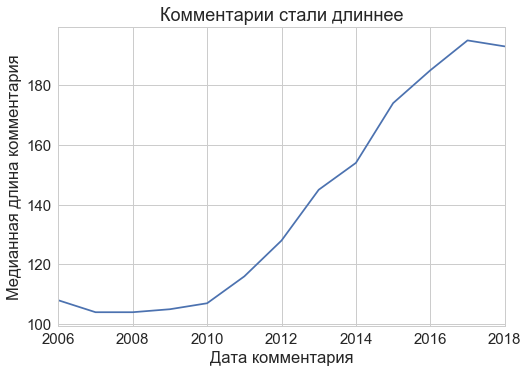
コメントが長くなったのは驚きでした。コメントの文字の平均数は、Habrの存在中にほぼ2倍になりました。
コメントよりも簡単なフィードバックは声です。 他の多くのリソースとは異なり、Habréにはプラスだけでなくマイナスも追加できます。 ただし、読者は最後の機会をそれほど頻繁に使用しません。現在の嫌悪感の割合は、投票総数の約15%です。 以前はもっとありましたが、時間が経つにつれて読者は一致しました。

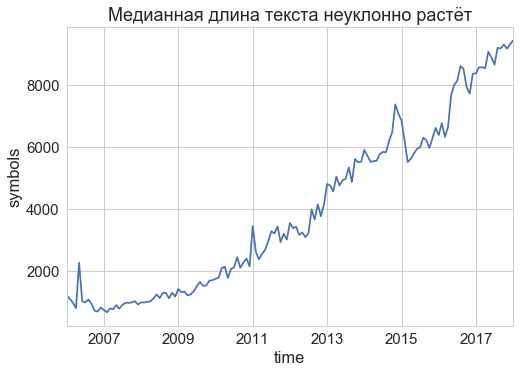
テキスト自体は時間とともに変化しました。 たとえば、危機にもかかわらず、テキストの典型的な長さはサイトの最初から着実に成長することを止めません。 10年で、テキストはほぼ10倍になりました!
テキストの文体も(最初の近似値まで)変更されました。 たとえば、Habrの存在の最初の数年間で、テキスト内のコードと数字の割合が増加しました。

サイトの一般的なダイナミクスを扱った後、さまざまなトピックの人気がどのように変化したかを測定することにしました。 トピックはテキストから自動的に選択できますが、初心者にはホイールを再発明することはできませんが、各記事の著者が付けた既製のタグを使用します。 チャートで4つの典型的な傾向を推測しました。 Googleのテーマは当初は(おそらくSEOの最適化が主な原因で)支配的でしたが、毎年体重が減少しました。 Javascriptは人気のあるトピックであり、徐々に継続していますが、機械学習は近年だけ急速に人気を集め始めました。 Linuxは、この10年間ずっと同じように関連しています。

もちろん、どのトピックがより多くの読者を引き付けたのかと思いました。 各トピックのビュー、投票、コメントの中央値を計算しました。 起こったことは次のとおりです。
- 最も見られたトピック:arduino、Webデザイン、Web開発、ダイジェスト、リンク、CSS、html、html5、nginx、アルゴリズム。
- 最も「好感の持てる」トピック:VKontakte、ユーモア、jquery、オペラ、c、html、web開発、html5、css、webデザイン。
- 最も議論されているトピック:オペラ、スカイプ、フリーランス、VKontakte、ubuntu、work、nokia、nginx、arduino、firefox。
ちなみに、トピックを比較しているので、頻度によって評価を行うことができます(そして、結果を2013年の同様の記事と比較できます)。
- Habrの長年にわたって、最も人気のあるタグ(降順)はgoogle、android、javascript、microsoft、linux、php、apple、java、python、プログラミング、スタートアップ、開発、ios、スタートアップ、ソーシャルネットワークになりました
- 2017年に最も人気があったのは、javascript、python、java、android、開発、linux、c ++、プログラミング、php、c#、ios、機械学習、情報セキュリティ、microsoft、react
これらの評価を比較するとき、たとえば、Pythonの勝利の行進とphpの消滅、またはスタートアップトピックの「日没」と機械学習の台頭に注意を払うことができます。
Habréのすべてのタグにこのような明らかなテーマの色が付いているわけではありません。 ここでは、たとえば、1回だけ発生したが、私には面白そうに思えた12個のタグがあります。 「アイデアは進歩のエンジン」、「フロッピーディスクのイメージからの読み込み」、「アイオワ州」、「ドラマトゥルギー」、「スーパーアリーシャ」、「蒸気エンジン」、「土曜日に何をすべきか」、「肉挽き器にキツネがいる」、「いつものように判明しました、「面白いタグを思い付くことができませんでした。」 そのような記事のトピックを決定するには、タグだけでは十分ではありません。記事のテキストをテーマにモデリングする必要があります。
記事の内容のより詳細な分析は、次の投稿にあります。 まず、コンテンツに応じて記事が表示される回数を予測するモデルを作成します。 次に、Habrの作者と同じスタイルでテキストを生成するようにニューラルネットワークに教えたいです。 だからサブスクライブ:)