現在、ディープニューラルネットワークは注目のトピックです。
Webには多くのチュートリアルやビデオレクチャーがあり、ニューラルネットワークの構築の基本原則、そのアーキテクチャ、学習戦略などを説明する他の資料もあります。 従来、ニューラルネットワークのトレーニングは、トレーニングセットからの画像パケットのニューラルネットワークを提示し、逆伝播法を使用してこのネットワークの係数を修正することによって実行されていました。 ニューラルネットワークを操作するための最も人気のあるツールの1つは、GoogleのTensorflowライブラリです。
Tensorflowのニューラルネットワークは、一連のレイヤー操作で表されます
(行列の乗算、 畳み込み 、プーリングなど)。 ニューラルネットワークの層は、係数を調整する操作とともに計算のグラフを形成します。
この場合のニューラルネットワークのトレーニングプロセスは、ニューラルネットワークの「提示」
オブジェクトのパッケージのネットワーク、予測クラスと真のクラスの比較、計算
ニューラルネットワーク係数のエラーと修正。
同時に、Tensoflowはトレーニングの技術的詳細と係数調整アルゴリズムの実装を隠しており、プログラマーの観点からは、主に「予測」を生成する計算グラフについてのみ話すことができます。 プログラマーが考えている計算グラフを比較してください。
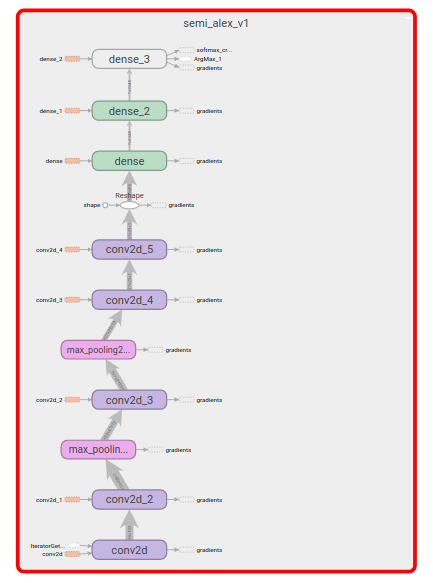
とりわけ、係数の調整を実行するグラフ
 。
。
しかし、プログラマにとってTensorflowができないことは、入力データセットをニューラルネットワークのトレーニングに適したデータセットに変換することです。 ライブラリにはかなりの数の「ベースブロック」がありますが。
それらを使用して、入力データを含むニューラルネットワークの「フィード」(英語フィード )に効果的なコンベヤを構築する方法については、この記事で説明します。
問題の例として、最近Kaggleでオブジェクトを検出するためのコンペティションとして公開されたImageNetデータセットを使用し、最大の境界ボックスを持つオブジェクトを検出するようにネットワークをトレーニングします。
このライブラリをまだ使用したことがない場合は、 Tensorflow Deep Learning Libraryの記事や公式Webサイトなど、基本的な概念を調べる価値があります。
準備手順
以下では、あなたが持っていると仮定されます
- [Python] [python_org]をインストールし、例ではPython 2.7を使用し、
しかし、Python 3に移植するのに困難はないはずです。* - ライブラリ[TensorflowとPythonインターフェイス] [install_tensorflow]
- Kaggleのコンテストから[データセット] [download_dataset]をダウンロードして解凍しました
従来のライブラリエイリアス:
import tensorflow as tf import numpy as np
データの前処理
データをロードするには、Tensorflow でデータセットを操作するためのモジュールが提供するメカニズムを使用します 。
トレーニングと検証には、画像とその説明の両方が含まれるデータセットが必要です。 しかし、ダウンロードされたデータセットでは、画像と注釈を含むファイルは異なるフォルダーにきちんと配置されています。
したがって、対応するペアを反復処理する反復子を作成します。
ANNOTATION_DIR = os.path.join("Annotations", "DET") IMAGES_DIR = os.path.join("Data", "DET") IMAGES_EXT = "JPEG" def image_annotation_iterator(dataset_path, subset="train"): """ Yields tuples of image filename and corresponding annotation. :param dataset_path: Path to the root of uncompressed ImageNet dataset :param subset: one of 'train', 'val', 'test' :return: iterator """ annotations_root = os.path.join(dataset_path, ANNOTATION_DIR, subset) print annotations_root images_root = os.path.join(dataset_path, IMAGES_DIR, subset) print images_root for dir_path, _, file_names in os.walk(annotations_root): for annotation_file in file_names: path = os.path.join(dir_path, annotation_file) relpath = os.path.relpath(path, annotations_root) img_path = os.path.join( images_root, os.path.splitext(relpath)[0] + '.' + IMAGES_EXT ) assert os.path.isfile(img_path), \ RuntimeError("File {} doesn't exist".format(img_path)) yield img_path, path
これから、すでにデータセットを作成して「グラフの処理」を実行できます。
たとえば、データセットからファイル名を取得します。
データセットを作成します。
files_dataset = tf.data.Dataset.from_generator( functools.partial(image_annotation_iterator, "./ILSVRC"), output_types=(tf.string, tf.string), output_shapes=(tf.TensorShape([]), tf.TensorShape([])) )
データセットからデータを取得するには、イテレータが必要です
make_one_shot_iterator
は、通過するイテレータを作成します
一度与えられた。 Iterator.get_next()
は、ロードされるテンソルを作成します
イテレータからのデータ。
iterator = files_dataset.make_one_shot_iterator() next_elem = iterator.get_next()
これで、セッションを作成し、テンソルの「値を計算」できます。
with tf.Session() as sess: for i in range(10): element = sess.run(next_elem) print i, element
しかし、ニューラルネットワークで使用する場合、ファイル名は必要ありませんが、同じ形状の「3層」マトリックスの形の画像と、 「1つのホット」ベクトルの形のこれらの画像のカテゴリ
画像のカテゴリをエンコードします
注釈ファイルの解析自体は、あまり興味深いものではありません。 このためにBeautifulSoupパッケージを使用しました。 ヘルパークラスのAnnotation
は、ファイルパスから初期化し、オブジェクトのリストを保存できます。 まず、カテゴリのリストを収集して、 cat_max
エンコーディングのベクトルのサイズを知る必要があります。 また、文字列カテゴリを[0..cat_max]
数値にマッピングします。 このようなマッピングの作成もあまり興味深いものではありません。さらに、辞書cat2id
およびid2cat
に上記の直接および逆マッピングが含まれているとid2cat
ます。
ファイル名をカテゴリのエンコードされたベクトルに変換する関数。
背景にもう1つのカテゴリが追加されていることがわかります。一部の画像では単一のオブジェクトがマークされていません。
def ann_file2one_hot(ann_file): annotation = reader.Annotation("unused", ann_file) category = annotation.main_object().cls result = np.zeros(len(cat2id) + 1) result[cat2id.get(category, len(cat2id))] = 1 return result
変換をデータセットに適用します。
dataset = file_dataset.map( lambda img_file_tensor, ann_file_tensor: (img_file_tensor, tf.py_func(ann_file2one_hot, [ann_file_tensor], tf.float64)) )
map
メソッドは、元のデータセットの各行に関数が適用された新しいデータセットを返します。 結果のデータセットの反復処理を開始するまで、関数は実際には適用されません。
また、必要なため、関数をtf.py_func
でラップしたことにも気付くことができます。 パラメータとして、テンソルは変換関数に属し、それらに含まれる値ではありません。
また、文字列を使用するには、このラッパーが必要です。
画像をアップロード
Tensorflowには豊富な画像ライブラリがあります。 ダウンロードに使用します。 ファイルを読み取り、マトリックスにデコードし、マトリックスを標準サイズ(平均など)にし、このマトリックスの値を正規化する必要があります。
def image_parser(file_name): image_data = tf.read_file(file_name) image_parsed = tf.image.decode_jpeg(image_data, channels=3) image_parsed = tf.image.resize_image_with_crop_or_pad(image_parsed, 482, 415) image_parsed = tf.cast(image_parsed, dtype=tf.float16) image_parsed = tf.image.per_image_standardization(image_parsed) return image_parsed
前の関数とは異なり、ここでfile_name
はテンソルです。つまり、この関数をラップする必要はなく、前のスニペットに追加します。
dataset = file_dataset.map( lambda img_file_tensor, ann_file_tensor: ( image_parser(img_file_tensor), tf.py_func(ann_file2one_hot, [ann_file_tensor], tf.float64) ) )
計算のグラフが意味のあるものを生成することを確認しましょう。
iterator = dataset.make_one_shot_iterator() next_elem = iterator.get_next() print type(next_elem[0]) with tf.Session() as sess: for i in range(3): element = sess.run(next_elem) print i, element[0].shape, element[1].shape
それは判明するはずです:
0 (482, 415, 3) (201,) 1 (482, 415, 3) (201,) 2 (482, 415, 3) (201,)
原則として、最初に、トレーニング/検証/テストのために、データセットを2つまたは3つの部分に分割する必要があります。 ダウンロードしたアーカイブからトレーニングおよび検証データセットへの分割を使用します。
計算グラフの設計
確率的勾配降下法に似た方法を使用して、畳み込みニューラルネットワーク(英語の畳み込みニューラルネットワーク、CNN)をトレーニングしますが、改良版のAdamを使用します。 これを行うには、インスタンスを「パッケージ」(英語バッチ)に結合する必要があります。 さらに、マルチプロセッシング(およびせいぜいトレーニング用のGPUの可用性)を利用するために、バックグラウンドデータページングを有効にできます。
BATCH_SIZE = 16 dataset = dataset.batch(BATCH_SIZE) dataset = dataset.prefetch(2)
パッケージをBATCH_SIZE
インスタンスにマージし、そのようなパッケージを2つポンプします。
トレーニング中、トレーニングに関係のないサンプルの検証を定期的に実行します。 したがって、別のデータセットに対して上記のすべての操作を繰り返す必要があります。
幸いなことに、それらはすべて、たとえばdataset_from_file_iterator
などの関数に結合して、2つのデータセットを作成できます。
train_dataset = dataset_from_file_iterator( functools.partial(image_annotation_iterator, "./ILSVRC", subset="train"), cat2id, BATCH_SIZE ) valid_dataset = ... # subset="val"
ただし、トレーニングと検証に同じ計算グラフを引き続き使用するため、より柔軟なイテレータを作成します。 再初期化できるもの。
iterator = tf.data.Iterator.from_structure( train_dataset.output_types, train_dataset.output_shapes ) train_initializer_op = iterator.make_initializer(train_dataset) valid_initializer_op = iterator.make_initializer(valid_dataset)
後で、この操作またはその操作を完了すると、反復子を1つのデータセットから次のデータセットに切り替えることができます。
別のもの。
with tf.Session(config=config, graph=graph) as sess: sess.run(train_initialize_op) # # ... sess.run(valid_initialize_op) # # ...
ここでは、ニューラルネットワークについて説明する必要がありますが、この問題については詳しく説明しません。
semi_alex_net_v1(mages_batch, num_labels)
関数semi_alex_net_v1(mages_batch, num_labels)
が目的のアーキテクチャを構築し、ニューラルネットワークによって予測された出力値を含むテンソルを返すと仮定します。
エラーと微妙な機能、最適化操作を設定します。
img_batch, label_batch = iterator.get_next() logits = semi_alexnet_v1.semi_alexnet_v1(img_batch, len(cat2id)) loss = tf.losses.softmax_cross_entropy( logits=logits, onehot_labels=label_batch) labels = tf.argmax(label_batch, axis=1) predictions = tf.argmax(logits, axis=1) correct_predictions = tf.reduce_sum(tf.to_float(tf.equal(labels, predictions))) optimizer = tf.train.AdamOptimizer().minimize(loss)
トレーニングと検証サイクル
これで学習を開始できます。
with tf.Session() as sess: sess.run(tf.local_variables_initializer()) sess.run(tf.global_variables_initializer()) sess.run(train_initializer_op) counter = tqdm() total = 0. correct = 0. try: while True: opt, l, correct_batch = sess.run([optimizer, loss, correct_predictions]) total += BATCH_SIZE correct += correct_batch counter.set_postfix({ "loss": "{:.6}".format(l), "accuracy": correct/total }) counter.update(BATCH_SIZE) except tf.errors.OutOfRangeError: print "Finished training"
上記では、セッションを作成し、グラフのグローバル変数とローカル変数を初期化し、反復子をトレーニングデータで初期化します。 [tqdm] [tgdm]は学習プロセスには適用されず、進行状況を視覚化するための便利なツールにすぎません。
同じセッションのコンテキストで検証を実行します。検証サイクルは非常に似ています。 主な違い:最適化操作は開始されません。
with tf.Session() as sess: # Train # ... # Validate counter = tqdm() sess.run(valid_initializer_op) total = 0. correct = 0. try: while True: l, correct_batch = sess.run([loss, correct_predictions]) total += BATCH_SIZE correct += correct_batch counter.set_postfix({ "loss": "{:.6}".format(l), "valid accuracy": correct/total }) counter.update(BATCH_SIZE) except tf.errors.OutOfRangeError: print "Finished validation"
エポックとチェックポイント
すべての画像を1回通過するだけでは、トレーニングには十分ではありません。 そして、上記のトレーニングおよび検証コードをサイクルで(1つのセッション内で)実行する必要があります。
一定の反復回数を実行するか、学習中に役立ちます。 データセット全体を1回通過することは、従来エポックと呼ばれます。
学習が予期せず中断した場合、およびモデルをさらに使用するために、モデルを保存する必要があります。 これを行うには、実行グラフを作成するときにSaver
クラスのオブジェクトを作成する必要があります。 そして、トレーニング中、モデルの状態を維持します。
# # ... saver = tf.train.Saver() # with tf.Session() as sess: for i in range(EPOCHS): # Train # ... # Validate # ... saver.save(sess, "checkpoint/name")
次は何ですか
データセットを作成し、関数を使用して変換する方法を学びました
テンソル、およびpythonで書かれた通常の関数。 画像をメモリにロードしたり、展開した形式で保存したりせずに、バックグラウンドループで画像をロードする方法を学びました。 また、訓練されたモデルを維持する方法も学びました。
上記の手順の一部を適用してダウンロードすると、画像を認識するプログラムを作成できます。
この記事では、ニューラルネットワークのトピック、アーキテクチャ、およびトレーニング方法については開示していません。 これを理解したい人には、UdacityのGoogleによるディープラーニングコースをお勧めします。初心者向けであり、深刻な背景はありません。 認識のための畳み込みニューラルネットワークの使用については、スタンフォード大学の視覚認識のための畳み込みニューラルネットワークの優れた講座があります。 CourseraのCoursera ning Coursera Specializationコースもご覧ください 。 また、Habrahabrには非常に多くの資料があります。たとえば、Open Data ScienceのTensorflowライブラリの概要です。
UPD: Githubで利用可能なスクリプトおよびヘルパーライブラリ