
免責事項
著者は数学的な背景を持っていますが、データマイニングや統計分析とは一切関係ありません。 この資料は、開発中の監視システム用に異常検索モジュール(脆弱なモジュールも含む)を作成する可能性を見つけるために実施された調査の結果です。
2つの写真で探しているもの
チャートの異常
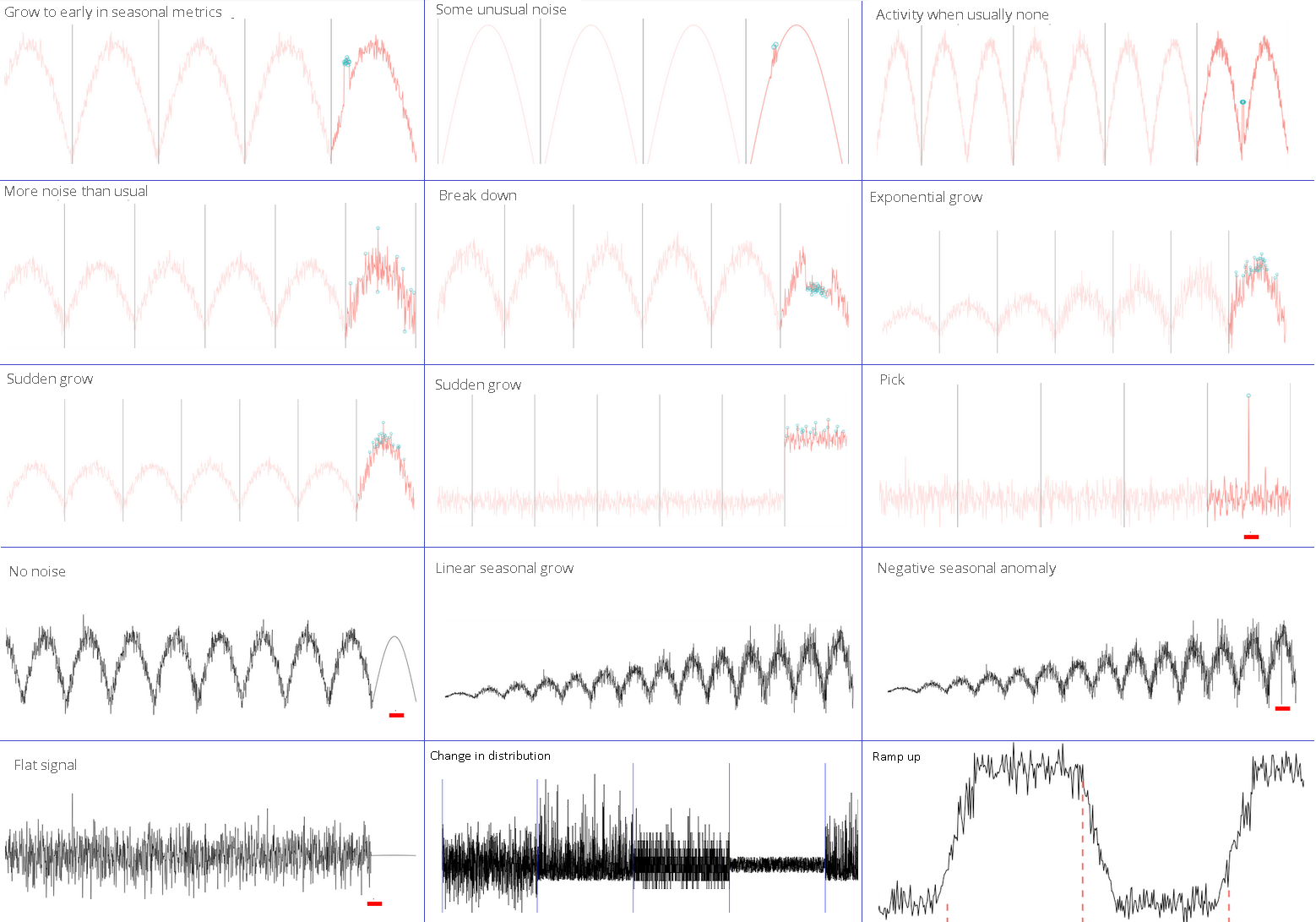
現状
商用製品は、ほとんどの場合、統計と機械学習の両方を使用したサービスの形式で提供されます。 AIMS 、 Anomaly.io (例のある優れたブログ)、 CoScale (Zabbixなどと統合する機能)、 DataDog 、 Grok 、 Metricly.com 、 Azure (Microsoftから)。 Elasticには機械学習ベースのX-Packモジュールがあります。
自宅で展開できるオープンソース製品:
- Netflix Atlasは、インメモリ時系列分析データベースです。 検索は、Holt-Wintersメソッドによって実行されます。
- エレミーのバンシー 。 検出には、3シグマルールに基づいて1つのアルゴリズムのみが使用されます。
- リアルタイムで問題を検出するための2つのSkyline製品で構成されるEtsyのKALEスタックと、関係を見つけるためのOculus 。 放棄されたようです。
- Morgoth -Kapacitorの異常検出フレームワーク(InfluxDB通知モジュール)。 箱から出してすぐに:3シグマルール、コルモゴロフスミルノフ検定、ジェンセンシャノン偏差 。
- プロメテウスは、標準機能を使用していくつかの検索アルゴリズムを個別に実装できる、ますます人気のある監視システムです。
- RRDToolは、CactiやMuninなどで使用されるデータベースです。 Holt-Winters法を使用して予測を行うことができます。 これの使用方法について- 予測監視の記事、潜在的な障害アラート
- GitHubの〜2000リポジトリ
私の意見では、オープンソースは検索品質がはるかに劣っています。 異常の検索がどのように機能し、状況を修正できるかどうかを理解するには、統計を少し掘り下げる必要があります。 数学の詳細は簡略化され、ネタバレの下に隠されています。
モデルとそのコンポーネント
時系列を分析するために、シリーズの予想される機能(コンポーネント)を反映するモデルが使用されます。 通常、モデルは3つのコンポーネントで構成されます。
- トレンド-値の増加または減少に関するシリーズの一般的な動作を反映します。
- 季節性-曜日や月などに関連付けられた値の周期的な変動。
- ランダムな値とは、他のコンポーネントを除外した後にシリーズに残るものです。 ここで異常を探します。
周期乗数などの追加コンポーネントをトレンド乗数として含めることができます。
異常(破局的イベント)または社会的(休日) 。 トレンドまたは季節性がデータに表示されない場合、モデルの対応するコンポーネントを除外できます。
モデルのコンポーネントの相互接続方法に応じて、そのタイプが決定されます。 したがって、すべてのコンポーネントが合計して観測シリーズを取得する場合、モデルは中毒性があり、乗算する場合は乗算型であり、乗算する場合は乗算し、追加する場合は混合すると言います。 通常、モデルのタイプは、データの予備分析に基づいて研究者によって選択されます。
分解
モデルのタイプとコンポーネントのセットを選択したら、時系列の分解に進むことができます。 コンポーネントへの分解。
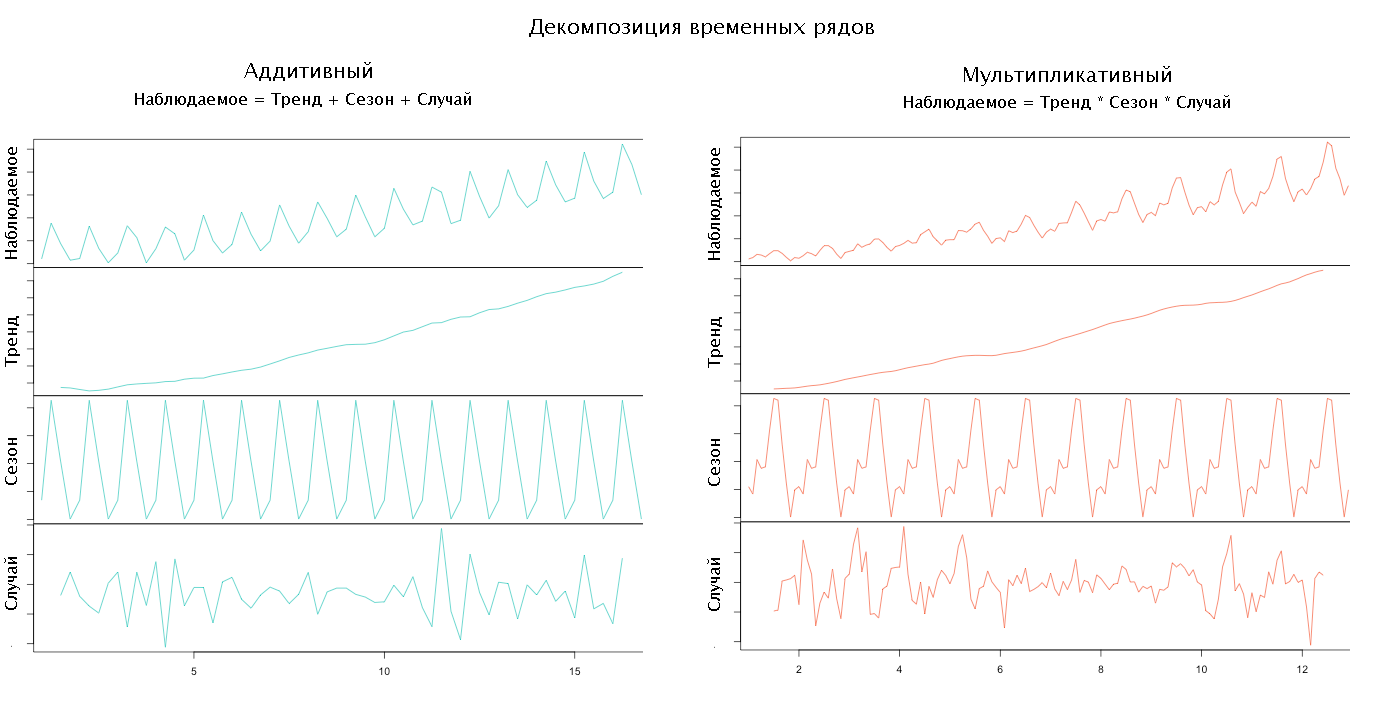
ソースAnomaly.io
まず、ソースデータを平滑化することで傾向を強調します。 平滑化の方法と程度は、研究者が選択します。
シリーズ平滑化方法:移動平均、指数平滑化、および回帰
時系列を滑らかにする最も簡単な方法は、元の値の代わりに隣接する値の半分を使用することです
1つではなく複数の以前の値を使用する場合、つまり k近傍値の算術平均、この平滑化は、ウィンドウ幅kの単純な移動平均と呼ばれます
以前の各値に対して、現在の係数への影響度を決定する独自の係数を使用する場合、 加重移動平均を取得します。
少し異なる方法は、指数平滑法です。 平滑化されたシリーズは次のように計算されます。最初の要素は元のシリーズの最初の要素と一致しますが、後続のものはフォーラムによって計算されます
ここで、αは0から1までの平滑化係数です。αが1に近いほど、結果の系列が元の系列に似ていることがわかります。
線形トレンドを決定するには、線形回帰の計算方法を使用できます 最小二乗法 : 、 どこで そして -算術平均 そして 。
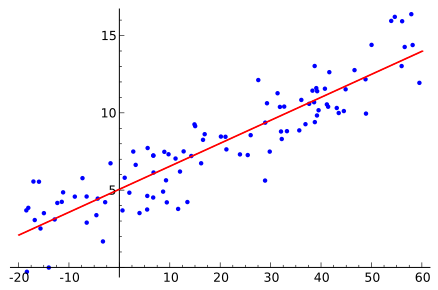
ソースウィキペディア
1つではなく複数の以前の値を使用する場合、つまり k近傍値の算術平均、この平滑化は、ウィンドウ幅kの単純な移動平均と呼ばれます
以前の各値に対して、現在の係数への影響度を決定する独自の係数を使用する場合、 加重移動平均を取得します。
少し異なる方法は、指数平滑法です。 平滑化されたシリーズは次のように計算されます。最初の要素は元のシリーズの最初の要素と一致しますが、後続のものはフォーラムによって計算されます
ここで、αは0から1までの平滑化係数です。αが1に近いほど、結果の系列が元の系列に似ていることがわかります。
線形トレンドを決定するには、線形回帰の計算方法を使用できます 最小二乗法 : 、 どこで そして -算術平均 そして 。
ソースウィキペディア
最初の系列から季節成分を決定するために、選択したモデルのタイプに応じてトレンドを減算するか、それで除算し、再び平滑化します。 次に、季節(期間)の長さ(通常は1週間)でデータを分割し、平均季節を見つけます。 シーズンの長さがわからない場合は、見つけることができます:
離散フーリエ変換または自己相関
私は、フーリエ変換がどのように機能するかを理解していなかったことを正直に認めます。 興味のある方は、次の記事をご覧ください。Rでのフーリエ変換を使用した季節性の検出と、フーリエ変換に関する簡単な単語 。 私が理解するように、初期のシリーズ/関数は要素の無限の合計として表され、最初のいくつかの重要な係数が取られます。
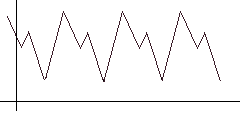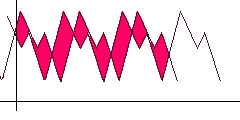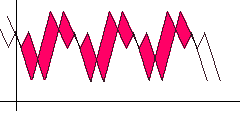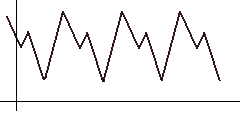
自己相関を検索するには、関数を右にシフトし、元の関数とシフトされた関数(赤で強調表示)の間の距離/面積が最小になるような位置を探します。 明らかに、アルゴリズムにシフトステップと最大制限を設定する必要があります。到達すると、期間検索が失敗したと考えられます。
自己相関を検索するには、関数を右にシフトし、元の関数とシフトされた関数(赤で強調表示)の間の距離/面積が最小になるような位置を探します。 明らかに、アルゴリズムにシフトステップと最大制限を設定する必要があります。到達すると、期間検索が失敗したと考えられます。
モデルと分解の詳細については、「 季節とトレンドの抽出:Rでの分解の使用 」および「時系列データのパターンを識別する方法」を参照してください。
最初のシリーズからトレンドと季節要因を削除して、ランダムなコンポーネントを取得します。
異常の種類
ランダムなコンポーネントのみを分析する場合、多くの異常を次のいずれかのケースに減らすことができます。
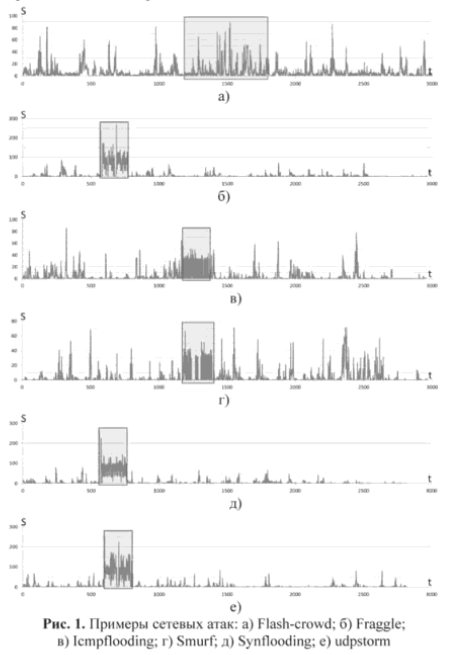
- パンク
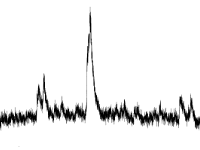 データ内の外れ値を見つけることは古典的な問題であり、その解決策にはすでに優れた解決策のセットがあります。
データ内の外れ値を見つけることは古典的な問題であり、その解決策にはすでに優れた解決策のセットがあります。
3つのシグマ、四分位範囲などのルールこのようなテストの考え方は、単一の値が平均からどれだけ離れているかを判断することです。 距離が「通常の」距離と異なる場合、値は外れ値として宣言されます。 イベント時間は無視されます。
入力時に一連の数字- 、 、... 合計 個。 - 番目の数。
標準テストは実装が非常に簡単で、平均の計算のみが必要です 標準偏差 そして時々中央値 -すべての数値を昇順で注文し、中央の数値を取得する場合の平均値。
3シグマのルール
もし それから 外れ値を検討します。
Zスコアおよび洗練されたIglewiczおよびHoaglinメソッド
-放出の場合 通常は3に等しい所定のしきい値を超えます。実際、3シグマの書き換えられたルール。
洗練された方法は次のとおりです。系列の各番号について、計算します そして、結果の値については、 。
-放出の場合 より多くのしきい値。
四分位範囲
初期値を昇順でソートし、2で除算し、各部分について中央値を見つけます そして 。
-放出の場合 。
グラブス試験
最小値を見つけます そして最大 値とそれらについて計算します そして 。 次に、有意水準α (通常0.01、0.05または0.1のいずれか)を選択し、 臨界値の表を見て、nおよびαの値を選択します。 もし または テーブルの値以上に、系列の対応する要素を外れ値と見なします。
通常、テストでは正規分布を調査する必要がありますが、多くの場合、この要件は無視されます。
- シフト
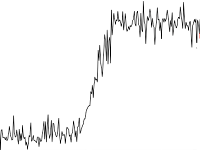 データのシフトを検出する問題は、信号処理に見られるため、よく研究されています。 これを解決するには、 Twitter Breakout Detectionを使用できます。 季節性と傾向の成分を含む初期シリーズを分析すると、動作が非常に悪くなることに注意してください。
データのシフトを検出する問題は、信号処理に見られるため、よく研究されています。 これを解決するには、 Twitter Breakout Detectionを使用できます。 季節性と傾向の成分を含む初期シリーズを分析すると、動作が非常に悪くなることに注意してください。
- 価値の性質(分布)の変化
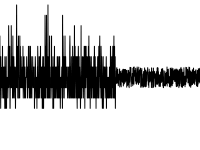 シフトに関しては、Twitterの同じBreakoutDetectionパッケージを使用できますが、すべてがスムーズではありません。
シフトに関しては、Twitterの同じBreakoutDetectionパッケージを使用できますが、すべてがスムーズではありません。
- 「毎日」からの偏差(季節性のあるデータの場合)
この異常を検出するには、現在の期間と以前のいくつかの期間を比較する必要があります。 一般的に使用される
ホルト・ウィンターズ法この方法は予測に関連するため、その適用は予測値と実際の値の比較に限定されます。
このメソッドの主な考え方は、3つのコンポーネントのそれぞれが個別の平滑化係数を使用して指数関数的に平滑化されるため、このメソッドはしばしばトリプル指数平滑法と呼ばれます。 乗法および中毒性の季節の計算式はウィキペディアにあり、方法の詳細はHabréの記事にあります。
結果のシリーズが元の「近く」になるように、3つの平滑化パラメーターを選択する必要があります。 実際には、RRDToolではこれらの値を明示的に指定する必要がありますが、このタスクは列挙によって解決されます。
この方法の欠点は、少なくとも3つの季節のデータが必要なことです。
Odnoklassnikiで使用されるもう1つの方法は、分析対象の瞬間に対応する他の季節から値を選択し、それらの組み合わせで異常値の存在を確認することです(例:グラブス検定)。
TwitterはAnomalyDetectionも提供しています。これは、 テストデータで良い結果を示しています 。 残念ながら、BreakoutDetectionのように、更新なしで2年が経過しています。
- 行動
異常には特定の文字が含まれる場合があります。ほとんどの場合、たとえば2つの隣接する要素の1つの値は無視されます。 そのような場合、個別のアルゴリズムが必要です。
- 関節異常
それとは別に、別々に観測された2つのメトリックの値が正常範囲内にあるが、それらの結合した外観が問題の兆候である場合、異常に言及する価値があります。 一般的な場合、このような異常の発見は、値のペアが平面上の点の座標を表し、イベントのセット全体が2/3グループ(クラスター)-「ノルム」/「ノイズ」と「異常」に分かれている場合、 クラスター分析によって解決できます。
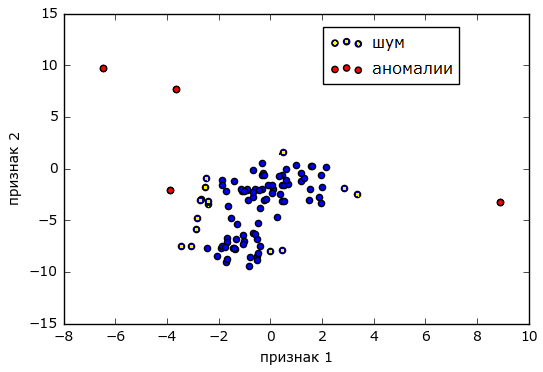
ソースalexanderdyakonov.wordpress.com
より弱い方法は、メトリックが時間の経過とともに互いにどの程度依存しているかを追跡し、依存関係が失われた場合に、異常に関するメッセージを提供することです。 おそらく、この方法のいずれかを使用できます。
ピアソン線形相関係数させる そして 2つの数値セットがあり、それらの間に線形関係があるかどうかを調べる必要があります。 計算する 平均的 および標準偏差 。 同様に 。
ピアソン相関係数
係数が1に近いほど、依存性が大きくなります。 係数が-1に近い場合、依存関係は逆になります。 成長 減少に伴う 。
距離ダメラウ-レーベンシュタインABCとADECの2つの行があるとします。 最初のものから2番目のものを取得するには、Bを削除してDとEを追加する必要があります。各操作にコストを設定してキャラクターを削除/追加し、XYをYXに再配置すると、合計コストはDamerau-Levenshteinの距離になります。
グラフの類似性を判断するには、KALEで使用されるアルゴリズムから始めることができます
最初に、一連の初期値、たとえば[960、350、350、432、390、76、105、715、715]の形式が正規化されます。最大値が求められます-25に対応し、最小値が0に対応します。 したがって、データは0から25までの整数の制限内で比例配分されます。その結果、[25、8、8、10、9、0、1、18、18]の形式のシリーズが得られます。 次に、正規化されたシリーズは、sdec(シャープダウン)、dec(ダウン)、s(正確)、inc(アップ)、sinc(シャープアップ)の5ワードを使用してエンコードされます。 結果は、[sdec、flat、inc、dec、sdec、inc、sinc、flat]の形式のシリーズです。
この方法で2つの時系列をエンコードすると、それらの間の距離を見つけることができます。 また、あるしきい値よりも小さい場合は、グラフが類似しており、接続があると想定します。
おわりに
もちろん、異常を検出するための多くのアルゴリズムは、統計データ処理を目的としたR言語で既に実装されています。パッケージの形式: tsoutliers 、 strucchange 、 Twitter Anomaly Detection など 。 記事でRの詳細を読んでください。すでにビジネスでRを使用していますか? Rでの私の導入経験 パッケージを接続して使用しているようです。 ただし、問題があります。統計チェックのパラメーターの設定は、重要な値とは異なり、ほとんど明白ではなく、普遍的な値を持ちません。 この状況から抜け出す方法は、メトリックごとに独立した、まれな定期的な改良を伴う徹底的な(リソース集約型)による選択です。 一方、季節性に関係しない異常のほとんどは視覚的に明確に定義されており、レンダリングされたグラフィックスにニューラルネットワークを使用することを示唆しています。
アプリ
以下に、結果別のTwitter Breakoutと同等に機能し、Java Scriptで実装した場合の速度がいくぶん速い独自のアルゴリズムを示します。
区分的線形時系列近似アルゴリズム 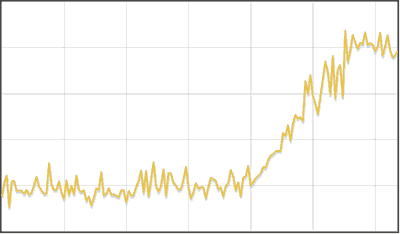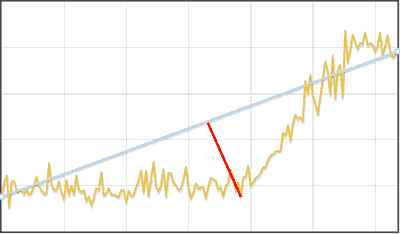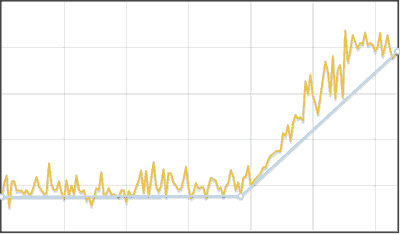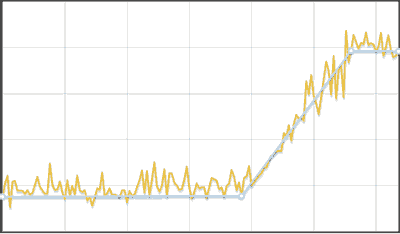
- 行が非常にノイズが多い場合、たとえば平均化されます。 5つの要素。
- 結果には、シリーズの最初と最後のポイントが含まれます。
- 現在のポリラインから行の最も離れた点を見つけて、セットに追加します。
- 折れ線から元の系列への平均偏差が元の系列の平均偏差より小さくなるか、折れ線の頂点の最大数に達するまで繰り返します(この場合、近似はおそらく失敗しました)。
データのシフトを見つけるためのアルゴリズム 
- 元の破線を近似します
- 最初と最後を除いて、ポリラインの各セグメントに対して:
- その高さを見つける 開始と終了のy座標の差として。 高さが無視された間隔より小さい場合、そのようなセグメントは無視されます
- 両方の隣接セグメント そして 各プロットを2で割る 、 、 、 行を近似し、行から行までの平均距離を見つけます- 、 、 、 。
- もし そして より大幅に少ない 、その後、シフトが検出されたと考えています
分布の変化を見つけるためのアルゴリズム 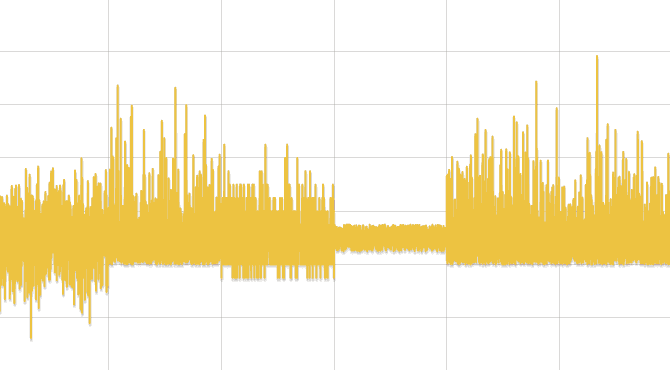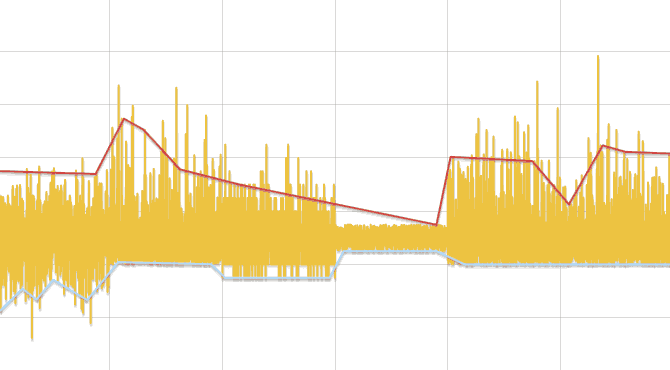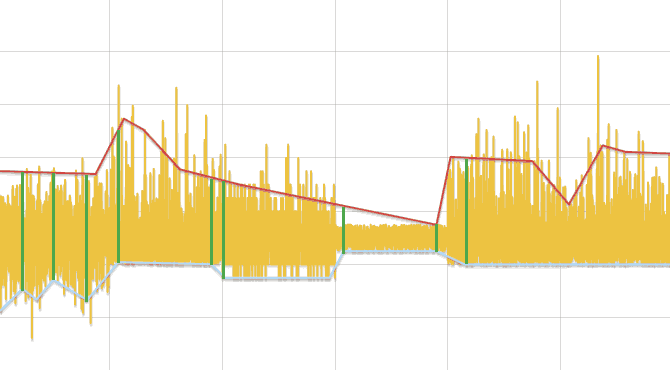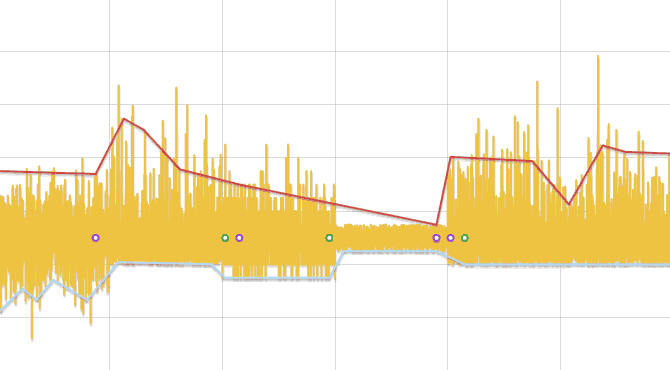
- 最初のシリーズは、データの数に応じて3つ以上の長いセグメントに分割されます。
- 各セグメントでは、最小値と最大値が求められます。 各セグメントをその中心に置き換えると、2つの行(最小値と最大値)が形成されます。 次に、行は個別に処理されます。
- 系列は線形近似され、最初と最後を除く各頂点について、折れ線の隣接する頂点の左右にある最初の系列のデータが、 コルモゴロフ-スミルノフ検定を使用して比較されます。 違いが見つかった場合、ポイントが結果に追加されます。
コルモゴロフ-スミルノフ検定