最初の記事では、実際のビジネスにビッグデータ分析が役立つ方法、クラウドとオンプレミスのHadoopホスティングの違い、およびSAP Cloud Platform Big Data Servicesの主な機能、サービス、テクノロジーについて説明します。 次の記事では、このソリューションの技術的特徴と個々のサービスを詳しく見ていきます。
ビジネスのビッグデータ

SAPのクライアントには、業界、冶金、石油、ガス、その他の「保守産業」から多くのロシアおよび世界の大企業が存在することを誰もが知っています。 現在、これらの企業は、モノのインターネット、機械学習、またはビッグデータとの連携(特に、このビッグデータから新しい価値を抽出しようとしている)で、新しいテクノロジーにますます投資しています。 たとえば、現在の経済状況および地政学的状況にある冶金会社にとって、新しい収益源やコスト削減方法を見つけることが重要です。 これらの方法の1つは、ビジネス、作業プロセス、および外界全体についてのビッグデータで新しいアイデアを検索することです。
無料のオープンソース製品と商用製品の両方で、ビッグデータの保存と操作のための市場には多くのソリューションがあります。 最も一般的なソリューションは、Hadoopとその追加コンポーネントです。 関連性の理由の中で:
- 信頼性
- 拡張性
- 情報ストレージの最適なコスト
- Hadoopでのデータ処理のための多数の追加オープンソースソフトウェアコンポーネント-Spark、Hiveなど
- Hadoopで作業できる多くの専門家が市場で利用可能です
無料のオープンソースソリューションの人気は明らかです。 ただし、Hadoopを工業用に展開する場合、原則として、無料のオープンソースバージョンは純粋な形では使用されません。 ビジネスの世界では、Hadoopオープンソース製品の商用バージョンが人気を集めています。 Cloudera、Hortonworks、その他の開発者によって配布されています。 この場合、プロバイダーはソフトウェアの信頼性とすべてのコンポーネントの相互作用に責任があります。 また、サブスクリプションにより、クラウドを介してビッグデータを操作する機能を提供する代替サービスもあります。
多くの場合、企業はジレンマに直面します。ビッグデータを扱うためのアプローチは、オンプレミス(ローカル)またはクラウドで選択する必要があります。 もちろん、従来のクラウドの懸念から、企業のほとんどの社内IT部門は最初の選択肢に投票します。
調査会社Forresterは、ビッグデータを扱う企業間で、クラウドまたはオンプレミスでのHadoopソリューションの使用方法に関する調査を実施しました。 回答者の37%が、ビッグデータのクラウドサービスへの投資を5%から10%に増やす予定だと答えました。 調査参加者の別の14%は、クラウドベースのHadoopソリューションのコストを10%以上増加させると述べています。 なぜ彼らは雲を選ぶのですか?
独自のサーバーでHadoopを実行することは、データを実験して仮説をテストするときのビッグデータを扱う最初のステップにすぎません。 別のストーリーは、特定の要件があるソリューションを商業運用に入れる必要がある場合です:99.9%の可用性のためのSLA、巨大なデータアレイのストレージの高い信頼性、およびパフォーマンスのためのターゲットKPIのパフォーマンスを確保します。
Hadoopを生産的にオンプレミスに配置することを選択した場合、次のタスクを解決する必要があります。
- 経験豊富なITプロフェッショナルを見つけて採用する
- 必要な機器を購入する
- 必要なディストリビューションを購入し、ソフトウェアをインストールしてセットアップします
- 生産性の高いソリューションを実行する
- 定期的な運用コスト(スタッフの給与、機器のメンテナンスなど)でソリューションを維持する
この準備段階にはかなりの時間がかかることに留意してください。 したがって、企業はオンプレミスとクラウドサービスのどちらかを選択します。
コンサルティング会社Bain&Co.のレポートの1つ Netflixはその一例です。 2016年、同社はビッグデータを処理するために膨大な負荷の下で数千のデータノードを操作しなければならないと発表しました。 毎日3500億のユーザーイベントとサービスからのペタバイトのデータを処理しています。 もちろん、この場合、自分のサーバーの力だけに対処することは不可能です。そうしないと、データセンターを継続的に構築する必要があります。
より「伝統的な産業」からの別の例は、ゼネラルエレクトリックです。 2013年に、彼らは自分のデータセンターからクラウドへの移行を開始しました。 最初に、石油およびガス部門が新しいサービスに切り替え、次に、同社の9,000千を超えるインフラストラクチャアプリケーションの転送が開始されました。 その結果、General Electricは自社のデータセンターの数を30から4に削減し、それに伴い人員、機器などのコストを削減することができました。
SAPはクラウドのトレンドを別にしてはいませんでした。 2016年、Big Data As-a-Serviceモデルを使用する世界有数のサービスプロバイダーの1つであるAltiscaleのチームが加わりました。 彼らのソリューションは、クラウドサブスクリプションモデルを使用してSAPの顧客が利用できるSAP Cloud Platform Big Data Servicesの新製品となり、SAPクラウド構造全体に統合されました。
このソリューションの開発者は、ヤフーの元最高技術責任者(CTO)と、同社のHadoopの開発に携わっている彼の同僚です。 ヤフーで7年間働いた彼らは、小さなHadoopプロジェクトを42,000以上のデータノードを備えた生産的なシステムに変えました。
SAP Cloud Platform Big Data Servicesとは-SAP Cloud Hadoopサービス
SAP Cloud Platform Big Data Servicesは、ビッグデータを操作するためのツールのSaaS(サービスとしてのソフトウェア)モデルです。
SAP Cloud Platform Big Data Servicesのアーキテクチャを検討してください。
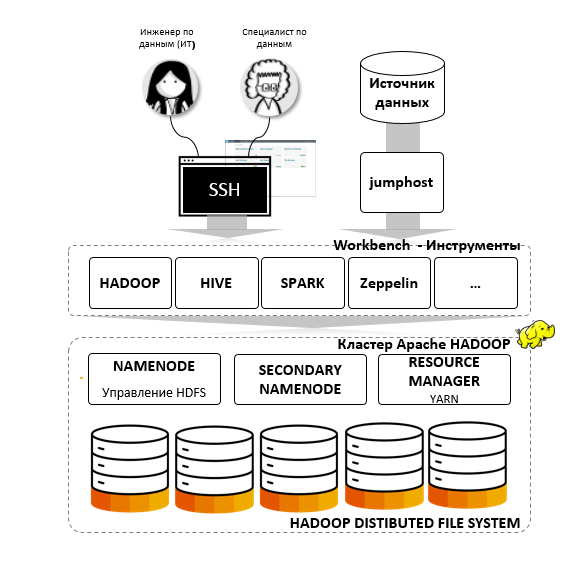
このサービスには、3つの主要な部分が含まれます。
Apache Hadoopクラスター
クラスターは、ODPi認定のHadoopコンパイルを使用します。 つまり、他のサービスのODPi環境で実行されているアプリケーションとスクリプトは、SAP Big Data Servicesで正常に実行されます。
*参考のため、ODPi(Open Data Platform Initiative)は、Hadoopとそのコンポーネントを標準化する非営利組織です。 ODPiには、SAPに加えて、Hortonworks、IBM、SASなどの有名ベンダーが含まれます。
クラスターには、namenode、secondary namenode、resource manager(YARNはサービスの初期構成に含まれます)の3つのタイプのコントロール、サービング、およびデータノードが含まれます。
同時に、重複する名前ノードはOozie、Hive Metastoreなどの追加サービスをサポートします。接続されると、クライアントは必要なリソースを備えた別のクラスターを発行されます。 リソースは、ストレージボリュームとマシン時間数によって記述されます。 必要に応じて、重要な計算の期間中または継続的にクラスターリソースを柔軟に拡張できます。
Workbenchは、Big Data Serviceへの単一のアクセスポイントです。
セキュリティ上の理由から、Hadoopクラスターへの直接アクセスはサービス要員とワークベンチに制限されています。 クライアントは、ローカルHadoop、Hive、Spark、Oozie、Pig、およびSAP LumiraやSAP Predictive Analyticsなどのデータサイエンスとデータエンジニアリングに必要なその他のコンポーネントを含むワークベンチにのみアクセスできます。

サービスの構成に関するより詳細な情報はウェブサイトで見つけることができます。
ワークベンチを使用すると、クライアントはスクリプトを実行し、ビジネスインテリジェンスツールを使用してデータを調べ、他のタスクを解決できます。 次に、Workbenchは高速チャネルを介してHadoopクラスターと密接に連携します。
ビッグデータサービスポータル
これは、ユーザーの保守、ビッグデータサービスへのアクセスキーの生成、クラスター使用統計の表示、およびクライアントが持っている他の操作タスクの実行に使用されます。
ジャンプホストサーバーは、ビッグデータサービスを外部に接続するために使用されます。 すべてのネットワーク相互作用は、ローカルIPアドレスのスペースで実行されます-仮想プライベートクラウド。 ビッグデータサービスにアクセスする標準的な方法はSSHです。 顧客の要求に応じて、他の接続オプションが利用可能です。 Big Data ServiceはKerberos認証もサポートしているため、シングルサインオン(SSO)を使用できます。
Big Data Serviceは、他のSAPクラウドサービスとオンプレミスソリューションと対話できます。 統合には次のオプションを使用できます。
- Kafka Streamingによるセンサーデータの収集と処理
- Kafka ConnectorsまたはSAP Data Servicesを使用したリレーショナルデータベースからのデータの抽出
- スマートデータアクセスとスマートデータ統合によるSAP HANAプラットフォーム上のSAPシステムとの相互作用
- Hadoop分散ファイルシステム(HDFS)レベルでのオンプレミスHadoopとの対話
ビッグデータサービスに接続された通信チャネルは、クライアントソースシステムからデータを高速でダウンロードするように編成されています。
来年のビッグデータサービスロードマップ-VoraビッグデータとSAPデータハブを操作するためのSAPソリューションとの統合。 これらについては、次のいずれかの記事で詳しく説明します。
SAP Cloud Platform Big Data Servicesと他のクラウドHadoopソリューションの違い
SAPソリューションと他のソリューションの主な違いは、サービスや他のSAPシステムとの統合により、ビジネスプロセスに有機的に統合できることです。 これは、実際にビッグデータを収益化するのに役立つ重要な要素です。 Hadoopで作業しているときにデータ分析の結果を見るのがデータサイエンティストのみである場合、ビジネスユーザーに新しいアイデアを実践する必要性をまだ納得させていません。実際に仮説が適用されるという保証はありません。 SAP Cloud Platform Big Data Servicesは、ビジネスプロセスのステップの1つとして、社内のITシステムと直接統合できます。 次の記事では、SAPソリューションと他のソリューションとの違い、ビッグデータスペシャリストの仕事の結果を実際のビジネスプロセスに統合する方法について詳しく説明します。
SAP Cloud Platform Big Data Services Clientのユースケース
Glu mobile
Glu Mobileは、成功しているクッキングダッシュ、ディアハンター、コントラクトキラー、キムカーダシアン:ハリウッド、フロントラインコマンドープロジェクトなど、モバイルゲームの世界最大の開発者の1つです。 同社には世界中に開発スタジオがあり、そのうちの1つはモスクワにあります。
Glu Mobileは、無料でダウンロードでき、内部のマイクロトランザクションで収益化される無料のゲームサービスを開発およびサポートしています。 このようなゲームサービスの場合、プレーヤーが長時間それらを離れないことが重要です。
Glu Mobileプロジェクトの毎日の視聴者は500万人以上のアクティブユーザーであり、同社のゲームは13億回以上インストールされています。 このような大規模な視聴者を想定して、同社は次のタスクに直面しています-プレーヤーを快適で面白くすると同時に、1人のプレーヤーの利益指標LTV(ライフタイムバリュー)を増加させる
これを行うために、会社はプロジェクトから膨大なデータをリアルタイムで収集します。
- 毎秒3万を超えるユーザーアクション
- 毎日約20億のユーザーアクティビティレポート
- さまざまなメトリックからの1億を超えるイベント
- SAP Cloud Platformに基づいて保存された2兆のユーザーイベント
当初、Glu MobileはオンプレミスのHadoopソリューションを使用しようとしましたが、次の問題に直面しました。
- データ量が増えれば増えるほど、データを扱うのが難しくなりました。
- Hadoopの弱い内部チーム
- 弱いシステムの信頼性、定期的なサーバークラッシュ
- データベースクエリを実行するときの弱い結果
SAP Cloud Platform Big Data Servicesへの切り替えの結果、Glu Mobileチームは次の結果を受け取りました。
- このソリューションは、データ処理会社のニーズを満たします
- 急速に出現する膨大な量の新しいデータを処理する能力
- パフォーマンスと信頼性の面で市場で最高のソリューションの1つ。
- 内部チームはHadoopで時間を無駄にすることなく、データサイエンスに切り替えました
- ビジネスニーズに基づいた簡単なスケーラビリティ
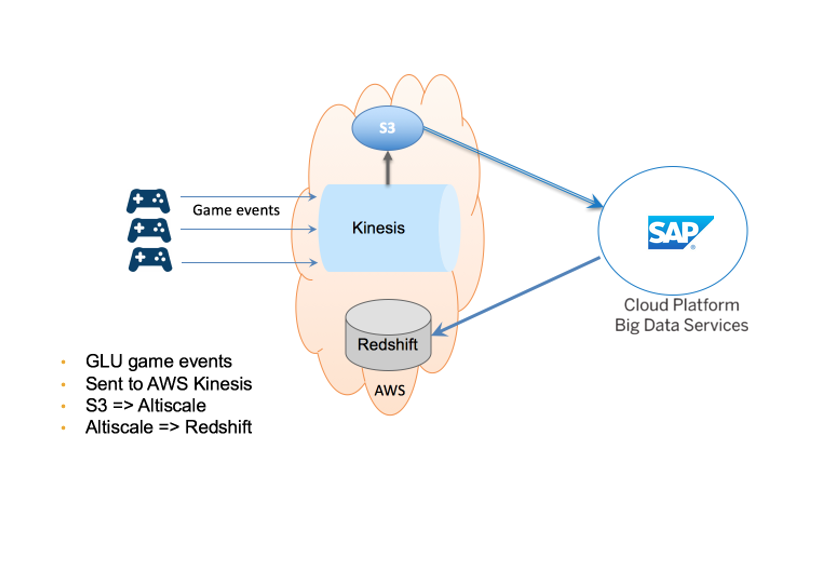
Glu MobileがSAP Cloud Platform Big Data Servicesを使用する方法:
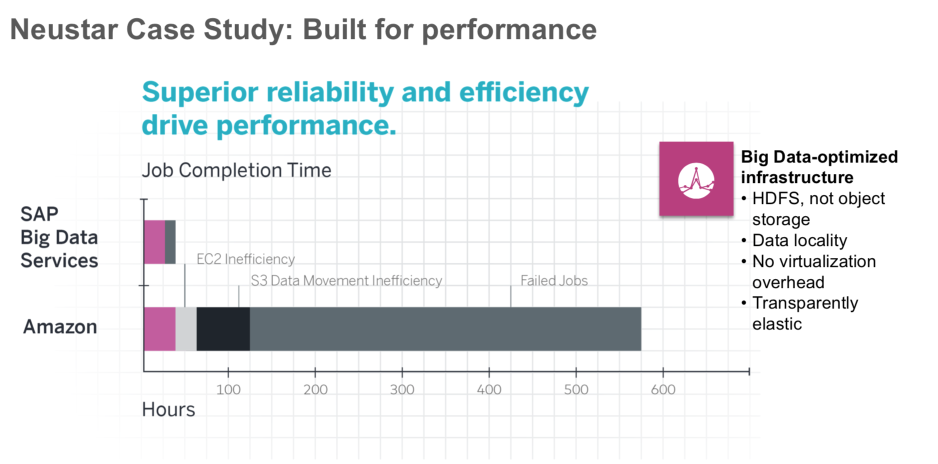
ケースNeustar MarketShare DecisionCloud
Neustarは、マーケティングキャンペーンの結果を分析し、ユーザーの行動を分析するためのサービスを顧客に提供する会社です。 同社は、小売、金融、医薬品、自動車産業、テクノロジー企業など、多くの業界で多種多様なデータを収集しています。
現在、SAP Cloud Big Data Serviceのサービス施設に投稿されるデータの量は約2.5ペタバイトです。
Neustarがビッグデータに以前のプラットフォームを使用した場合、次の問題がありました。
- 操作を完了するのに時間がかかりすぎる
- 弱いサービスの信頼性
- 製品開発の難しさ
- インフラストラクチャメンテナンスコストの増加
- 限られた数のクライアントのみと連携する能力
SAP Cloud Platform Big Data Servicesに切り替えた後、同社は次の利点を得ました。
- 高いパフォーマンスとサービスの信頼性
- Hadoopを操作する代わりに分析に集中する機能
- より効率的なリソース割り当てとコスト管理
- 市場競争力の向上

最初のデータ会社
First Dataは、銀行カード取引を処理する会社です。 これは、米国最大の銀行カード処理サービスです(市場の最大45%)。
2015年の実装の最初の段階で、SAPクラウドプラットフォームビッグデータサービスソリューションは、小規模ビジネス向けのファーストデータ機能を拡張し、50万米ドルのコストを削減しました。 2017年の第2段階では、このソリューションは銀行カードでの不正検出の導入を支援し、さらに200万ドルのACVを節約しました。
SAPソリューションを使用すると、First Dataのお客様は次の情報を取得することもできました。
- 取引情報とサードパーティのデータをリンクする
- 地理的または人口統計学的要因に応じて、顧客データとプロモーションキャンペーンの結果の分析を取得する
- 結果を類似のビジネスと比較する
- ビッグデータに基づいて販売、マーケティング活動を改善し、顧客ロイヤルティを高めるための推奨事項を取得する
ビッグデータを操作するための以前のインフラストラクチャの問題:
- 独自のソリューションの使用を拡大するために必要な投資の不可能な量
- 情報を詳細に研究できない
- 限られた数の視覚化オプションが利用可能
- 弱いベンダーサポート
SAPソリューションを選択する際、First Dataは次の目標に基づいています。
- より多くの顧客の間で製品の使用を拡大する
- より詳細なデータの分析とより大きな視覚化セットのサポート
- 製品に新しい機能を追加し、時間とともにインタラクティブ性を高める機能
SAPに切り替えるメリットは何ですか?
- 大幅なコスト削減
- 設定された生産的な目標の達成
- 詳細情報の分析における柔軟性
- データの視覚化のための十分な機会
- 技術専門家を含むベンダーからの幅広いサポート
- ビッグデータを操作するための生産的なプラットフォーム
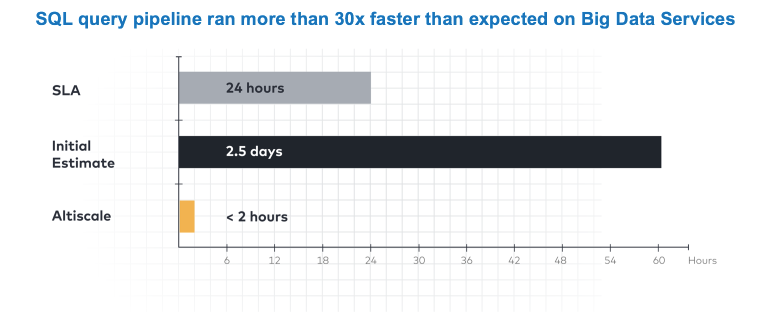
SAPソリューションへの移行の結果の1つ-新しいソリューションでのSQLクエリの実行は、予想よりも30倍高速です。
SAP Cloud Platform Big Data Servicesに関する記事の簡単な要約 :
- プロジェクトのクイックスタート
- 数ヶ月ではなく、数日以内に産業打ち上げのための機器の可用性
- クラウドサービスの使用による投資の迅速な回収(専門家とアナリストの意見により確認)
- 信頼性とSLA 99.99%のサービス可用性の点で、産業用ソリューションの要件を満たしています
- 革新的なアーキテクチャと特別に開発されたソフトウェアバージョンによる高いデータ処理速度
- Cloud Hadoopサービスは、既存のオンプレミスHadoopクラスターおよびその他のシステムと正常に共存します
- クライアントは、ハードウェア、Hadoopの管理、コンポーネントの更新について心配する必要はありません。これらのタスクはプロバイダーの責任です。
- SAP Big Data Serviceは、有名なSAP Max Attentionプレミアムサポートサービスに匹敵するサポートサービスを顧客に提供します。 クライアントは、計算の実行に関する推奨事項など、さまざまな問題について専門家チームから支援を求めることができます。

次の記事では、SAP Cloud Platform Big Data Serviceの開発計画について詳しく説明します。他のSAPサービスやソリューションとの統合、新機能やアプリケーションなどについてです。
この資料を最後まで読んで、SAP Cloud Platform Big Data Servicesの使用方法を独自にテストしたい場合は、当社に連絡して、サービスへの無料のテストアクセスを取得してください 。