
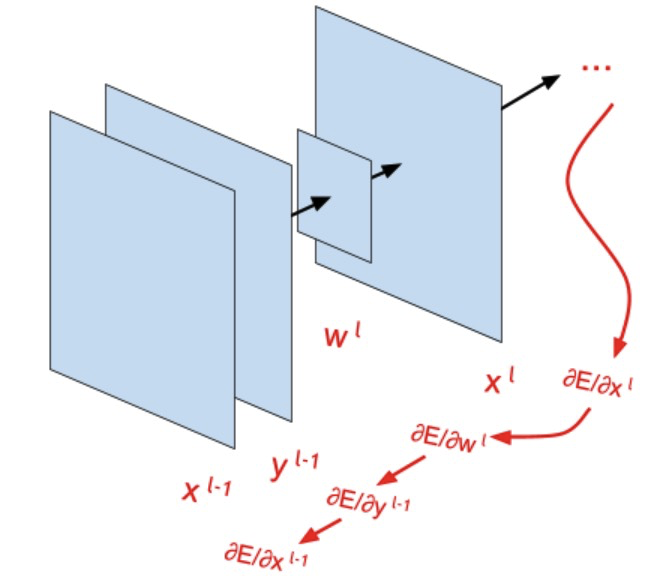
前回の記事では、将来のモデルを構成するすべてのレイヤーと機能を概念的に検討しました。 今日は、このモデルのトレーニングを担当する公式を導き出します。 損失関数から始めて畳み込み層で終わる、逆順で層を解析します。 数式を理解するのが困難な場合は、エラーの逆伝播法の詳細な説明 (写真)を理解し、 複雑な関数の微分規則を覚えておくことをお勧めします。
損失関数を介したエラーの逆伝播の公式の導出
これは、損失関数の偏微分です。 E モデル出力。
beginarrayrcl dfrac partialE partialyli&=& dfrac partial frac12 sumni=0(ytruthi−yli)2 partialyli&=& dfrac partial frac12((ytruth0−yl0)2+ ldots+(ytruthi−yli)2+ ldots+(ytruthn−yln)2) partialyli&=& dfrac partial frac12(ytruthi−yli)2\パーシャルyli= frac12 cdot2 cdot(ytruthi−yli)2−1 cdot frac partial(ytruthi−yli) partialyli&=&(ytruthi−yli) cdot(−1)=yli−y真理i endarray
デリバティブ partial frac12(y真実i−yli)2 分子では、複素関数の導関数として扱います。 (un)′=nun−1 cdotu′ 。 ここで、ところで、人はどのように見ることができます frac12 そして 2 、そして最初に式に追加した理由が明らかになります frac12
最初は標準偏差を使用しましたが、分類問題にはクロスエントロピーを使用する方が適切です(説明付きのリンク )。 以下は、backpropの式です。可能な限り詳細な式の出力を記述しようとしました。
beginarrayrcl dfrac partialE partialyli&=& dfrac partial(− sumni=0(ytruthi cdotln(yli)) partialyli&=& dfrac partial(−(ytruth0ln(yl0)+ ldots+ytruthiln(yli)+ ldots+ytruthnln(yln)) partialyli&=& dfrac partial(−ytruthiln(yli)) partialyli=− dfracytruthiyli endarray
覚えておいて largeln(x)′= frac1x
アクティベーション関数を介したbackprop式の導出
... ReLU経由
f '_ {ReLU} = \ frac {\ mathrm {\ partial} y ^ l_i} {\ mathrm {\ partial} x ^ l_i} = \ left \ {\ begin {matrix} 1、&if \ enspace x ^ l_i> 0 \\ 0、その他の場合\\ \ end {matrix} \ right。
どこで large frac partialyli partialxli -アクティベーション機能によるバックプロップの指定。
つまり、アクティベーション関数を直接通過する際に最大で選択された要素にエラーを渡し(前のレイヤーからのエラーを1倍します)、選択されなかったため結果に影響を与えなかった要素にはパスしません(乗算します)前のレイヤーからゼロへのエラー)。
... シグモイドを通して
beginarrayrclf′sigmoid&=& dfrac mathrm partial mathrm partialxli left( dfrac11+e−xli right)= dfrac mathrm partial mathrm partialxli(1+e−xli)−1&=&−(1+e−xli)−2(−e−xli)= dfrace−xli(1+e−xli)2&=& dfrac11+e−xli cdot dfrace−xli1+e−xli= dfrac11+e−xli cdot dfrac(1+e−xli)−11+e−xli&=& dfrac11+e−xli cdot left( dfrac1+e−xli1+e−xli− dfrac11+e−xli\右)= dfrac11+e−xli cdot left(1− dfrac11+e−xli right)&=&fsigmoid cdot(1−fsigmoid)\終了配列
ここで覚えておく必要があります (eu(x))′=eu(x) cdot(u(x))′
同時に largefsigmoid= frac11+e−xli シグモイド式です
さらに示す large frac partialE partialxli どうやって \大\デルタli (どこ large frac partialE partialxli= frac partialE partialyli frac partialyli partialxli )
...また、softmax経由 (またはこちら )
i番目の出力のsoftmax関数はその計算だけに依存しないため、これらの計算はもう少し複雑に思えました。 xli 他のすべてからも xlj\エンスペース foralli、j in(0、...、n) 、その合計は、ネットワークを直接通過する公式の分母にあります。 したがって、backpropの式は2つに「分割」されます。 xli そして xlj :
beginarrayrcl dfrac partialyli partialxli&=& dfrac partial partialxli left( dfracexli sumnk=0exlk\右)= dfracexli cdot sumnk=0exlk−exli cdotexli left( sumnk=0exlk\右)2&=& dfracexli cdot left( sumnk=0exlk−exli\右) sumnk=0exlk cdot sumnk=0exlk=yli cdot dfrac sumnk=0exlk−exli sumnk=0exlk&=&yli cdot left( dfrac sumnk=0exlk sumnk=0exlk− dfracexli sumnk=0exlk\右)=yli cdot(1−yli) endarray
式を適用します \大\左( fracuv\右)′= fracu′v−uv′v2 どこで u=exli そして largev= sumnk=0exlk
同時に large frac partial partialxli sumnk=0exlk= frac partial(exl0+ ldots+exli+ ldots+exln) partialxli= frac partialexli partialxli=exli
そして、の偏微分 xlj :
beginarrayrcl dfrac partialyli partialxlj&=& dfrac partial partialxlj left( dfracexli sumnk=0exlk\右)= dfrac0 cdot sumnk=0exlk−exli cdotexlj left( sumnk=0exlk right)2 \&=& dfracexli cdotexlj sumnk=0exlk cdot sumnk=0exlk=−yli cdotylj endarray
上記の式に基づいて、エラーが逆方向に伝播するときに関数が(コードで)返す必要のあるニュアンスがあります large fracylxl この場合、1つを計算するため、softmaxで yli すべて使用されています xl または、言い換えれば、それぞれ xli すべてに影響する yl :

ソフトマックスの場合 large frac partialE partialxli 等しくなります large sumnk=0 frac partialE partialylk frac partialylk partialxli (金額が登場しました!)、つまり:
frac partialE partialxli= frac partialE partialyl0 frac partialyl0 partialxli+...+ frac partialE partialyl1 frac partialyl1 partialxli+...+ frac partialE partialyln frac partialyln partialxli qquad foralli in(0、...n)
この場合、値 large frac partialE partialylk すべてのために k 損失関数を介してこのバックプロップがあります。 見つけることが残っている large frac partialylk partialxli すべてのために k そしてすべて i -つまり、マトリックスです。 展開された形式の行列乗算の下 large frac partialylk partialxli -行列と行列の乗算はどこから来ますか。
beginbmatrix& frac partialE partialxl0& frac partialE partialxl1&。..& frac partialE partialxln endbmatrix== scriptsize beginbmatrix&( frac partialE\部分yl0 frac partialyl0 partialxl0+ frac partialE partialyl1 frac partialyl1 partialxl0+ ldots+ frac partialE\部分yln frac partialyln partialxl0)&( frac partialE partialyl0 frac partialyl0 partialxl1+ frac partialE\部分yl1 frac partialyl1 partialxl1+ ldots+ frac partialE partialyln frac partialyln partialxl1)&...&( frac\部分E\部分yl0 frac\部分yl0\部分xln+ frac\部分E\部分yl1 frac\部分yl1\部分xln+ ldots+ frac\部分E\部分yln frac\部分yln\部分xln) endbmatrix= beginbmatrix& frac partialE partialyl0& frac partialE partialyl1&...& frac partialE partialyln endbmatrix beginbmatrix& frac partialyl0 partialxl0& frac partialyl0 partialxl1&...& frac partialyl0 partialxln& frac partialyl1 partialxl0& frac partialyl1 partialxl1&...& frac partialyl1 partialxln&...&...&...&...& frac partialyln partialxl0& frac partialyln partialxl1&...& frac\部分的なyln\部分的なxln endbmatrix
それは分解のこの最後の行列についてでした- large frac partialyl partialxl 。 行列を乗算する方法をご覧ください large frac partialE partialyl そして large frac partialyl partialxl 私たちは得る large frac partialE partialxl 。 したがって、softmaxのbackprop関数(コード内)の出力は行列でなければなりません large frac partialyl partialxl 、その時点で既に計算されているものを掛けたとき large frac partialE partialyl 取得します large frac partialE partialxl 。
完全に接続されたネットワークを介したバックプロップ

重み行列を更新するためのbackprop式の出力 wl fcネットワーク
\ begin {array} {rcl} \ dfrac {\ partial E} {\ partial w ^ l_ {ki}}&=&\ dfrac {\ partial E} {\ partial y ^ l_i} \ dfrac {\ partial y ^ l_i} {\ partial x ^ l_i} \ dfrac {\ partial x ^ l_i} {\ partial w ^ l_ {ki}} = \ delta ^ l_i \ cdot \ dfrac {\ partial x ^ l_i} {\ partial w ^ l_ {ki}} = \ delta ^ l_i \ cdot \ dfrac {\ partial \ left(\ sum ^ m_ {k '= 0} w ^ l_ {k'i} y ^ {l-1} _ {k'} + b ^ l_i \ right)} {\ partial w ^ l_ {ki}} \\&=&\ delta ^ l_i \ cdot \ dfrac {\ partial \ left(w ^ l_ {0i} y ^ {l-1} _ {0} + \ ldots + w ^ l_ {ki} y ^ {l-1} _ {k} + ... w ^ l_ {mi} y ^ {l-1} _ {m} + b ^ l_i \右)} {\ partial w ^ l_ {ki}} = \ delta ^ l_i \ cdot y ^ {l-1} _k \\ && \ forall i \ in(0、...、n)\ enspace \ forall k \ in(0、...、m)\ end {array}
分子の合計を展開し、すべての偏微分がゼロに等しいことを取得します large frac partialwlkiyl−1k partialwlki それは等しい yl−1k 。 このケースは次の場合に発生します k′=k 。 バーは、ここで「内部」サイクルを示します k 、つまり、これはまったく関連しないイテレータです k から large frac partialE partialwlki
そのため、マトリックス形式で表示されます。
frac partialE partialwl= left(yl−1 right)T cdot deltal tiny(m timesn) enspace\エンスペース\エンスペース(m\回1)\エンスペース\エンスペース(1\回n)
マトリックス次元 yl−1 等しい (1\回m) 、および行列乗算を生成するには、行列を転置する必要があります。 以下では、マトリックスを完全に「拡張された」形式で表示し、計算がより明確に見えるようにします。
beginbmatrix& frac partialE partialwl00& frac partialE partialwl01&。..& frac partialE partialwl0n& frac partialE partialwl10& frac partialE partialwl11&...& frac partialE partialwl1n&...&。..&...&...& frac partialE partialwlm0& frac partialE partialwlm1&...& frac partialE partialwlmn endbmatrix= beginbmatrix&yl−10 deltal0&yl−10 deltal1&...&yl−10 deltaln&yl−11 deltal0&yl−11 deltal1&...&yl−11 deltaln&。..&...&...&...&yl−1m deltal0&yl−1m deltal1&。..&yl−1m deltaln endbmatrix qquad qquad qquad qquad qquad qquad= beginbmatrix&yl−10&yl−11&...&yl−1m endbmatrix beginbmatrix& deltal0& deltal1&...& deltaln endbmatrix
マトリックスを更新するためのbackprop式の出力 bl
バイアスについては、すべての計算は前の段落と非常に似ています。
\ begin {array} {rcl} \ dfrac {\ partial E} {\ partial b ^ l_ {i}}&=&\ dfrac {\ partial E} {\ partial y ^ l_i} \ dfrac {\ partial y ^ l_i} {\ partial x ^ l_i} \ dfrac {\ partial x ^ l_i} {\ partial b ^ l_ {i}} = \ delta ^ l_i \ cdot \ dfrac {\ partial x ^ l_i} {\ partial b ^ l_ {i}} \\&=&\ delta ^ l_i \ cdot \ dfrac {\ partial \ left(\ sum ^ m_ {k '= 0} w ^ l_ {k'i} y ^ {l-1} _ { k '} + b ^ l_i \ right)} {\ partial b ^ l_ {i}} = \ delta ^ l_i \\ && \ forall i \ in(0、...、n)\ end {array}
それは明らかです large frac partial left( summk′=0wlk′iyl−1k′+bli right)\部分的bli=1
マトリックス形式では、すべてが非常に単純です。
frac partialE partialbl= deltal tiny(1 timesn) enspace enspace(1 timesn)
を介した逆プロップ式の導出 yl−1
次の式では、 i 各という事実から生じる yl−1k それぞれに接続されている xli (レイヤーは完全に接続されていると呼ばれることに注意してください )
\ begin {array} {rcl} \ dfrac {\ partial E} {\ partial y ^ {l-1} _ {k}}&=&\ sum_ {i = 0} ^ {n} \ delta ^ l_i \ cdot \ dfrac {\ partial x ^ l_i} {\ partial y ^ {l-1} _ {k}} = \ sum_ {i = 0} ^ {n} \ delta ^ l_i \ cdot \ dfrac {\ partial \ left (\ sum ^ m_ {k '= 0} w ^ l_ {k'i} y ^ {l-1} _ {k'} + b ^ l_i \ right)} {\ partial y ^ {l-1} _ {k}} \\&=&\ sum_ {i = 0} ^ {n} \ delta ^ l_i \ cdot \ dfrac {\ partial \ left(w ^ l_ {0i} y ^ {l-1} _ {0 } + \ ldots + w ^ l_ {ki} y ^ {l-1} _ {k} + ... w ^ l_ {mi} y ^ {l-1} _ {m} + b ^ l_i \右) } {\ partial y ^ {l-1} _ {k}} \\&=&\ sum_ {i = 0} ^ {n} \ delta ^ l_i \ cdot w ^ l_ {ki} \\ && \ forall i \ in(0、...、n)\ enspace \ forall k \ in(0、...、m)\ end {array}
分子を分解すると、すべての偏微分がゼロに等しいことがわかります。ただし、 k′=k :
frac partial left(wl0iyl−10+ ldots+wlkiyl−1k+...wlmiyl−1m+bli right) partialyl−1k= frac partialwlkiyl−1k partialyl−1k=wlki
そして、マトリックス形式で:
frac partialE partialyl−1= deltal cdot(wl)T tiny(1 timesm) enspace enspace\エンスペース(1\回n)\エンスペース(n\回m)
さらに、「オープン」形式のマトリックス。 私は意図的に、転置する前の形で最新の行列のインデックスを残したので、転置後にどの要素がどこに行ったのかを確認した方がよいことに注意してください。
beginbmatrix& frac partialE partialyl−10& frac partialE partialyl−11&...& frac partialE partialyl−1m endbmatrix= scriptsize beginbmatrix&( deltal1wl00+ deltal2wl01+ ldots+ deltalnwl0n)&( deltal1wl10+ deltal2wl11+ ldots+ deltalnwl1n)&。..&( deltal1wlm0+ deltal2wlm1+ ldots+ deltalnwlmn) endbmatrix= enspace enspace= beginbmatrix& deltal0& deltal1&...& deltaln endbmatrix beginbmatrix&wl00&wl01&...&wl0n&wl10&wl11&...&wl1n&...&...&...&...&wlm0&wlm1&...&wlmn endbmatrixT= beginbmatrix& deltal0& deltal1&...& deltaln endbmatrix beginbmatrix&wl00&wl10&...&wlm0&wl01&wl11&...&wlm1&...&...&...&...&wl0n&wl1n&...&wlmn endbmatrix
さらに示す large frac partialE partialyl−1k どうやって deltal−1k 、および完全に接続されたネットワークの後続のレイヤーを介したエラーの逆伝播のすべての式は、同様の方法で計算されます。
maxpoolingによるバックプロップ
エラーは、maxpoolingステップで最大として選択された元のマトリックスの値のみを「通過」します。 マトリックスの残りのエラー値はゼロになります(これらの要素の値は、ネットワークを直接通過する際にmaxpooling関数によって選択されなかったため、最終結果に影響しなかったため、論理的です)。
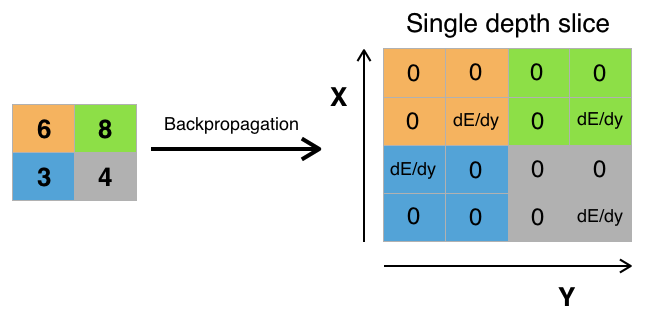
Pythonのmaxpoolingの実装は次のとおりです。
import numpy as np y_l = np.array([ [1,0,2,3], [4,6,6,8], [3,1,1,0], [1,2,2,4]]) other_parameters={ 'convolution':False, 'stride':2, 'center_window':(0,0), 'window_shape':(2,2) } def maxpool(y_l, conv_params): indexes_a, indexes_b = create_indexes(size_axis=conv_params['window_shape'], center_w_l=conv_params['center_window']) stride = conv_params['stride'] # y_l_mp = np.zeros((1,1)) # y_l y_l_mp_to_y_l = np.zeros((1,1), dtype='<U32') # backprop ( ) # if conv_params['convolution']: g = 1 # else: g = -1 # # i j y_l , for i in range(y_l.shape[0]): for j in range(y_l.shape[1]): result = -np.inf element_exists = False for a in indexes_a: for b in indexes_b: # , if i*stride - g*a >= 0 and j*stride - g*b >= 0 \ and i*stride - g*a < y_l.shape[0] and j*stride - g*b < y_l.shape[1]: if y_l[i*stride - g*a][j*stride - g*b] > result: result = y_l[i*stride - g*a][j*stride - g*b] i_back = i*stride - g*a j_back = j*stride - g*b element_exists = True # , i j if element_exists: if i >= y_l_mp.shape[0]: # , y_l_mp = np.vstack((y_l_mp, np.zeros(y_l_mp.shape[1]))) # y_l_mp_to_y_l y_l_mp y_l_mp_to_y_l = np.vstack((y_l_mp_to_y_l, np.zeros(y_l_mp_to_y_l.shape[1]))) if j >= y_l_mp.shape[1]: # , y_l_mp = np.hstack((y_l_mp, np.zeros((y_l_mp.shape[0],1)))) y_l_mp_to_y_l = np.hstack((y_l_mp_to_y_l, np.zeros((y_l_mp_to_y_l.shape[0],1)))) y_l_mp[i][j] = result # y_l_mp_to_y_l , # y_l y_l_mp_to_y_l[i][j] = str(i_back) + ',' + str(j_back) return y_l_mp, y_l_mp_to_y_l def create_axis_indexes(size_axis, center_w_l): coordinates = [] for i in range(-center_w_l, size_axis-center_w_l): coordinates.append(i) return coordinates def create_indexes(size_axis, center_w_l): # coordinates_a = create_axis_indexes(size_axis=size_axis[0], center_w_l=center_w_l[0]) coordinates_b = create_axis_indexes(size_axis=size_axis[1], center_w_l=center_w_l[1]) return coordinates_a, coordinates_b out_maxpooling = maxpool(y_l, other_parameters) print(' :', '\n', out_maxpooling[0]) print('\n', ' backprop:', '\n', out_maxpooling[1])

関数が返す2番目の行列は、maxpooling操作中に元の行列から選択された要素の座標です。
畳み込みネットワークを介したバックプロップ
畳み込みカーネルを更新するためのbackprop式の出力
\ begin {array} {rcl} \ dfrac {\ partial E} {\ partial w ^ l_ {ab}}&=&\ sum_ {i} \ sum_ {j} \ dfrac {\ partial E} {\ partial y ^ l_ {ij}} \ dfrac {\ partial y ^ l_ {ij}} {\ partial x ^ l_ {ij}} \ dfrac {\ partial x ^ l_ {ij}} {\ partial w ^ l_ {ab}} \\&=&^ {(1)} \ sum_ {i} \ sum_ {j} \ dfrac {\ partial y} l_ {ij}} \ dfrac {\ partial y ^ l_ {ij}} {\ partial x ^ l_ {ij}} \ cdot \ dfrac {\ partial \ left(\ sum_ {a '=-\ infty} ^ {+ \ infty} \ sum_ {b' =-\ infty} ^ {+ \ infty} w ^ l_ {a'b '} \ cdot y ^ {l-1} _ {(is-a')(js-b ')} + b ^ l \ right)} {\ partial w ^ l_ { ab}} \\&=&^ {(2)} \ sum_ {i} \ sum_ {j} \ dfrac {\ partial E} {\ partial y ^ l_ {ij}} \ dfrac {\ partial y ^ l_ { ij}} {\ partial x ^ l_ {ij}} \ cdot y ^ {l-1} _ {(is-a)(js-b)} \\ && \ forall a \ in(-\ infty、.. 。、+ \ infty)\ enspace \ forall b \ in(-\ infty、...、+ \ infty)\ end {array}
(1)ここで、単に式を xlij なでる a′ そして b′ 別のイテレータであることを意味します。
(2)ここで、分子の量を次のようにレイアウトします。 a そして b :
small sumi sumj frac partialE partialylij frac partialylij partialxlij frac partial left(wl− infty、− infty cdotyl−1(is+ infty)(js+ infty)+ ldots+wlab cdotyl−1(is−a)(js−b)+ ldots+wl infty、 infty cdotyl−1(is− infty)(js− infty)+bl right) partialwlab
つまり、分子内のすべての偏微分。ただし、 a′=a、b′=b ゼロに等しくなります。 同時に large frac partialwlab cdotyl−1(is−a)(js−b) partialwlab 等しい yl−1(is−a)(js−b)
上記のすべてが畳み込みに適用されます。 相互相関のバックプロップ式は、次の場合の符号の変更を除いて似ています a そして b :
frac partialE partialwlab= sumi sumj frac partialE partialylij frac\部分的ylij\部分的xlij cdotyl−1(is+a)(j+b)
ここで重要なのは、畳み込みカーネル自体が最終式に含まれていないことです。 一種の畳み込み演算がありますが、すでに参加しています large frac partialE partialxlij そして yl−1 、およびコアとして機能します large frac partialE partialxlij 、それでも、特にステップ値が1より大きい場合、畳み込みのようには見えません。 large frac partialE partialxlij 「破る」 yl−1 、これは通常の畳み込みに完全には似ていません。 この「崩壊」は、パラメーターが i そして j 数式のループ内で繰り返します。 デモコードを使用すると、これがすべてどのように見えるかを確認できます。
import numpy as np w_l_shape = (2,2) # stride = 1 dEdx_l = np.array([ [1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,16]]) # stride = 2 'convolution':False ( - x_l ) # dEdx_l = np.array([ # [1,2], # [3,4]]) # stride = 2 'convolution':True # dEdx_l = np.array([ # [1,2,3], # [4,5,6], # [7,8,9]]) y_l_minus_1 = np.zeros((4,4)) other_parameters={ 'convolution':True, 'stride':1, 'center_w_l':(0,0) } def convolution_back_dEdw_l(y_l_minus_1, w_l_shape, dEdx_l, conv_params): indexes_a, indexes_b = create_indexes(size_axis=w_l_shape, center_w_l=conv_params['center_w_l']) stride = conv_params['stride'] dEdw_l = np.zeros((w_l_shape[0], w_l_shape[1])) # if conv_params['convolution']: g = 1 # else: g = -1 # # a b for a in indexes_a: for b in indexes_b: # y_l, ( stride>1) x_l demo = np.zeros([y_l_minus_1.shape[0], y_l_minus_1.shape[1]]) result = 0 for i in range(dEdx_l.shape[0]): for j in range(dEdx_l.shape[1]): # , if i*stride - g*a >= 0 and j*stride - g*b >= 0 \ and i*stride - g*a < y_l_minus_1.shape[0] and j*stride - g*b < y_l_minus_1.shape[1]: result += y_l_minus_1[i*stride - g*a][j*stride - g*b] * dEdx_l[i][j] demo[i*stride - g*a][j*stride - g*b] = dEdx_l[i][j] dEdw_l[indexes_a.index(a)][indexes_b.index(b)] = result # "" w_l # demo print('a=' + str(a) + '; b=' + str(b) + '\n', demo) return dEdw_l def create_axis_indexes(size_axis, center_w_l): coordinates = [] for i in range(-center_w_l, size_axis-center_w_l): coordinates.append(i) return coordinates def create_indexes(size_axis, center_w_l): # coordinates_a = create_axis_indexes(size_axis=size_axis[0], center_w_l=center_w_l[0]) coordinates_b = create_axis_indexes(size_axis=size_axis[1], center_w_l=center_w_l[1]) return coordinates_a, coordinates_b print(convolution_back_dEdw_l(y_l_minus_1, w_l_shape, dEdx_l, other_parameters))

バイアスの重みを更新するためのバックプロップ式の出力
前の段落と同様に、置換のみ wlab に bl 。 1つの機能マップに1つのバイアスを使用します。
beginarrayrcl dfrac partialE partialbl&=& sumi sumj dfrac partialE partialylij dfrac partialylij partialxlij dfrac partialxlij partialbl&=& small sumi sumj dfrac partialE partialylij dfrac partialylij partialxlij cdot dfrac partial left( sum+ inftya=− infty sum+ inftyb=− inftywlab cdotyl−1(is−a)(js−b)+bl right) partialbl&=& sumi sumj dfrac partialE partialylij dfrac partialylij partialxlij endarray
つまり、合計をすべてに展開すると i そして j に関して、すべての偏微分 \部分的なbl 1に等しくなります。
frac partial left( sum+ inftya=− infty sum+ inftyb=− inftywlab cdotyl−1(is−a)(js−b)+bl right) partialbl=1
1枚の標識のカードについては、このカードのすべての要素と「接続」されている1つのバイアスのみ。 したがって、バイアス値を調整するときは、エラーの逆伝播中に取得したマップのすべての値を考慮する必要があります。 別の方法として、このマップ内の要素と同じ数の個別の機能マップにバイアスをかけることができますが、この場合、たたみ込みカーネル自体のパラメーターよりも多くのバイアスパラメーターがあります。 2番目の場合、導関数の計算も簡単です。 large frac partialE partialblij (バイアスには既に下付き文字があります ij )それぞれに等しくなります large frac partialE partialxlij 。
畳み込み層を介してバックプロップ式を導出する
ここでは、すべてが以前の結論に似ています。
\ begin {array} {rcl} \ dfrac {\ partial E} {\ partial y ^ {l-1} _ {ij}}&=&\ sum_ {i '} \ sum_ {j'} \ dfrac {\部分E} {\部分y ^ l_ {i'j '}} \ dfrac {\部分y ^ l_ {i'j'}} {\部分x ^ l_ {i'j '}} \ dfrac {\部分x ^ l_ {i'j '}} {\ partial y ^ {l-1} _ {ij}} \\&=&\ sum_ {i'} \ sum_ {j '} \ dfrac {\ partial E} {\パーシャルy ^ l_ {i'j '}} \ dfrac {\パーシャルy ^ l_ {i'j'}} {\ partial x ^ l_ {i'j '}} \ cdot \ dfrac {\ partial \ left(\ sum_ {a =-\ infty} ^ {+ \ infty} \ sum_ {b =-\ infty} ^ {+ \ infty} w ^ l_ {ab} \ cdot y ^ {l-1} _ {(i's-a )(j's-b)} + b ^ l \ right)} {\ partial y ^ {l-1} _ {ij}} \\&=&\ sum_ {i '} \ sum_ {j'} \ dfrac { \部分E} {\部分y ^ l_ {i'j '}} \ dfrac {\部分y ^ l_ {i'j'}} {\部分x ^ l_ {i'j '}} \ cdot w ^ { l} _ {(i's-i)(j's-j)} \\ && \ forall i、j \次元\エンスペースの行列\エンスペースy ^ {l-1} \ end {array}
分子の量を次のようにレイアウトする a そして b 、すべての偏微分がゼロに等しいことを取得します。ただし、 i′s−a=i そして j′s−b=j 、それに応じて、 a=i′s−i 、 b=j′s−j 。 これは畳み込みにのみ当てはまり、相互相関は i′s+a=i そして j′s+b=j それに応じて a=i−iの そして b=j−jの 。 そして、相互相関の場合の最終的な式は次のようになります。
frac partialE partialyl−1ij= sumi′ sumj′ frac partialE partialyli′j′ frac partialyli′j′ partialxli′j′ cdotwl(i−i′s)(j−j′s)
結果の式は同じ畳み込み演算で、カーネルはおなじみのカーネルです wl 。 しかし、真実、すべてが通常の畳み込みのように見えますが、ストライドが1に等しい場合のみ、別のステップの場合、他のものが既に取得されています(畳み込みカーネルを更新するためのbackpropの場合と同様) wl マトリックス全体で「破壊」し始める large frac partialE partialxl さまざまな部分をキャプチャします(これも、インデックスが i′ そして j′ で wl 数式のループ内で繰り返されます)。
ここで、コードを確認してテストできます。
import numpy as np w_l = np.array([ [1,2], [3,4]]) # stride = 1 dEdx_l = np.zeros((3,3)) # stride = 2 'convolution':False ( - x_l ) # dEdx_l = np.zeros((2,2)) # stride = 2 'convolution':True # dEdx_l = np.zeros((2,2)) y_l_minus_1_shape = (3,3) other_parameters={ 'convolution':True, 'stride':1, 'center_w_l':(0,0) } def convolution_back_dEdy_l_minus_1(dEdx_l, w_l, y_l_minus_1_shape, conv_params): indexes_a, indexes_b = create_indexes(size_axis=w_l.shape, center_w_l=conv_params['center_w_l']) stride = conv_params['stride'] dEdy_l_minus_1 = np.zeros((y_l_minus_1_shape[0], y_l_minus_1_shape[1])) # if conv_params['convolution']: g = 1 # else: g = -1 # for i in range(dEdy_l_minus_1.shape[0]): for j in range(dEdy_l_minus_1.shape[1]): result = 0 # demo = np.zeros([dEdx_l.shape[0], dEdx_l.shape[1]]) for i_x_l in range(dEdx_l.shape[0]): for j_x_l in range(dEdx_l.shape[1]): # "" w_l a = g*i_x_l*stride - g*i b = g*j_x_l*stride - g*j # if a in indexes_a and b in indexes_b: a = indexes_a.index(a) b = indexes_b.index(b) result += dEdx_l[i_x_l][j_x_l] * w_l[a][b] demo[i_x_l][j_x_l] = w_l[a][b] dEdy_l_minus_1[i][j] = result # demo print('i=' + str(i) + '; j=' + str(j) + '\n', demo) return dEdy_l_minus_1 def create_axis_indexes(size_axis, center_w_l): coordinates = [] for i in range(-center_w_l, size_axis-center_w_l): coordinates.append(i) return coordinates def create_indexes(size_axis, center_w_l): # coordinates_a = create_axis_indexes(size_axis=size_axis[0], center_w_l=center_w_l[0]) coordinates_b = create_axis_indexes(size_axis=size_axis[1], center_w_l=center_w_l[1]) return coordinates_a, coordinates_b print(convolution_back_dEdy_l_minus_1(dEdx_l, w_l, y_l_minus_1_shape, other_parameters))

興味深いことに、相互相関を実行する場合、ネットワークを直接通過する段階で、畳み込みコアは反転せず、畳み込み層を介してエラーが逆方向に伝搬するときに反転します。 畳み込み式を適用すると、すべてがまったく逆になります。
この記事では、エラーの逆伝播のすべての式、つまり、将来のモデルが学習できる式を導き出し、詳細に調べました。 次の記事では、これをすべて畳み込みネットワークと呼ばれる単一のコードに結合し、このネットワークをトレーニングして実際のデータセットのクラスを予測します。 また、テンソルフロー機械学習ライブラリと比較して、すべての計算が正しいことを確認します。