 AppleはiOS 10から詳細な学習を使用して顔を特定し始めました。Visionフレームワークのリリースにより、開発者はアプリケーションでこのテクノロジーと他の多くのマシンビジョンアルゴリズムを使用できるようになりました。 フレームワークを開発するとき、ユーザーのプライバシーを維持し、モバイルデバイスのハードウェアで効果的に機能するために、重大な問題を克服する必要がありました。 この記事では、これらの問題について説明し、アルゴリズムの仕組みについて説明します。
AppleはiOS 10から詳細な学習を使用して顔を特定し始めました。Visionフレームワークのリリースにより、開発者はアプリケーションでこのテクノロジーと他の多くのマシンビジョンアルゴリズムを使用できるようになりました。 フレームワークを開発するとき、ユーザーのプライバシーを維持し、モバイルデバイスのハードウェアで効果的に機能するために、重大な問題を克服する必要がありました。 この記事では、これらの問題について説明し、アルゴリズムの仕組みについて説明します。
はじめに
初めて、パブリックAPIの顔の定義がCIDetectorクラスを介してCore Imageフレームワークに登場しました。 これらのAPIは、写真などのApple独自のアプリケーションでも機能しました。 Viola-Jonesアルゴリズムに基づいてメソッドを決定するために使用されたCIDetectorの最初のバージョン[1] 。 CIDetectorの一貫した機能強化は、従来のマシンビジョンの成果に基づいていました。
ディープラーニングの出現とそのマシンビジョンの問題への応用により、顔認識システムの精度は大きく前進しました。 このパラダイムシフトの恩恵を受けるには、アプローチを完全に再考する必要がありました。 従来のマシンビジョンと比較して、ディープラーニングモデルでは、1桁以上のメモリ、ディスクスペース、およびコンピューティングリソースが必要です。
現在、典型的な高性能スマートフォンは、視覚のディープラーニングモデルにとって実行可能なプラットフォームではありません。 ほとんどの業界のプレーヤーは、クラウドAPIを使用してこの制限を回避しています。 そこで、写真は分析のためにサーバーに送信され、そこで深層学習システムが顔を決定する結果を生成します。 クラウドサービスは通常、大量の利用可能なメモリを備えた強力なデスクトップGPUを実行します。 非常に大規模なネットワークモデル、および大規模なモデルのアンサンブル全体がサーバー側で機能し、顧客(携帯電話を含む)がローカルで実行するのが現実的ではない大規模な深層学習アーキテクチャを活用できるようにします。
Apple iCloud Photo Libraryは、写真やビデオを保存するためのクラウドベースのソリューションです。 iCloud Photo Libraryに送信される前の各写真とビデオは、デバイスで暗号化され、対応するiCloudアカウントを持つデバイスでのみ復号化できます。 したがって、ディープラーニングでマシンビジョンシステムを操作するには、iPhoneにアルゴリズムを直接実装する必要がありました。
解決すべきいくつかの問題がありました。 ディープラーニングモデルはオペレーティングシステムの一部として提供される必要があり、貴重なNANDスペースを占有します。 それらはRAMにロードされ、GPUやCPUのかなりのコンピューティングリソースを消費する必要があります。 コンピューティングデバイス上のマシンビジョンタスク専用にリソースを割り当てることができるクラウドサービスとは異なり、システムリソースは実行中の他のアプリケーションと共有されます。 最後に、計算は、かなりの電力消費や加熱なしで、適切な時間で大量の写真の写真を処理するのに十分効率的でなければなりません。
残りの記事では、アルゴリズムを使用してディープラーニングシステムの顔を決定する方法と、決定の最大精度を達成するために困難を克服する方法について説明します。 以下について説明します。
- GPUとCPUを完全に使用した方法(BNNSとMetalを使用);
- ニューラルネットワーク出力、画像の読み込みおよびキャッシュ用にメモリを最適化します。
- iPhoneで同時に実行される他の多くのタスクの作業を妨げないように、ニューラルネットワークを実装する方法。
Viola-Jonesからディープラーニングへの移行
2014年に顔を特定するための深層学習に取り組み始めたとき、深層畳み込みニューラルネットワーク(GNSS)はオブジェクト検出タスクで有望な結果を示し始めました。 最も有名なのはOverFeatモデルでした[2] 、いくつかの簡単なアイデアを示し、GNSSが画像内のオブジェクトの検出に非常に効果的であることを示しました。
OverFeatモデルは、完全に接続されたニューラルネットワーク層と、入力データと同じ空間次元の有効な畳み込みフィルターを備えた畳み込み層との間の対応を推定しました。 この作業により、固定受容野(16ピクセルの自然なピッチの32×32など)を持つバイナリ分類ネットワークが、任意のサイズ(320×320など)の画像に使用できる可能性があり、出力で対応するサイズのマップを生成できることが明らかになりました例20×20)。 OverFeatを説明する科学記事には、より高密度の出力カードを作成し、ニューラルネットワークの間隔を効果的に削減する方法に関する明確なレシピも含まれていました。
最初に、OverFeatに関する記事のいくつかのアイデアに基づいてアーキテクチャを構築しました。その結果、マルチタスクの目標を持つ完全な畳み込みネットワーク(図1を参照)が作成されました。
- 入力内の人物の有無を予測するためのバイナリ分類。
- 入力内の顔を最適にローカライズする境界ボックスのパラメーターを予測する回帰。
このようなニューラルネットワークのさまざまなトレーニングオプションを試しました。 たとえば、単純なトレーニング手順では、最小有効入力データサイズに対応する固定サイズの画像タイルで大きなデータセットを作成し、各タイルがニューラルネットワークの出力で1つの結果を生成するようにしました。 トレーニングデータセットは完全にバランスが取れているため、タイルの半分(ポジティブクラス)に人がおり、残りの半分(ネガティブクラス)には人がいません。 各正のタイルについて、顔の真の座標(x、y、w、h)が示されました。 上記のマルチタスクの目標に最適化するために、ニューラルネットワークをトレーニングしました。 トレーニング後、ニューラルネットワークは画像内の顔の存在を予測することを学び、肯定的な答えの場合、フレーム内の顔の座標とスケールを提供しました。
図 1.顔検出のための高度なGNSSアーキテクチャ
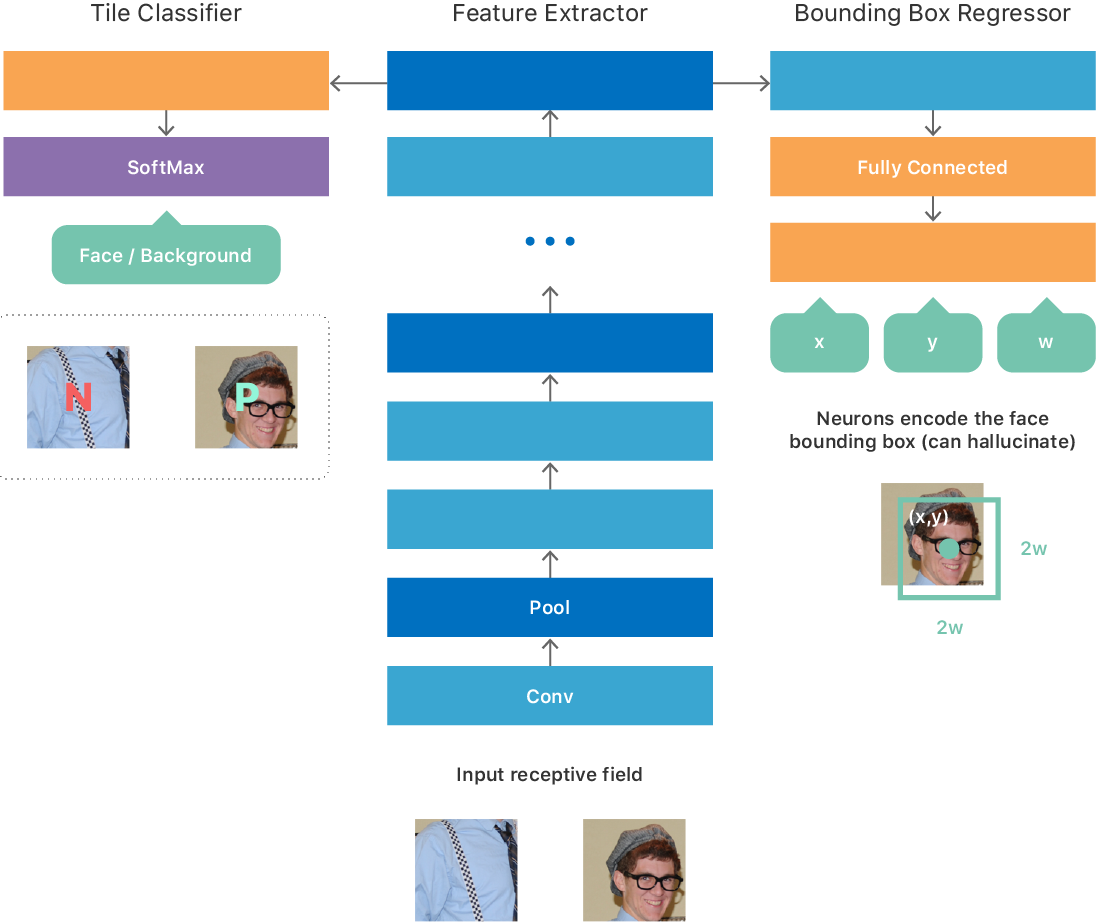
ネットワークは完全に畳み込みであるため、任意のサイズの画像を効率的に処理し、出力2Dマップを作成できます。 マップ上の各ポイントは入力画像タイルに対応し、このタイル上の人物の有無に関するニューラルネットワーク予測と、その位置/縮尺が含まれています(図1のGNSS入力および出力を参照)。
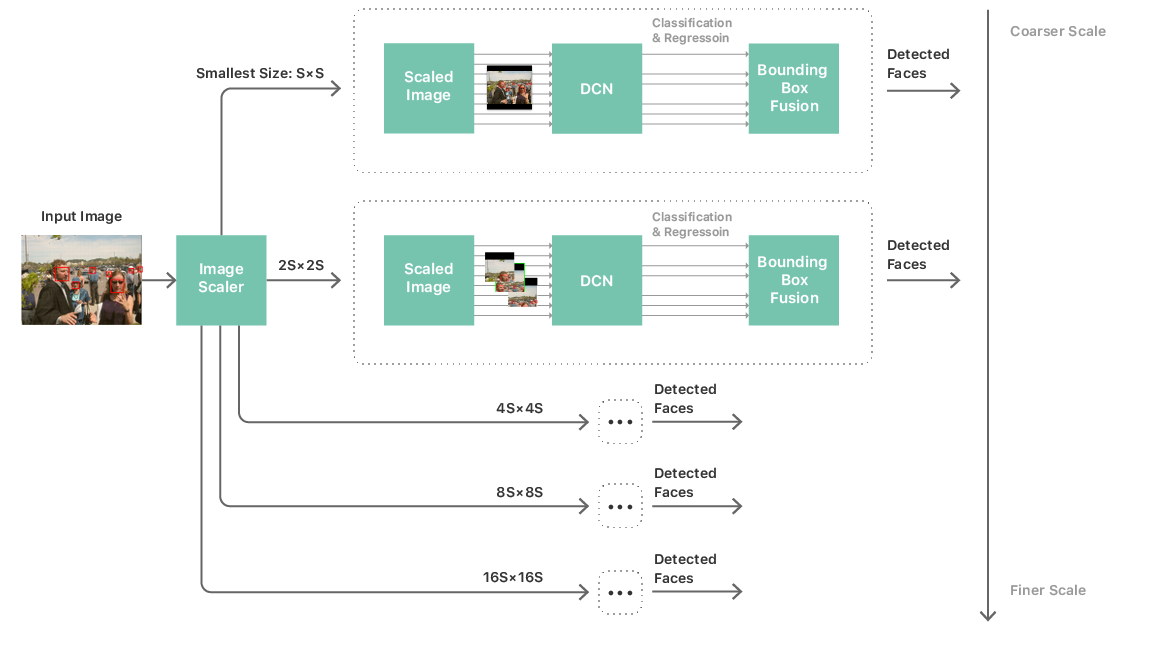
このようなニューラルネットワークを使用すると、顔を識別するためのかなり標準的な処理パイプラインを構築できます。 画像のマルチスケールピラミッド、顔検出ニューラルネットワーク、および後処理モジュールで構成されます。 すべてのサイズの面を処理するには、マルチスケールピラミッドが必要です。 ピラミッドの各レベルでニューラルネットワークが使用され、そこから認識候補が抽出されます(図2を参照)。 後処理モジュールは、すべてのスケールの候補を組み合わせて、画像内の顔によるニューラルネットワークの最終予測に対応する境界ボックスのリストを生成します。
図 2.個人を特定するプロセス
このような戦略により、深い畳み込みニューラルネットワークを起動し、モバイルハードウェアで完全な画像スキャンを行うことがより現実的になりました。 しかし、ニューラルネットワークの複雑さとサイズは、パフォーマンスの主なボトルネックのままでした。 この問題を解決するには、ニューラルネットワークを単純なトポロジに制限するだけでなく、レイヤー数、レイヤーあたりのチャネル数、および畳み込みフィルターカーネルのサイズを制限する必要がありました。 これらの制限は重要な問題を引き起こしました:許容できる精度を提供する私たちのニューラルネットワークは単純なものからはほど遠いです:それらのほとんどには20以上の層といくつかのネットワーク内ネットワークモジュールがあります[3] 。 上記の画像スキャンフレームワークでこのようなネットワークを使用することは、許容できないパフォーマンスと電力消費のために絶対に不可能です。 実際、ニューラルネットワークをメモリにロードすることさえできません。 タスクは、正確ではあるが非常に複雑なネットワークの動作をシミュレートできるシンプルでコンパクトなニューラルネットワークをトレーニングする方法に要約されます。
教師と学生の教育として非公式に知られているアプローチを使用することにしました[4] 。 このアプローチは、前述のように教えた大規模な複雑なニューラルネットワーク(「教師」)の出力に非常によく一致するように、2番目の細くて深いニューラルネットワーク(「生徒」)をトレーニングするメカニズムを提供します。 学生のニューラルネットワークは、3×3コンボリューションとサブサンプルレイヤーの単純な繰り返し構造で構成され、そのアーキテクチャは、ニューラルネットワーク出力エンジンの使用を最大化するように適合されています(図1を参照)。
これで、モバイルハードウェアでの実行に適した深層顔検出ニューラルネットワークアルゴリズムが完成しました。 いくつかのトレーニングサイクルを繰り返し、タスクを実行するのに十分な精度のニューラルネットワークモデルを取得しました。 このモデルは正確であり、モバイルデバイスで作業できますが、実際には何百万ものユーザーデバイスにモデルを展開できるようにするために、膨大な作業が残っています。
画像処理パイプラインの最適化
ディープラーニングに関する実用的な考慮事項は、Visionと呼ばれる使いやすい開発者プラットフォームアーキテクチャの選択に大きな違いをもたらしました。 すぐに、優れたアルゴリズムだけでは優れたフレームワークを作成するには不十分であることが明らかになりました。 画像処理パイプラインを大幅に最適化する必要がありました。
開発者にスケーリング、色変換、または画像ソースについて考えてほしくありませんでした。 カメラからのストリームがリアルタイムで使用されているかどうか、ビデオ処理、ディスクまたはWebからのファイルに関係なく、顔検出はうまく機能するはずです。 画像の種類と形式に関係なく動作するはずです。
特にストリーミングや画像キャプチャ中に、電力とメモリの使用量が心配でした。 64メガピクセルのパノラマを処理する場合を含め、メモリの消費が気になりました。 パーシャルダウンサンプリングデコードと自動タイリングを使用して、これらの問題を解決しました。 これにより、非標準のアスペクト比でも大きな画像でマシンビジョンタスクを実行できました。
別の問題は、色空間のマッチングでした。 AppleにはさまざまなAPIがありますが、色空間を選択する作業を開発者に任せたくありませんでした。 これにより、ビジョンフレームワークが処理されるため、あらゆるアプリケーションでマシンビジョンを正常に実装するためのエントリのしきい値が低くなります。
中間体を効率的に再利用および処理することにより、ビジョンも最適化されます。 顔の検出、顔の座標の決定、およびコンピュータービジョンのその他のタスク-これらはすべて、同じスケーリングされた中間画像で機能します。 インターフェイスをアルゴリズムのレベルに抽象化し、画像またはバッファを処理するための最適な場所を見つけることにより、Visionは中間画像を作成およびキャッシュできます。これにより、開発者の介入なしでもさまざまなコンピュータービジョンタスクのパフォーマンスが向上します。
逆もまた真です。 中央インターフェイスの観点から、中間データの再利用または共有を最適化するような方向でアルゴリズムの開発を指示できます。 Visionは、いくつかの異なる独立したマシンビジョンアルゴリズムを実装しています。 異なるアルゴリズムがうまく連携するために、可能な限り同じ入力解像度と色空間を共有します。
モバイルアイロンのパフォーマンス最適化
顔を検出するためのAPIがリアルタイムまたはバックグラウンドシステムプロセスで動作できない場合、使いやすいフレームワークの喜びはすぐに消えます。 ユーザーは、フォトアルバムの処理中に、またはフレームを撮影した直後に、顔検出が自動的に感知できないように動作することを期待しています。 このためにバッテリーが減少したり、システムの速度が低下したりするのは望ましくありません。 Appleモバイルデバイスはマルチタスクです。 したがって、マシンビジョンのバックグラウンドプロセスが他のシステム機能に大きな影響を与えることはありません。
メモリ使用量とGPU使用量を削減するためのいくつかの戦略を実装しました。 メモリ使用量を削減するために、計算グラフを分析してニューラルネットワークの中間層を割り当てます。 これにより、複数のレイヤーを1つのバッファーに割り当てることができます。 それにもかかわらず、この手法は完全に確定的であるため、メモリのパフォーマンスや断片化に影響を与えることなくメモリ消費を削減し、CPUとGPUの両方に使用できます。
ビジョン検出器は5つのニューラルネットワーク(図2に示すように、マルチスケールピラミッドの各レベルに1つ)で動作します。 これらの5つのニューラルネットワークの合計重みとパラメーターが示されていますが、入力データと出力データの形式および中間層が異なります。 メモリ消費をさらに削減するために、これら5つのネットワークで構成される共同グラフでメモリ最適化アルゴリズムを実行し、メモリ消費を大幅に削減します。 また、すべてのニューラルネットワークは、重みとパラメーターを備えた同じバッファーを一緒に使用して、割り当てられたメモリの量を減らします。
パフォーマンスを向上させるために、ニューラルネットワークの完全な畳み込みの性質を使用します。すべてのスケールは、入力画像の解像度に合わせて動的に変更されます。 代替アプローチ(画像をニューラルネットワークの正方形グリッド(空のバーでレイアウト)に合わせる)と比較して、ニューラルネットワークを画像のサイズに合わせると、操作の総数を劇的に減らすことができます。 このような再配置の結果として、操作のトポロジは変更されないため、ディストリビューターの残りの部分のパフォーマンスが高いため、動的な形状変更は割り当てより多くのリソースを消費しません。
バックグラウンドプロセスでのディープニューラルネットワークの操作中のUIブレーキングの対話性と不在を保証するために、ニューラルネットワークの各レイヤーのGPUの作業タスクを分割して、各タスクが1ミリ秒以内に完了するようにしました。 これにより、ドライバーはコンテキストを変更し、UIアニメーションなどの優先度の高いタスクにリソースを割り当てて、フレームを削減し、場合によっては完全に削除できます。
同時に、これらの戦略により、ユーザーはローカルマシンビジョンを低遅延でプライベートモードで楽しむことができますが、スマートフォンのニューラルネットワークが毎秒数千億の浮動小数点演算を実行することさえ知りません。
ビジョンフレームワークの使用
目標を達成し、顔を識別するための高性能で使いやすいAPIを開発できましたか? Visionフレームワークを試して、自分で決めることができます。 開始するためのリソースは次のとおりです。
- WWDCによるプレゼンテーション:「 ビジョンフレームワーク:コアML開発 」
- Vision Frameworkヘルプ
- ガイド「コアMLとビジョン:iOS 11の機械学習」 [5]
文学
[1] Viola、P.、Jones、MJ 単純な特徴のブーストされたカスケードを使用したロバストなリアルタイムオブジェクト検出 。 Proceedings of the Computer Vision and Pattern Recognition Conference 、2001に掲載されています。 ↑
[2] Sermanet、Pierre、David Eigen、Xiang Zhang、Michael Mathieu、Rob Fergus、Yann LeCun。 OverFeat:畳み込みネットワークを使用した統合認識、ローカリゼーションおよび検出 。 arXiv:1312.6229 [Cs]、2013年12月。 ↑
[3] Lin、Min、Qiang Chen、Shuicheng Yan。 ネットワークネットワーク 。 arXiv:1312.4400 [Cs]、2013年12月。 ↑
[4]ロメロ、アドリアーナ、ニコラス・バラス、サミラ・エブラヒミ・カホウ、アントワーヌ・チャサン、カルロ・ガッタ、ヨシュア・ベンジオ。 FitNets:シンディープネットのヒント arXiv:1412.6550 [Cs]、2014年12月。 ↑
[5] Tam、 A。Core MLおよびVision:iOSチュートリアルの機械学習 。 2017年9月にwww.raywenderlich.comから取得。 ↑