機械学習とニューラルネットワークは、多くの企業にとってますます不可欠になっています。 彼らが直面する主な問題の1つは、この種のアプリケーションの展開です。 このような展開の実用的で便利な方法を示したいのですが、クラウドテクノロジーとクラスターの専門家である必要はありません。 このために、サーバーレスインフラストラクチャを使用します。
はじめに
最近、機械学習またはニューラルネットワークによって作成されたモデルを使用して、製品の多くのタスクが解決されました。 多くの場合、これらは長年にわたって従来の決定論的手法によって解決されてきたタスクであり、MLを介して解決するのがより簡単で安価になりました。
KerasやTensorflowなどの最新のフレームワークと既製のソリューションのカタログを使用すると、製品に必要な精度を提供するモデルを簡単に作成できます。
私の同僚はこれを「機械学習のコモディティ化」と呼び、いくつかの点で正しいです。 最も重要なことは、今日ではモデルの検索/ダウンロード/トレーニングが容易であり、モデルを簡単に展開できるようにすることです。
繰り返しになりますが、スタートアップや小さな会社で働いているときは、技術的なだけでなく市場の前提も含めて、すぐに仮定を確認する必要があります。 そのためには、モデルを迅速かつ簡単に展開する必要があります。これは、強力ではなく、依然としてトラフィックを想定しています。
この展開の問題を解決するために、クラウドマイクロサービスを使用することが好きでした。
Amazon、Google、Microsoftは最近、サービスとして機能するFaaSを提供しました。 それらは比較的安価で、簡単にデプロイできます(Dockerは必要ありません)。また、無制限の数のエンティティを並行して実行できます。
次に、TensorFlow / KerasモデルをAmazonのAWS Lambda-FaaSにデプロイする方法を説明します。 その結果、20,000件の認識に対して1ドル相当の画像上のコンテンツを認識するAPI。 もっと安くできますか? おそらく。 それは簡単ですか? ほとんどない。
サービスとしての機能
さまざまなタイプのデプロイアプリケーションの図を検討してください。
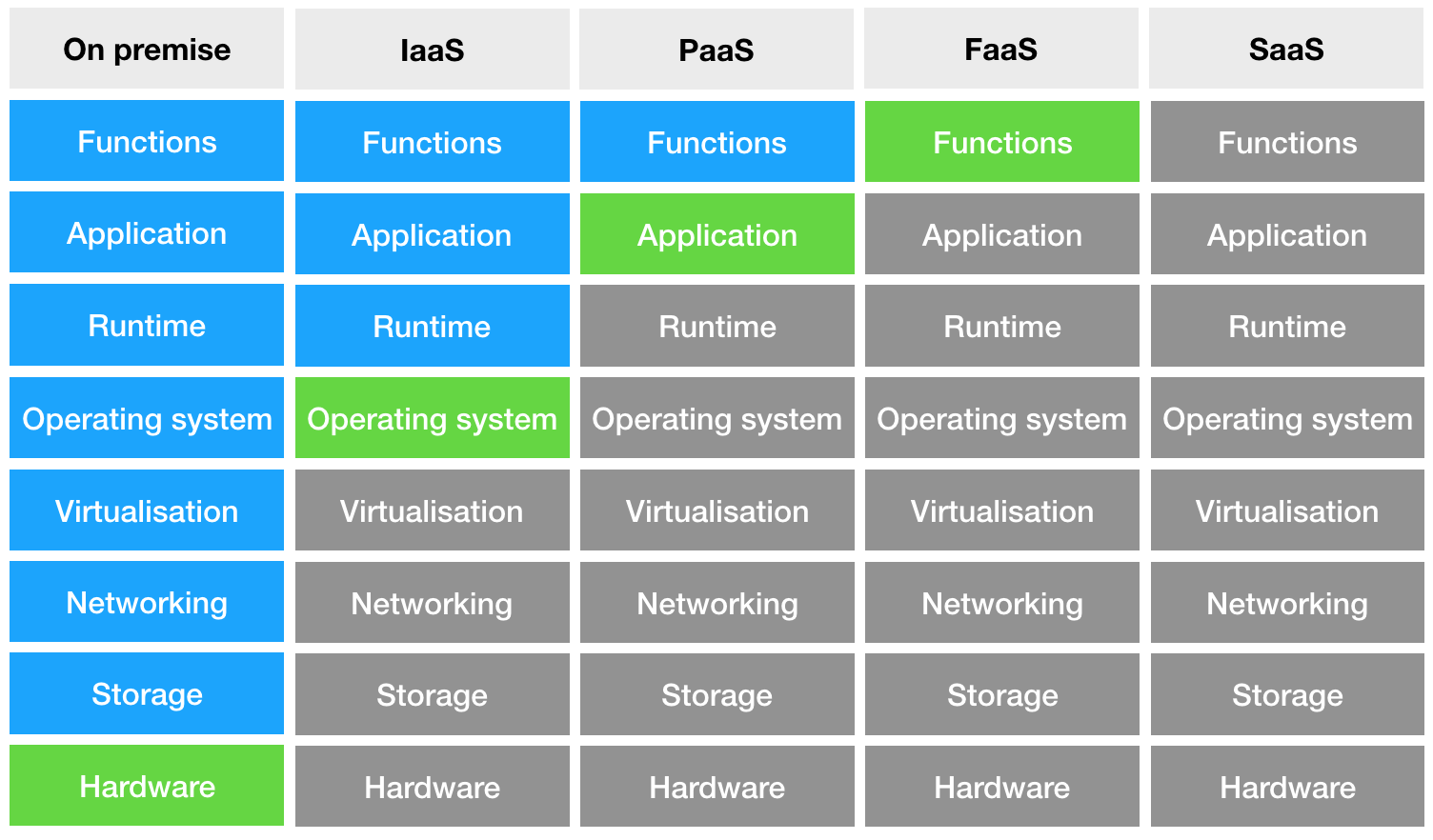
左側にあるのはオンプレミス-サーバーを所有しているときです。 次に、Infrastructure-as-a-Serviceが表示されます-ここでは、既に仮想マシンで作業しています-データセンターにあるサーバーです。 次のステップはPlatform-as-a-Serviceで、マシン自体にはアクセスできなくなりますが、アプリケーションが実行されるコンテナを管理します。 そして最後に、コードのみを制御し、他のすべてが私たちから隠されている場合の、Function-as-a-Service。 これは良いニュースです。後で見るように、とてもクールな機能を提供します。
AWS Lambdaは、AWSプラットフォームでのFAASの実装です。 実装について簡単に説明します。 コンテナはzipアーカイブ[コード+ライブラリ]です。 コードはローカルマシンのものと同じです。 AWSは、外部リクエスト(トリガー)の数に応じて、このコードをコンテナーにデプロイします。 上部には本質的に境界線はありません。現在の制限は同時に動作する1000コンテナですが、サポートを通じて簡単に最大10000以上に引き上げることができます。
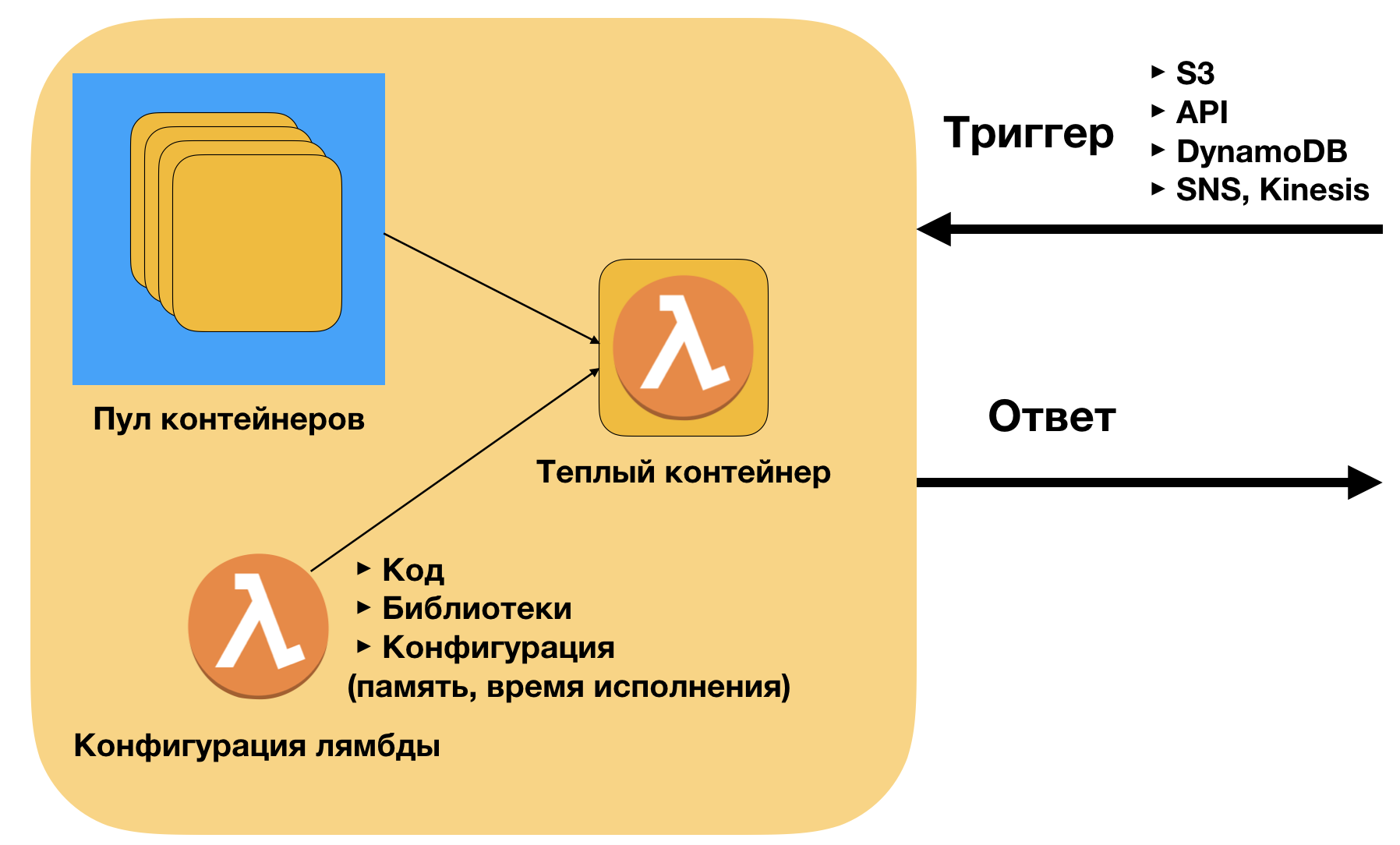
AWS Lambdaの主な利点:
- 簡単にデプロイ(ドッカーなし)-コードとライブラリのみ
- トリガー(API、S3、SNS、DynamoDB)への接続が簡単
- 優れたスケーリング-本番環境では、40,000を超える呼び出しを同時に起動しました。 それは可能です。
- 低い通話コスト。 BDの同僚にとって、マイクロサービスがサービスを使用するための従量課金モデルをサポートすることも重要です。 これにより、スケーリング時にモデルを使用するユニットの経済性が明確になります。
ニューラルネットワークをサーバーレスに移植する理由
まず、私の例では、開発者が機械学習モデルを作成、トレーニング、展開できるオープンフレームワークであるTensorflowを使用していることを明確にします。 現時点では、これはディープラーニングで最も人気のあるライブラリであり、専門家と初心者の両方が使用しています。
現時点では、機械学習モデルを展開する主な方法はクラスターです。 深層学習用のREST APIを作成する場合、次のようになります。
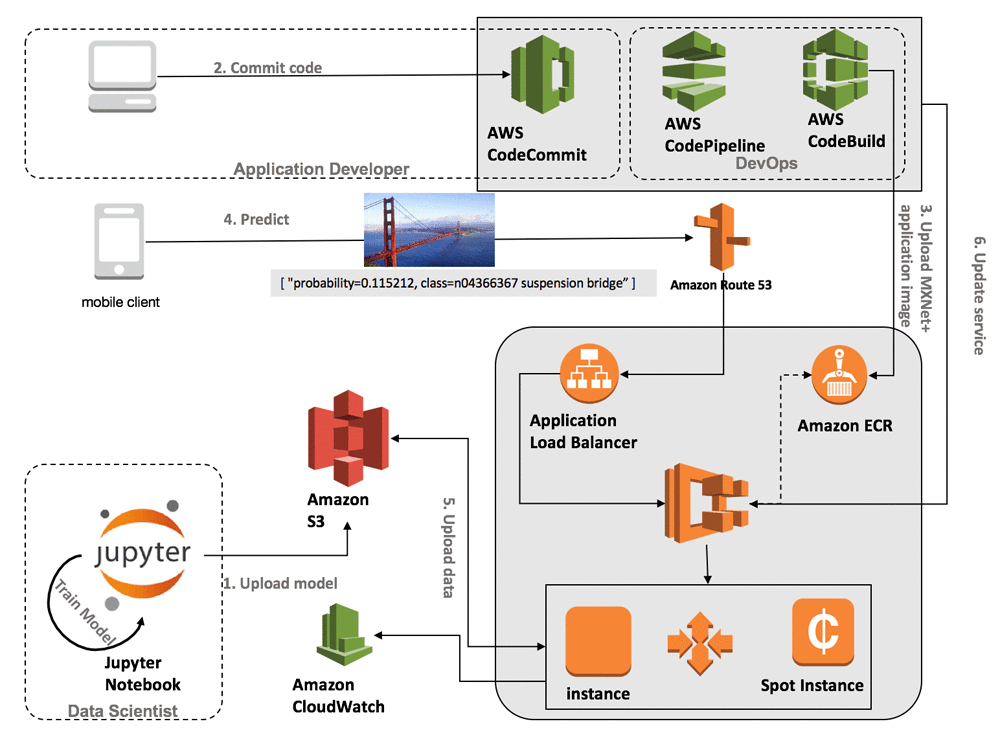
( AWSブログからの画像 )
かさばってる? 同時に、次のことに注意する必要があります。
- トラフィック分散のロジックをクラスターマシンに登録する
- ダウンタイムとブレーキの中間点を見つけようとするスケーリングのロジックを規定する
- コンテナの動作のロジックを規定します-ロギング、着信リクエストの管理
AWS Lambdaでは、アーキテクチャは著しく単純になります。
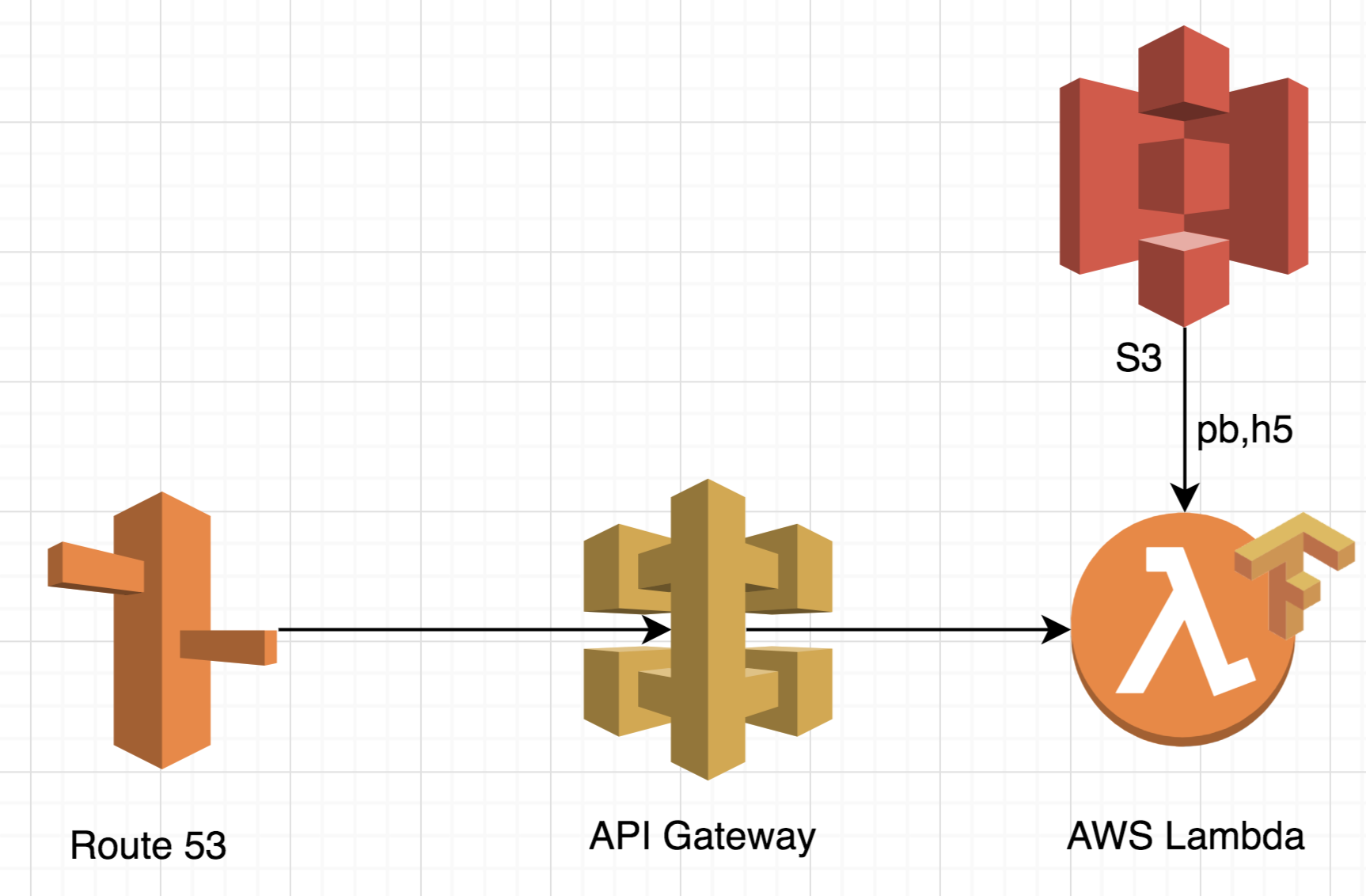
まず、このアプローチは非常にスケーラブルです。 追加のロジックを規定することなく、最大1万件の同時リクエストを処理できます。 この機能により、追加の処理時間が必要ないため、アーキテクチャはピーク負荷処理に最適です。
第二に、単純なサーバーに料金を支払う必要はありません。 サーバーレスアーキテクチャでは、支払いは1つのリクエストに対して行われます。 これは、25,000件のリクエストがある場合、それらがどのフローから来たかに関係なく、25,000件のリクエストに対してのみ支払うことを意味します。 したがって、コストがより透明になるだけでなく、コスト自体も非常に低くなります。 たとえば、後で説明するTensorflowでは、コストは1ドルで20〜25,000リクエストです。 同様の機能を備えたクラスターははるかにコストがかかり、非常に多くのリクエスト(> 100万)に対してのみより収益性が高くなります。
第三に、インフラストラクチャがはるかに大きくなっています。 Dockerを使用する必要はありません。スケーリングと負荷分散のロジックを規定します。 要するに、会社はインフラストラクチャをサポートするために追加の人を雇う必要がなく、あなたがデータセンターであるなら、あなたはそれを自分で行うことができます。
以下に示すように、上記のアプリケーションのインフラストラクチャ全体を展開するには、わずか4行のコードが必要です。
サーバーレスインフラストラクチャの短所や、機能しないケースについて言わないのは正しくありません。 AWS Lambdaには、処理時間と使用可能なメモリに厳しい制限があるため、注意する必要があります。
まず、前述したように、クラスターは特定の数の要求の後に収益性が高くなります。 ピーク負荷と多くのリクエストがない場合、クラスターはより収益性が高くなります。
第二に、AWS Lambdaの開始時間はわずかですが明確です(100〜200ミリ秒)。 ディープラーニングアプリケーションでは、S3からモデルをダウンロードするのにさらに時間が必要です。 以下に示す例では、コールドスタートは4.5秒、ウォームスタートは3秒です。 一部のアプリケーションではこれは重要ではないかもしれませんが、アプリケーションが単一の要求をできるだけ早く処理することに焦点を合わせている場合、クラスターがより良いオプションになります。
アプリ
それでは、実際の部分に移りましょう。
この例では、ニューラルネットワークのかなり一般的なアプリケーションである画像認識を使用します。 私たちのアプリケーションは入力画像を受け取り、その上のオブジェクトの説明を返します。 これらの種類のアプリケーションは、画像をフィルタリングし、複数の画像をグループに分類するために広く使用されています。 私たちのアプリケーションは、パンダの写真を認識しようとします。

次のスタックを使用します。
- リクエスト管理用のゲートウェイAPI
- 処理のためのAWS Lambda
- サーバーレス展開フレームワーク
「Hello world」コード
開始するには、サーバーレスフレームワークをインストールして構成する必要があります。サーバーレスフレームワークは、アプリケーションのオーケストレーションとデプロイに使用します。 ガイドへのリンク 。
空のフォルダーを作成し、次のコマンドを実行します。
serverless install -u https://github.com/ryfeus/lambda-packs/tree/master/tensorflow/source -n tensorflow cd tensorflow serverless deploy serverless invoke --function main --log
次の応答が返されます。
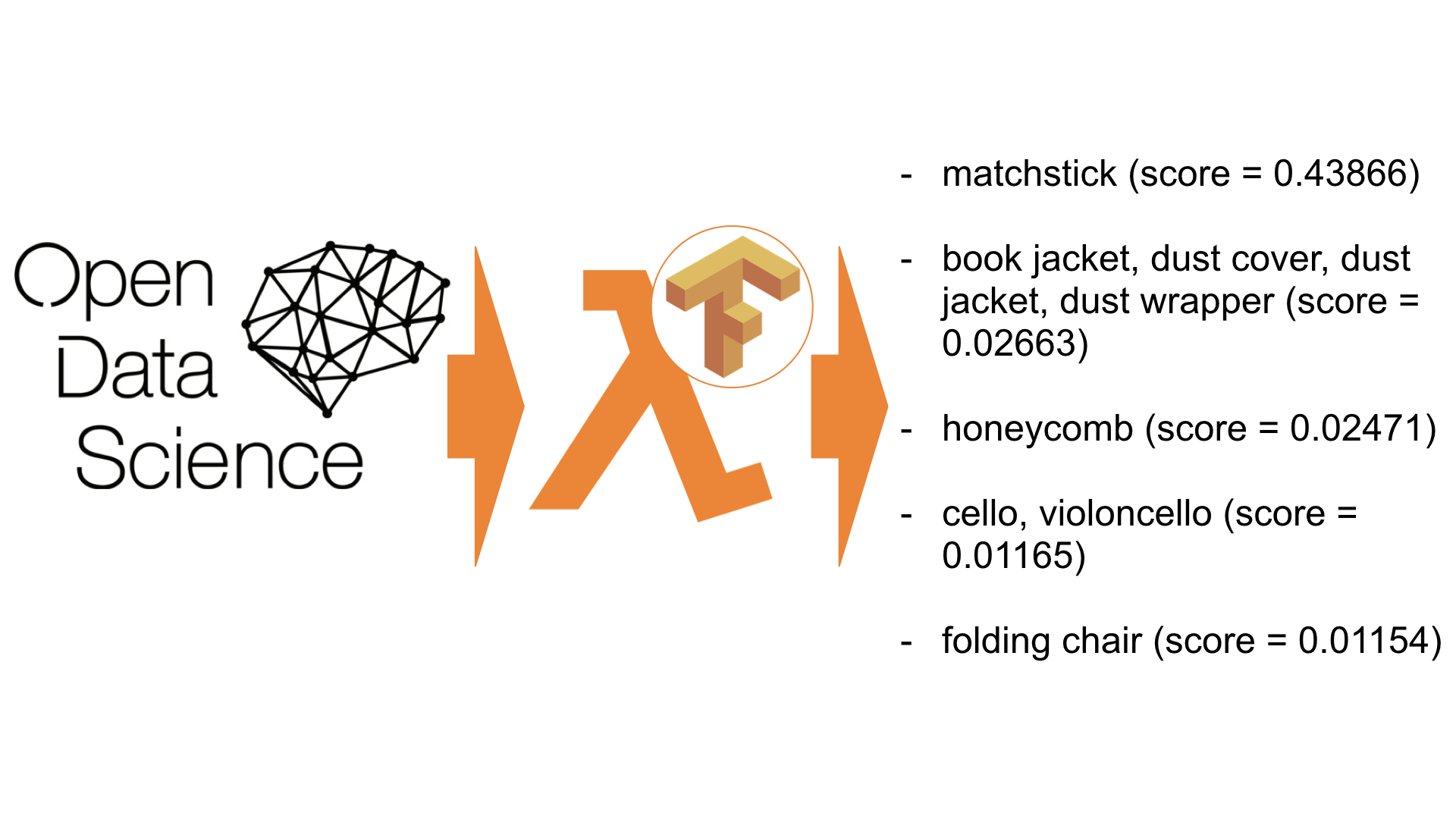
/tmp/imagenet/imagenet_synset_to_human_label_map.txt /tmp/imagenet/imagenet_2012_challenge_label_map_proto.pbtxt /tmp/imagenet/classify_image_graph_def.pb /tmp/imagenet/inputimage.jpg giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107) indri, indris, Indri indri, Indri brevicaudatus (score = 0.00779) lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00296) custard apple (score = 0.00147) earthstar (score = 0.00117)
ご覧のとおり、私たちのアプリケーションはパンダ(0.89)のある写真を正常に認識しました。
出来上がり。 AWS LambdaのTensorflowで画像認識用のニューラルネットワークを正常にデプロイしました。
コードをさらに詳しく考えてみましょう。
構成ファイルから始めましょう。 すぐに使用できるものはありません-AWS Lambdaの基本設定を使用します。
service: tensorflow frameworkVersion: ">=1.2.0 <2.0.0" provider: name: aws runtime: python2.7 memorySize: 1536 timeout: 300 functions: main: handler: index.handler
ファイル 'index.py'自体を見ると、最初にモデル( '.pb'ファイル)をAWS Lambdaのフォルダー '/ tmp /'にダウンロードし、Tensorflowを介して標準的な方法でインポートすることがわかります。
以下は、独自のモデルを挿入する場合に留意すべきGithubのコードへのリンクです。
strBucket = 'ryfeuslambda' strKey = 'tensorflow/imagenet/classify_image_graph_def.pb' strFile = '/tmp/imagenet/classify_image_graph_def.pb' downloadFromS3(strBucket,strKey,strFile) print(strFile)
インポートモデル :
def create_graph(): with tf.gfile.FastGFile(os.path.join('/tmp/imagenet/', 'classify_image_graph_def.pb'), 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def, name='')
画像ダウンロード :
strFile = '/tmp/imagenet/inputimage.jpg' if ('imagelink' in event): urllib.urlretrieve(event['imagelink'], strFile) else: strBucket = 'ryfeuslambda' strKey = 'tensorflow/imagenet/cropped_panda.jpg' downloadFromS3(strBucket,strKey,strFile) print(strFile)
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0') predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data}) predictions = np.squeeze(predictions)
ここで、ラムダにAPIを追加しましょう。
APIの例
APIを追加する最も簡単な方法は、構成YAMLファイルを変更することです。
service: tensorflow frameworkVersion: ">=1.2.0 <2.0.0" provider: name: aws runtime: python2.7 memorySize: 1536 timeout: 300 functions: main: handler: index.handler events: - http: GET handler
次に、再スタックしましょう:
serverless deploy
以下が得られます。
Service Information service: tensorflow stage: dev region: us-east-1 stack: tensorflow-dev api keys: None endpoints: GET - https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler functions: main: tensorflow-dev-main
APIをテストするには、リンクとして単に開くことができます。
https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler
または、curlを使用します。
curl https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler
取得します:
{"return": "giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107)"}
おわりに
サーバーレスフレームワークを使用して、AWS LambdaベースのTensorflowモデル用のAPIを作成しました。 すべてが非常に簡単に実行できるように管理され、このアプローチは従来のアプローチと比較して多くの時間を節約しました。
構成ファイルを変更することにより、ストリーミング処理タスク用のSQSなど、他の多くのAWSサービスに接続したり、AWS Lexを使用してチャットボットを作成したりできます。
私の趣味として、サーバーレスをより使いやすくするために多くのライブラリを移植しています。 ここで見つけることができます 。 MITプロジェクトにはライセンスがあるため、安全に変更してタスクに使用できます。
ライブラリには次の例が含まれます。
- 機械学習(Scikit、LightGBM)
- コンピュータービジョン(Skimage、OpenCV、PIL)
- テキスト認識(Tesseract)
- テキスト分析(Spacy)
- Webスクレイピング(Selenium、PhantomJS、lxml)
- APIテスト(WRK、pyrestest)
他の人がプロジェクトでサーバーレスをどのように使用しているかを見るのは非常にうれしいです。 コメントのフィードバックと開発の成功を必ずお知らせください。