
当社の顧客は数千の企業のリストを保持しており、通常は手付かずの混乱があります。
農業生産者が全国で商品を販売する店舗のリストを取ります。 店舗名は必要に応じて書き込まれるため、一般的なリストは次のようになります。
- ユーラシア
- 「さくら」日本料理。
- 支配的
- ショップブティック「ユーラシア」。
- Milenium、LLC、食料品店。
- キウイ/ LLC /チェリャビンスク。
- エコ製品のスーパーマーケット「支配的」。
ポイント番号1と4-重複、番号3と7-も、しかしそれを把握してください。
しかし、あなたはそれを理解する必要があります:1000のアウトレットのリストに300のテイクがあるとき、メーカーは問題を抱え始めます。
- 販売計画が失敗しています。 1000店舗で販売していると思いますが、実際には300店舗が2倍です。
- 営業担当者は明確ではありません。 貿易担当者は、ポイントを運転し、棚を掃除し、商品を再注文する必要があります。 データベースに重複がある場合、スタッフは理解できないルートを受け取り、アイドル状態で作業します。
最初の反応は、生きているオペレーターの手をきれいにすることです。 無駄です。 時々、名前が非常にエキゾチックに書かれているので、人々はまだ間違っています。 はい、それは高価です。
既製のソリューションを列挙することで問題を取り上げました。
完成したツールが合わない
古き良きExcelは明らかに、
個人の重複の「ダダトフスキー」 検索も適合しませんでした。 彼は人々を名前、住所、電話のような追加フィールドで比較します。 しかし、氏名を比較するアルゴリズムは氏名には適さず、1つの住所だけで重複を見つけることはできません。多数のブティック部門があるショッピングセンターでは、すべての統計情報が破壊されます。
まだチャンスがありました:Faktorエンタープライズエンジンがあり、名前を登録簿の形式(法人の状態レジストリ)にもたらします。 しかし、彼はどちらも助けませんでした:ポイントの名前はしばしば法人の名前とは何の関係もありません。 Vector + LLCがUyutという名前の場合、Uyutが報告されます。 登録は役に立ちません。
その結果、個人による重複の検索を行い、最終決定しました。 彼は住所を比較しました。名前を比較する方法を教えなければなりませんでした。
名前の意味の基礎を見つける
企業の名前を比較するには、最初にそれらを殻から剥がす必要があります-意味の基礎を見つけるために。 これは正規表現で行います。
句読点をきれいに:
- コンマの後にスペースを追加します。
- 取り消し線をスペースに変更します。
- 名前から文字、数字、スペースを除くすべてを削除します。
典型的なパターンに該当するものはすべて削除します。 アナリストは、アウトレットレポートで10,000件のレコードを調べました。 最後に、彼は名前を散らかすパターンのデータベースを作りました。 Dadataの削除:
- コンセントの種類 :「製品。 ショップ」、「ミニマーケット」、「スーパーマーケット」、「デパート」、「エコストア」、「店舗チェーン」など。
- 括弧内およびその後のすべて :「社会薬局6(104、バタイスク)」→「社会薬局6」。
- 「Bashmedservice / LLC / Chelyabinsk」→「Bashmedservice」 という3つの単語がスラッシュで記述されている場合、最初の単語を除くすべて 。 おそらく、この形式では、問題は非常に一般的であるため、会計システムまたはレジストリから名前がダウンロードされます。
- 最初から都市 :「KRYMSK、LLC * BEREZKA *」→「LLC * BEREZKA *」。
- テールアドレス :「ノルマンデックスM LLC、ムルマンスク州アパティティ市」→「ノルデックスM LLC」。
- OPFの後のテール :「契約LLCのステータスNO」→「LLCのステータス」。
必要に応じて、アルゴリズムをバイパスするのは簡単です。パターンはほとんどありません。 しかし、重複の問題は、悪意ではなく標準の欠如が原因で発生します。 実際には、上記で十分です。
OPFを削除します。ZAO、OJSC、PAO、およびタイプ「open。」の復号化。 acc。 合計。
その結果、Dadataが比較する会社名のセマンティックパーツのみが残ります。
セマンティックの基盤とアドレスを比較する
名前の一致自体は非常に弱い基準です。 したがって、「Dadatu」は通常、住所、および場合によっては電話もダウンロードします。
このサービスは、名前のセマンティック基盤を見つけ、アドレスを標準化します。 そして、重複排除自体が始まります。Dadataは入力ファイルからエントリをヒープに収集し、それぞれを比較します。
アルゴリズムはシナリオに従ってペアをチェックします。合計で10個あります。 例:
| スクリプト | 二重確率 |
|---|---|
| 名前が一致し、他のフィールドは空です | 100% |
| 名前は似ていますが、アドレスは一致します | 95% |
| 名前は一致し、住所は家番号の拡張子(文字、文字など)で区別されます | 95% |
| 名前は似ていますが、電話は同じです | 70% |
- 幹が数字で終わり、数字が異なる場合、Dadataは名前が異なると見なします。 それ以外の場合、フィルターには、たとえば、「Social pharmacy Doctor Zhivago 12」および「Social pharmacy Doctor Zhivago 13」が含まれます。
- マッチアドレスは、マッチ名よりも重みがあります。 名前が60%に一致し、アドレスが100%に一致する場合、重複の可能性は95%です。
- レコードのペアに適したシナリオの中で、Dadataは類似性の割合が最も高いシナリオを選択します。
サービスが重複の可能性を見つけると、判定を下します。
- > 85%の類似性-保証されたテイク。 レコードを自動的に1つにマージできます。
- <85%-おそらく2倍。 システムは、ラベル「類似」とIDでエントリをマークします。 結果ファイルのIDにより、ユーザーは類似したレコードのグループを選択します。
- スクリプトが表示されない場合、エントリは異なります。
このアルゴリズムでは、すべての重複が100%として検出されるわけではありません。 オペレーターが手でそれらを分解できるように、彼は単に同様のポイントをマークします。 改善の余地がありますが、まだ完了しています。
ロボットを機能させる
その間、 重複検索の価格を 10倍に引き下げました 。 現在、Dadataは、処理されたレコードごとに1つのコペックだけで同じ人と会社を探しています。
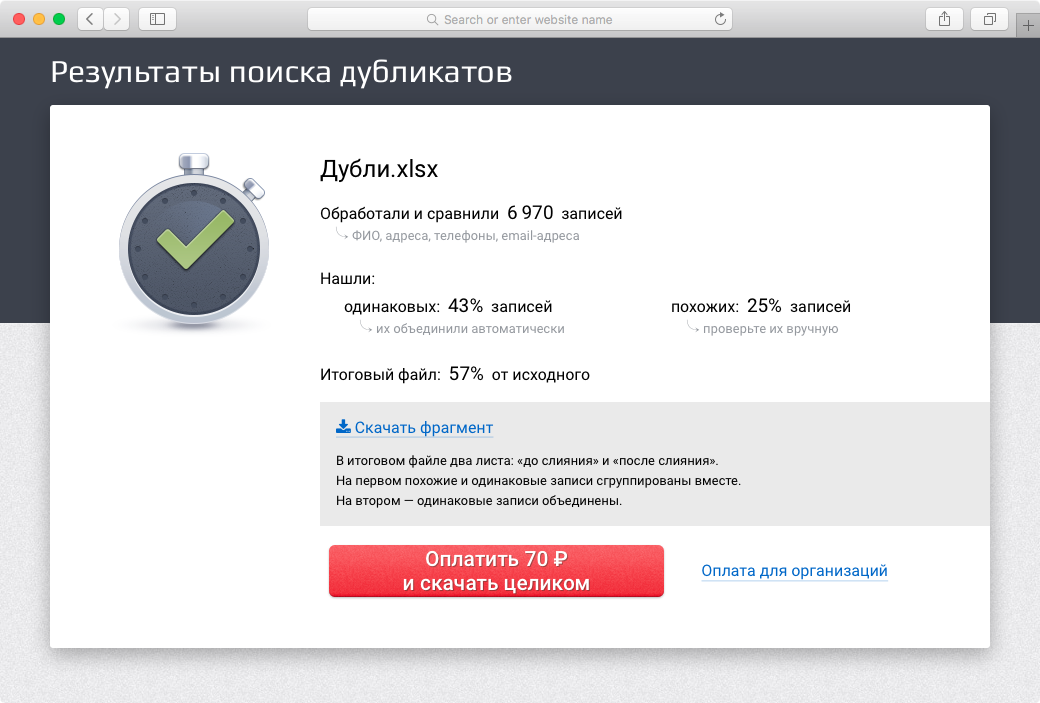
Dadataは最初にファイルを受け入れ、テイクの数を表示してから、支払いたいかどうかを尋ねます。
登録 、ファイルのアップロード-アウトレット、請負業者、顧客、誰でも重複リストを消去できます。