この記事では、基本について話し、プロセスのすべての俳優を知り、楽しんで、お気に入りのミームを思い出し、その間に必要な知識の図を形成します。
だから:
- OpenCVライブラリ。
- 認識原則。
- コンピュータビジョンの歴史。
+これらすべてがどのように接続されているかを示すケース分解。
一つの重要な事実
科学的専門分野としてのコンピュータービジョンは、かなり前の1950年代に登場しました。 その後、OpenCVの問題はありませんでした。その公式リリースは2000年にのみ行われました。
1950年代には、統計的特徴を認識するための2次元アルゴリズムが開発され、最も単純なアルゴリズムが使用されました。

その後、1980年代にJ.ギブソンの理論に基づいて、ピクセルベースで光束を計算する数学モデルが開発されました。
だから、一歩一歩、人々はオブジェクトをよりよく認識する機会を見つけました。 ある時点で、彼らは写真の中の文字を認識することを学び、それからこの操作とコンピューターを教えました。
OpenCVを使用して、遠い1つの遠くの銀河で、すべてがずっと前に始まりました。
一言で言えば、OpenCVは、

ライブラリはさまざまなプラットフォームに適応しているため、モバイルデバイスからArduinoロボットまで、あらゆる場所で使用されています。 OpenCVはZarathustraのメモと同じくらい古いですが、それでも新しいプロジェクトの発展と刺激を与え続けています。 深く掘り下げないために、 こちらに連絡することをお勧めします。
人々はコンピューターを訓練してオブジェクトを認識します。これが機械学習です。 その後、ディープラーニングにスムーズに流れ込みました。これは、「数層の通信を備えたニューラルネットワーク」のような、機械学習の優れたブランド変更です。 現代世界の深層学習の巨人の1人はGoogleです。
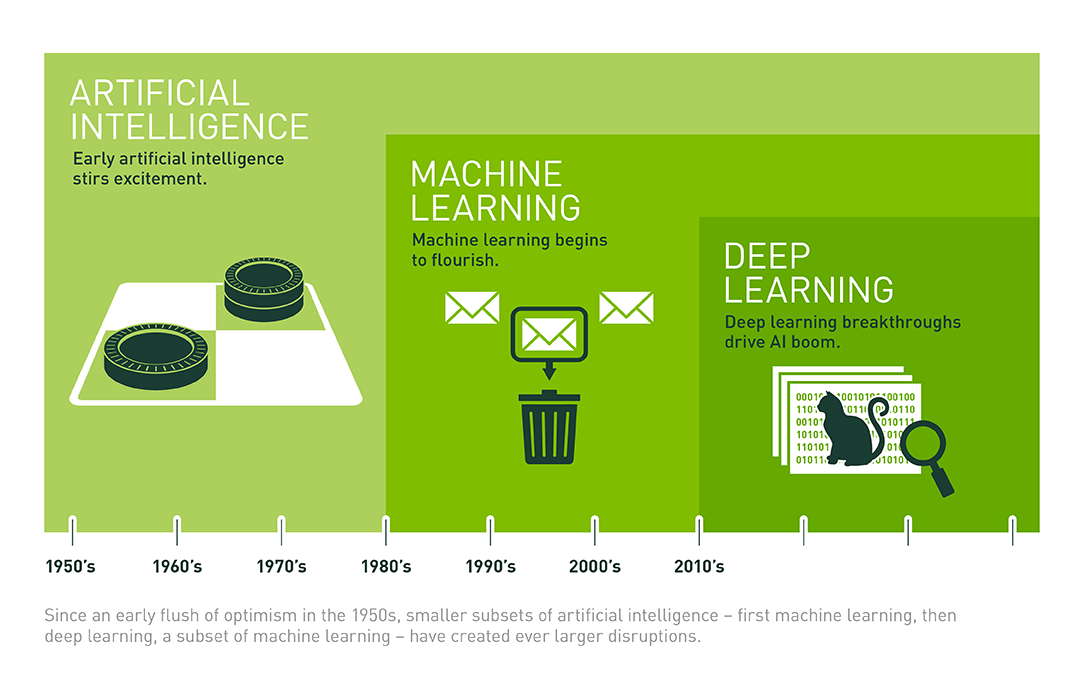
写真でわかるように、それはすべて人工知能で始まり、その後機械学習に移り、ディープラーニングで終わりました。
ニューラルネットワークについて一言
ニューラルネットワークは、機械学習の開発における次のマイルストーンであり、新しいレベルに達します。 「40YearOldVirgin」というニックネームを持つ私のルームメイトは数学のすべての面と面を完全に理解しているという事実にもかかわらず、私たちは開発アプローチの最高の伝統に物事を残します。
つまり、シンプルで愚かなことです。
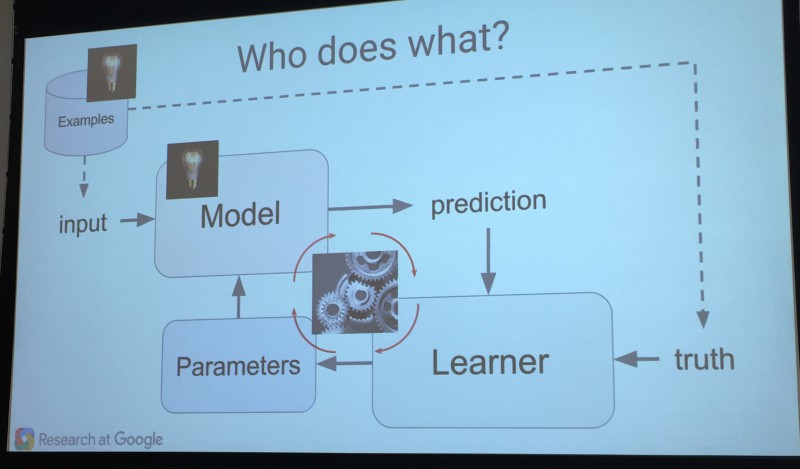
写真を見てください、それはニューラルネットワークとデバイスの構成を説明しています。
入力には例があり、その有効性はネットワークによって評価され、既存の経験と蓄積されたデータに基づいています。
予測の基本原則:サンプルが大きいほど、データの正確性は高くなります。新しい意味を持ちます...トレーニングが長ければ長いほど、予測の正確性は高まります。 ハードコアファンはブログを読むことをお勧めします。
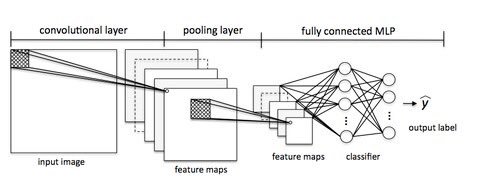
この図は、ニューラルネットワークのさまざまな層にある一連のアクションを示しています。
それで、塩は何ですか? -読者は尋ねます
しかし、ディープラーニングの登場により、すべてが巨大な山のように混ざり合い、境界が非常に曖昧になり、誰もその仕組みを理解できなくなりました。

したがって、要約します。
- OpenCVはオブジェクトを認識します。
- これらのオブジェクトはニューロンに供給されます。
- レイヤーのコンプライアンスを分析し、結果を出力します。
- ニューラルネットワーク自体は、得られた経験から学習します。
もちろん、この場合、サードパーティのML(機械学習)なしで学習できますが、それはより困難です。 私たち、またはむしろiOS開発者は、HAARカスケードを使用しました。 これがどのように機能するかの素晴らしい例。
ケースに対処しましょう
道路標識の「制限速度」を認識するために、unningなアルゴリズムを使用する必要があります。
怠zyな人々のためのチュートリアル。 実装の詳細には立ち入らず、問題の単純な分解を実行して、すべてを見通します。
オブジェクト認識:
- OpenCVとやり取りするオブジェクトを作成してみましょう。具体的には、CVPixelBufferRefをcv :: Matに変換して操作し、その名前をCV Managerとしましょう。
- GPUImageライブラリを使用して、独自のフィルターを作成し、指定された間隔で(プロセッサーを完全にロードしないように)ビデオストリームからCVPixelBufferRefフレームを取得し、それをCVマネージャーに渡します。
- フレーム内のオブジェクトを認識するために、 HAARcascadesを使用します 。
- 出力では、長方形の配列を取得します。
オブジェクトを理解する :
そのような場合を調べてみましょう。
- 「制限速度」の道路標識を認識するには、システムを自分でトレーニングするか、すでに認識用にトレーニングされているシステムを見つけることができます。
- たとえば、顔を認識するために、FindFaceなどのサービスが使用されます。 APIの前のステップの長方形を指定して、フェイスIDを取得できます。
どちらの状況でも、認識のためにニューラルネットワークを使用します。これは、経験に基づいて結果を提供できます。 たとえば、道路リミッターを備えた「ニューロン」には、標識のさまざまなオプションがありました。速度制限があり、私たちの場合には不適切です(数字やレンガの標識はまったくありません)。
ネットワークにリクエストを頻繁に送信しないために、前のフレームからあまりシフトしていない5つのフレームに長方形がある場合、これは同じオブジェクトであると想定します。
アプローチの短所:
- 少しの精度。
- ネットワークを認識に使用します。
- 画面の向きを変える問題(HAARは斜めに認識できない)。
- ご覧のとおり、すべてが非常に原始的であり、実際、各要素について、既製、ドライツードライ、生産にすべてを使用します。
これは、1つのプラットフォームでの単純な認識に関してはすべて素晴らしいです。 しかし、顧客の考えは神秘的です。
次号では、3Dの魅力的な世界に突入します。

ReksoftシニアソフトウェアエンジニアVitaly Zarubinが作成