
エクスポート先
テーブル、ビュー、または結果は、ファイルまたはクリップボードにエクスポートできます。
ファイルにエクスポート:
-ツリーのテーブルまたはビューのコンテキストメニュー→ データをファイルにダンプします。
-エディターでのリクエストのコンテキストメニュー→ファイルへの実行。
- データまたは結果 エディターのツールバーで、 データの ダンプ→ファイルへ...

クリップボードにエクスポート:
- データまたは結果エディターでエクスポートするデータを選択し、 コピーまたはCtrl / Cmd + Cを押します。
- 結果またはデータエディターのツールバーで、 [ データのダンプ ] →[ファイルへ... ]をクリックします。
デフォルト形式
一部の形式はデフォルトで設定されています。 エクスポートメカニズム自体を「エクストラクター」と呼びます。さまざまな形式のいくつかのエクストラクターがすでにIDEに組み込まれています。 たとえば、データをクリップボードにエクスポートすることを検討しますが、これはファイルにエクスポートする場合にも機能します。
[ データのダンプ ]ボタンの左側のメニューで、エクストラクターを選択します。
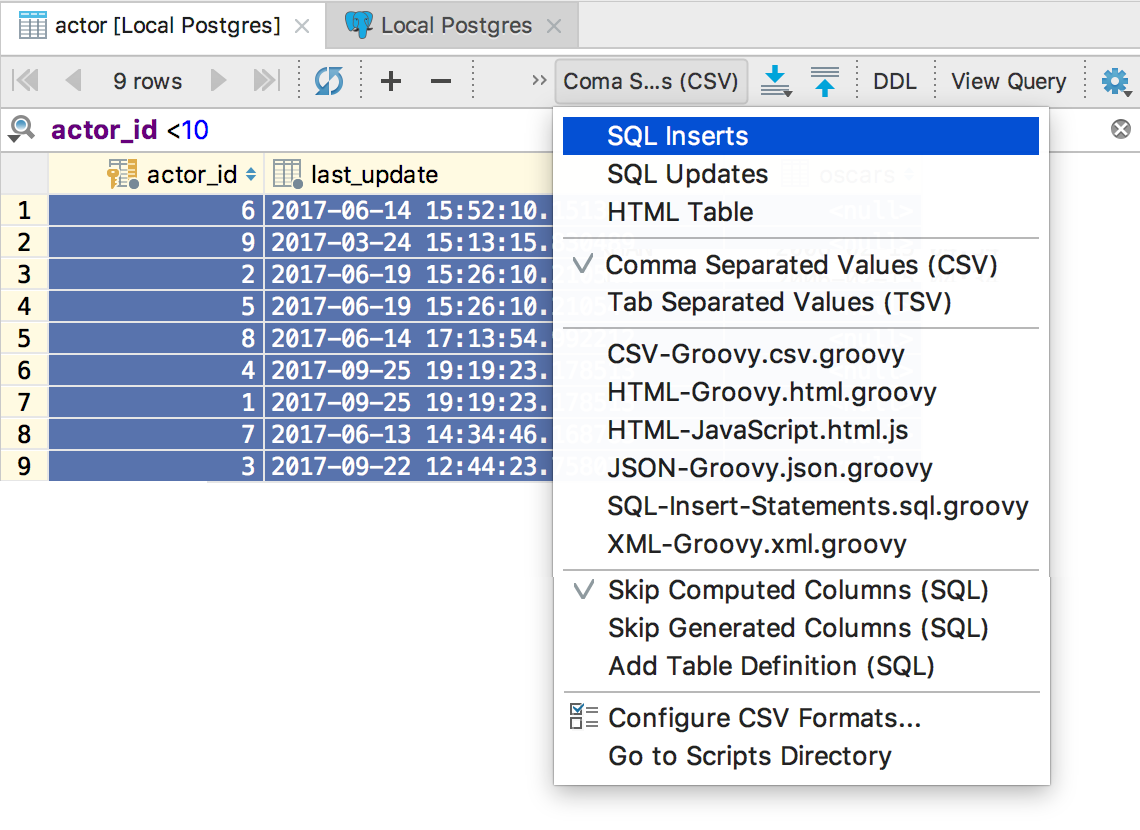
INSERT / UPDATEクエリまたはJSON、CSV、HTMLのセット-あなたが決定します。 組み込みのエクストラクタがどのように機能するかを説明しますが、これには焦点を合わせません。
ユーザーが組み込みの機能を拡張したいと考えるのは当然です。

CSVカスタム抽出
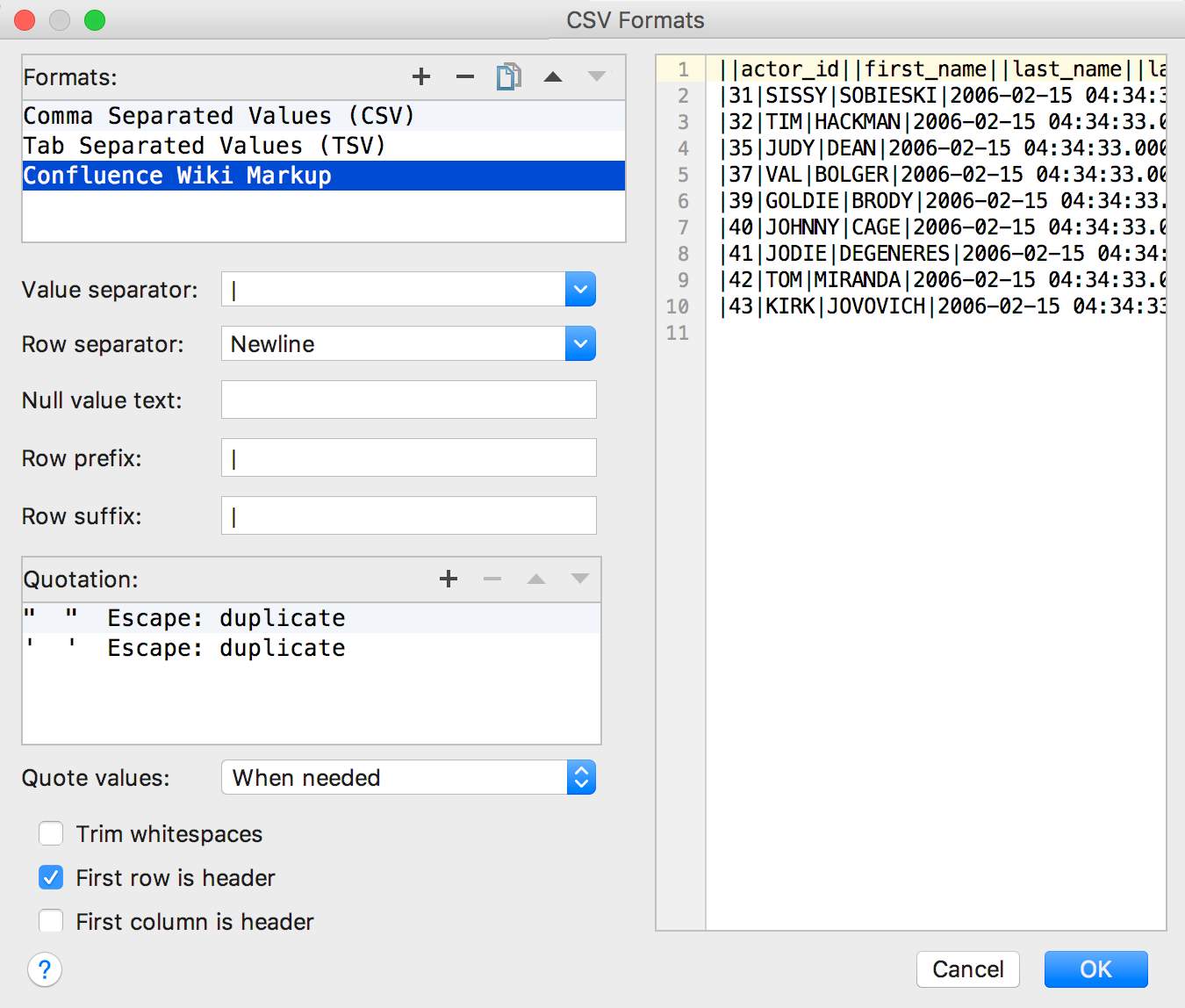
CSV(または厳密に言えばDSV)に基づく形式の独自の抽出プログラムを作成するには、同じメニューで[ CSV形式の構成 ]をクリックします...

ここで、既存の抽出プログラムに変更を加えるか、独自の抽出プログラムを作成できます。 たとえば、 Confluence Wikiマークアップ。
保存された新しい抽出プログラムがメニューに表示されます:

スクリプトを使用して任意の形式で抽出プログラムを作成する
より複雑な場合は、スクリプトを使用します。 いくつかの組み込みエクストラクターは、GroovyまたはJavaScriptのスクリプトです: CSV-Groovy.csv.groovy 、 HTML-JavaScript.html.jsなど。 この例では、Groovyを使用します。
ファイル名CSV-Groovy.csv.groovyを分析しましょう:
CSV-Groovy-スクリプトの名前。
csv-結果のファイル拡張子。
groovy-スクリプトファイル拡張子。 IntelliJ IDEAで編集する場合、コードの強調表示と自動補完が役立ちます。
スクリプトは通常、 「スクラッチとコンソール/拡張機能/データベースツールとSQL /データ/エクストラクター」にあります 。 このフォルダーにアクセスするには、抽出機能の選択メニューで[ スクリプトディレクトリに移動 ]をクリックします。

既存のエクストラクターを変更するか、このフォルダーに新しいエクストラクターを追加します。 たとえば、コンマで区切られた1行でデータをエクスポートする抽出プログラムを作成します。 これは、単一の列の値をINステートメントのWHERE句に挿入する場合に便利です。
既存の抽出プログラムに基づいて、 CSV-ToOneRow-Groovy.csv.groovyという新しい抽出プログラムを作成しました。
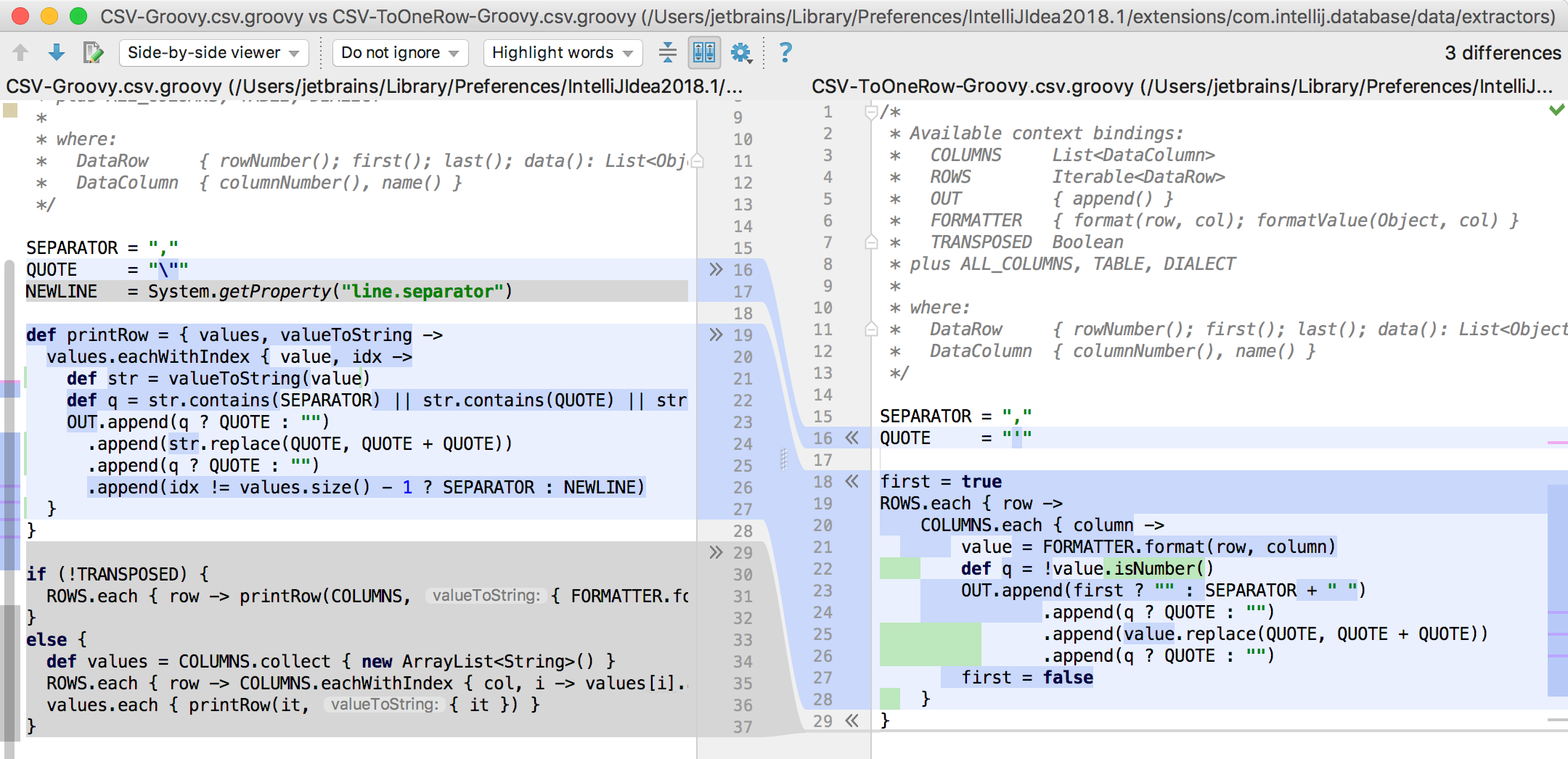
コンテキストで利用可能:
OUT {append()} // FORMATTER {format(row, col); formatValue(Object, col)} // TRANSPOSED Boolean // Transpose ( ) COLUMNS List<DataColumn> // ALL_COLUMNS List<DataColumn> // // , . ROWS Iterable<DataRow> // , : DataRow { rowNumber(); first(); last(); data(): List<Object>; value(column): Object } DataColumn { columnNumber(); name() } TABLE DasTable //
DasTableには 2つの重要なメソッドがあります。
バージョン2017.3より前:
DasObject getDbParent() JBIterable<DasObject> getDbChildren(Class, ObjectKind)
2017.3以降:
DasObject getDasParent() JBIterable<DasObject> getDasChildren(ObjectKind)
APIの詳細については、 こちらをご覧ください 。
GroovyがインストールされたIntelliJ IDEAでこれを行うと、バックライトと自動補完が機能します。

新しいスクリプトをフォルダーに入れてください:使用する準備が整い、メニューに表示されます。
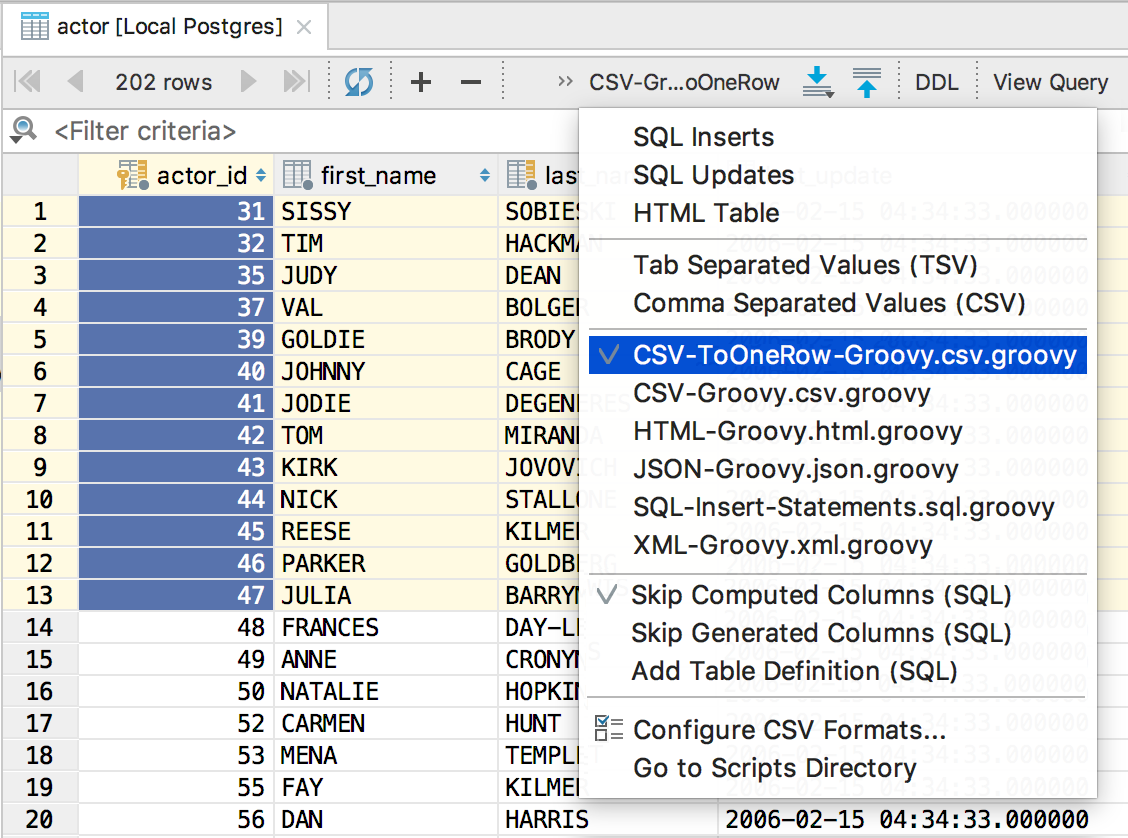
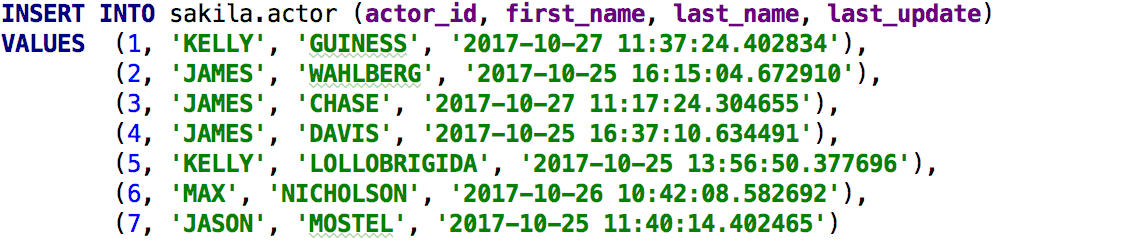
たとえば、これらの値をコピーしてクエリに貼り付けます。

別の例:INSERTの複数行構文は、MySQLとPostgreSQLで許可されています。 INSERTの現在のエクストラクターを変更すると、新しいファイルSQL-Inserts-MultirowSynthax.sql.groovyが取得されます。
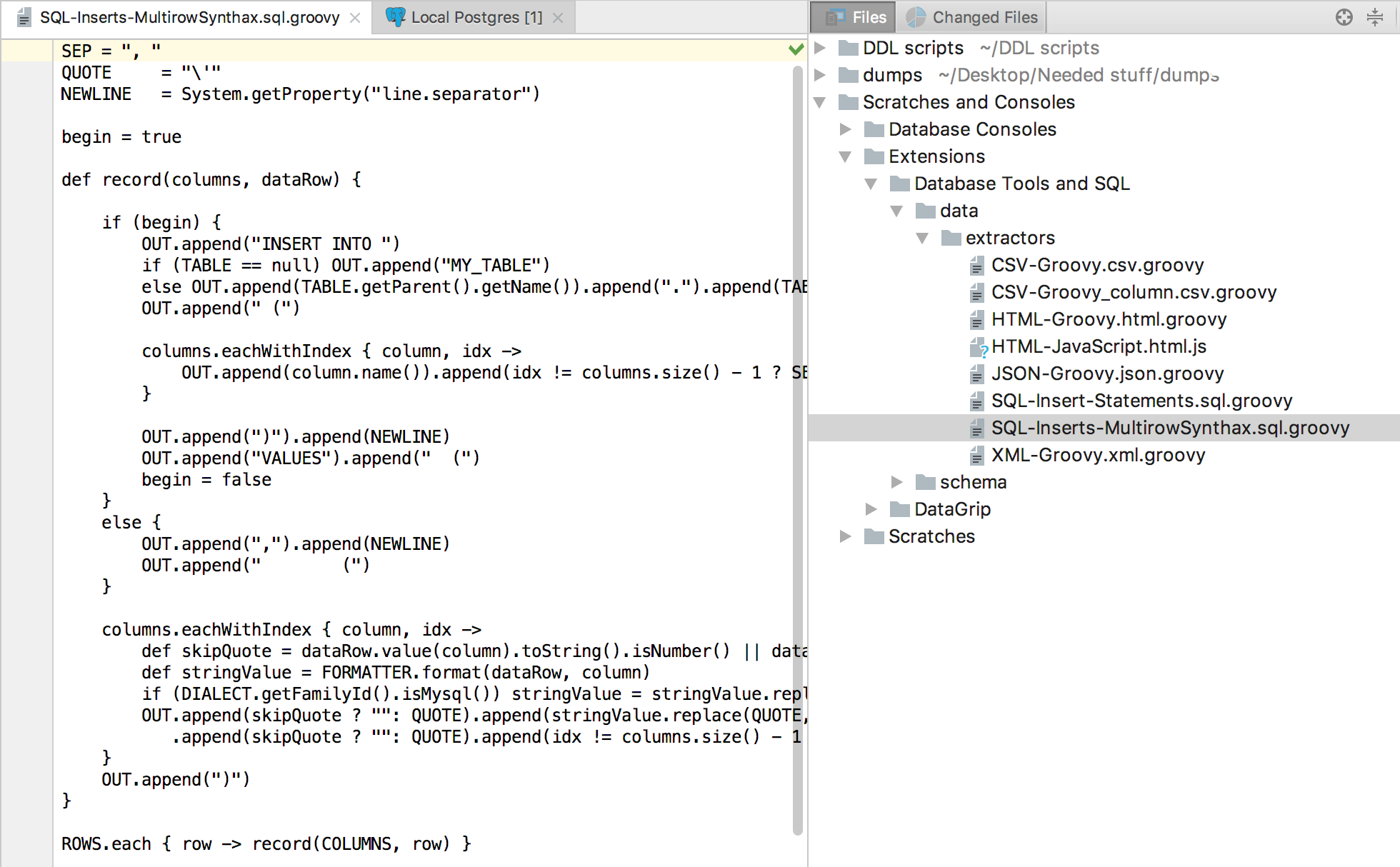
新しく作成した抽出プログラムを選択し、データをコピーします。
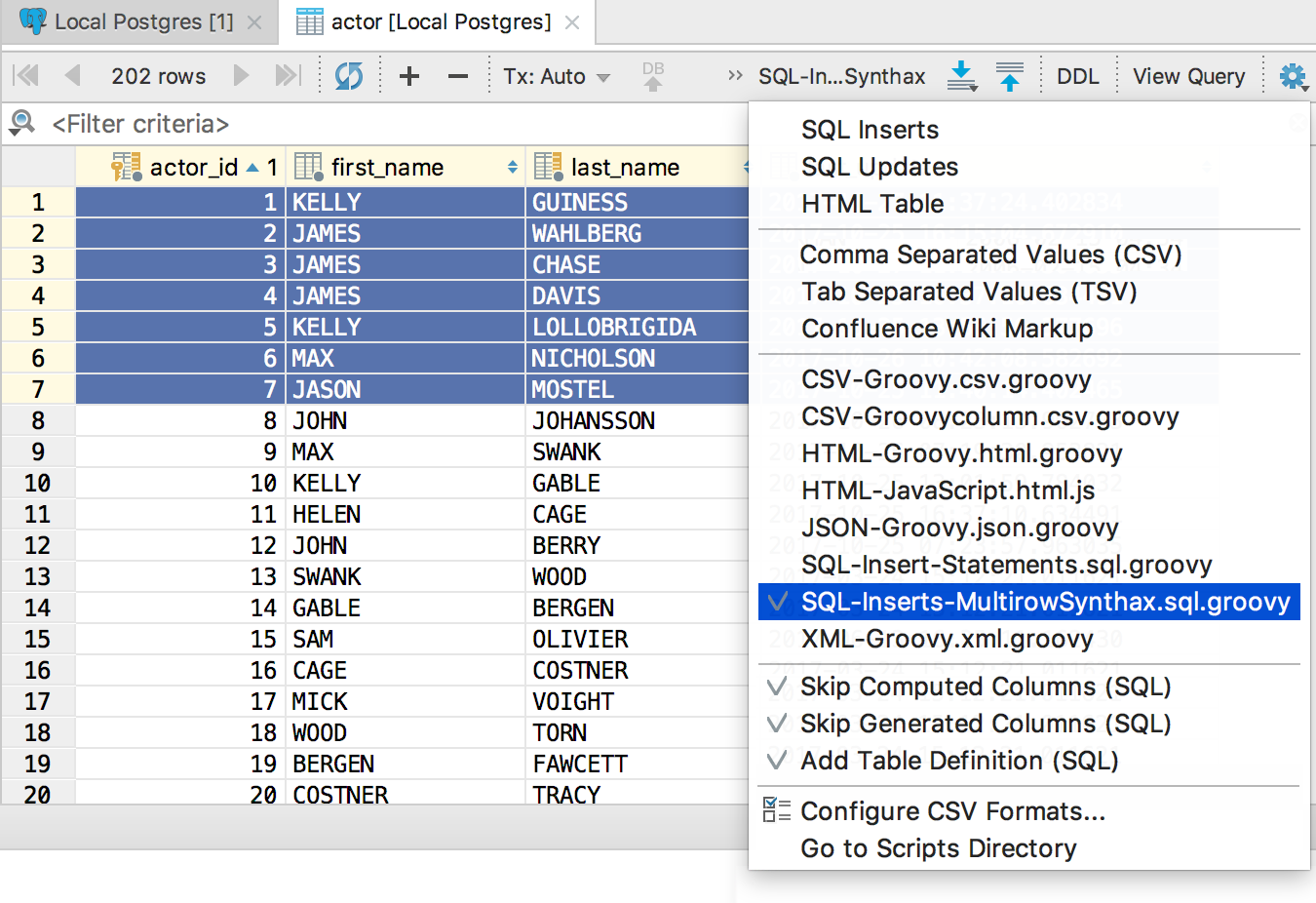
完了:
一部のユーザーはすでにこれを理解し、抽出プログラムを作成しています。
- テキスト表 。 ( 同様 )。
-Phpの配列 。
- マークダウン 。
-DBunit XML 。
このテキストが、あなたの抽出プログラムを書いて、他の人と共有することを刺激するなら、それはクールです!
DataGripチーム