
少し前に、私は私の人生を簡素化するユーティリティを作り始めました。 これはgomodifytagsと呼ばれます 。 ユーティリティは、フィールド名を使用して構造タグ(structタグ)のフィールドに自動的に入力します。 例:
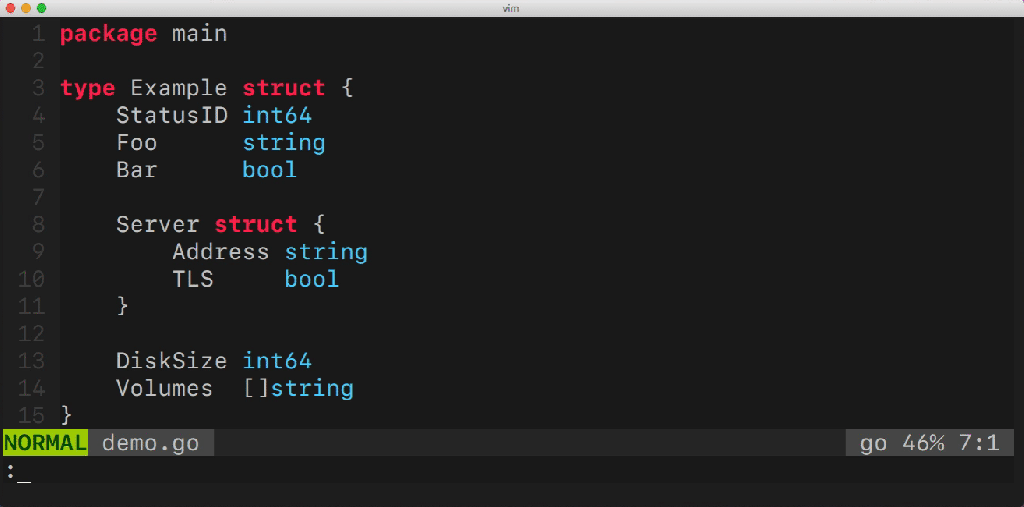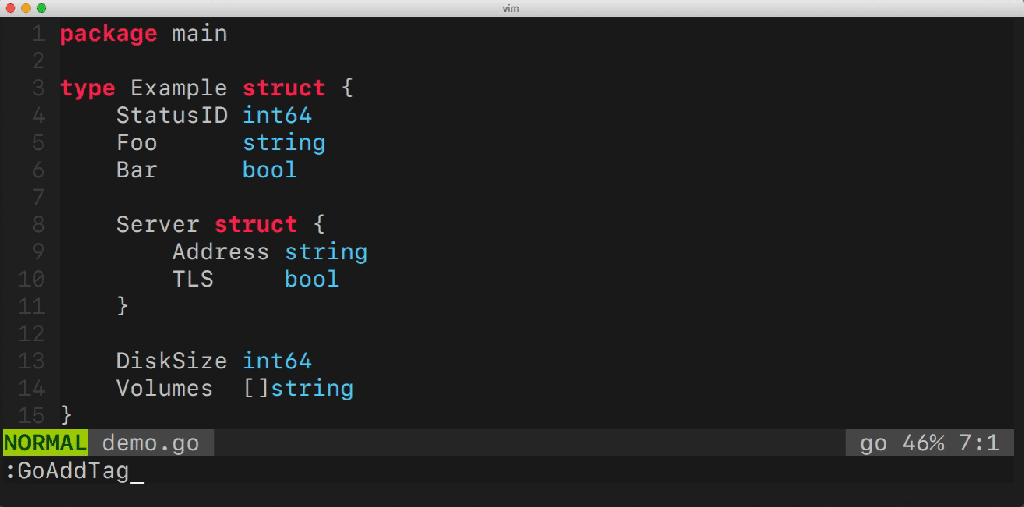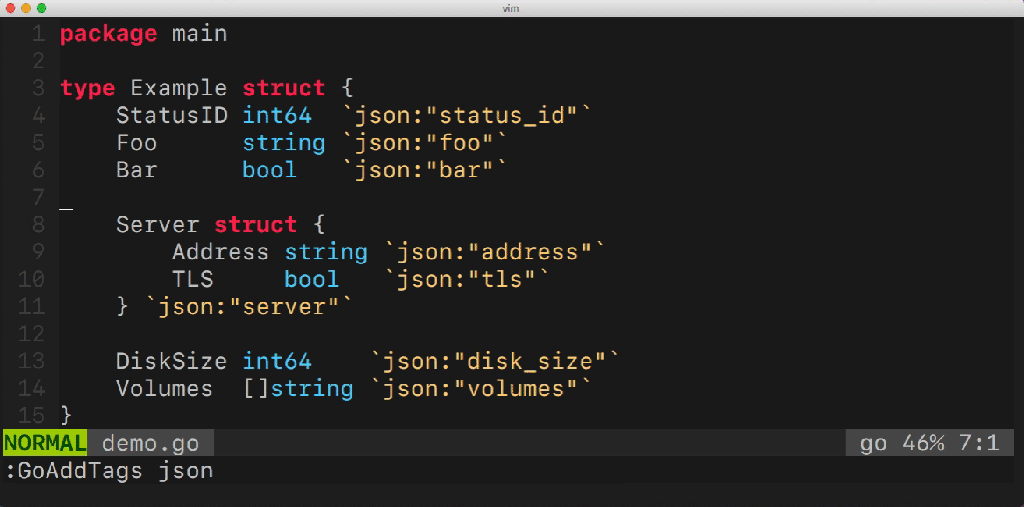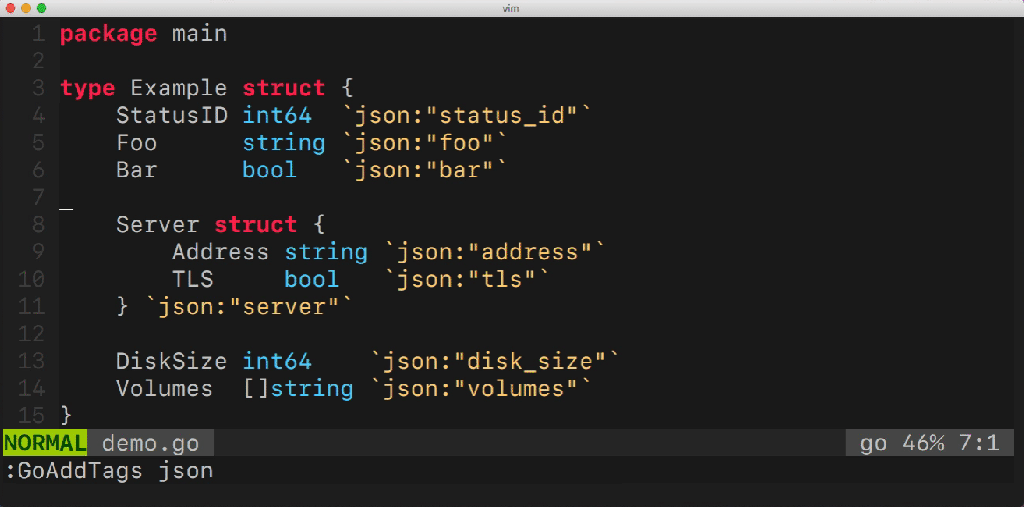
このユーティリティを使用すると、複数の構造フィールドを簡単に管理できます。 タグの追加と削除、オプションの管理(たとえば、emptyempty)、変換ルール( snake_case、camelCaseなど)の定義などができます。 このユーティリティはどのように機能しますか? 彼女はどのGoパックを使用していますか? おそらく多くの質問があります。
この非常に長い記事では、このようなユーティリティを作成および構築する方法について詳しく説明します。 ここには、Goコードだけでなく、多くのヒントやコツがあります。
コーヒーを注いで、読み始めましょう!
まず、ユーティリティが何をすべきかを考えましょう。
- ソースファイルを読んで理解し、Goファイルに変換します。
- 適切な構造を見つけます。
- フィールド名を取得します。
- 構造タグをフィールド名で更新します(変換ルール、たとえばsnake_caseに従って )。
- 最後に、これらの変更をファイルに加えるか、別の便利な方法でプログラマーに提供します。
構造タグを定義することから始め、次にユーティリティを順番に構築して、その部分と相互の相互作用を調べます。

値タグ(たとえば、そのコンテンツjson:"foo"
)は、公式の仕様には記載されていません 。 ただし、reflectパッケージには、stdlibパッケージも使用する形式( encoding / jsonなど )でこのタグを定義する非公式の仕様があります。 これは、 reflect.StructTag型を介して行われます 。
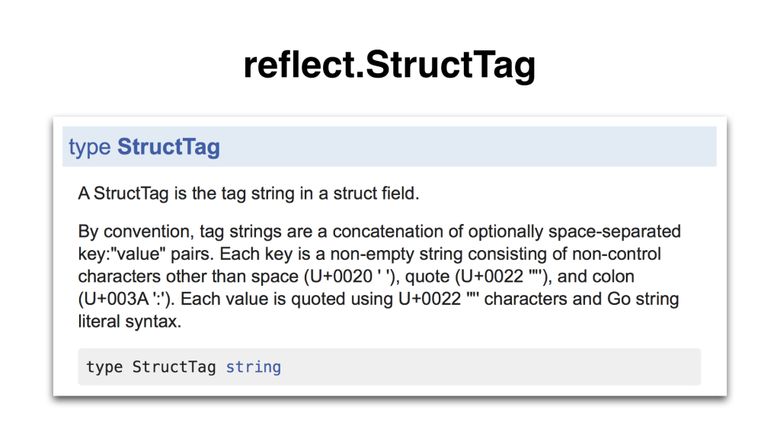
定義は簡単ではありません。理解しましょう。
- 構造タグは文字列リテラルです(文字列型を参照するため)。
- キーは引用符で囲まれていない文字列リテラルです 。
- 値は、 引用符で囲まれた文字列リテラルです 。
- キーと値はコロン(:)で区切られます。 すべてをまとめてキーと値のペアと呼びます 。
- 構造タグには、複数のキーと値のペアを含めることができます (必要な場合)。 ペアはスペースで区切られます 。
- オプションの設定は、定義には記載されていません。 encoding / jsonのようなパッケージは、コンマが区切り文字として使用されるリストの値を読み取ります。 最初のコンマの後に来るものはすべてオプションの一部です。 たとえば、リスト「 foo、 nullempty、string」は、値「foo」とオプション[「omitempty」、「string」]をリストします。
- 構造タグは文字列リテラルであるため、二重引用符または逆アポストロフィ(左の一重引用符)で囲む必要があります。
これらすべてのルールを繰り返します。

構造タグの定義には多くの明白でない詳細があります。
これで、構造タグが何であるかがわかり、必要に応じて簡単に変更できます。 質問は、今それを解析して簡単に変更する方法ですか? 幸い、 reflect.StructTagには、タグを解析して特定のキーの値を返すメソッドもあります。 例:
package main import ( "fmt" "reflect" ) func main() { tag := reflect.StructTag(`species:"gopher" color:"blue"`) fmt.Println(tag.Get("color"), tag.Get("species")) }
画面に表示します:
blue gopher
キーが存在しない場合、空の文字列が返されます。
しかし、非常に便利ですが、より柔軟なソリューションが必要なため、この機能が役に立たない制限があります。 制限のリスト:
- タグ内のエラーは認識しません(たとえば、引用符で囲まれたキー、引用符のない値など)。
- オプションのセマンティクスを認識しません。
- 既存のタグを調べたり、返したりすることはできません。 どのタグを変更するかを事前に知る必要があります。 そして、名前が不明な場合は?
- 既存のタグは変更できません。
- 新しい構造タグを最初から作成することはできません。
Goパッケージを作成しました。これは、これらすべての欠点を修正し、構造タグの任意の部分を簡単に変更できるAPIを提供します。

パッケージはstructtagと呼ばれ、ここからダウンロードできます: github.com/fatih/structtag パッケージは、タグを正確に解析および変更できます 。 以下は完全に機能する例です。コピーしてテストできます。
package main import ( "fmt" "github.com/fatih/structtag" ) func main() { tag := `json:"foo,omitempty,string" xml:"foo"` // parse the tag tags, err := structtag.Parse(string(tag)) if err != nil { panic(err) } // iterate over all tags for _, t := range tags.Tags() { fmt.Printf("tag: %+v\n", t) } // get a single tag jsonTag, err := tags.Get("json") if err != nil { panic(err) } // change existing tag jsonTag.Name = "foo_bar" jsonTag.Options = nil tags.Set(jsonTag) // add new tag tags.Set(&structtag.Tag{ Key: "hcl", Name: "foo", Options: []string{"squash"}, }) // print the tags fmt.Println(tags) // Output: json:"foo_bar" xml:"foo" hcl:"foo,squash" }
これで、構造タグを解析し、変更して新しいタグを作成できます。 次に、正しいソースGoファイルを変更する必要があります。 上記の例では、タグはすでにそこにありますが、既存のGo構造からどのように取得しますか?
回答: ASTを通じて。 AST( 抽象構文ツリー )を使用すると、ソースコードから任意の識別子(ノード)を抽出できます。 以下は、単純化された構造化ツリーです。

Go ast.Node構造タイプの基本表現
このツリーでは、任意の識別子を抽出して操作できます-文字列、角括弧など。それらはそれぞれASTノードで表されます 。 たとえば、フィールドの名前を「Foo」から「Bar」に変更して、それを表すノードを置き換えることができます。 構造タグについても同じです。
Go ASTを取得するには、ソースファイルを解析し、ASTに変換する必要があります。 これらはすべて1ステップで実行されます。
ファイルを解析するには、 go / parserパッケージを使用して(ファイル全体のツリーを構築します)、 go / astパッケージの助けを借りてツリーを調べます(手動で行うことができますが、これは別の記事のトピックです) 完全に機能する例を次に示します。
package main import ( "fmt" "go/ast" "go/parser" "go/token" ) func main() { src := `package main type Example struct { Foo string` + " `json:\"foo\"` }" fset := token.NewFileSet() file, err := parser.ParseFile(fset, "demo", src, parser.ParseComments) if err != nil { panic(err) } ast.Inspect(file, func(x ast.Node) bool { s, ok := x.(*ast.StructType) if !ok { return true } for _, field := range s.Fields.List { fmt.Printf("Field: %s\n", field.Names[0].Name) fmt.Printf("Tag: %s\n", field.Tag.Value) } return false }) }
実行結果:
Field: Foo Tag: `json:"foo"`
私たちがすること:
- 単一の構造を使用して、有効なGoパッケージの例を定義します。
- go / parserパッケージを使用して、この文字列を解析します。 また、パッケージはディスクからファイル(またはパッケージ全体)を読み取ることができます。
- ファイルを解析した後、ノード(変数ファイルに割り当てられている)に移動し、 * ast.StructTypeで定義されたASTノードを探します(AST図を参照)。
ast.Inspect()
関数を使用して、ツリーを下っていきます。 この関数は、間違った値が見つかるまですべてのノードを反復処理します。 ノードを覚える必要がないため、非常に便利です。 - 構造フィールドの名前と構造タグを表示します。
これで、 2つの重要な問題を解決できます 。 最初に、 元のGoファイルを解析し 、構造タグを取得する方法を知っています (go / parserを使用)。 次に、 構造タグを解析し、必要に応じて変更できます( github.com/fatih/structtagを使用)。
これらの2つのスキルを使用して、ユーティリティ(gomodifytags)の構築を開始できます。 彼女は:
- どの構造を変更する必要があるかを示す構成を取得します。
- この構造を見つけて変更します。
- 結果を出力します。
gomodifytagsはほとんどの場合エディターによって実行されるため、CLIフラグを介して構成を渡します。 2番目の段階は、ファイルの解析、正しい構造の検索、変更(ASTを使用)などのいくつかの手順で構成されます。 最後に、結果を元のGoファイルに出力するか、何らかのプロトコル(JSONなど)で出力します。これについては以下で説明します。
gomodifytagsの簡略化されたメイン関数:

各ステップを詳しく見てみましょう。 もっと簡単に伝えようと思います。 ここではすべてが同じですが、読み終えると、ヘルプなしでソースコードを把握できます(ソースへのリンクはマニュアルの最後にあります)。
設定を取得することから始めましょう。 以下は、必要なすべての情報がある構成です。
type config struct { // first section - input & output file string modified io.Reader output string write bool // second section - struct selection offset int structName string line string start, end int // third section - struct modification remove []string add []string override bool transform string sort bool clear bool addOpts []string removeOpts []string clearOpt bool }
構成は3つのセクションで構成されています。
最初のファイルには、どのファイルをどのように読み込むかを説明する設定が含まれています。 これは、ローカルファイルシステムのファイル名を使用するか、stdinから直接実行できます(通常はエディターで作業するときに使用されます)。 最初のセクションでは、結果を(元のGoファイルまたはJSONに)出力する方法と、stdoutに出力する代わりにファイルを上書きするかどうかも示します。
2番目のセクションでは、構造とそのフィールドを選択する方法を示します。 これはさまざまな方法で実行できます。オフセット(カーソル位置)、構造の名前、1行(フィールドを選択するだけ)、または行の範囲を使用します。 最後に、開始行と終了行を抽出する必要があります。 以下は、名前で構造を選択し、開始行と終了行を抽出して正しいフィールドを選択する方法を示しています。
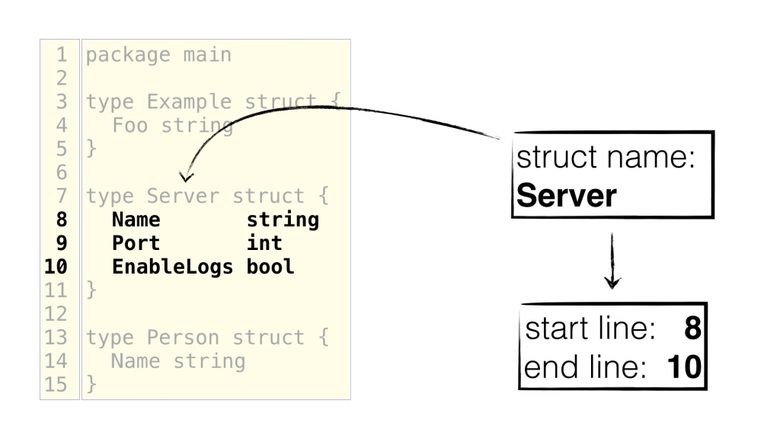
同時に、エディターはバイトオフセットを使用する方が快適です。 次の図では、カーソルは"Port"
フィールドの名前のすぐ後にあり、そこから開始行と終了行を簡単に取得できます。
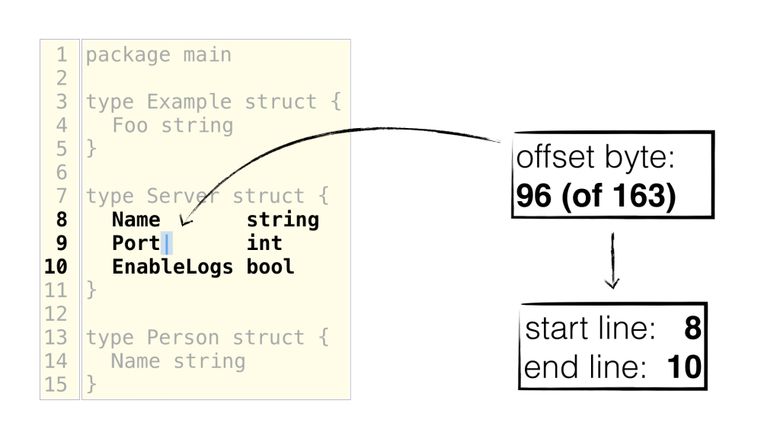
構成の3番目のセクションは、 structtag
パッケージにデータを渡すことにstructtag
ます。 すべてのフィールドを読み取った後、構成がstructtag
パッケージに渡されます。これにより、構造タグを解析し、その部分を変更できます。 ただし、同時に、構造フィールドは上書きまたは更新されません。
そして、どのように構成を取得しますか? flag
パッケージを取得し、構成内の各フィールドのフラグを作成し、それらにバインドします。 例:
flagFile := flag.String("file", "", "Filename to be parsed") cfg := &config{ file: *flagFile, }
構成内の各フィールドに対して同じことを行います 。 フラグ定義の完全なリストは、現在のgomodifytagウィザードにあります。
設定を受け取ったら、基本的なチェックを実行します。
func main() { cfg := config{ ... } err := cfg.validate() if err != nil { log.Fatalln(err) } // continue parsing } // validate validates whether the config is valid or not func (c *config) validate() error { if c.file == "" { return errors.New("no file is passed") } if c.line == "" && c.offset == 0 && c.structName == "" { return errors.New("-line, -offset or -struct is not passed") } if c.line != "" && c.offset != 0 || c.line != "" && c.structName != "" || c.offset != 0 && c.structName != "" { return errors.New("-line, -offset or -struct cannot be used together. pick one") } if (c.add == nil || len(c.add) == 0) && (c.addOptions == nil || len(c.addOptions) == 0) && !c.clear && !c.clearOption && (c.removeOptions == nil || len(c.removeOptions) == 0) && (c.remove == nil || len(c.remove) == 0) { return errors.New("one of " + "[-add-tags, -add-options, -remove-tags, -remove-options, -clear-tags, -clear-options]" + " should be defined") } return nil }
チェックが1つの関数で実行されると、テストが簡単になります。
ファイルの解析に移りましょう:
最初に、ファイルの解析方法についてすでに説明しました。 この場合、解析は構成構造内のメソッドによって行われます。 実際、すべてのメソッドはこの構造の一部です。
func main() { cfg := config{} node, err := cfg.parse() if err != nil { return err } // continue find struct selection ... } func (c *config) parse() (ast.Node, error) { c.fset = token.NewFileSet() var contents interface{} if c.modified != nil { archive, err := buildutil.ParseOverlayArchive(c.modified) if err != nil { return nil, fmt.Errorf("failed to parse -modified archive: %v", err) } fc, ok := archive[c.file] if !ok { return nil, fmt.Errorf("couldn't find %s in archive", c.file) } contents = fc } return parser.ParseFile(c.fset, c.file, contents, parser.ParseComments) }
parse
関数はparse
ソースコードのみをparse
ast.Node
を返すことがast.Node
ます。 ファイルを転送する場合、すべてが非常に簡単です。この場合、 parser.ParseFile()
関数が使用されます。 *token.FileSet
タイプを作成するtoken.NewFileSet()
注意してください。 c.fset
に保存しますが、 parser.ParseFile()
関数にも渡します。 なんで?
ファイルセットは 、各ファイルごとに各ノードの場所に関する情報を保存するために使用されるためです。 これは、 ast.Node
正確な位置を取得するために後で非常に役立ちます。 (ast.Nodeはtoken.Posと呼ばれるコンパクトな位置情報を使用することに注意してください token.FileSet.Position()
関数を使用して token.FileSet.Position()
を復号化すると 、 詳細情報を含む token.Position
を取得します。)
続けましょう。 stdinを介してソースファイルを転送すると、状況はさらに興味深いものになります。 config.modified
フィールドは簡単なテストのためにio.Readerですが、実際には標準入力を渡します。 しかし、stdinから何を読みたいのかを判断する方法は?
ユーザーにstdin経由でコンテンツを送信するかどうかを尋ねます。 この場合、ユーザーは--modified
フラグ( ブールフラグ)を渡す必要があります。 合格した場合は、 c.modified
stdinを添付しc.modified
。
flagModified = flag.Bool("modified", false, "read an archive of modified files from standard input") if *flagModified { cfg.modified = os.Stdin }
config.parse()
関数をもう一度見ると、 .modified
フィールドの添付ファイルをチェックしていることが.modified
ます。 Stdinは、選択したプロトコルに従って解析する必要がある任意のデータストリームです。 この場合、アーカイブには次のものが含まれていると仮定します。
- ファイルの名前、次に新しい行。
- 10進数のファイルサイズ、次に改行。
- ファイルの内容。
ファイルサイズがわかっているため、コンテンツを安全に解析できます。 何かが大きくなった場合は、解析を停止してください。
このアプローチは他のいくつかのユーティリティ( guru 、 gogetdocなど)で使用されます。編集者はファイルシステムに保存せずに変更されたファイルの内容を転送できるため、編集者にとって非常に便利です。 したがって、「変更」。
したがって、ノードがあります。構造を探しましょう。
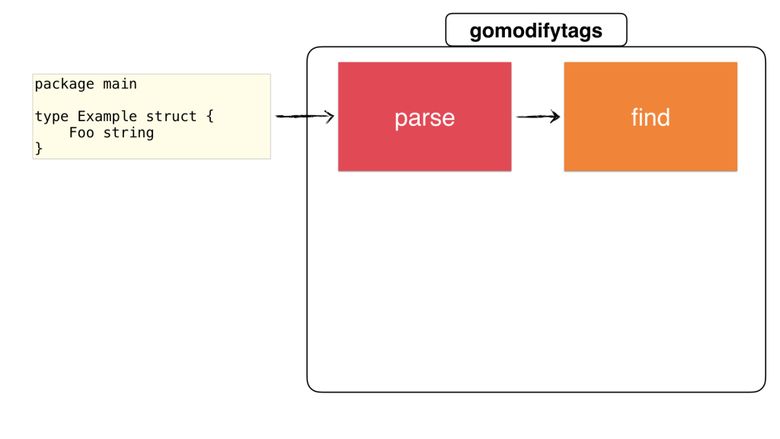
メイン関数では、 findSelection()
関数を呼び出します。これは前のステップで解析します。
func main() { // ... parse file and get ast.Node start, end, err := cfg.findSelection(node) if err != nil { return err } // continue rewriting the node with the start&end position }
cfg.findSelection()
関数は、構成に基づいて、構造の開始位置と終了位置、および構造が選択された順序を返します。 指定されたノードを通過し、開始位置と終了位置を返します(構成のセクションで説明されています)。
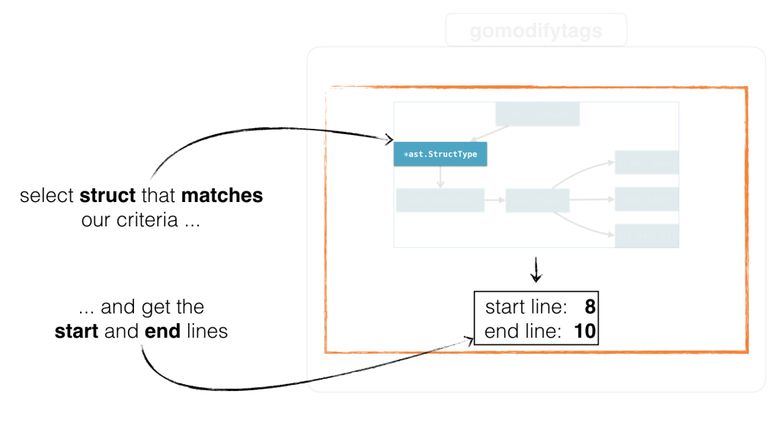
その後、関数は* ast.StructTypeが見つかるまですべてのノードを反復処理し、その開始位置と終了位置をファイルに返します。
しかし、これはどのように行われますか? 3つのモードがあることに注意してください。 行 、 オフセット、および構造名による選択:
// findSelection returns the start and end position of the fields that are // suspect to change. It depends on the line, struct or offset selection. func (c *config) findSelection(node ast.Node) (int, int, error) { if c.line != "" { return c.lineSelection(node) } else if c.offset != 0 { return c.offsetSelection(node) } else if c.structName != "" { return c.structSelection(node) } else { return 0, 0, errors.New("-line, -offset or -struct is not passed") } }
行で選択するのが最も簡単です。 フラグ値自体を返すだけです。 ユーザーがフラグ"--line 3,50"
渡した場合、関数は(3, 50, nil)
"--line 3,50"
(3, 50, nil)
返します。 値を選択して整数に変換するだけでなく、同時にチェックします:
func (c *config) lineSelection(file ast.Node) (int, int, error) { var err error splitted := strings.Split(c.line, ",") start, err := strconv.Atoi(splitted[0]) if err != nil { return 0, 0, err } end := start if len(splitted) == 2 { end, err = strconv.Atoi(splitted[1]) if err != nil { return 0, 0, err } } if start > end { return 0, 0, errors.New("wrong range. start line cannot be larger than end line") } return start, end, nil }
このモードは、編集者が行のグループを選択して選択(強調表示)するときに使用されます。
オフセットおよび構造名で選択するには、さらに作業が必要です。 まず、利用可能なすべての構造を収集して、オフセットを計算したり、名前で検索したりする必要があります。 したがって、すべての構造を収集します。
// collectStructs collects and maps structType nodes to their positions func collectStructs(node ast.Node) map[token.Pos]*structType { structs := make(map[token.Pos]*structType, 0) collectStructs := func(n ast.Node) bool { t, ok := n.(*ast.TypeSpec) if !ok { return true } if t.Type == nil { return true } structName := t.Name.Name x, ok := t.Type.(*ast.StructType) if !ok { return true } structs[x.Pos()] = &structType{ name: structName, node: x, } return true } ast.Inspect(node, collectStructs) return structs }
ast.Inspect()
関数は、ASTを下って構造を探します。
最初に、名前を抽出できるように*ast.TypeSpec
が必要です。 *ast.StructType
を検索すると、構造自体はわかりますが、名前はわかりません。 したがって、名前と構造ノードを含むstructType
タイプを使用します。これは便利です。 各構造の位置は一意であるため、その位置をバインドのキーとして使用します。
これですべての構造ができました。オフセットと構造名を使用して、モードの開始位置と終了位置を返すことができます。 最初のケースでは、変位が指定された構造内に収まるかどうかを確認します。
func (c *config) offsetSelection(file ast.Node) (int, int, error) { structs := collectStructs(file) var encStruct *ast.StructType for _, st := range structs { structBegin := c.fset.Position(st.node.Pos()).Offset structEnd := c.fset.Position(st.node.End()).Offset if structBegin <= c.offset && c.offset <= structEnd { encStruct = st.node break } } if encStruct == nil { return 0, 0, errors.New("offset is not inside a struct") } // offset mode selects all fields start := c.fset.Position(encStruct.Pos()).Line end := c.fset.Position(encStruct.End()).Line return start, end, nil }
collectStructs()
を使用して、構造を収集し、繰り返します。 ファイルの解析に使用した初期token.FileSet
を保存したことを覚えていますか?
これで、構造体の各ノードからオフセットに関する情報を取得するのに役立ちます( token.Position
復号化し、 .Offset
フィールドを取得します )。 構造(この場合、名前はencStruct
)が見つかるまで、チェックして繰り返します。
for _, st := range structs { structBegin := c.fset.Position(st.node.Pos()).Offset structEnd := c.fset.Position(st.node.End()).Offset if structBegin <= c.offset && c.offset <= structEnd { encStruct = st.node break } }
この情報を使用して、見つかった構造の開始位置と終了位置を抽出できます。
start := c.fset.Position(encStruct.Pos()).Line end := c.fset.Position(encStruct.End()).Line
構造名を選択するときに同じロジックを使用します。 オフセットが指定された構造内にあるかどうかをチェックする代わりに、正しい構造が見つかるまで構造の名前をチェックします。
func (c *config) structSelection(file ast.Node) (int, int, error) { // ... for _, st := range structs { if st.name == c.structName { encStruct = st.node } } // ... }
開始位置と終了位置を取得したら、構造フィールドの変更に進みます。

メイン関数では、前の手順で解析されたノードでcfg.rewrite()
関数を呼び出します。
func main() { // ... find start and end position of the struct to be modified rewrittenNode, errs := cfg.rewrite(node, start, end) if errs != nil { if _, ok := errs.(*rewriteErrors); !ok { return errs } } // continue outputting the rewritten node }
これはユーティリティの重要な部分です。 書き換え機能は、開始位置と終了位置の間のすべての構造のフィールドを書き換えます。
// rewrite rewrites the node for structs between the start and end // positions and returns the rewritten node func (c *config) rewrite(node ast.Node, start, end int) (ast.Node, error) { errs := &rewriteErrors{errs: make([]error, 0)} rewriteFunc := func(n ast.Node) bool { // rewrite the node ... } if len(errs.errs) == 0 { return node, nil } ast.Inspect(node, rewriteFunc) return node, errs }
ご覧のとおり、再びast.Inspect()
を使用して、指定されたノードのツリーを下に移動します。 rewriteFunc
関数内で、各フィールドのタグを書き換えます(これについては後で説明します)。
ast.Inspect()
によって返される関数はエラーを返さないため、エラースキーム( errs
変数を使用して定義される)を作成し、ツリーを下ってフィールドを処理してエラースキームを収集します。 rewriteFunc
対処しましょう。
rewriteFunc := func(n ast.Node) bool { x, ok := n.(*ast.StructType) if !ok { return true } for _, f := range x.Fields.List { line := c.fset.Position(f.Pos()).Line if !(start <= line && line <= end) { continue } if f.Tag == nil { f.Tag = &ast.BasicLit{} } fieldName := "" if len(f.Names) != 0 { fieldName = f.Names[0].Name } // anonymous field if f.Names == nil { ident, ok := f.Type.(*ast.Ident) if !ok { continue } fieldName = ident.Name } res, err := c.process(fieldName, f.Tag.Value) if err != nil { errs.Append(fmt.Errorf("%s:%d:%d:%s", c.fset.Position(f.Pos()).Filename, c.fset.Position(f.Pos()).Line, c.fset.Position(f.Pos()).Column, err)) continue } f.Tag.Value = res } return true }
この関数はAST ノードごとに呼び出されることに注意してください。 したがって、タイプ*ast.StructType
ノードのみを探しています。 次に、構造体のフィールドを反復処理し始めます。
ここで、お気に入りの変数start
とend
を再び使用します。 このコードは、フィールドを変更するかどうかを決定します。 彼の位置がstart—end
間にある場合は続行し、そうでない場合は注意を払いません。
if !(start <= line && line <= end) { continue // skip processing the field }
次に、タグがあるかどうかを確認します。 タグフィールドが空( nil
)の場合、空のタグで初期化します。 後でこれはcfg.process()
関数の混乱を避けるのに役立ちます:
if f.Tag == nil { f.Tag = &ast.BasicLit{} }
続行する前に、面白いことを説明しましょう。 gomodifytagsはフィールド名を取得して処理しようとします。 そして、フィールドが匿名の場合はどうなりますか?
type Bar string type Foo struct { Bar //this is an anonymous field }
この場合、フィールドには名前がなく 、タイプ名に基づいてフィールド名を想定します。
// if there is a field name use it fieldName := "" if len(f.Names) != 0 { fieldName = f.Names[0].Name } // if there is no field name, get it from type's name if f.Names == nil { ident, ok := f.Type.(*ast.Ident) if !ok { continue } fieldName = ident.Name }
フィールド名とタグ値を受け取ったら、フィールドの処理を開始できます。 cfg.process()
関数が処理を担当します(フィールド名とタグ値がある場合)。 結果(この場合、構造タグのフォーマット)を返します。これを使用して、既存のタグ値を上書きします。
res, err := c.process(fieldName, f.Tag.Value) if err != nil { errs.Append(fmt.Errorf("%s:%d:%d:%s", c.fset.Position(f.Pos()).Filename, c.fset.Position(f.Pos()).Line, c.fset.Position(f.Pos()).Column, err)) continue } // rewrite the field with the new result,ie: json:"foo" f.Tag.Value = res
structtagを覚えている場合、実際にはString()がここに返されます-タグインスタンスの表現です。 タグの最終表現を返す前に、structtagパッケージのさまざまなメソッドを使用して、必要に応じて構造を変更します。 簡略化されたレビュー:
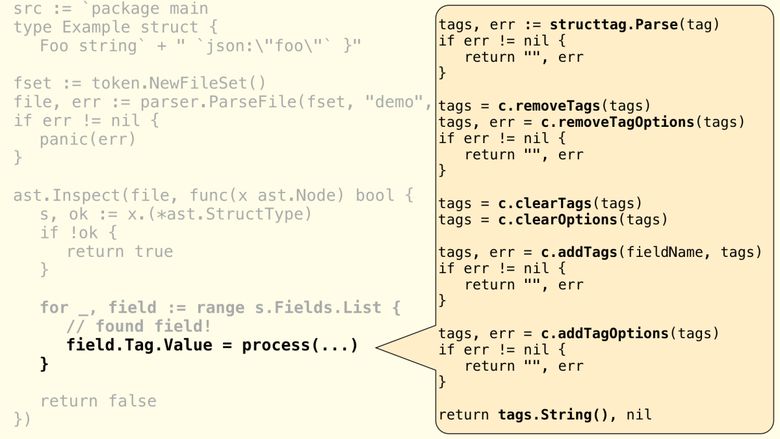
structtag
, removeTags()
process()
. ( ), :
flagRemoveTags = flag.String("remove-tags", "", "Remove tags for the comma separated list of keys") if *flagRemoveTags != "" { cfg.remove = strings.Split(*flagRemoveTags, ",") }
removeTags()
, - --remove-tags
. tags.Delete()
structtag:
func (c *config) removeTags(tags *structtag.Tags) *structtag.Tags { if c.remove == nil || len(c.remove) == 0 { return tags } tags.Delete(c.remove...) return tags }
cfg.Process()
.
, : .

cfg.format()
, :
func main() { // ... rewrite the node out, err := cfg.format(rewrittenNode, errs) if err != nil { return err } fmt.Println(out) }
stdout . . -, — , . -, stdout , , .
format()
:
func (c *config) format(file ast.Node, rwErrs error) (string, error) { switch c.output { case "source": // return Go source code case "json": // return a custom JSON output default: return "", fmt.Errorf("unknown output mode: %s", c.output) } }
.
(« ») ast.Node
Go-. , , .
(“JSON”) ( ). :
type output struct { Start int `json:"start"` End int `json:"end"` Lines []string `json:"lines"` Errors []string `json:"errors,omitempty"` }
( ):

format()
. , . « » go/format AST Go-. , gofmt . « »:
var buf bytes.Buffer err := format.Node(&buf, c.fset, file) if err != nil { return "", err } if c.write { err = ioutil.WriteFile(c.file, buf.Bytes(), 0) if err != nil { return "", err } } return buf.String(), nil
format io.Writer
. ( var buf bytes.Buffer
), , -write
. , Go.
JSON . , , . . , format.Node()
, lossy .
lossy- ? :
type example struct { foo int // this is a lossy comment bar int }
*ast.Field
. *ast.Field.Comment
, .
? foo bar ?
type example struct { foo int bar int }
, lossy- *ast.File
. , . , , , JSON:
var buf bytes.Buffer err := format.Node(&buf, c.fset, file) if err != nil { return "", err } var lines []string scanner := bufio.NewScanner(bytes.NewBufferString(buf.String())) for scanner.Scan() { lines = append(lines, scanner.Text()) } if c.start > len(lines) { return "", errors.New("line selection is invalid") } out := &output{ Start: c.start, End: c.end, Lines: lines[c.start-1 : c.end], // cut out lines } o, err := json.MarshalIndent(out, "", " ") if err != nil { return "", err } return string(o), nil
.
以上です!
, , :
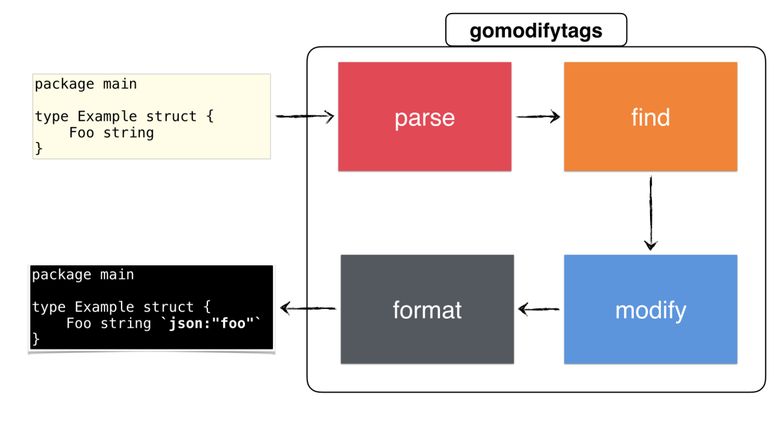
gomodifytags
:
- CLI- .
-
go/parser
,ast.Node
. - ( ) , , .
- ,
ast.Node
( structtag). - Go, JSON .
gomodifytags , :
- vim-go
- atom
- vscode
- acme
→ ソースコード