これは、 以前の出版物の続きです。 出版物の主な目的は、ビジネスで発生するさまざまな「通常の」データ処理タスクを解決するRの機能を実証することです。 主な重点は、エンドユーザー向けの完全なソリューションを作成することであり、コンソールの一連のコマンドによる特定の問題の根本的なソリューションではありません。 回路図のプロトタイプと組立ライン以外の製品には、類似点よりも多くの違いがあります。
Rの優れたメカニズムには、膨大な数の専門ブログ、書籍、githubがあります。 しかし、彼らは通常、Rを使って問題を解決することが可能であり、非常にエレガントであるとわかった後にのみ、彼らに目を向けます。
それがすべて始まった方法
一般に、初期状況は、外部ユーザーの要求に対応するコールセンターに少なくともある程度似ている企業にとって非常に典型的です。 PBXがあります(この場合、地理的に分散した複数のアスタリスクインスタンス、バージョン13LTS)。 オペレーターがユーザーから聞いた情報を提供する情報システム/システムがあります。 また、ユーザーリクエストを処理するための自動化されたビジネスプロセスが山ほどあります。
戦略的な管理のために「人々の生活」、「KPIの振る舞い」、「ビジネスが動いている場所」の要約を必要とするマーケティングなどの関連部門と同様に、コールセンターのトップからトップマネジメントに至るまでのリーダーシップの垂直性がまだあります。 そして、ここでお互いの欲望と可能性は非常に弱いと感じています。
サービスデスク部分にレポートジェネレーターが既にある場合、アスタリスクには最初はログとcdrしかありませんでした。
ステップ1
私たちはアスタリスクの既存のツールを見て、標準的な道を辿ろうとしました。 最初の近似として、プログラムの無料版に決めました。
少し良くなりました。 責任ある従業員は、最終的に必要な分析サマリーを準備することができました。 ただし、このレポートの品質は、いくつかの理由で非常に不十分でした。
- アスタリスクの処理スクリプトは非常に複雑で、マクロを介して記述されました。 定期的にCDRファイルは、レコード数を最小限に抑えることを重視して生成されます。 したがって、内部転送と肩の結合を「崩壊」させた場合の結果のCDRでは、多くの重要なデータが失われました。 A番号(マクロによる)とB番号(オペレーターによって開始された肩を組み合わせる場合)。
- キューには不完全な情報も含まれています。 IVRに関する記録、外部への転送に関する情報はありません。 そして、もっとたくさんあります。
- プログラム自体はコールセンターで一般に受け入れられている統計を作成および生成できますが、タスクに関しては、出力の半分以上が適切な質問に答えなかったため、ビジネスにはあまり役立ちませんでした。
- 無料版は機能性によってトリミングされます+少なくともそれが落ちないように、私は自分の手でphpを「仕上げ」なければなりませんでした。 それらが重要でないため(〜10%)、不正確な期間計算を無視します。 簡単にするために、これを特定のアスタリスク設定に帰します。
- 外部ディレクトリおよびシステムからのデータは添付できません。 すべてが優れている。 たとえば、シフトスケジュールを指定して、番号ではなくオペレーターの名前でレポートを表示します。
- グラフィカルな表現はなく、有料版で提供されるものは必要なものとはほど遠いものです。
- システムが異なれば、ほとんど常に異なる数値結果が得られます。 時々、違いは数百パーセントに達しました。 これは明らかに、呼び出しの複雑さと、プログラムに組み込まれた計算アルゴリズムの違いによるものです。
ステップ番号2
cdrおよびログファイルの独立した分析を行いました。 R. ChNNを数千回呼び出すと、1年間の作業で1〜2 GBのパッケージレコードが作成されます。 現代のラップトップの場合-これは完全なナンセンスであり、サーバーハードウェアは言うまでもありません。
そして、興味深いことが始まりました。 さまざまなデータスライスを一見しただけでも、アスタリスクの調整につながる多くの技術的な問題が発生しました。
- マクロが特定の種類の会話に必要な情報を提供しないのはなぜですか?
- オペレーターが仲介者である三者セッションをバインドできるように識別子が失われることがあるのはなぜですか?
- cdrの時間メトリックが常にリアルタイムイベントと一致しないのはなぜですか? IVRの時間は常にではなく、完全ではない(ロジックによって異なります)ことを考慮する必要があり、IVRは異なります。
- キューに多くの必須パラメーターがないのはなぜですか?
しかし、これは問題の技術的な側面にすぎません。 データを慎重に検討した結果、cdrの使用を中止することが決定されました(あまりにも不完全で不正確なデータがそこに書き込まれました。次のロジックを持つキュー(キューログ):
- プライマリセッションとリンクされたセッションの識別子を使用して、コールフローのフレームワーク内ですべてのイベントを再構築します。
- 私たちは、kpiを計算するビジネスロジックに基づいてイベントの細線化を行います(複数の応答なし、同じキューまたは別の複数の入力キュー、外部番号への転送、ブラインド転送など)。
- クリーンアップされたコールフローに基づいて、タイムスタンプに基づいてすべてのイベントの実際の継続時間を再計算します。
- オペレーターの番号から名前を取得するために、外部ソースからのデータ、特にオペレーターの勤務シフトのスケジュールからのデータでコールフローを強化します。
- 既に必要なレポートをすべて作成している「生の」データの「クリーンな」セットを取得します。
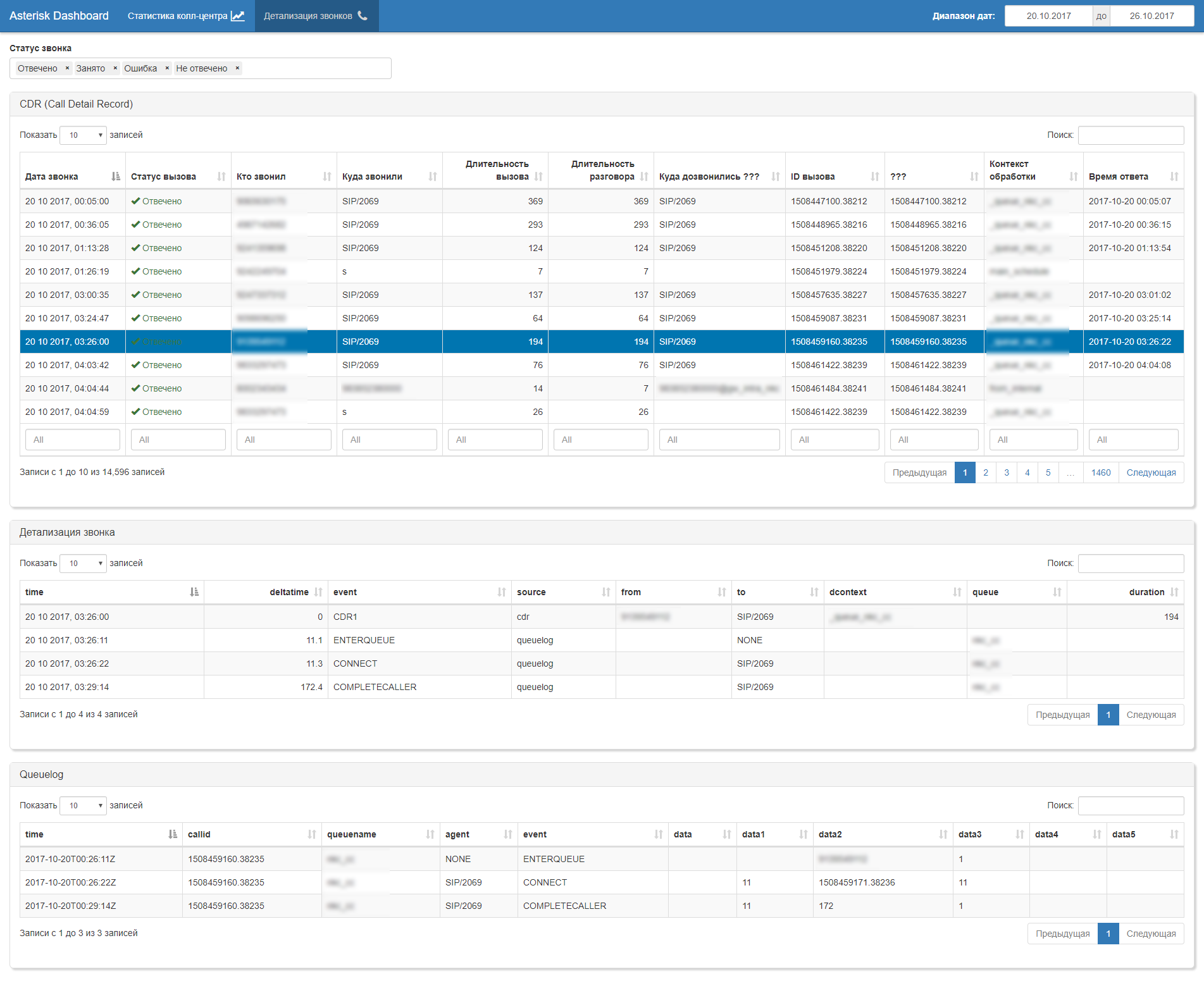
一般に、ビジネス成果物の定期的なセットの自動生成は次のとおりです。ダッシュボード、レポート、アップロード(xls、pdf、csv、doc、ppt、...)
コールセンターのヘッドのワークステーション自体は、Shinyで構築されています。

このようなデータの「クリーニング」の後、ビジネスと一緒にテーブルに座って、メトリック(KPI)とそれらを計算する方法論について話し合うことが重要です。 内部IVRで加入者が費やした時間は、通話時間と見なされますか? CONNECTは、オペレーターの答えとしてキューへの後続のインスタントリターンを考慮するかどうか。 サブスクライバーが複数のキューに留まるように、KPIオペレーターとキューを分解する方法は? キュー内の平均待機時間を時刻とシフト内のオペレーターの数と相関させる方法は? オペレーターの典型的な「最適化」シナリオとは何ですか? 他にもたくさんの質問があります。 最良の部分は、すべての質問に明確で明確な答えを与えることができるということです。
コールフローイベント分析への移行に加えて、コールセンターのシナリオを調査する機能(プロセスマイニング)があります。 実際、コールセンターのログで発生したビジネスプロセスのリバースエンジニアリング。 好奇心が強いものが現れます!
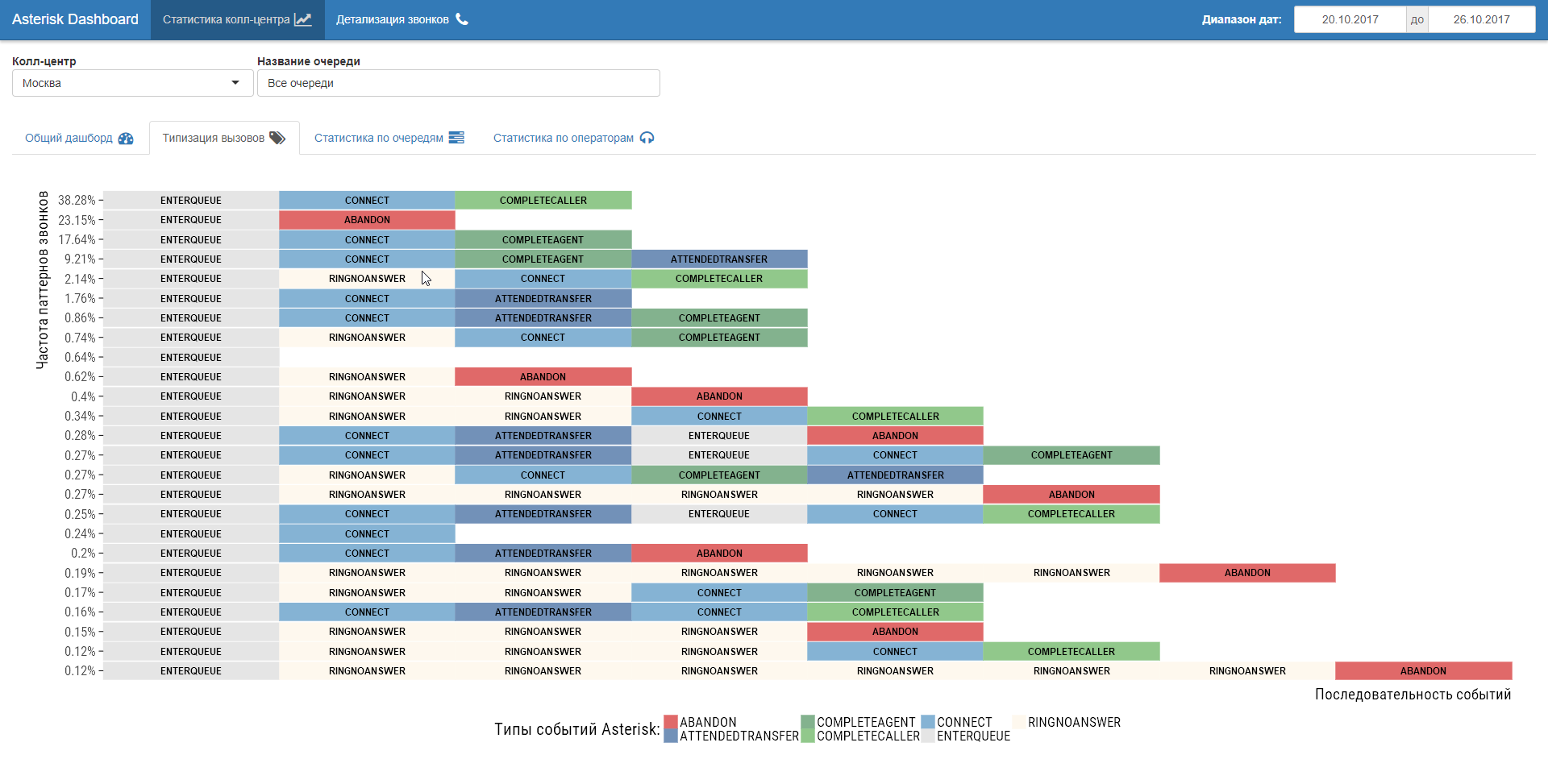
ステップ番号3
AMIイベントの分析への移行。 一般的に、これは最も普遍的な方法ですが、もう少し計算能力が必要です。 キューログを少し調整した後、AMI分析の重大度は1つのアスタリスクで消えましたが、アスタリスクの履歴作業(トラブルシューティング)のコンテキストでそれらを保存することは有用です。 また、AMIを使用すると、個々のアスタリスクのプライベート設定からの独立性が確保されます。これは、以下を接続するときに関連します。 AMIの処理速度を確保するために、ClickHouseに619の可能なフィールドを持つ151種類すべてのイベントをダンプします。
あとがき
多くの人が気付くように、タスクは非常にプライベートであり、データ量はわずかです。 しかし、このことから、ビジネスにおけるこのタスクの重要性は決して低下しません。 Rを使用することで、通常のビジネスユーザーにとって便利なワークステーションを作成しながら、迅速かつエレガントに解決することができました。 また、産業用プログラミングの観点から見ると、パッケージング、roxygenツールを使用した関数のドキュメント化、自動テスト、ログ記録、オンラインチェックやアサーションで裏打ちできるすべてのものも問題ありません。
強固な基盤ができたので、安全に予測と運用分析に進むことができます。
「ワードローブはそれと何の関係があるのか」という質問に対する答えは、悲しいかな、非常に平凡です。 スケルトンが彼から雨が降ったので、コールセンターのオペレーターによって慎重に隠されました。 そして、R + Shinyは、それを開くためのキーとして機能しました。
前の投稿: ビジネスですでにRを使用していますか?