puppeteer
を使用して、Webサイトからデータを自動的に収集するためのプログラムを作成できます。これは、通常のユーザーのアクションを模倣する、いわゆるWebスクレイパーです。 このようなシナリオでは、ユーザーインターフェースのないブラウザー、いわゆる「ヘッドレスChrome」を使用できます。
puppeteer
を使用すると、通常モードで実行されるブラウザーを制御できます。これは、プログラムのデバッグ時に特に役立ちます。
今日は、Node.jsと
puppeteer
基づいたWebスクレイパーの作成について説明します。 この記事の著者は、できるだけ多くのプログラマーの読者にこの記事を面白くするよう努めました。したがって、既に
puppeteer
経験があるWeb開発者と、「ヘッドレスクローム。」
事前準備
開始する前に、ノード8以降が必要です。 現在のバージョンを選択して、 ここで検索してダウンロードできます。 Nodeで作業したことがない場合は、 これらのトレーニングコースを見るか、他の資料を探してください。それらはWeb上にたくさんあります。
Nodeのインストール後、プロジェクト用のフォルダーを作成し、
puppeteer
をインストールします。 それとともに、Chromiumの現在のバージョンがインストールされます。これは、興味のあるAPIで動作することが保証されています。 これを行うには、次のコマンドを使用します。
npm install --save puppeteer
例#1:スクリーンショットを作成する
puppeteer
インストールした後、簡単な例を見てみ
puppeteer
。 彼は、わずかな修正を加えて、ライブラリのドキュメントを繰り返します。 これからレビューするコードは、特定のWebページのスクリーンショットを撮ります。
最初に、
test.js
ファイルを作成し、
test.js
ファイルを
test.js
入れます。
const puppeteer = require('puppeteer'); async function getPic() { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://google.com'); await page.screenshot({path: 'google.png'}); await browser.close(); } getPic();
このコードを行ごとに解析しましょう。 まず、全体像を示します。
const puppeteer = require('puppeteer');
この行では、以前にインストールした
puppeteer
ライブラリを依存関係として接続します。
async function getPic() { ... }
これがメイン関数
getPic()
です。 この関数には、ブラウザーでの作業を自動化するコードが含まれています。
getPic();
この行では、
getPic()
関数を呼び出します。つまり、実行します。
getPic()
関数は非同期であり、
async
定義されていることに注意することが重要です。 ES 2017の
async / await
コンストラクトを使用します
getPic()
は非同期関数であるため、呼び出されると
Promise
オブジェクトを返します。 このようなオブジェクトは、通常「約束」と呼ばれます。
async
定義された関数が終了して値を返すと、promiseは許可される(操作が成功した場合)または拒否されます(エラーが発生した場合)。
関数を定義するときに
async
キーワードを使用することにより、
await
キーワードを使用して他の関数を呼び出すことができます。 関数の実行を一時停止し、対応するプロミスの解決を待つことができます。その後、関数は続行します。 このすべてがまだ明確でない場合は、読み進めてください。徐々にすべてが適切な位置に収まり始めます。
次に
getPic()
関数コードを
getPic()
ましょう。
const browser = await puppeteer.launch();
ここでは
puppeteer
を実行します。 実際、これは、Chromeブラウザーのインスタンスを起動し、作成したばかりの
browser
定数にそのインスタンスへのリンクを書き込むことを意味します。 この行では
await
キーワードが使用され
await
いる
await
、対応するpromiseが解決されるまで、main関数の実行が中断されます。 この場合、これは、Chromeインスタンスが正常に起動するか、エラーが発生するのを待つことを意味します。
const page = await browser.newPage();
ここでは、プログラムコードによって制御されるブラウザで新しいページを作成します。 つまり、この操作を要求し、完了するのを待って、ページへのリンクを
page
定数に書き込み
page
。
await page.goto('https://google.com');
前の行で作成した
page
変数を使用して、指定したURLに移動するコマンドをページに与えることができます。 この例では、
https://google.com
し
https://google.com
。 前の行のように、コードの実行は、操作が完了するまで一時停止します。
await page.screenshot({path: 'google.png'});
ここでは、
puppeteer
、
page
定数で表される現在のページのスクリーンショット
puppeteer
ように依頼し
page
。
screenshot()
メソッドは、パラメーターとしてオブジェクトを受け入れます。 ここで、スクリーンショットを
.png
形式で保存するパスを指定できます。 繰り返しますが、ここでは
await
キーワードが使用され、操作が完了するまで関数が一時停止します。
await browser.close();
getPic()
関数
getPic()
し、ブラウザーを閉じ
getPic()
。
実行例
test.js
保存された上記のコードは、次のようにNodeを使用して実行できます。
node test.js
正常に完了した後は次のようになります。
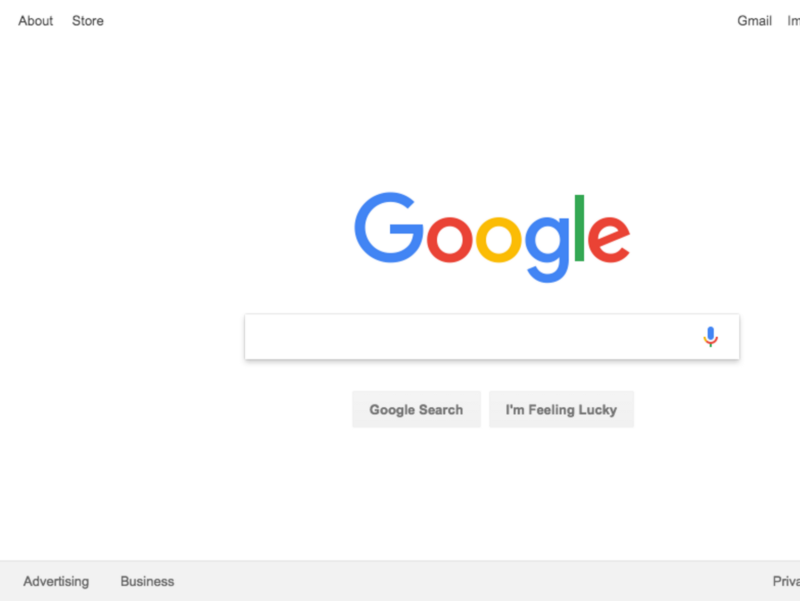
いいね! そして今、それをもっと楽しくするために(そしてデバッグを簡単にするために)、Chromeを通常モードで起動することで同じことをすることができます。
それはどういう意味ですか? 試してみて、自分の目で確かめてください。 これを行うには、次のコード行を置き換えます。
const browser = await puppeteer.launch();
これに:
const browser = await puppeteer.launch({headless: false});
ファイルを保存し、Nodeを使用して再度実行します。
node test.js
いいですね ブラウザの起動時に
{headless: false}
オブジェクトをパラメーターとして
{headless: false}
ことで、コードがGoogle Chromeの動作を制御する方法を観察できます。
先に進む前に、別のことを行います。 プログラムによって作成されたスクリーンショットには、ページの一部のみが含まれていることに気づきましたか? これは、ブラウザウィンドウがWebページのサイズよりわずかに小さいためです。 次の行でこれを修正し、ウィンドウのサイズを変更できます。
await page.setViewport({width: 1000, height: 500})
URLに移動するには、コマンドの直後にコードに追加する必要があります。 これにより、プログラムは非常に見栄えの良いスクリーンショットを撮ります。
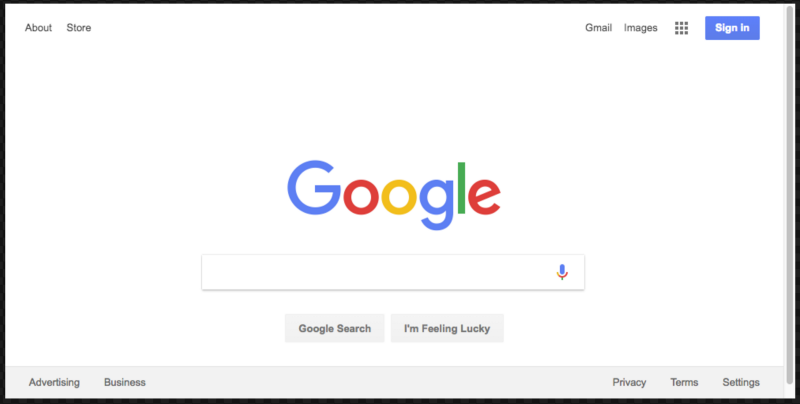
コードの最終バージョンは次のとおりです。
const puppeteer = require('puppeteer'); async function getPic() { const browser = await puppeteer.launch({headless: false}); const page = await browser.newPage(); await page.goto('https://google.com'); await page.setViewport({width: 1000, height: 500}) await page.screenshot({path: 'google.png'}); await browser.close(); } getPic();
例2:ウェブスクレイピング
puppeteerを使用してChrome自動化の基本をマスターしたので、Webページからデータを収集するより洗練された例を見てみましょう。
まず、
puppeteer
ドキュメントを
puppeteer
ください。 ページ要素のマウスクリックをシミュレートするだけでなく、フォームに入力してページからデータを読み取ることができる膨大な数の異なる方法があることに注意してください。
Books To Scrapeからデータを収集します。 これは、Webスクレイピング実験用に作成された電子書店の模造品です。
test.js
ファイルが
test.js
ている同じディレクトリに、
test.js
ファイルを作成し、そこに次の
scrape.js
を貼り付けます。
const puppeteer = require('puppeteer'); let scrape = async () => { // ... // }; scrape().then((value) => { console.log(value); // ! });
理想的には、最初の例を解析した後、このコードがどのように機能するかをすでに理解している必要があります。 しかし、そうでない場合は大丈夫です。
このスニペットでは、以前にインストールした
puppeteer
を接続します。 次に、scrape
scrape()
関数があります。この関数に、以下にスクレイピング用のコードを追加します。 この関数は何らかの値を返します。 そして最後に、
scrape()
関数を呼び出し、それが返すものを操作します。 この場合、単にコンソールに出力します。
scrape()
関数に改行を追加して、このコードを確認します。
let scrape = async () => { return 'test'; };
その後、
node scrape.js
してプログラムを実行し
node scrape.js
。
test
という単語がコンソールに表示されます。 コードの操作性を確認し、コンソールに目的の値を取得しました。 これで、Webスクレイピングを実行できます。
▍ステップ1:セットアップ
まず、ブラウザインスタンスを作成し、新しいページを開いてURLにアクセスする必要があります。 これがすべての方法です。
let scrape = async () => { const browser = await puppeteer.launch({headless: false}); const page = await browser.newPage(); await page.goto('http://books.toscrape.com/'); await page.waitFor(1000); // browser.close(); return result; };
このコードを分析しましょう。
const browser = await puppeteer.launch({headless: false});
この行では、ブラウザーインスタンスを作成し、
headless
パラメーターを
false
設定し
false
。 これにより、何が起こっているのかを観察できます。
const page = await browser.newPage();
ここで、ブラウザに新しいページを作成します。
await page.goto('http://books.toscrape.com/');
http://books.toscrape.com/
ます。
await page.waitFor(1000);
ここでは、ブラウザにページを完全にロードする時間を与えるために1000ミリ秒の遅延を追加しますが、通常、この手順は省略できます。
browser.close(); return result;
ここで、ブラウザを閉じて結果を返します。
準備が完了しました。今度はスクレイピングを取り上げます。
▍ステップ2:スクレイピング
おそらく既にご存知のように、Books To Scrape Webサイトには、条件付きデータを備えた本の大きなカタログがあります。 ページにある最初の本を取り、その名前と価格を返します。 これがサイトのホームページです。 最初の本をクリックします(赤で強調表示されています)。

puppeteer
ドキュメントには、ページ上のマウスクリックをシミュレートできるメソッドがあります。
page.click(selector[, options])
selector <string>
ビューは、クリックする要素を見つけるためのセレクターです。 セレクターを満たす複数の要素が見つかった場合、最初の要素をクリックします。
Google Chrome開発者ツールを使用すると、特定の要素のセレクターを簡単に決定できます。 これを行うには、画像を右クリックして、[
Inspect
コマンド(コードの表示)を選択します。
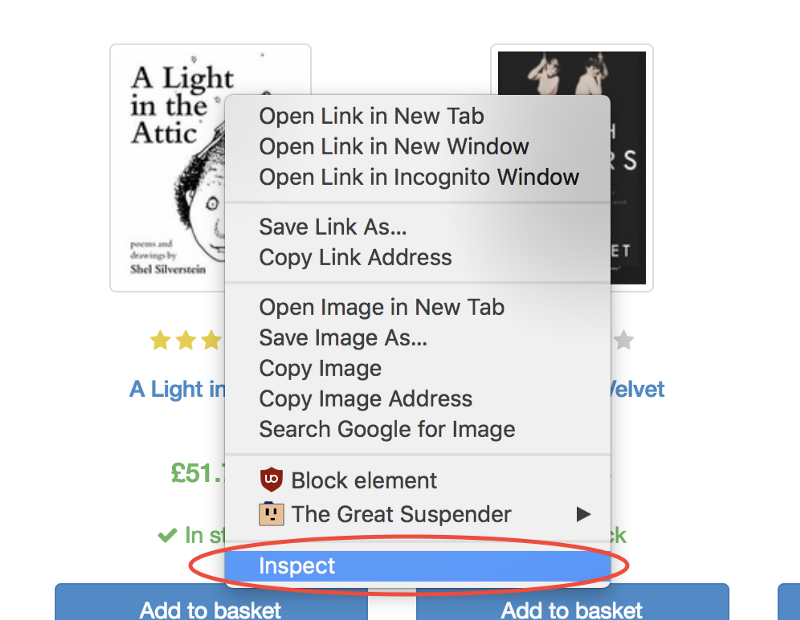
このコマンドは、
Elements
パネルを開きます。このパネルでは、ページのコードが表示され、対象の要素に対応するフラグメントが強調表示されます。 その後、左側にある3つのドットのボタンをクリックして、表示されるメニューから[
Copy → Copy selector
[
Copy → Copy selector
]を
Copy → Copy selector
します。
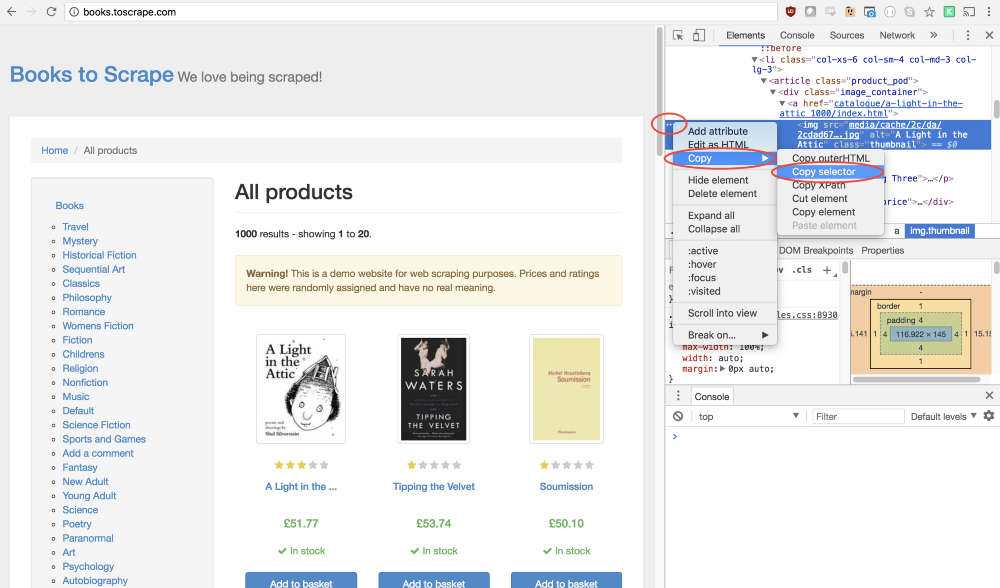
いいね! これでセレクターが作成され、
click
メソッドを作成してプログラムに貼り付ける準備がすべて整いました。 これがどのように見えるかです:
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
これで、プログラムは製品の最初の画像のクリックをシミュレートし、この製品のページが開きます。
この新しいページでは、本の名前とその価格に興味があります。 下の図で強調表示されています。

これらの値を取得するために、
page.evaluate()
メソッドを使用します。 このメソッドを使用すると、
querySelector()
などのJavaScriptメソッドを使用してDOMを操作できます。
まず、
page.evaluate()
メソッドを呼び出し、それによって返される値を
result
定数に割り当てます。
const result = await page.evaluate(() => { // - });
この関数では、必要な要素を選択できます。 必要なものを記述する方法を理解するために、再びChrome開発者ツールを使用します。 これを行うには、ブックの名前を右クリックして、[
Inspect
コマンド(コードの表示)を選択します。
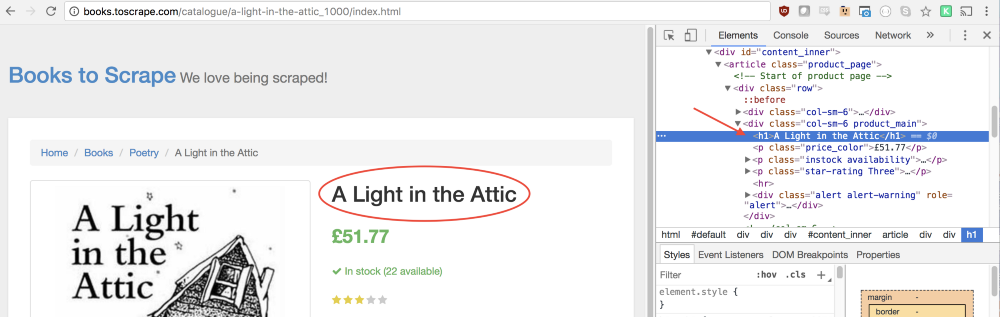
[
Elements
]パネルで、本のタイトルが通常の第1レベルの見出し
h1
であることがわかります。 次のコードを使用して、このアイテムを選択できます。
let title = document.querySelector('h1');
この要素に含まれるテキストが必要なので、
.innerText
プロパティを使用する必要があります。 その結果、次の構造に到達します。
let title = document.querySelector('h1').innerText;
同じアプローチは、ページから本の価格を取得する方法を見つけるのに役立ちます。
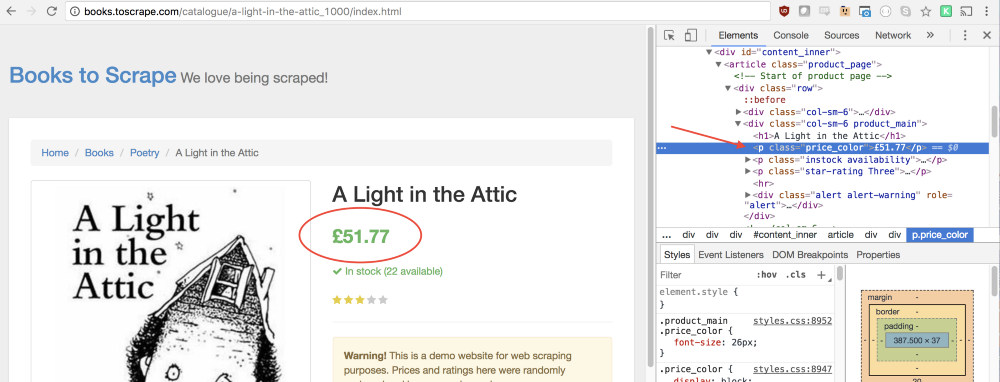
price_color
クラスが価格のある行に対応していることに気付くかもしれません。 このクラスを使用して要素を選択し、それに含まれるテキストを読み取ることができます。
let price = document.querySelector('.price_color').innerText;
ページから本の名前とその価格を引き出したので、関数からこのすべてをオブジェクトとして返すことができます。
return { title, price }
結果は次のコードです。
const result = await page.evaluate(() => { let title = document.querySelector('h1').innerText; let price = document.querySelector('.price_color').innerText; return { title, price } });
ここで、ページから本の名前と価格を読み取り、それらをオブジェクトに保存し、このオブジェクトを返します。これにより、
result
が書き込まれます。
現在は、
result
定数を返し、その内容をコンソールに表示するだけです。
return result;
この例の完全なコードは次のようになります。
const puppeteer = require('puppeteer'); let scrape = async () => { const browser = await puppeteer.launch({headless: false}); const page = await browser.newPage(); await page.goto('http://books.toscrape.com/'); await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img'); await page.waitFor(1000); const result = await page.evaluate(() => { let title = document.querySelector('h1').innerText; let price = document.querySelector('.price_color').innerText; return { title, price } }); browser.close(); return result; }; scrape().then((value) => { console.log(value); // ! });
これで、Nodeを使用してプログラムを実行できます。
node scrape.js
すべてが正しく行われると、本の名前とその価格がコンソールに表示されます。
{ title: 'A Light in the Attic', price: '£51.77' }
実際、これはすべてWebスクレイピングであり、このレッスンの最初のステップを踏んだだけです。
例3:プログラムの改善
ここには、かなり合理的な質問があります。「本の名前と価格の両方がホームページに表示されている場合、なぜ本のページにつながるリンクをクリックしますか? そこからまっすぐに連れて行ってみませんか? そして、これができたら、すべての本の名前と価格を読んでみませんか?」
これらの質問に対する答えは、Webスクレイピングには多くのアプローチがあるということです。 さらに、ホームページに表示されるデータに制限すると、書籍の名前が短くなるという事実に遭遇する場合があります。 しかし、これらすべての考えはあなたに練習する絶好の機会を与えてくれます。
▍タスク
あなたの目標は、すべての本のタイトルとその価格をホームページから読み、それらをオブジェクトの配列として返すことです。 ここに私が得た配列があります:

続行できます。 さらに読むことはせず、すべて自分でやるようにしてください。 この問題は、先ほど解決した問題と非常に似ていると言わなければなりません。
うまくいきましたか? そうでない場合は、ここにヒントがあります。
ヒント
このタスクと前の例の主な違いは、ここでデータのリストを調べる必要があることです。 方法は次のとおりです。
const result = await page.evaluate(() => { let data = []; // let elements = document.querySelectorAll('xxx'); // // // // data.push({title, price}); // return data; // });
今でも問題を解決できない場合は、心配する必要はありません。 これは練習問題です。 考えられる解決策の1つを次に示します。
▍問題を解決する
const puppeteer = require('puppeteer'); let scrape = async () => { const browser = await puppeteer.launch({headless: false}); const page = await browser.newPage(); await page.goto('http://books.toscrape.com/'); const result = await page.evaluate(() => { let data = []; // let elements = document.querySelectorAll('.product_pod'); // for (var element of elements){ // let title = element.childNodes[5].innerText; // let price = element.childNodes[7].children[0].innerText; // data.push({title, price}); // } return data; // }); browser.close(); return result; // }; scrape().then((value) => { console.log(value); // ! });
まとめ
この記事では、Google ChromeブラウザーとPuppeteerライブラリーを使用してWebスクレイピングシステムを作成する方法を学びました。 つまり、コードの構造、ブラウザをプログラムで制御する方法、スクリーンコピーを作成する方法、ページでのユーザーの作業をシミュレートする方法、およびWebページに投稿されたデータを読み取って保存する方法を検討しました。 これがWebスクレイピングの最初の知り合いである場合、インターネットから必要なものすべてを入手するために必要なものがすべて揃っていることを願っています。
親愛なる読者! ユーザーインターフェイスなしでPuppeteerライブラリとGoogle Chromeブラウザーを使用していますか?