私の名前はEvgeny Zhirovです。インフラストラクチャチームKontur.Ekternaの開発者です 。 この投稿は、最近のPerm Tech Talks mitapからの私のレポートのテキスト版です。
私たちのチームには200のマイクロサービスがあり、ユーザーが問題に気付かないようにフォールトトレラントでなければなりません。 しかし、もちろん問題が発生します。 したがって、特定のサービスおよびシステム全体の状況を把握するために、メトリックを収集します。 メトリックは、時間内に反応し、すべてを修正するのに役立ちます。
メトリックは収集、保存、視覚化できます。 そして、メトリクスを誤って収集し、エラーを引き寄せ、間違った結論を引き出す多くの方法があります。
私は私の仕事からいくつかの例について話し、ヒントを共有します。
指標は何ですか?
Requests.count.byhostメトリック*
定量的指標。 任意のWebサービスの最も単純なメトリックは、単位時間あたりにそこに飛び込むリクエストの数です。 このメトリックは通常、RPS(1秒あたりの要求数)と呼ばれます。
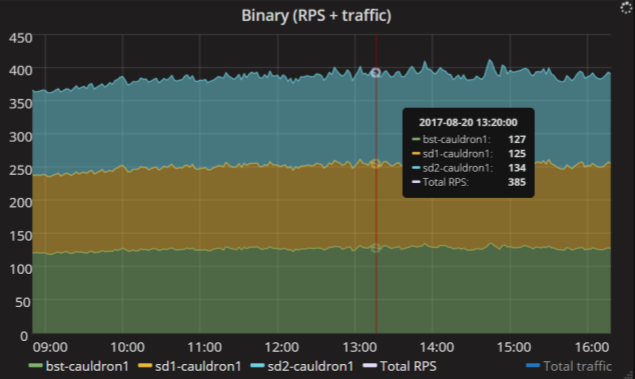
以下に例を示します。 このサービスには3つのレプリカがあり、1秒あたり合計で約400のリクエストがレプリカに入力されます。 このグラフは非常に単純ですが、多くの情報を提供します。 負荷はサービスレプリカ全体に均等に分散されており、各レプリカはほぼ同数のリクエストを受信していることがわかります。 だから、すべてがバランサーの設定で整然としています。
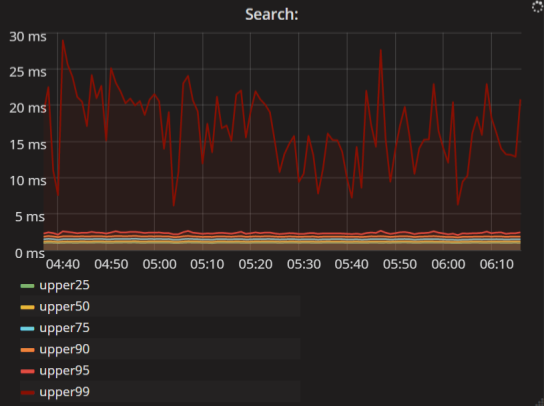
時間間隔。 これらは、より興味深い指標です。 通常、パーセンタイルで表示されます。 たとえば、このグラフは次のように表示されます。検索クエリの99%は25ミリ秒より高速です。 リクエストの95%は3ミリ秒よりも高速です。
メトリックclient.requests.search.latency。*
システムメトリック。 これは別個のメトリッククラスです。 これらはアプリケーション自体とは関係ありませんが、使用するリソースの状態を診断できます。

メトリックsystem.loadavg。*
Cassandraクラスターの1つのメトリックのグラフで、負荷平均値をプロセッサーコアの数で割った値。 これらを使用して、クラスターがCPUでサグするかどうか、および鉄を追加するかどうかを決定できます。 ここで、現在の値は約12%であり、CPUは十分であることがわかります。
負荷プロファイルもグラフに表示されます。 ここは昼、夜、再び昼間の活動のピークであり、夕方に向かって減少しています。 アプリケーションの負荷がピークになる時期を知ることが重要です。 多くの場合、アプリケーションが平均してロードされず、10,000件のリクエストが到着し、すべてが遅くなります。
メトリックが必要な理由
指標は私たちの「目」です。 メトリックがなければ、アプリケーションの負荷、パフォーマンス、およびフォールトトレランスを判断することはできません。
- 問題にすばやく対応できます。 通知は各チャートでハングアップし、値が所定のしきい値を超えると、通知が届きます。
- クラスターが負荷にどのように対処するかを監視し、適時に鉄を追加できます。
- リリース前後のアプリケーションパフォーマンスのグラフを比較できます。
メトリックの収集を開始する方法は?
.NETで作成するとします。 インターネットで「.NETアプリのメトリック」を検索し、 Metrics.NETやApp Metricsなどの多くのオープンソースライブラリを取得します。 アプリケーションメトリックの収集に役立ちます。
収集したメトリックを保存するには、データベースが必要です。 そして、グラフを描くために-メトリックを視覚化するためのインターフェース。 Contourでは、従来のGraphiteとGrafanaを使用しています。
すべてをセットアップし、アプリケーションをデプロイしますが、いったん失敗したことに気付いたら。 たとえば、彼らは故障を予測できませんでした。 または、収集した数字の意味がわからないだけです。 これが私の仕事の例です。
例1.貨物のプログラミング
すべてのストーリーは同じ方法で始まります。 午前2時頃、私は仕事に来ます。 グラフを見ると、突然お気に入りのサービスのエラーが表示されます。

巨大なピーク! そうではないが。 垂直軸に沿ったピークの高さは、1分あたりわずか4×10 –17エラーです。 同時に、すべてがサービスで正常に動作し、ログはクリーンです。 私は理解し始めています。

15時間前にサービスで何が起こったのかを確認します。 ここでは、ピークが大きくなり、値がより適切になります。 しかし、どのメトリックスがチャートに表示されますか? 1分あたりのエラー。 考えてみてください:1分あたり0.4エラー。 アプリケーションは毎分エラーの数を送信するため、これは少し奇妙です。 0、1、2、または100の整数でなければなりませんが、0.4ではありません。 ここで何かが間違っています。 最初の会議で奇妙なことがしばしば起こるので、私はそれを無視することにしました。 私はコードを書き続けます。
確かに、この問題は他のチャートを手放すことなく追求します。

以下は、Cassandraでの読み取り時間と書き込み時間のグラフです。 青い線は、データベースへの書き込みエラーを示します。 これらのメトリックを送信するのは私のコードでさえありませんが、Cassandra自体です。 10:10にエラーが開始し、10:35に終了したことがわかります。 25分間のCassandra全体が機能しませんでした。
また、実際に問題が発生したのは何分ですか? クライアントメトリック、つまりこのデータベースに書き込むサービスのメトリックは次のとおりです。 まったく異なる状況:1分で5万件のレコードが失敗し、すべてが再び正常になりました。

2回目、3回目、4回目に何かが起こった場合、何が起こっているのかを理解する時が来ました。 これを行う最も簡単な方法は何ですか? ラボでの実験が必要です。 スレッドセーフなイベントの数をカウントする単純なカウンターを作成し、値を無限ループでGraphiteに送信し、1分間スリープします。
class Counter { private long value; public void Add(long amount) { Interlocked.Add(ref value, amount); } public void Start() { while (true) { var result = Interlocked.Exchange(ref value, 0); SaveToStorage(result); Thread.Sleep(1000 * 60); } } }
2つのテストを作成しています。 1つは、わかりやすい方法で機能するカウンターを使用する方法です。 別の方法では、人気のあるライブラリのカウンターを使用します。 私の場合、これはMetrics.NETのMeterであり、同様のインターフェースを備えています。
負荷はいくらですか? 2分を10 RPSとし、10秒間-100 RPSとし、再度10 RPSを2分間とします。 スケジュールは次のとおりです。

緑色の線は、サービスで実際に起こったことです。 そして、黄色は人気のあるライブラリが提供するものです。 あまり似ていません。
ここで何が起こっていますか? 指数平滑法 。
別の例を示します。 メトリックの実際の値については、以前のすべてのポイントの加重加算により54が取得されます54。 係数は指数関数的に減少し、奇妙な平滑化された値を取得します。
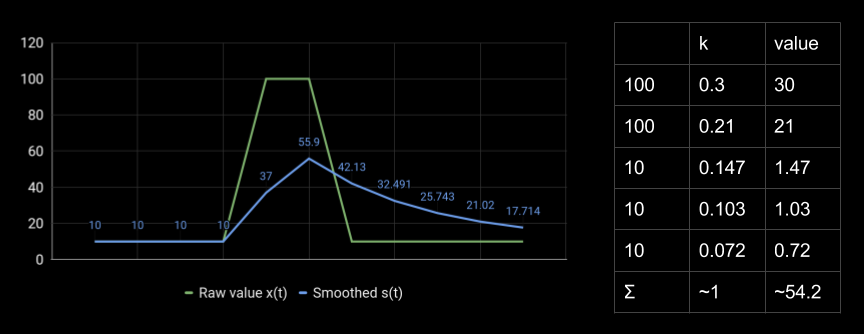
1秒あたりのリクエスト数または1分あたりのエラー数を測定したいのですが、奇妙な値が得られます。 この動作が、.NETおよびJavaのメトリックを収集するための多くの一般的なライブラリにあることは残念です。 変更は非常に困難です。
その理由は何ですか? 開発者が特定のテクノロジーを使用したり、特定の方法でコードを記述したりするとき、祖父がやったので、それは貨物プログラミングだと思います。 元の理由は忘れられていますが、誰もがそうしているので、誰もがそうし続けています。
Webサービスメトリックを計算するとき、指数平滑法は邪魔になります。 正確な値を見ることができず、ピークに位置し、テールが長くなり、誤ったアラートが発生します。 これは実際の負荷プロファイルを隠します。1つのピークの代わりに、まったく異なる数値が表示され、さらに15時間消えるからです。
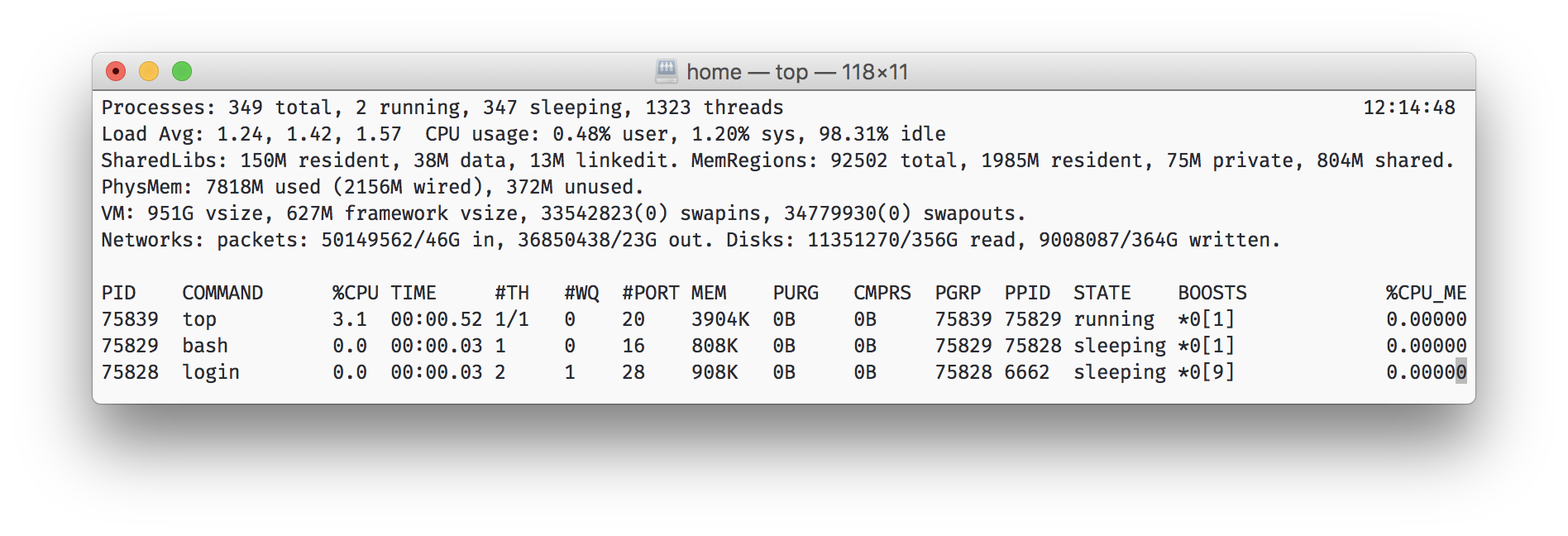
きっとあなたの多くは* nixのトップユーティリティを見たことがあるでしょう。 同様の方法で平滑化された3つの負荷平均値(1分、5分、15分間)を示します。 それらから正確な値を判断することはできませんが、傾向ははっきりと見えます。 たとえば、15分でプロセッサの負荷が大幅に増加したことがわかります。 ここでは、ノイズの多いメトリックがスムーズに変化し、0から100までハングしないため、スムージングが役立ちます。
例2.統合
メトリックの視覚化にはまだ問題があります。

私は仕事に戻り、チャートを見てください。 検索時間の95パーセンタイルです。 午前中に検索が遅くなったことがわかります。いずれかのポイントで550ミリ秒、他のピークがあります。 たぶんこれはサービスの通常の動作ですか? スケールを変更し、そのようなピークが1週間にいくつあったかを確認する必要があります。
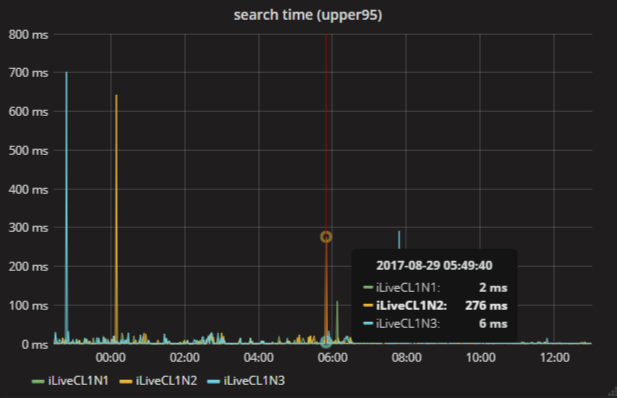
ここにも多くのピークがあります。 しかし、午前6時にその意味が変わりました! 現在276ミリ秒。 これはどのようにできますか?
ポイントマージ戦略の理由は、グラファイトで統合することです。 時間スケールを変更し、すべてのポイントが画面に収まらない場合、Graphiteは選択した機能を使用してそれらを結合します。 それらは異なりますが、デフォルトではこれは平均であり、このチャートには適していません。 通常、パーセンタイルの場合、最大値に関心があり、場合によっては金額を取得することもあります。
ポイントの統合を忘れたり、間違った関数を選択したり、デフォルトの関数を残したりすると、グラフから間違った結論を導き出すのは簡単です。
例3.グラフの嘘
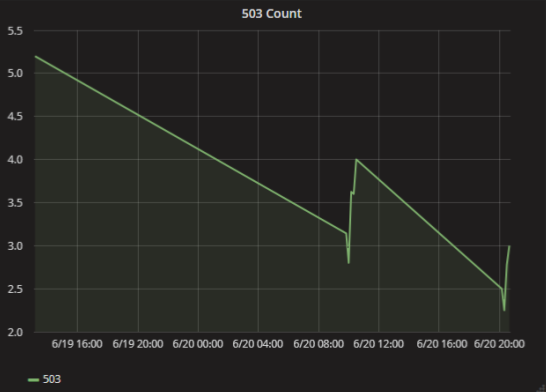
再び仕事に来て、スケジュールを開きますが、すべてが完全に悪いです。 すでに1日、サービスは毎分503エラーを安定して返します。 ここに問題がありますか? それは非常にシンプルで面白いです:単にレンダリングするのに十分なデータがありません。
Graphiteには、ある時点でデータがなかった場合にグラフ上のポイントを接続する方法に関する設定があります。 考えずに選んだ場合、間違った結論を導き出すのは簡単です。 実際、いくつかのケースでわずかなエラーがありました。

どうする エラーがなかった場合はメトリックにゼロを書き込むか、別のタイプのチャート(棒など)を使用します。
例4.メトリックの物理的な意味
アプリケーションは、作業中にRAMを使用することが知られています。 アプリケーションが大量のメモリを割り当て、それ以上割り当てることができない場合、奇妙なエラーでクラッシュし始めます。
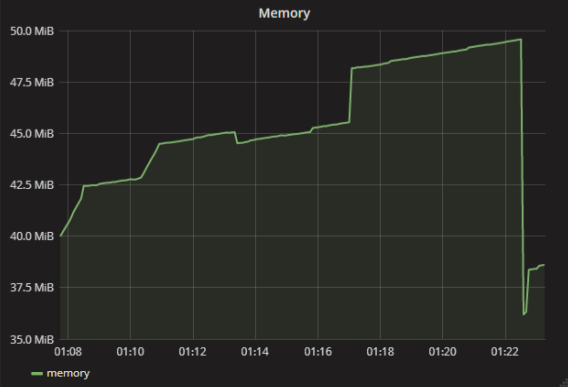
私の場合、アプリケーションの1つがアクセス違反のためにクラッシュし始めました。 その理由は正確にはメモリ不足であることに気づきましたが、メトリックスではすべて問題ありませんでした-40 MBで十分だと思います。
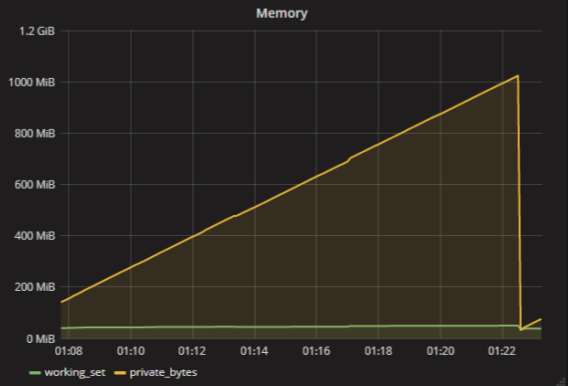
実際、もちろん、そのような測定基準はありません-「アプリケーションが使用するメモリ量」。 RAMには多くのメトリックがあります。 たとえば、Windows上のすべてのプロセスには、 ワーキングセットとプライベートバイトがあります 。 おおよその場合、ワーキングセットは使用済みの物理メモリの量であり、プライベートバイトはアプリケーションが割り当てたメモリの量です。 アプリケーションのスワップファイルには大量のデータが含まれる場合がありますが、物理メモリにはほとんど何も含まれません。 アプリケーションは悪くなり、バラバラになります。
「メモリ」や「プロセッサ負荷」などの単純なメトリックは存在しないことに注意してください。 より多くのメトリックがあり、それらはすべて特定の何かを意味します。
結論
- 測定対象を理解する必要があります。 「メモリ」を単純に測定する場合、取得された値は実質的に何も意味しません。
- ツールの仕組みを理解する必要があります。 たとえば、メトリックを収集するライブラリは指数平滑化を行い、データベースは何らかのアルゴリズムを使用してポイントを統合することを忘れないでください。
- メトリックが他のデータ(ログなど)または観測されたシステムの動作に対応していない場合は、それについて考える必要があります。 通り過ぎることはできません。 矛盾を説明できない場合、結果のメトリックは役に立たない。
メトリックをどのように収集して視覚化しますか? メトリックの収集と表示に関してどのような困難がありましたか?