
(これは抽象的なアーティストの写真ではなく、LiveJournalデータセットの鳥瞰図です)
変更を加えたt-SNE
t-SNEは約10年前のものですが、時間までにすでにテストされていると安全に言うことができます。 データ科学のベテランの支持者の間だけでなく、人気のある科学論文の著者の間でも人気があります。 彼についてはすでにHabréで書いています。 この視覚化アルゴリズムについても、インターネットには多くの 優れた記事があります。
ただし、これらの記事のほとんどすべてが標準 t-SNEについて説明しています。 彼に簡単に思い出させてください:
- ペアごとにデータポイントのペアをカウントします x i 、x j i n X ガウスカーネルを使用したソース空間での相互の類似性:
pj|i= frac exp(− left |xi−xj right |2/(2 sigma2i) sumk neqi( exp(−\左 |xi−xk\右 |/(2\シグマ2i))
pij= fracpj|i+pi|j2
- 表示ポイントの各ペアについて、t分布カーネルを使用して視覚化空間での類似性を表現します
qij= frac(1+ left |yi−yj right |2)−1 sumk neqm(1+ left |yk−ym right |2)−1
- 目的関数を作成し、比較的最小化する y 勾配降下法を使用する
C(y)= KL(P || Q)= \ sum_ {i \ neq j} {p_ {ij} \ log {\ frac {p_ {ij}} {q_ {ij}}}
C(y)= KL(P || Q)= \ sum_ {i \ neq j} {p_ {ij} \ log {\ frac {p_ {ij}} {q_ {ij}}}
どこで KL(P||Q) -カルバック・ライブラーの発散。
3次元の場合、直感的に次のように表現できます。 ありますか N ビリヤードボール。 あなたはそれらにラベルを付け、天井からの糸でそれらを掛けます。 さまざまなサイズのスレッド。したがって、部屋の3次元空間でデータセットがハングします。 N との要素 d=3 。 ボールの各ペアを理想的なスプリングに接続して、スプリングが必要な長さになるようにします(たるみがなく、伸びません)。 スプリングの剛性は次のように選択されます。ボールの隣に他のボールがない場合、すべてのスプリングは多少弱くなります。 ちょうど1つのボールが隣人であり、他のすべてが遠くにある場合、この隣人は非常に硬いバネを持ち、他のすべては弱いバネを持ちます。 隣人が2人いる場合、隣人(前の場合よりも弱い)、および他のすべての人(さらに弱い)に強いスプリングがあります。 などなど。
次に、結果のデザインを取り、テーブルに配置してみます。 3次元オブジェクトが自由に移動するノードで構成されている場合でも、一般的に平面に配置することはできません(四面体をテーブルに保持する方法を想像してください)。したがって、スプリングの張力または張力ができるだけ小さくなるように単純に配置します。 2次元空間では、各ボールの最近傍は少なくなりますが、平均距離ではより多くの近傍になるという事実を修正することを忘れないでください(3乗法則を思い出してください)。 ほとんどのスプリングは非常に弱いため、まったく考慮に入れることはできませんが、強いスプリングで接続された要素は並べて配置するのが最適です。 任意の初期構成から少しずつ移動し、ゆっくりとバネの張力を減らします。 スプリングの元の張力を現在の張力から元に戻すことができれば、それだけ良くなります。
(最初のばね張力がゼロであることを知っていることを少し忘れました)
(これらは互いに通過する魔法のボールとスプリングであることを言及しましたか?)
(なぜそのようなナンセンスに悩むのか?-読者への演習として残された)
そのため、最新のデータサイエンスパッケージでは実際にこれを実装していません。 標準のt-SNEには複雑さがあります O(N2) 。 最近の研究の結果、これは冗長であり、ほぼ同じ結果が達成できることが判明しました O(N logN) 操作。
最初に、最初のステップですべてを検討します pij 明らかに冗長なようです。 それらのほとんどはまだゼロです。 この数を制限します。各データインスタンスのk最近傍を見つけ、計算します pij 正直なところ、彼らだけに。 残りはゼロにします。 したがって、これらの要素についてのみ、対応する式の分母の合計を考慮します。 問題は、この数の隣人を正確に選択する方法ですか? それに対する答えは驚くほど簡単です:アルゴリズムのグローバル構造とローカル構造の間の関係を担当するパラメーターが既にあります- u 、困惑! その特性値の範囲は5〜50で、データセットが多いほど、複雑さが増します。 必要なものだけ。 VPツリーを使用すると、あたりの十分な数のネイバーを見つけることができます O(uN logN) 時間。 スプリングとの類推を続けると、これはすべてのボールをペアで接続する方法ではなく、ボールごとに、スプリングをたとえば5つの最も近い隣に吊るす方法です。
第二に...
バーンズハットアルゴリズム
Barnes-Hutについて説明するために少し脱線しましょう。 このアルゴリズムについては、Habréに関する別の記事はありませんでしたが、ここではそれを伝える絶好の機会です。
おそらく、誰もがN体の古典的な重力問題を知っています:与えられた質量とNの宇宙体の初期座標、およびそれらの相互作用のよく知られた法則から、その後のすべての瞬間におけるオブジェクトの座標を示す関数を構築します その解は、通常の代数関数では表現されませんが、たとえば、 ルンゲクッタ法を使用して数値的にのみ見つけることができます。 残念ながら、微分方程式を解くためのそのような数値的手法には複雑さがあります O(N2) 、そして最新のコンピューター上でも、オブジェクトの数が 105−106 。
このような膨大な数のボディを使用したシミュレーションでは、いくつかの単純化を行う必要があります。 ボディA、B、Cのトリプルの場合、BとCの側面からAに作用する力の合計は、BとCの質量の中心に置かれた単一のボディ(BC)が及ぼす力に等しいことに注意してください。それだけでは最適化には不十分です。もう一つのトリック。 スペースをセルに分割します。 ボディAからセルまでの距離が大きく、セル内に複数のボディがある場合、内部にオブジェクトの総質量があるオブジェクトがこのセルの中心に正確に配置されると想定します。 その位置は、セルの内容の実際の重心からわずかに逸脱しますが、セルが遠ければ遠いほど、力の作用角の誤差はより重要ではなくなります。
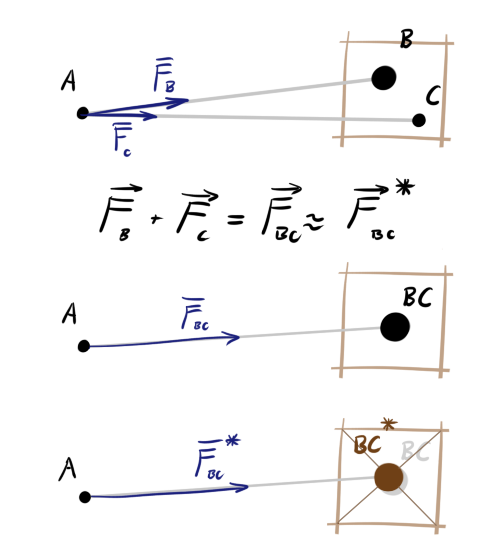
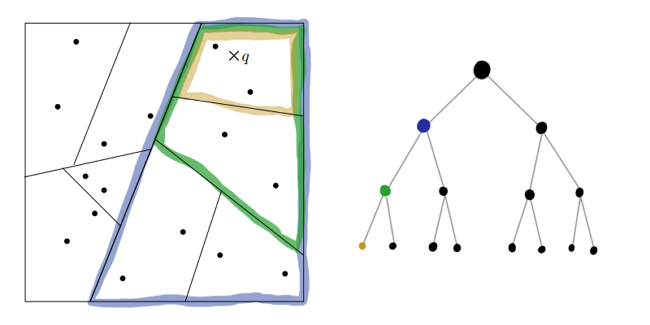
以下の図では、緑は体Aの近接領域を示しています。青は力の作用方向を示しています。 体B、C、およびDはAに個別に力を加えます。 CとDは同じセルにありますが、精度の領域にあります。 Eはまた、単独で力を発揮します-それはセル内のものです。 しかし、オブジェクトF、G、およびHは、Aから十分に離れており、相互作用をより近づけることができるほど十分に近接しています。 セルの中心は、実際の重心の位置と常に一致するとは限りません(K、L、M、Nを参照)が、平均して、距離が長く、多数の物体がある場合、エラーは無視できます。
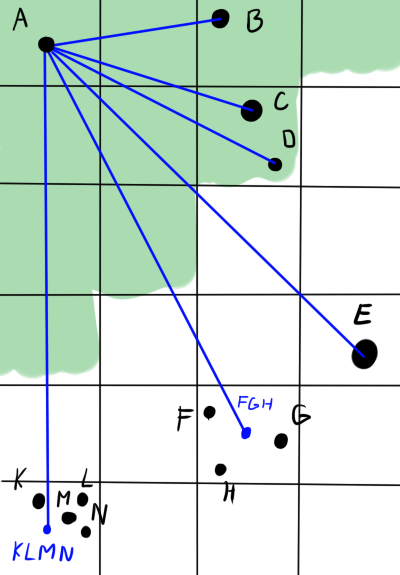
改善されました。オブジェクトの有効数を数倍減らしました。 しかし、最適なパーティションサイズを選択する方法は? パーティションが小さすぎると意味がなくなり、大きすぎるとエラーが増加し、精度を犠牲にする準備ができる非常に大きな距離を置く必要があります。 次のステップに進みましょう。固定ステップのグリッドではなく、平面の長方形をセルの階層に分割します 。 大きなセルには小さなセル、さらに小さなセルなどが含まれます。 結果のデータ構造はツリーであり、各非リーフノードは4つの子ノードを生成します。 この設計は「 クアッドツリー 」と呼ばれます。 3次元の場合は、それぞれオクトツリーが使用されます。 これで、特定の物体に作用する力を計算するときに、十分なレベルの細かさを持つセルが一致するまでツリーを一周し、近似を使用することができます。
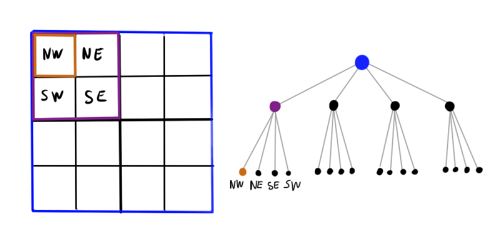
単一のオブジェクトに該当しないノードは、さらに先に進むのが理にかなっているため、この構造は一見すると重くありません。 一方、オーバーヘッドが確実に存在するため、シミュレートされたオブジェクトは100未満ですが、このようなunningなデータ構造は(実装によっては)わずかに有害になる可能性があります。
より正式になりました:
アルゴリズム1:
させる d -身体から問題の細胞の中心までの距離、 s このセルの側面です \シータ -細かさの事前定義されたしきい値。 オブジェクトに加えられた力を判断するには b 、ルートから始めて、クワッドツリーを一周します。
- 現在のセルに要素がない場合は、スキップします
- それ以外の場合、ノードに要素が1つしかなく、そうでない場合 b 、直接その効果を総強度に追加します
- そうでなければ、 s/d leq theta 、このノードを単一のオブジェクト全体と見なし、上記のようにその合計強度を追加します
- それ以外の場合は、現在のセルのすべての娘セルに対してこの手順を再帰的に実行します。
アルゴリズムのより詳細な実装を段階的に示します。 銀河シミュレーションの美しいBarnes-Hut アニメーション 。 さまざまなBarnes-Hut実装がgithubにあります。
明らかに、このような興味深いアイデアは、科学の他の分野では見過ごされることはありませんでした。 Barnes-Hutは、多数のオブジェクトを備えたシステムが存在するすべての場所で使用されます。各システムは、空間であまり変化しない単純な法則(群れシミュレーション、コンピューターゲーム)に従って他のオブジェクトに作用します。 したがって、データ分析も例外ではありませんでした。 t-SNEの勾配降下(3)のステップをさらに詳しく説明します。
frac deltaC deltay=4 sumj neqi(pij−qij)qijZ(yi−yj)
=4( sumj neqipijqijZ(yi−yj)− sumj neqiq2ijZ(yi−yj))
=4(Fattr+Frep)
どこで Fattr 誘引力が示されています Freq -反発、および Z 正規化要因です。 以前の最適化のおかげで Fattr と考えられる O(uN) でも Freq -まだ O(N2) 。 ここで、上記のクアッドツリートリックとBarens-Hutが役立ちますが、ニュートンの法則ではなく、 F=q2ijZ(yi−yj) 。 この単純化により、計算が可能になります Freq のために O(N logN) 平均して。 欠点は明らかです:スペースの離散化によるエラー。 上記の記事のローレンス・ファン・デル・マーテンは、それらがまったく制限されているかどうかさえ明確ではないと主張しています(関連記事へのリンクが提供されています)。 それはそうかもしれませんが、通常選択されたBarens-Hut t-SNEを使用して得られた結果 \シータ 一貫して見える。 あなたは通常置くことができます theta=0.25 または 0.1 そして彼のことを忘れます。
さらに高速ですか? はい 状況をさらに簡素化できる場合、ポイントツーセル近似で停止する理由:2つのセルが十分に離れている場合、最終的な近似だけでなく近似もできます y 、ただし最初のもの(「セル間」近似)。 これは、デュアルツリーアルゴリズムと呼ばれます(ロシア語の名前はまだありません)。 各データインスタンスに対して上記の再帰を開始しませんが、クアッドツリーをバイパスし始め、細かさが目的の値に達すると、同じクアッドツリーをバイパスし、2番目のラウンドセルからの合計力を最初のラウンドの選択されたセル内の各インスタンスに適用します。 このアプローチを使用すると、もう少し速度を絞ることができますが、エラーがはるかに速く蓄積し始め、より小さく設定する必要があります \シータ 。 はい、そのような迂回はどこでもそれほど実装されていません。
LargeVis
良いのですが、もっと速くできますか? Jian Tangと会社、はい答えてください!
正確さを犠牲にしたら、
RTツリー
クワッドツリーを使用して平面を分割するという考えは悪くありませんでした。 それでは、もっと簡単な方法で飛行機をセクターに分割してみましょう。 kdツリーはどうですか?
アルゴリズム2:
パラメータ: M -最小サイズ X -データセット
MakeTree( X )
- もし |X| leqM 戻り電流 X 葉ノードのような
- そうでなければ
- 変数をランダムに選択する i in[0、d−1]
- ルール(x):= xj leq 中央値( zi:X$のzi )//座標軸に垂直な超平面でデータ部分空間を分割する述語 i 値の中央値を通過する i この要素変数 X 。
- LeftTree:= MakeTree({x in X:ルール(x)= true})
- RightTree:= MakeTree({x in X:ルール(x)= false})
- [Rule、LeftTree、RightTree]を返します
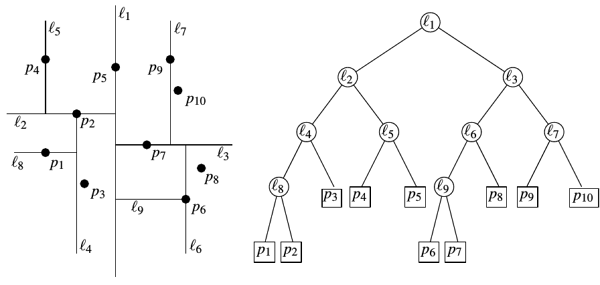
どういうわけか原始的すぎる。 ある座標軸の分割面の垂直性が疑わしいように見えます。 より高度なバージョンがあります:ランダム投影ツリー(RTツリー)。 空間を再帰的に分割し、ランダムな単位ベクトルを選択するたびに、平面はそれに垂直になります。 ツリーのわずかな非対称性のために、プレーンのアンカーポイントに少しのノイズも追加します。
アルゴリズム3:
ChooseRule(X)//スペースを分割するための述語を返すメタ関数
- ランダムな単位ベクトルを選択します v in mathcalRd
- ランダムに選択

- させる
 -それから最も遠いデータポイント X
-それから最も遠いデータポイント X - \デルタ :=乱数 [−6 cdot left |y−z right |/ sqrtd、6 cdot left |y−z right |/ sqrtd]
- リターンルール(x):= x cdotv leq (中央値( z cdotv:z inX )+ \デルタ )
MakeRPTree( X )
- もし |X| leqM 戻り電流 X 葉ノードのような
- そうでなければ
- ルール(x):= ChooseRule(X)
- LeftTree:= MakeTree({x in X:ルール(x)= true})
- RightTree:= MakeTree({x in X:ルール(x)= false})
- [Rule、LeftTree、RightTree]を返します
このようなラフで混andとしたパーティションは、少なくともいくつかの結果をもたらすことができますか? はい、そうです! 多次元データが実際にはあまり多次元ではないハイパーフォールディングの近くにある場合、RTツリーはかなりまともな振る舞いをします(最初のリンクの証明とこちらをご覧ください )。 データに有効なディメンションがある場合でも d 、投影に関する知識には多くの情報が含まれています。
うーん、複雑さ:中央値の計算はまだです O(|X|) そして、私たちはそれぞれでそれを行います O( logN) ステップ。 超平面の選択をさらに簡素化します。通常、アンカーポイントを放棄します。 再帰の各ステップで、次から2つのランダムポイントを選択するだけです。 X それらから等間隔に平面を描きます。
少なくとも何らかの形で数学的厳密性または正確性を思い出させるすべてのものをアルゴリズムから除外したようです。 結果のツリーは、最近傍を見つけるのにどのように役立ちますか? 明らかに、グラフシート上のデータポイントの近傍は、kNNの最初の候補です。 しかし、これは正確ではありません。ポイントがパーティションの超平面の隣にある場合、実際の隣人は完全に異なるシートに表示される可能性があります。 複数のRPツリーを構築すると、結果の近似値を改善できます。 それぞれの結果のグラフのシートの交差点 x 検索するのに適したエリアです。
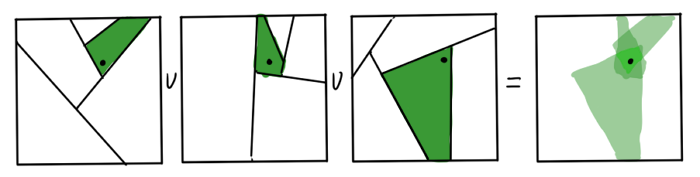
木はあまり必要ありません、それは速度を損ないます。 結果の近似は、「私の隣人の隣人は私の隣人である可能性が高い」というヒューリスティックを使用して思い起こされます。 適切な結果を得るには、かなりの数の反復で十分であると主張されています。
この記事の著者は、このすべての効果的な実装が O(N) 時間。 ただし、彼らが言及していないことが1つあります。O-bigは影響を受ける巨大な定数を飲み込みます M 、RPツリーの数、およびヒューリスティックチューニングの段階数。
サンプリング
kNNを計算した後、Jian TangとKOは、t-SNEと同じ式を使用してソース空間のデータの類似度を計算します。
pj|i= frac exp(− left |xi−xj right |2/(2 sigma2i) sum(i、k) inNeigh( exp(−\左 |xi−xk\右 |/(2\シグマ2i))
pij= fracpj|i+pi|j2
分母の金額はkNNによってのみ考慮され、残りは pj|i 0に等しい; また pii=0 。
その後、cな理論的操作が提案されます。今、私たちは受け取った wij equivpij 、ノードが要素であるグラフのエッジの重みのように X 。 セットを使用して、このグラフの重みに関する情報をエンコードします y 展示スペース。 バイナリの重みのないエッジを観測する確率をみましょう eij 等しい
P( existseij)= frac11+\左 |yk−ym\右 |
t分布は、わずかに異なる方法でのみ再び使用されます。 異なる空間を持つ異なるレイヤーの異なる数の隣人についてまだ覚えている d 。 ソースグラフに次の重みを持つエッジがある確率 wij :
P(\存在するwij)=P(\存在するeij)wij
すべてのエッジの確率を乗算し、位置を取得します y 最尤法:
O= prod(i、j) inEP( existseij)wij prod(i、j) in vecE(1−P( existseij) gamma
どこで vecE -最近傍のリストにないすべてのペアのセット、および \ガンマ -存在しないエッジの影響を示すハイパーパラメーター。 対数:
logO propto sum(i、j) inEwij logP( existseij)+ sum(i、j) in vecE gamma loG ( 1 - P ( E X I 、S 、T 、S 、E 、I 、J)) \右矢印 M X
再び、彼らは2つの部分からなる合計を受け取りました:1つはお互いを引き付けます y 互いに近い x 他の反発 y 、 x お互いの隣人ではなく、見た目が違うだけです。 また、2番目の合計の正確な計算には時間がかかるという問題もありました。 O (N 2 ) 、グラフに不足しているアークがたくさんあるためです。 今回は、クアッドツリーを使用する代わりに、アークのないグラフのノードをサンプリングすることを提案します 。 このトリックは 、機械ワードプロセッシングから生まれました。 各単語のコンテキストをより速く理解するためにあります j それは単語の隣のテキストに立っています 私は 、辞書にある次の単語をすべて取得しないでください 私は 発生することはありませんが、頻度の3/4に比例する確率で、少数の任意の単語のみ(3/4インジケータは経験的に選択されます。詳細はこちら )。 各ノード用です j そこから端がある 私は 重量で w i j 、エッジのない任意のノードをサンプリングします。これらのノードから発生するアークの数の度合いの3/4に比例します。
\ log {O} \およそ\ sum _ {(i、j)\ in E} {w_ {ij}(\ log {P(\ exists e_ {ij})}} + \ sum_ {k = 1} ^ M {E_ {j_k \ sim P_n(j)} \ gamma \ log {(1-P(\が存在するe_ {ij_k}))}}}右矢印印\ max
どこで M ノードごとの負のエッジの数、および P N ( J )、S 、I 、M個のD 3 / 4 J 。
以来 w i j 勾配を安定させるために、サンプリング技術の高度なバージョンを使用する必要があります。 整理する代わりに j 同じ頻度で、それらに比例する確率でそれらを取ります w i j エッジが特異であるふりをします。
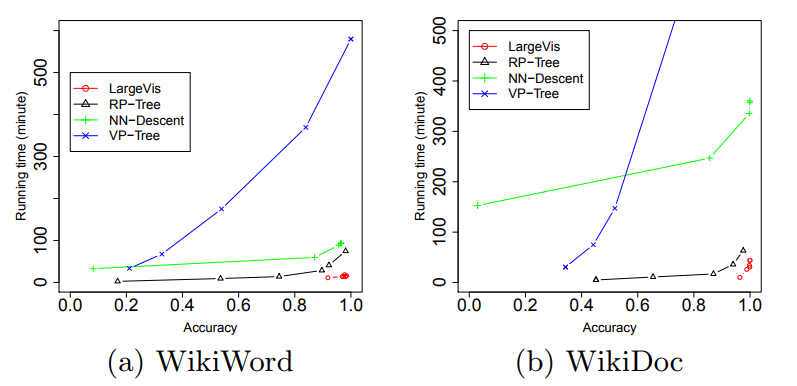
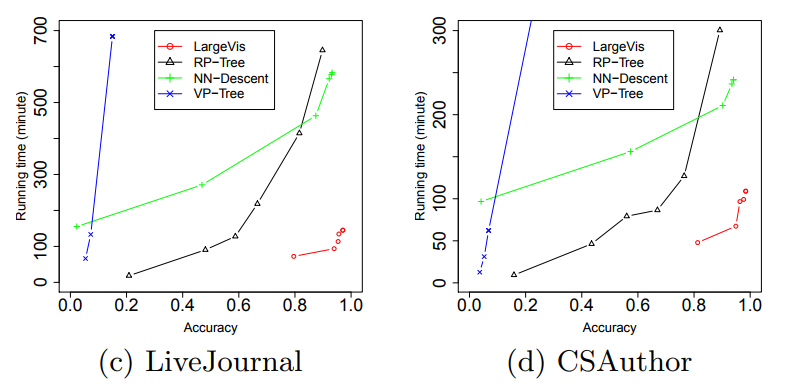
うわー これらのトリックはすべて私たちに何を与えますか? Barnes-Hut t-SNEと比較して、適度に大きなデータセットでの速度が約5倍になりました!

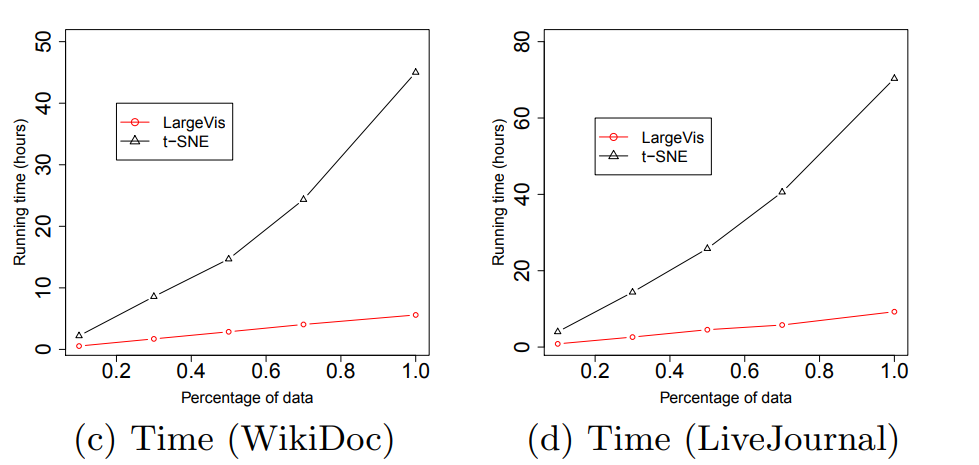
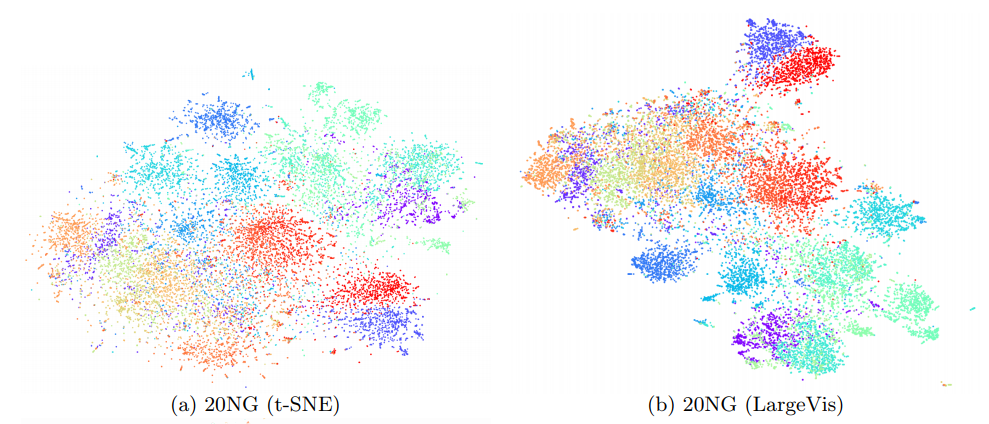


( 記事からの写真)
同時に、視覚化の品質はほぼ同じです。 気配りのある読者は、20のニュースグループの比較的小さなデータセット( | X | ≈ 20,000)LargeVisは、T-SNEを失います。これは、潜んでいる定数の影響であり、舞台裏に残りました。学生は、O-ラージの下で程度の低いアルゴリズムを軽率に使用することはあなたの健康に有害です。最後に、いくつかの実用的なポイント。LargeVisの公式実装はありますが、私の意見では、コードは少しいので、自己責任で使用してください。ノードごとの負のサンプルの数
Mは通常5になります(マシンワードプロセッシングから取得)。実験により、品質が非常にわずかに向上することが示されました。Mは3から7です。ツリーの数は、データセットが大きくなるほど大きくなりますが、多すぎません。10の最小値に焦点を当てる| X | < 10 5および100を超える値に近い| X | > 10 7 。 \ガンマクリエイターアルゴリズム理由を説明せず、7に連れて行きます。最も重要なこと:LargeVisは、すべての作業段階で完全に並列します。重み行列がまばらであるため、異なるフローでの非同期のまばらな勾配降下が互いに衝突することはほとんどありません。
おわりに
ご清聴ありがとうございました。sklearnのTSNEのパラメーターにどのような神秘的な方法= 'barnes_hut'と角度が含まれているかがより明確になり、1,000万件のレコードのデータセットをレンダリングする必要があるときに失われないことを願っています。大量のデータを扱う場合は、Barens-Hutの独自のアプリケーションを見つけるか、LargeVisを実装することに決めます。念のため、後者の作業に関する簡単なメモを以下に示します。良い一日を!
