通常、TCPサーバーのスケーリング方法は明らかです。 必要なときに1つのプロセスから開始します。追加するだけです。 Apache、NGINX、LighttpdなどのHTTPサーバーを含む多くのアプリケーションがこれを実行します。

サービスプロセスの数を増やすことは、CPUコアを1つしか使用しないという問題を解決する優れた方法ですが、他の問題を犠牲にします。
TCPサーバーをパフォーマンスに関して整理するには、次の3つの方法があります。
a)1つのパッシブソケット、1つのサービスプロセス。
b)1つのパッシブソケット、多数のサービスプロセス。
c)多くのサービスプロセス。それぞれに独自のパッシブソケットがあります。

要求の処理に使用できるCPUが1つに制限されているため、方法「a」が最も簡単です。 唯一のプロセスは、 accept()
を呼び出して接続をaccept()
、それ自体が接続を提供します。 このメソッドは、Lighttpdに適しています。
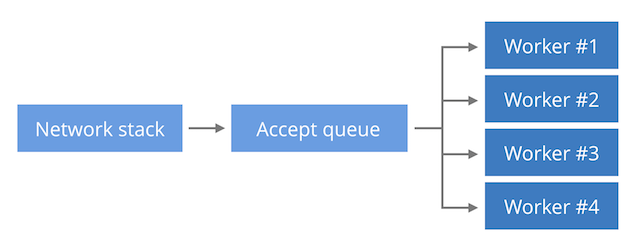
方法bでは、新しい接続は同じカーネルデータ構造(パッシブソケット)にあります。 多くのサービスプロセスは、このソケットでaccept()
を呼び出し、受信した要求を処理します。 この方法では、一定の制限内で、複数のCPU間の着信接続のバランスを取ることができ、NGINXの標準です。
ソケットSO_REUSEPORT
を使用すると、各プロセスに独自のカーネル構造(パッシブソケット)を提供できます。 これにより、単一のソケットにアクセスするためのサービスプロセスの競合が回避されます。ただし、トラフィックのみがGoogleに匹敵しない場合、特別な問題にはなりません。 また、この方法は負荷のバランスを改善するのに役立ちます。これを以下に示します。
Cloudflareでは、NGINXを使用しているため、方法bに精通しています。 この記事では、特定の問題について説明します。
負荷分散受け入れ()
複数のプロセス間で新しい接続を配布する方法が2つあることを知っている人はほとんどいません。 2つの擬似コードリストを検討してください。 最初のblocking-acceptに名前を付けましょう:
sd = bind(('127.0.0.1', 1024)) for i in range(3): if os.fork () == 0: while True: cd, _ = sd.accept() cd.close() print 'worker %d' % (i,)
新しい接続の1つのキューは、各プロセスでaccept()
するブロッキング呼び出しによってプロセス間で共有されます。
2番目の方法は、epoll-and-acceptと呼ばれます。
sd = bind(('127.0.0.1', 1024)) sd.setblocking(False) for i in range(3): if os.fork () == 0: ed = select.epoll() ed.register(sd, EPOLLIN | EPOLLEXCLUSIVE) while True: ed.poll() cd, _ = sd.accept() cd.close() print 'worker %d' % (i,)
各プロセスには、独自のepollベースのイベントループがあります。 ノンブロッキングaccept()
は、epollが新しい接続をアナウンスしたときにのみ呼び出されます。 通常の雷の群れの問題(単一のイベントが発生した場合でも、それを処理できるすべてのプロセスが「ウェイクアップ」- およそTransl。 ) EPOLLEXCLUSIVE
フラグを使用して回避されます。 完全なコードはこちらから入手できます 。
両方のプログラムは似ていますが、動作はわずかに異なります。 これは、それぞれといくつかの接続を確立しようとするときに起こることです。
もちろん、ブロッキングaccept()
とepoll()
イベントループを比較することは不正です。 Epollはより強力なツールであり、本格的なイベント指向プログラムを作成できます。 ブロッキング接続の使用は面倒です。 このようなアプローチを実際の状況で意味のあるものにするためには、各リクエストにスレッドを割り当てる、綿密なマルチスレッドプログラミングが必要になります。
もう1つの驚きは、Linuxでブロックaccept()
を使用することが技術的に間違っていることです。 Alan Burlisonは、パッシブソケットでclose()
を実行する場合、そのソケットで実行されているaccept()
呼び出しをブロックしても中断されないことを指摘しました。 これにより、突然の動作が発生する可能性があります。存在しないパッシブソケットでaccept()
成功します。 疑わしい場合は、マルチスレッドプログラムでブロックaccept()
を使用しないでください。 回避策は、 close()
shutdown()
前close()
shutdown()
を呼び出すことですが、POSIX標準に準拠していません。 くそレッグブレイク。
$ ./blocking-accept.py & $ for i in `seq 6`; do nc localhost 1024; done worker 2 worker 1 worker 0 worker 2 worker 1 worker 0
$ ./epoll-and-accept.py & $ for i in `seq 6`; do nc localhost 1024; done worker 0 worker 0 worker 0 worker 0 worker 0 worker 0
ブロッキング受け入れプログラムでは、接続はすべてのサービスプロセスに分散され、それぞれが正確に2つを受信しました。 epoll-and-acceptプログラムでは、すべての接続は最初のプロセスによって排他的に受信され、残りは何も受信しませんでした。 実際、Linuxはこれら2つのケースでクエリバランシングを異なる方法で実行します。
前者の場合、LinuxはFIFO循環配布を行います。 accept()
呼び出しが戻るのを待機する各プロセスはキューに入れられ、新しい接続をキュー順に受け取ります。
epoll-and-acceptの場合、アルゴリズムは異なります。Linuxは、新しい接続を待つためにキューに最後に追加されたプロセスを選択するようです。 LIFO この動作により、要求を処理した後に新しいイベントの待機に戻ったばかりの最もビジーなプロセスが、ほとんどの新しい接続を受信します。
NGINXで観察されるこの分布。 以下に、合成テスト中のWebサーバーからのtop
コマンドの出力を示します。このテストでは、サービスを提供するプロセスの1つがより多くの負荷を受け取り、残りは比較的少なくなります。

リストの最後のプロセスはほとんどビジーではなく(CPUの1%未満)、最初のプロセスはCPUの30%を消費することに注意してください。
SO_REUSEPORTが救助に
Linuxは、説明されている負荷分散の問題を回避するSO_REUSEPORT
ソケットSO_REUSEPORT
サポートしてSO_REUSEPORT
ます。 着信接続が1つではなく複数のキューに分散される「in」メソッドでのこのオプションの使用については既に説明しました。 原則として、サービングプロセスごとに1つのキューが使用されます。
このモードでは、Linuxはハッシュを使用して新しい接続を配布します。これにより、新しい接続が統計的に均一に分散され、その結果、各プロセスのトラフィックがほぼ同じ量になります。

現在、プロセスのワークロードの分散はそれほど大きくありません。リーダーはCPUの13.2%を消費し、アウトサイダーは9.3%を消費しています。
さて、負荷分散は改善されましたが、それだけではありません。 接続を受信するためにキューを分割すると、リクエスト処理の遅延の分散が低下する場合があります! エンジニアの人はこれについて良い説明があります:
私はこの問題を「ウェイトローズのレジ係とテスコのレジ係」と呼んでいます(英国の一般的な小売チェーン- 約Transl。 )。 ウェイトローズの「ワンストップからオールキャッシャー」モデルでは、最大レイテンシが短縮されます。 停滞している1人のレジ係は、忙しくない従業員に行くため、キュー内の他の顧客に大きな影響を与えません。 この場合、「各レジには自分の順番があります」テスコモデルは、特定のクライアントと彼の後ろに立つすべての人のサービス時間の増加につながります。
負荷が増加した場合、メソッド「b」は負荷を均等に分散しませんが、最適な応答時間を提供します。 これは、模擬テストで示すことができます。 以下は、比較的CPUを要求する100,000件のリクエスト、HTTPキープアライブなしの200件の同時リクエストが、設定中にメソッド「b」(すべてのプロセスに1つのキュー)を使用してNGINXによって処理される場合の分布です。
$ ./benchhttp -n 100000 -c 200 -r target:8181 http://aa/ | cut -d " " -f 1 | ./mmhistogram -t "Duration in ms (single queue)" min:3.61 avg:30.39 med=30.28 max:72.65 dev:1.58 count:100000 Duration in ms (single queue): value |-------------------------------------------------- count 0 | 0 1 | 0 2 | 1 4 | 16 8 | 67 16 |************************************************** 91760 32 | **** 8155 64 | 1
応答時間が予測可能であることは簡単にわかります。 中央値は平均値とほぼ等しく、標準偏差はわずかです。
SO_REUSEPORT
を使用した「c」メソッドを使用して構成中にNGINXで実行した同じテストの結果:
$ ./benchhttp -n 100000 -c 200 -r target:8181 http://aa/ | cut -d " " -f 1 | ./mmhistogram -t "Duration in ms (multiple queues)" min:1.49 avg:31.37 med=24.67 max:144.55 dev:25.27 count:100000 Duration in ms (multiple queues): value |-------------------------------------------------- count 0 | 0 1 | * 1023 2 | ********* 5321 4 | ***************** 9986 8 | ******************************** 18443 16 | ********************************************** 25852 32 |************************************************** 27949 64 | ******************** 11368 128 | 58
平均値は前のテストの平均値に匹敵し、中央値は減少しましたが、最大値は大幅に増加しました。そして最も重要なことは、標準偏差が今では非常に大きいことです。 サービス時間は大きく異なります-戦闘サーバー上で私が望む状況ではありません。
ただし、このテストは健全な懐疑論で処理してください。このケースを証明するために、かなりの負担をかけようとしました。 特定の条件により、サーバーが説明された状態にならないようにサーバーの負荷を制限できる場合があります。 テストを再現したい人のために、その説明が利用可能です 。
NGINXとSO_REUSEPORT
を使用するには、いくつかの条件を満たしている必要があります。 まず、NGINXバージョン1.13.6以降を使用していることを確認するか、 このパッチを適用します。 2番目に、TCP REUSEPORTのLinux実装の欠陥により、REUSEPORTキューの数を減らすと、保留中のTCP接続がドロップされることに注意してください。
おわりに
1つのアプリケーションの複数のプロセス間で着信接続のバランスをとるという問題は、解決策にはほど遠いものです。 方法「b」に従って1つのキューを使用すると、適切にスケーリングされ、最大応答時間を許容レベルに維持できますが、epollのメカニズムにより、負荷は不均等に分散されます。
サービスプロセス間で均一に分散する必要があるワークロードの場合、「in」メソッドを使用してSO_REUSEPORT
フラグを使用すると便利な場合があります。 残念ながら、高負荷の状況では、応答時間の分布が著しく低下する可能性があります。
最善の解決策は、標準的なepollの動作をLIFOからFIFOに変更することです。 AkamaiのJason Baronはすでにこれを行おうとしました( 1、2、3 )が、これまでのところ、これらの変更はカーネルに到達していません。
説明:翻訳者はCloudflare、Inc.と提携していません。 翻訳は、芸術への愛、所有者のすべての権利から作られています。 KDPV ポールタウンゼンド 、CC BY-SA 2.0。