旅行の本を読んだ後のある晩、彼らはラディシュチェフの有名な「サンクトペテルブルクからモスクワへの旅」とウラジミール・ソルログブの「タランタス」だったようです。 彼は見て、紙に何かを描き、有向グラフを描きました。 少し考えた後、有向グラフ上の1つの開始点(a)から他の一意のエンドポイント(f)までのすべてのパスを検索するアルゴリズムをどのように実装するのか疑問に思いました。 私はすでに深さおよび幅の検索アルゴリズムについて読み始めましたが、アルゴリズムを再度「発明」しようとすることはより興味深いと思いました。 同時に、いくつかの条件を設定しました。1)文学を使わない。 2)非再帰的アプローチを使用します。 3)ネストせずに、別々の配列にエッジを保存します。 次に、PHPでの通常のアルゴリズムとその実装を見つけるプロセスについて説明します。
グラフ自体は次のようになりました。
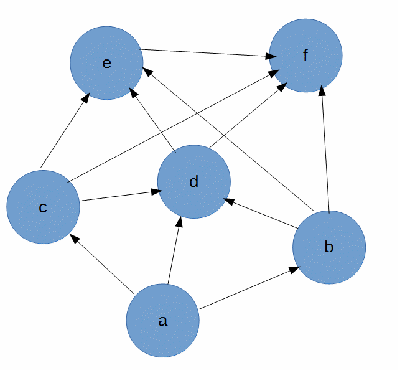
一般的に、入力には6つの頂点を持つ有向グラフがあり、タスクは再帰なしで最小コストでaからfまでのすべてのパスを見つけることです。
エッジはいくつかの配列に格納され、配列の名前は頂点です:
$a=array('b','c','d'); $b=array('d','e','f'); $c=array('d','e','f'); $d=array('e','f'); $e=array('f');
最初のパスを取得するために、各配列のゼロインデックスを調べて、それらを単一の行xに接着することにしました(この変数では、見つかったパスは各段階で保存されます)。 しかし、最小限のコストでそれを行う方法?! 最も簡単なオプションは、別のアレイを導入することであると思われました-初期化。
int配列では、グラフ内のすべての要素が逆の順序で表示されます。
$int=array('f','e','d','c','b','a');
その後、最初のパスを取得するのは非常に簡単です。すべての配列をループ処理するだけで、
連結を使用してxに新しい値を追加し、各段階で前の配列の要素を次の配列へのポインターとして使用します。
このスタイルはbashに少し似ていますが、コードは非常に単純です。
$x='a'; $z=$a[0]; while (1) { $x.=$z; $z=${$z}[0]; if ($z == 'f') {$x.=$z; break ;} }
そして、最初のパスx = abdefを取得しました。
画面に表示して、アルゴリズム自体を直接処理することができます。これは上記のすべてが準備段階であるためです。 理論的には、それを取り除くことができますが、思考の流れがよりよく理解されるように、それを残して公開します。
最初のパスを表示し、最初の関数を実行します。
print $x; print '<br>'; search_el ($x,$a,$b,$c,$d,$e);
アルゴリズム自体は実際には2サイクルに短縮され、別々の機能で実行されます。
最初の関数は、以前に受信した最初のパスxを使用します。 さらにループ内で、 xは右から左に走査されます。 2つの要素を探しています。そのうちの1つは
配列へのポインターとして、もう一方(右、配列が上下逆であることを覚えておく価値がある) array_searchを使用して、要素のキーを見つけ、この配列の後に何かがあるかどうかを確認します。 存在する場合は、見つかった要素で要素を置き換えますが、その前に尾を切り取ります(これにはsubstrが必要です)。 交換は別の方法で手配できます:
function search_el($x, $a, $b, $c, $d, $e) { $j = strlen($x); while ($j != 0) { $j--; if (isset(${$x[$j - 1]})) $key = array_search($x[$j], ${$x[$j - 1]}); if (${$x[$j - 1]}[$key + 1] != '') { $x = substr($x, 0, $j); $x.= ${$x[$j - 1]}[$key + 1]; new_way_search($x, $a, $b, $c, $d, $e); break; } } }
インタプリタが警告をスローしないように、issetの条件が必要です。 アルゴリズム自体とは関係ありません。 配列内に要素が見つからなかった場合、アルゴリズムは終了しますが、奇跡が起こった場合、その本質は非常に単純な新しい関数に進みます。xにテールを追加し、画面に表示して...元の関数に追加しますが、 xの新しい値を使用します。
function new_way_search($x, $a, $b, $c, $d, $e) { $z = $x[strlen($x) - 1]; $z = ${$z}[0]; while (1) { $x.= $z; if ($x[strlen($x) - 1] == 'f') break; if ($z == 'f') { $x.= $z; break; } $z = ${$z}[0]; } echo $x; echo '<br />'; search_el($x, $a, $b, $c, $d, $e); }
上の図のグラフのアルゴリズムの結果:
アブデフ
アブド
アベフ
abf
acdef
acdf
アセフ
acf
アデフ
adf
更新:
さらに、結果のアルゴリズムの説明をより簡単に示します。
有向グラフのエッジは、昇順で別々の配列に書き込まれます。
すなわち グラフの頂点とエッジが順序付けられます。 これは前提条件です。
アルゴリズムを開始する前に、最初のパスを見つけます。最初の条件は、最初の条件を考慮して、頂点名が最小になります。 見つける方法は特に重要ではありません。
紙で確認するための説明:
入力では、最初のパスx = abdefが見つかります。
1)配列xに沿って右から左に移動し、隣接する2つの要素を選択します
(最後のものを除く)ab d [e] f、left(d)は配列へのポインタとして使用されます
この配列の要素へのポインタとしての頂点(右)(e)。
eの後のdの要素を探し、ある場合は、eの右側のxのすべての要素を削除します。 x = abdeになります。 正しい要素(e)を見つかった要素に置き換えます。
2)最後の要素(f)に置き換えられた要素の右側(または右側の要素のインデックス)を(2番目のサイクルで)追加します。 このループでは、配列は条件でソートされるため、常にインデックスが0の配列を取得する必要があります。 この場合、右側の最後の要素x = abdfがすぐに得られるため、2番目のサイクルはアイドル状態になります。
3)右側の形成後、アレイを右から左にバイパスすることに戻ります。
最初の頂点(配列a)に要素がないことは、アルゴリズムを終了するための条件です。
関数と再帰のない同じコード、xの最初のパスが与えられます:
タイトルスポイラー
<?php // $a=array('b','c','d'); $b=array('d','e','f'); $c=array('d','e','f'); $d=array('e'); $e=array('f'); // $x='abdef'; print $x; print '<br>'; $j=strlen($x); while($j !=0) { // $key = array_search($x[$j], ${$x[$j-1]}); // , if (${$x[$j-1]}[$key+1] != '') { $x=substr($x, 0, $j); $x.= ${$x[$j-1]}[$key+1]; $z=$x[strlen($x)-1]; $z=${$z}[0]; // c while (1) { // f, if ($x[strlen($x)-1]=='f') {$x.=$z; break ;} $x.=$z; $z=${$z}[0]; } // $j=strlen($x); echo $x; echo '<br>'; } $j--; } ?>
PS
配列オプション:
タイトルスポイラー
<?php error_reporting(0); $a=array('b','c','d'); $b=array('d','e','f'); $c=array('d','e','f'); $d=array('e'); $e=array('f'); $x=array('a','b','d','e','f'); print_r ( $x ); print "\n"; $j=count($x)-1; while($j !=0) { $key = array_search($x[$j], ${$x[$j-1]}); if (${$x[$j-1]}[$key+1] != '') { $x=array_slice($x, 0, $j); array_push($x, ${$x[$j-1]}[$key+1]); $z=$x[count($x)-1]; $z=${$z}[0]; while (1) { if ($x[count($x)-1]=='f') { array_push($x, $z); break ;} array_push($x, $z); $z=${$z}[0]; } $j=count($x); print_r ( $x ); echo "\n"; } $j--; } ?>
結論ではなく方法論について少し。
その結果、そのようなアルゴリズムを開発するために、動的配列の操作に役立つかなり単純な方法が判明しました。
その一般的な本質は、実装を簡素化するために、メインアルゴリズムを起動する前に準備アクションを実行することです。 これにより、アルゴリズムがより透明で理解しやすくなり、最適化と簡素化がさらに容易になります。
この場合、手法は3つの準備ステップに分けられます。
1)データ内の順序の存在を決定します。 必要に応じて注文。
2)順序付けられたデータの初期化(ベクトル)配列の導入。
3)前のステップに基づいて初期パスを取得します。その意味は、メインアルゴリズムを単純化することにもあります。 この場合、パスがスキップされないように、データの順序を考慮して初期パスも構築する必要があります。
グラフの頂点に順序がない場合、頂点の名前を再定義し、実際に同形グラフを構築し、対応の配列を作成する(たとえば、実際の都市名とアルファベットの文字の間)追加のステップが必要になる場合があります。 アルゴリズム化のその他のケースでは、サイクルの制限を超える初期パス(ベクトル)の削除は、組み合わせオブジェクトの生成に関する以前の記事( 順列 、 パーティション/構成 、 組み合わせ、配置)から借りました。
特定の実用的な実装について話す場合、もちろん、動的データを扱うための特定の言語の機能を慎重に研究する価値があります。 この状況では、ある変数の値を別の変数の名前として決定するための「変数変数」の使用は、アルゴリズム自体の正確さを示す方法にすぎません。 著者は、労働条件でこのアプローチを使用する場合、どのようなリスクが存在するかを知りません。