
PostgreSQLを操作するための便利なトリックを共有したいと思います(他のDBMSには同様の機能がありますが、構文が異なる場合があります)。
特定の機能の詳細な説明を掘り下げないようにしながら、データを扱うときに役立つ多くのトピックとテクニックをカバーしようとします。 私は自分で学んでいたときにこれらの記事が大好きでした。
この資料は、SQLの基本的なスキルを完全にマスターし、さらに学習したい人に役立ちます。 pgAdmin 'eの例を実行して実験することをお勧めします。ダンプを展開せずにすべてのSQLクエリを実行可能にしました。
行こう!
1.一時テーブルの使用
複雑な問題を解決するとき、ソリューションを1つのリクエストに入れることは困難です(多くの人がそうしようとします)。 このような場合、将来の使用に備えて、一時データを中間テーブルに配置すると便利です。
このようなテーブルは通常どおり作成されますが、 TEMPキーワードを使用して、セッションの終了後に自動的に削除されます。
ON COMMIT DROPキーは、トランザクションが完了するとテーブル(およびそれに関連付けられているすべてのオブジェクト)を自動的に削除します。
例:
ROLLBACK; BEGIN; CREATE TEMP TABLE my_fist_temp_table -- ON COMMIT DROP -- AS SELECT 1 AS id, CAST ('- ' AS TEXT) AS val; ------------ : ------------------ -- , . ALTER TABLE my_fist_temp_table ADD COLUMN is_deleted BOOLEAN NOT NULL DEFAULT FALSE; -- , , , CREATE UNIQUE INDEX ON my_fist_temp_table (lower(val)) WHERE is_deleted = FALSE; -- /, -- ( ) VAL, -- UPDATE my_fist_temp_table SET id=id+3; -- / SELECT * FROM my_fist_temp_table; --COMMIT;
2.頻繁に使用される短縮Postgres構文
- データ型の変換。
式:
SELECT CAST ('365' AS INT);
面倒ではないように書くことができます:
SELECT '365'::INT;
- 略記法(I)LIKE '%text%'
LIKEはテンプレート式を受け入れます 。 マニュアルの詳細
LIKE演算子は~~ (2つのチルダ)に置き換えることができます
ILIKE演算子は~~ * (アスタリスク付きの2つのチルダ)に置き換えることができます
正規表現検索(LIKEとは異なる構文を使用)
演算子〜 (1つのチルダ)は正規表現を受け入れます
演算子〜* (1つのチルダとアスタリスク)大文字と小文字を区別しないバージョン〜
単語テキストを含む文字列をさまざまな方法で検索する例を示します
| 短縮構文 | 説明 | アナログ(I)LIKE |
|---|---|---|
| 〜 'テキスト'
または ~~ '%text%' | 大文字と小文字を区別する式を検証します | LIKE '%text%' |
| 〜* 'テキスト'
~~ * '%text%' | 大文字と小文字を区別しない式をチェックします | ILIKE '%text%' |
| !〜 'テキスト'
!~~ '%text%' | 大文字と小文字を区別しない式をチェックします | 「%text%」のようではない |
| !〜* 'テキスト'
!~~ * '%text%' | 大文字と小文字を区別しない式を確認する | しない '%text%' |
3.一般的なテーブル式(CTE)。 WITH句
非常に便利な設計により、クエリ結果を一時テーブルに入れてすぐに使用できます。
例は要点をつかむために原始的です。
a)単純なSELECT
WITH cte_table_name AS ( -- SELECT schemaname, tablename -- FROM pg_catalog.pg_tables -- , ORDER BY 1,2 ) SELECT * FROM cte_table_name; -- --
このようにして、任意のクエリ( UPDATE、DELETE 、 INSERTなど)を「ラップ」し、それらの結果を将来使用することができます。
b)次のようにリストすることにより、複数のテーブルを作成できます。
WITH table_1 (col,b) AS (SELECT 1,1), -- table_2 (col,c) AS (SELECT 2,2) -- --,table_3 (cool,yah) AS (SELECT 2,2 from table_2) -- , SELECT * FROM table_1 FULL JOIN table_2 USING (col);
c)上記の構成をさらに別の(またはそれ以上の)WITHに埋め込むこともできます。
WITH super_with (col,b,c) AS ( /* */ WITH table_1 (col,b) AS (SELECT 1,1), table_2 (col,c) AS (SELECT 2,2) SELECT * FROM table_1 FULL JOIN table_2 USING (col)-- ) SELECT col, b*20, c*30 FROM super_with;
パフォーマンスの観点から、オプティマイザーは効果的なクエリを作成できないため、後続の外部条件(クエリブラケットの外側)によって大きくフィルタリングされるデータをWITHセクションに配置しないでください。 何度もアクセスする必要がある結果をCTEに入力するのが最も便利です。
4.関数array_agg(MyColumn)。
リレーショナルデータベースの値は個別に格納されます(1つのオブジェクトの属性は複数の行で表すことができます)。 アプリケーションにデータを転送するには、多くの場合、1行(セル)または配列でデータを収集する必要があります。
PostgreSQLには、このためのarray_agg()関数があり、列全体からデータを収集して配列に入れることができます(選択範囲が1列の場合)。
GROUP BYを使用すると、各グループに関連する列のデータが配列に入ります。
すぐに別の機能を説明し、例に進みます。
array_to_string(array []、 ';')を使用すると、配列を文字列に変換できます。最初のパラメーターは配列を示し、2番目は単一引用符(アポストロフィ)で区切られた便利な区切り文字です。 セパレータとして使用できます
特殊文字
Tab \ t-たとえば、セルをEXCELに挿入するとき、値を列に簡単に分割できます(これを使用: array_to_string(array []、E '\ t') )
改行\ n-配列の値を1つのセルの行に分解します(これを使用: array_to_string(array []、E '\ n') -理由を以下に説明します)
改行\ n-配列の値を1つのセルの行に分解します(これを使用: array_to_string(array []、E '\ n') -理由を以下に説明します)
例:
-- WITH my_table (ID, year, any_val) AS ( VALUES (1, 2017,56) ,(2, 2017,67) ,(3, 2017,12) ,(4, 2017,30) ,(5, 2020,8) ,(6, 2030,17) ,(7, 2030,50) ) SELECT year ,array_agg(any_val) -- ( ) ,array_agg(any_val ORDER BY any_val) AS sort_array_agg -- ( 9+ Postgres) ,array_to_string(array_agg(any_val),';') -- ,ARRAY['This', 'is', 'my' , 'array'] AS my_simple_array -- FROM my_table GROUP BY year; --
結果を生成します:

逆のアクションを実行します。 UNNEST関数を使用して配列を行に分解し、同時にSELECT列INTO table_nameコンストラクトを示します。 記事があまり膨らまないように、これをネタバレに入れました。
UNNESTリクエスト
結果:
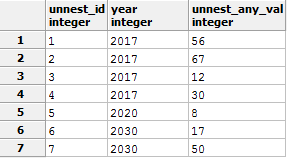
-- 1 -- tst_unnest_for_del, SELECT INTO -- , , . -- , production - , DROP TABLE IF EXISTS tst_unnest_for_del; /* IF EXISTS , */ WITH my_table (ID, year, any_val) AS ( VALUES (1, 2017,56) ,(2, 2017,67) ,(3, 2017,12) ,(4, 2017,30) ,(5, 2020,8) ,(6, 2030,17) ,(7, 2030,50) ) SELECT year ,array_agg(id) AS arr_id -- (id) ,array_agg(any_val) AS arr_any_val -- (any_val) INTO tst_unnest_for_del -- !! FROM my_table GROUP BY year; --2 Unnest SELECT unnest(arr_id) unnest_id -- id ,year ,unnest(arr_any_val) unnest_any_val -- any_val FROM tst_unnest_for_del ORDER BY 1 -- id,
結果:
5.キーワードRETURNIG *
INSERT、UPDATE、またはDELETEクエリの後に指定すると、変更の影響を受ける行を確認できます(通常、サーバーは変更された行の数のみを報告します)。結果として不確実な場合、またはIDを次のステップに転送する場合、 BEGINと組み合わせて、リクエストが正確に何に影響するかを確認すると便利です。
例:
--1 DROP TABLE IF EXISTS for_del_tmp; /* IF EXISTS , */ CREATE TABLE for_del_tmp -- AS -- SELECT generate_series(1,1000) AS id, -- 1000 random() AS values; -- --2 DELETE FROM for_del_tmp WHERE id > 500 RETURNING *; /* , RETURNING * - test, SELECT (. RETURNING id,name)*/
PS
私は非常に混乱しました、それが難しいことがわかったのですが、私はすべてについてコメントしようとしました。
--1 DROP TABLE IF EXISTS for_del_tmp; /* IF EXISTS , */ CREATE TABLE for_del_tmp -- AS -- SELECT generate_series(1,1000) AS id, -- 1000 ((random()*1000)::INTEGER)::text as values; /* . PS Postgre 9.2 Random() , 1000, , INTEGER , , .. , TEXT*/ --2 DELETE FROM for_del_tmp WHERE id > 500 RETURNING *; -- , --3 WITH deleted_id (id) AS ( DELETE FROM for_del_tmp WHERE id > 25 RETURNING id -- , id CTE "deleted_id" ) INSERT INTO for_del_tmp -- INSERT SELECT id, ' ' || now()::TIME || ' , ' || timeofday()::TIMESTAMP /* , ( , , )*/ FROM deleted_id -- "for_del_tmp" RETURNING *; -- -- , . --4 SELECT * FROM for_del_tmp; -- ,
したがって、データの削除が実行され、削除された値は次のステージに転送されます。 それはすべてあなたの想像力と目標に依存します。 複雑な設計を適用する前に、DBMSのバージョンのドキュメントを必ず確認してください! (INSERT、UPDATE、またはDELETEを並行して組み合わせる場合、微妙な点があります)
6.クエリ結果をファイルに保存する
COPYチームにはさまざまなパラメーターと目的があります。慣れるための最も簡単なアプリケーションについて説明します。
COPY ( SELECT * FROM pg_stat_activity /* . : */ --) TO 'C:/TEMP/my_proc_tst.csv' -- . Windows ) TO '/tmp/my_proc_tst.csv' -- . LINUX --) TO STDOUT -- pgAdmin WITH CSV HEADER -- .
7.別のベースでのリクエストの履行
少し前に、リクエストを別のデータベースにアドレスすることができることを学びました。これにはdblink関数があります( 詳細はマニュアルに記載されています )
例:
SELECT * FROM dblink( 'host=localhost user=postgres dbname=postgres', /* host user , */ 'SELECT '' : '' || current_database()' /* . , , ( ). */ ) RETURNS (col_name TEXT) UNION ALL SELECT ' : ' || current_database();

エラーが発生した場合:
「エラー:関数dblink(不明、不明)が存在しません」次のコマンドで拡張機能をインストールする必要があります。
CREATE EXTENSION dblink;
8.関数の類似性
ある値と別の値の類似性を判断する機能。
似ているが互いに等しくない(入力ミスがあった)テキストデータを比較するために使用されます。 手作業によるバインディングを最小限に抑え、多くの時間と神経を節約しました。
類似度(a、b)は、0から1までの小数を提供し、1に近いほど、より正確に一致します。
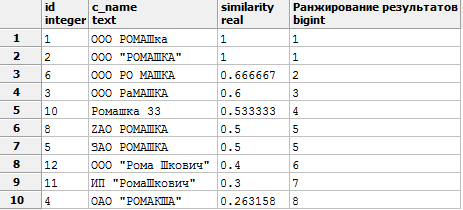
例に移りましょう。 WITHを使用して、架空のデータ(および機能を示すために特別にワープ)を使用して一時テーブルを編成し、各行をテキストと比較します。 以下の例では、 LLC“ ROMASHKA”のように見えるものを探します(2番目のパラメーターに関数パラメーターを代入します)。
WITH company (id,c_name) AS ( VALUES (1, ' ') UNION ALL /* PS UNION ALL , UNION, .. , */ VALUES (2, ' ""') UNION ALL VALUES (3, ' ') UNION ALL VALUES (4, ' ""') UNION ALL VALUES (5, ' ') UNION ALL VALUES (6, ' ') UNION ALL VALUES (7, ' ') UNION ALL VALUES (8, 'ZAO ') UNION ALL VALUES (9, ' ?') UNION ALL VALUES (10, ' 33') UNION ALL VALUES (11, ' ""') UNION ALL VALUES (12, ' " "') UNION ALL VALUES (13, ' " "') ) SELECT *, similarity(c_name, ' ""') ,dense_rank() OVER (ORDER BY similarity(c_name, ' ""') DESC) AS " " -- , FROM company WHERE similarity(c_name, ' ""') >0.25 -- 0 1, 1, ORDER BY similarity DESC;
次の結果が得られます。
エラーが発生した場合
「エラー:関数の類似性(不明、不明)が存在しません」次のコマンドで拡張機能をインストールする必要があります。
CREATE EXTENSION pg_trgm;
より複雑な例
次の結果が得られます。
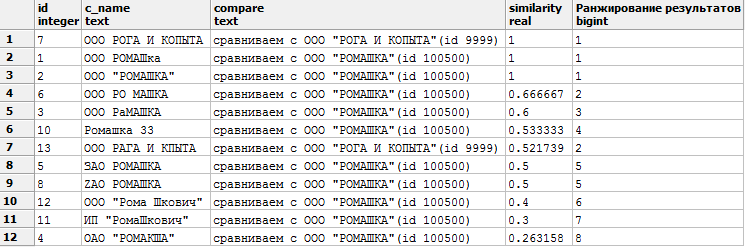
WITH company (id,c_name) AS ( -- VALUES (1, ' ') ,(2, ' ""') ,(3, ' ') ,(4, ' ""') ,(5, ' ') ,(6, ' ') ,(7, ' ') ,(8, 'ZAO ') ,(9, ' ?') ,(10, ' 33') ,(11, ' ""') ,(12, ' " "') ,(14, ' " "') ,(13, ' ') ), compare (id, need) AS -- (VALUES (100500, ' ""') ,(9999, ' " "') ) SELECT c1.id, c1.c_name, ' ' || c2.need, similarity(c1.c_name, c2.need) ,dense_rank() OVER (PARTITION BY c2.need ORDER BY similarity(c1.c_name, c2.need) DESC) AS " " -- , FROM company c1 CROSS JOIN compare c2 WHERE similarity(c_name, c2.need) >0.25 -- 0 1, 1, ORDER BY similarity DESC;
次の結果が得られます。
類似度DESCでソートします。 最初の結果には、最も類似した行が表示されます(1-完全な類似性)。
SELECTで類似度の値を表示する必要はありません。WHERE条件の類似度(c_name、 'ROMASHKA LLC')で使用できます> 0.7
そして、私たちに合ったパラメーターを設定します。
PSテキストデータを比較する他の方法を教えていただければ幸いです。 正規表現で文字/数字を除くすべてを削除しようとしましたが、平等に一致しましたが、タイプミスが存在する場合、このオプションは機能しません。
9.ウィンドウ関数OVER()(PARTITION BY __ ORDER BY __)
ドラフトでこの非常に強力なツールをほぼ説明した後、彼は
10. LIKEの複数テンプレート
チャレンジ。 名前が特定のパターンに一致する必要があるユーザーのリストをフィルタリングする必要があります。
いつものように、最も簡単な例を示します。
-- CREATE TEMP TABLE users_tst (id, u_name) AS (VALUES (1::INT, NULL::VARCHAR(50)) ,(2, ' .') ,(3, ' .') ,(4, ' .') ,(5, ' .') ,(6, ' .') ,(7, ' .') ,(8, ' .') ,(9, ' .') );
その機能を果たすクエリがありますが、多数のフィルターを使用すると面倒になります。
SELECT * FROM users_tst WHERE u_name LIKE '%' OR u_name LIKE '%%' OR u_name LIKE ' .' OR u_name LIKE '%' -- ..
よりコンパクトにする方法を示します。
SELECT * FROM users_tst WHERE u_name LIKE ANY (ARRAY['%', '%%', ' .', '%'])
同様のアプローチを使用して、興味深いトリックを行うことができます。
元のリクエストを他に書き直す方法があれば、コメントに書いてください。
11.いくつかの便利な機能
NULLIF(a、b)
特定の値をNULLとして扱う必要がある場合があります。
たとえば、長さがゼロの文字列( ''は空の文字列)またはゼロ(0)です。
CASEを記述できますが、2つのパラメーターを持つNULLIF関数を使用する方が簡潔です。等しい場合はNULLを返し、そうでない場合は元の値を表示します。
SELECT id ,param ,CASE WHEN param = 0 THEN NULL ELSE param END -- CASE ,NULLIF(param,0) -- NULLIF ,val FROM( VALUES( 1, 0, ' 0' ) ) AS tst (id,param,val);
COALESCEは最初の非NULL値を選択します
SELECT COALESCE(NULL,NULL,-20,1,NULL,-7); -- -20
GREATESTはリストから最大値を選択します
SELECT GREATEST(2,1,NULL,5,7,4,-9); -- 7
LEASTはリストされている最小値を選択します
SELECT LEAST(2,1,NULL,5,7,4,-9); -- -9
PG_TYPEOFは列のデータ型を示します
SELECT pg_typeof(id), pg_typeof(arr), pg_typeof(NULL) FROM (VALUES ('1'::SMALLINT, array[1,2,'3',3.5])) AS x(id,arr); -- smallint, numeric[] unknown
PG_CANCEL_BACKENDは、データベース内の不要なプロセスを停止します
SELECT pid, query, * FROM pg_stat_activity -- . postgres PID PROCPID WHERE state <> 'idle' and pid <> pg_backend_pid(); -- SELECT pg_terminate_backend(PID); /* PID , , , */ SELECT pg_cancel_backend(PID); /* PID . , - KILL -9 LINUX */
マニュアルの詳細
PS
注意! KILL -9コンソールまたはタスクマネージャーを使用して、凍結されたプロセスを強制終了しないでください。
これは、データベースのクラッシュ、データの損失、長時間の自動データベース回復につながる可能性があります。
SELECT pg_cancel_backend(pid) FROM pg_stat_activity -- WHERE state <> 'idle' and pid <> pg_backend_pid();
注意! KILL -9コンソールまたはタスクマネージャーを使用して、凍結されたプロセスを強制終了しないでください。
これは、データベースのクラッシュ、データの損失、長時間の自動データベース回復につながる可能性があります。
12.エスケープ文字
基本から始めましょう。
SQLでは、文字列値は'アポストロフィ(単一引用符)で囲まれています。
数値をアポストロフィで囲むことはできませんが、小数部分を分離するには、ドットを使用する必要があります。 コンマはセパレータとして認識されます
SELECT ' ', 365, 567.6, 567,6
結果:

アポストロフィ記号自体を表示する必要があるまでは、すべて順調です。
これを行うには、2つのシールド方法があります(私には知られています)
SELECT 1, ' '' '''' ' -- '' UNION ALL SELECT 2, E' \' \'\' ' -- , , E , \
結果は同じです:

PostgreSQLには、文字をエスケープせずにデータを使用するより便利な方法があります。 2つのドル記号$$で囲まれた行には、ほぼすべての文字を使用できます。
例:
select $$ '' ', E'\' $$
元の形式でデータを取得します。

これだけでは不十分で、内部で2つのドル記号を連続して$$で使用したい場合、Postgresでは独自の「リミッター」を設定できます。 たとえば、次のように2ドルの間に独自のテキストを書くだけです。
select $uniq_tAg$ '' ', E'\', $$ $any_text$ $uniq_tAg$
テキストが表示されます。

私自身にとって、この方法は、関数の記述を研究し始めた少し前に発見されました。
おわりに
この資料が初心者や「調停者」にとって多くの新しいことを学ぶのに役立つことを願っています。 私自身は開発者ではありませんが、私は自分自身をSQLの恋人としか呼べません。そのため、説明した手法をどのように使用するかはあなた次第です。
SQLの学習が成功することを願っています。 コメントを待って、読んでくれてありがとう!
UPD つづく