
2,940,928 x 10,295,296を測定するテトリスプロセッサを作成するタスク
このプロジェクトは、過去1年半にわたる多くのユーザーの作業の集大成でした。 チームの構成は時間とともに変化しましたが、この記事の執筆には次の著者が参加しました。
- フィノッピ
- エレンディアスターマン
- Kチャン
- マディフィッシュ
- クリチキシリソス
- メゴ
- カルタタ
7H3_H4CK3R、Conor O'Brien、およびこのタスクに貢献してくれた他の多くのユーザーにも感謝します。
このタスクの前例のない規模のため、この記事はチームメンバーによって書かれたいくつかの部分に分かれています。 各参加者は、関連するプロジェクトの領域にほぼ対応する個別のサブトピックについて書きました。
また、問題を解決するために書かれたすべてのコードを投稿した、 組織のGitHubを見る価値があります。 開発チャットで質問することができます。
パート1:概要
このプロジェクトは、Stackexchange に関する質問への回答として始まりました。
これは理論的なタスクです。単純な答えも些細な答えもありません。
ConwayのLifeゲームには、LifeゲームがLifeに似たルールのシステムをシミュレートできるようにするメタピクセルなどの構造があります。 さらに、チューリングライフゲームが完了していることが知られています。
あなたの仕事は、コンウェイゲーム「ライフ」のルールを使用するセルオートマトンを作成し、テトリスをプレイできるようにすることです。
プログラムは、特定の世代のオートマトンの状態を手動で変更することによって入力を受け取る必要があります。これは中断です(つまり、フィギュアを左または右に動かしたり、回転したり、投げたり、フィールドに配置する新しいフィギュアをランダムに生成したりします)。 特定の世代数は待機時間と見なされます。 ゲームの結果は、マシンのどこかに表示されます。 結果は、実際のテトリスのフィールドに視覚的に似ている必要があります。
プログラムは、次の基準に従って、次の順序で評価されます(低い基準は高い基準に追加されます)。
- 境界矩形のサイズ-ソリューションを完全に含む最小の領域を持つ矩形フィールドが優先されます。
- 入力する変更の最小数-セルの数が最も少ないソリューション(マシンにとって最悪の場合)が勝ち、割り込みとしての手動構成に必要です。
- 最速の実行-世代数が最も少ないソリューションが勝利し、シミュレーションの1ステップを進めます。
- 生細胞の初期数-最小数が勝ちます。
- 最初の公開-ソリューションを含む最初の投稿が優先されます。
このプロジェクトの基本的な考え方は抽象化でした。 Lifeゲームでテトリスを直接開発する代わりに、作成した抽象化を段階的に拡張しました。 各層で、私たちは生命の複雑さからどんどん遠ざかり、他のプログラムと同じくらい簡単にプログラムできるコンピューターを作成することに近づきました。
まず、 OTCAメタピクセルをコンピューターの基礎として使用しました。 これらのメタピクセルは、「Life」に似たゲームのルールをエミュレートできます。 このプロジェクトの重要なインスピレーションの源はWireworldとWireworld computerであり、メタピクセルに基づいて同様のデザインを作成することを目指しました。 OTCAメタピクセルを使用してWireworldをエミュレートすることはできませんが、メタピクセルごとに異なるルールを設定し、Wireworldワイヤのように機能するメタピクセルデザインを作成できます。
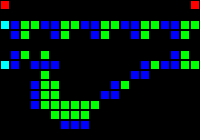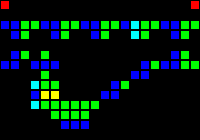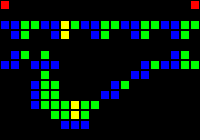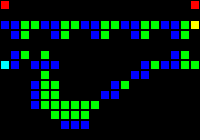
次のステップは、コンピューターの基礎として使用できる多くの基本的な論理ゲートの作成でした。 この段階では、実際のプロセッサの設計概念に類似した概念をすでに扱っています。 ORゲートの例を次に示します。この画像の各セルは、実際にはOTCAメタピクセル全体です。 「電子」(それぞれが1ビットのデータ)がゲートに出入りする方法がわかります。 コンピューターの作成に使用したすべてのタイプのメタピクセルも表示されます。B/ S-黒の背景、B1 / S-青、B2 / S-緑、B12 / S1-赤。
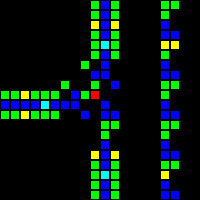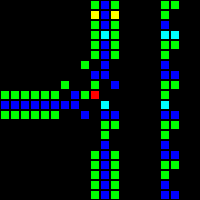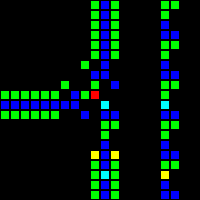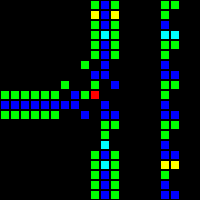
これから、プロセッサアーキテクチャを開発しました。 理解しやすく、実装が簡単なアーキテクチャの開発に多くの時間を費やしました。 Wireworldは基本的なトランスポートトリガーアーキテクチャを使用しますが、このプロジェクトでは、複数のオペコードとアドレッシングモードを備えたはるかに柔軟なRISCアーキテクチャを使用します。 プロセッサの製造を制御するアセンブリ言語QFTASM(Quest for Tetris Assembly)を作成しました。
また、コンピューターは非同期であるため、グローバルクロックによって制御されません。 コンピューター内での送信中、データには同期信号が付随します。 これは、コンピューターのグローバルなタイミングではなく、ローカルなタイミングのみを追跡する必要があることを意味します。
プロセッサアーキテクチャの図を以下に示します。
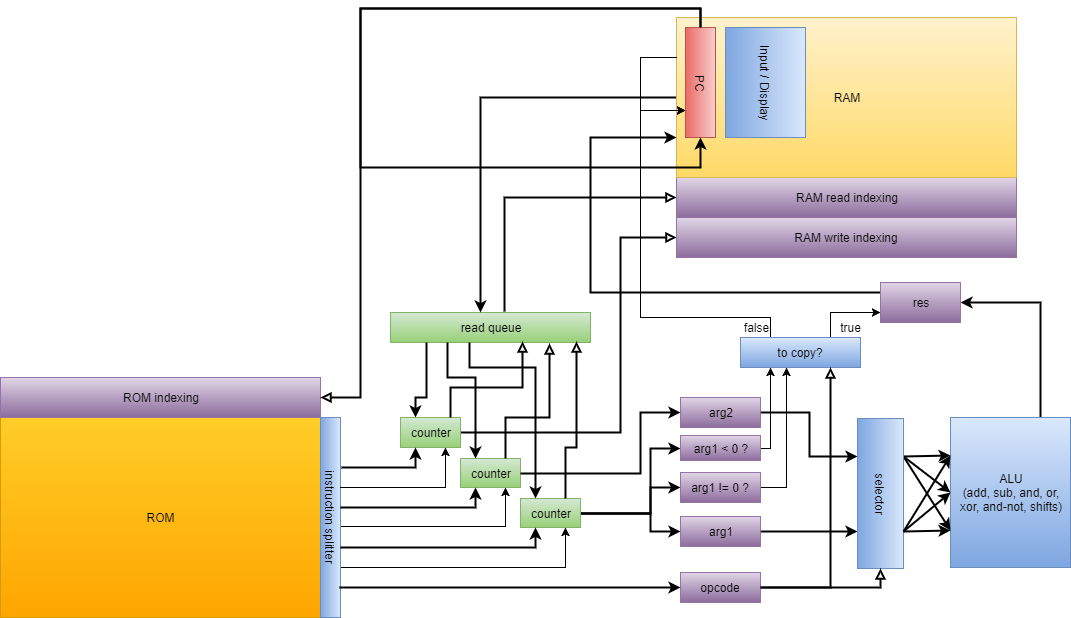
これからは、コンピューターにテトリスのみを実装できます。 タスクを簡素化するために、QFTASMで高水準言語をコンパイルするいくつかの方法を開発しました。 基本言語であるCogolがあり、2番目のより高度な言語が開発中であり、最終的にGCCバックエンドを作成しています。 現在、TetrisプログラムはCogolで記述され、それからコンパイルされています。
最終的なQFTASM Tetrisコードが生成された後、次のステップは、このコードから対応するROMへのアセンブリ、そしてメタピクセルから基礎となるゲーム「Life」へのアセンブリで、これで作業が完了します。
テトリスの発売
コンパイラに煩わされることなくテトリスをプレイしたい人は、QFTASMインタプリタでテトリスのソースコードを実行できます。 ゲーム全体を表示するには、表示されるRAMアドレス3-32を指定します。 便宜上、パーマリンクを次に示します。QFTASMのテトリス 。
ゲームの特徴:
- 7つのテトロミノすべて
- 動き、回転、数字のスムーズな下降
- 明確な線とスコア
- 次の図を表示
- プレイヤーを入力すると、ランダム性が追加されます
ディスプレイ
私たちのコンピューターは、メモリ内のグリッドとしてテトリスフィールドを表します。 アドレス10〜31はフィールドを示し、アドレス5〜8は次の図を示し、アドレス3はアカウントを含みます。
入る
ゲームでの入力は、RAMのアドレス1の内容を手動で編集することにより実行されます。 QFTASMインタープリターを使用する場合、これはアドレス1への直接記録を意味します。インタープリターページの「RAMへの直接書き込み」を参照してください。 各移動にはRAMの1ビットのみを変更する必要があり、この入力レジスタは入力イベントの読み取り後に自動的にリセットされます。
value motion
1
2
4 ( )
8
16
スコアリングシステム
プレーヤーは、1回の動きで複数の行を削除した場合にボーナスを受け取ります。
1 = 1
2 = 2
3 = 4
4 = 8
パート2:OTCAメタピクセルとVarLife
OTCAメタピクセル
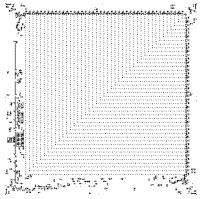
OTCAメタピクセルは、Conwayゲーム「Life」の構造で、「Life」に似たセルラーオートマトンをシミュレートするために使用できます。 LifeWikiを引用するには(以下のリンク):
OTCAメタピクセルは、Bryce Dewによって作成された35328セルの2048×2048セルです。...生命に似たセルオートマトンをエミュレートする機能など、多くの利点があります。ONおよびOFF状態のセルをズームアウトすると非常に目立ちます。 ..
Lifeに似たセルオートマトンは、基本的に、8つの隣接するセルのうちいくつが生きているかに基づいて、セルが生まれて生き残ることを意味します。 これらのルールの構文は次のとおりです。文字B、それに続く誕生につながる生きている隣人の数、スラッシュ、文字S、それに続く細胞の生命を支える生きている隣人の数。 少しわかりにくいので、例を挙げたほうがいいと思います。 規範的なゲーム「Life」は、ルールB3 / S23の形式で表すことができます。ルールB3 / S23は、3人の隣人に囲まれた死細胞が生き生きとし、2つまたは3つの生きている隣人の生きている細胞が生きていることを示しています そうでなければ、セルは死にます。
OTCAメタピクセルは2048 x 2048セルですが、実際には2058 x 2058セルの境界矩形があります。これは、すべての方向に5つのセルが隣接する対角線でオーバーラップしているためです。 重複セルは、メタセルの隣人にそれがオンになっていることを知らせるために放出される「グライダー」をインターセプトするために必要です。 このため、他のメタピクセルに影響を与えたり、制御不能に移動したりすることはありません。 出生と生存の規則は、2つの列に沿った特定の位置(出生用、生存用)の「食べる人」の有無によって、メタピクセルの左側のセルの特別なセクションにエンコードされます。 隣接セルの状態の認識に関して、これは何が起こるかです:
次に、9-LWSSストリームは、セルの周りを時計回りに回り、ハニービット反応メモリセルを開始する各「オン」セルのLWSSを失います。 欠落しているLWSSの数は、反対方向から別のLWSSと衝突することにより、前面LWSSの位置を認識することによって計算されます。 この衝突は、出生/生存の状態を決定する「食べる人」がいない場合、グライダーをリリースし、別の1つまたは2つのハニービット反応を引き起こします。
OTCAメタピクセルの各側面のより詳細な図は、そのWebサイトで入手できます。 。
バルライフ
私は、Life-likeゲームのルールのオンラインシミュレーターを作成しました。このシミュレーターでは、「Life」のルールと同様のルールに従って、任意のセルの動作を設定できます。 シミュレーターを「Variations of Life」と呼びました。 簡潔にするため、後にこの名前は「VarLife」に変更されました。 以下にスクリーンショットを示します(シミュレーターへのリンク: http : //play.starmaninnovations.com/varlife/BeeHkfCpNR ):

注目すべき機能:
- セルを「ライブ」/「デッド」状態の間で切り替え、さまざまなルールに従ってフィールドをペイントします。
- シミュレーションを開始および停止する機能。一度に1ステップずつ実行します。 サイクル/ sおよびms /サイクルで設定された速度で、最大速度またはそれ以上の速度で所定のステップ数を実行することもできます。
- すべての生細胞を除去するか、フィールドを空の状態に完全にリセットすることができます。
- フィールドとセルのサイズを変更でき、水平および/または垂直トロイダル畳み込みも含めることができます。
- パーマネントリンク(すべてのURL情報をエンコードする)および短いURL(情報が多すぎることがありますが、それらは依然として有用です)。
- B / S、色、オプションのランダム性を持つルールのセット。
- そして最後はgifレンダリングです!
render-to-gif関数は、実装に時間がかかったため、私のお気に入りです。 朝の7時にようやく完成したときはとてもクールでした。 これにより、VarLifeデザインを他の人と簡単に共有できます。
VarLife基本スキーム
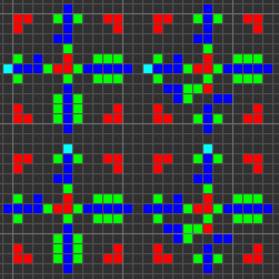
一般に、VarLifeコンピューターに必要なセルは4種類だけです! 死んだ/生きている州を考慮に入れた8つの州のみ:
- B / S(黒/白)、これはすべてのコンポーネント間のバッファとして機能します。これは、B / Sセルが決して生存できないためです。
- B1 / S(青/シアン)は、信号を伝播するために使用される主なタイプのセルです。
- B2 / S(緑/黄)-主に信号の制御に使用され、逆伝播から信号を保護します。
- B12 / S1(赤/オレンジ)-信号を交差させてデータビットを保存する場合など、いくつかの特別な状況で使用されます。
この短いURLを使用して、既にエンコードされたルールでVarLifeを開きます: http ://play.starmaninnovations.com/varlife/BeeHkfCpNR
指揮者
異なる特性を持つ導体には、いくつかの異なる設計があります。
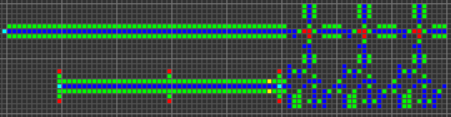
これは、VarLifeで最もシンプルで主要な導体で、青のストリップで、緑のストライプに限定されています。

短いURL: http : //play.starmaninnovations.com/varlife/WcsGmjLiBF
これは単方向導体です。 つまり、反対方向に行こうとするすべての信号を破壊します。 また、主導体よりも1セル狭い。

短いURL: http : //play.starmaninnovations.com/varlife/ARWgUgPTEJ
斜めの導体もありますが、ほとんど使用されません。
短いURL: http : //play.starmaninnovations.com/varlife/kJotsdSXIj
ゲートウェイ
実際には、個々のゲートウェイを作成する方法は多数あるため、各タイプの例を1つだけ示します。 最初のgifは、それぞれAND、XOR、およびORゲートウェイを示しています。 主なアイデアは、緑のセルがANDのように機能し、青のセルがXORのように機能し、赤のセルがORのように機能し、それらの周囲の他のすべてのセルが正しい伝送を提供することです。
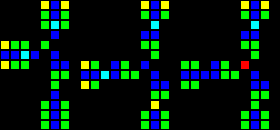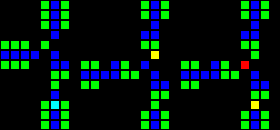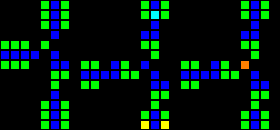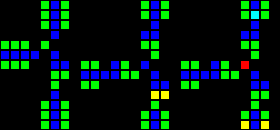
短いURL: http : //play.starmaninnovations.com/varlife/EGTlKktmeI
AND-NOTゲートウェイ(ANTと省略)は重要なコンポーネントであることが証明されています。 このゲートウェイは、Bからの信号がない場合にのみAから信号を送信します。つまり、「A AND NOT B」です。
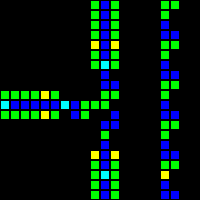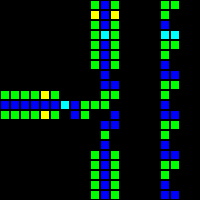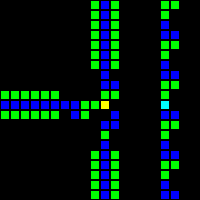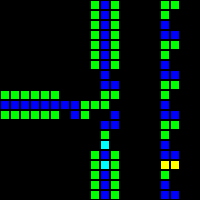
短いURL: http : //play.starmaninnovations.com/varlife/RsZBiNqIUy
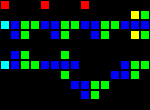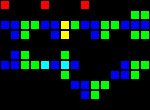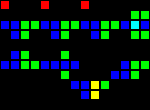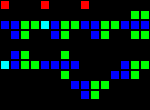
これはまさにゲートウェイではありませんが、タイルを横切る導体は非常に重要で便利です。
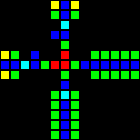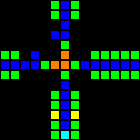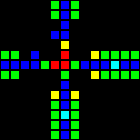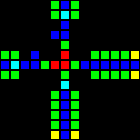
短いURL: http : //play.starmaninnovations.com/varlife/OXMsPyaNTC
ところで、NOTゲートウェイはありません。 これは、着信信号なしでは一定の出力を作成する必要があるためです。これは、最新のコンピューター機器に必要な多くのタイミングではあまりよく表示されません。 しかし、いずれにせよ、私たちはそれなしでなんとかしました。
さらに、多くのコンポーネントは、11 x 11の境界ボックス( タイル )に収まるように意図的に作成されました。タイルがタイルに入ってから出口に達すると、信号は11クロックサイクルを必要とします。 これにより、スペースやタイミングに合わせて導体を調整することなく、コンポーネントをよりモジュール化して接続しやすくなります。
回路コンポーネントの研究中に研究/作成された他のゲートウェイは、ポストPhiNotPi: ビルディングブロック:論理ゲートにあります。
遅延コンポーネント
コンピューターハードウェアの開発プロセスで、KZhangは以下に示す遅延コンポーネントの多くを思いつきました。
4サイクル遅延:
短いURL: http : //play.starmaninnovations.com/varlife/gebOMIXxdh
5サイクルの遅延:
短いURL: http : //play.starmaninnovations.com/varlife/JItNjJvnUB
8サイクルの遅延(3つの個別のエントリポイント):
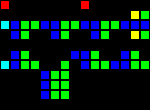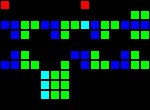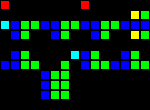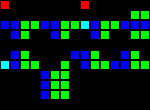
短いURL: http : //play.starmaninnovations.com/varlife/nSTRaVEDvA
11メジャーの遅延:
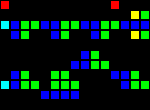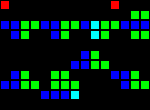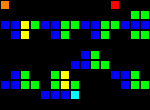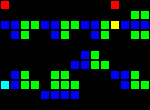
短いURL: http : //play.starmaninnovations.com/varlife/kfoADussXA
12ビート遅延:
短いURL: http : //play.starmaninnovations.com/varlife/bkamAfUfud
14メジャーの遅延:
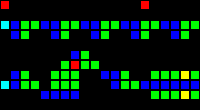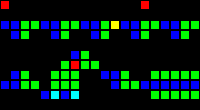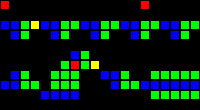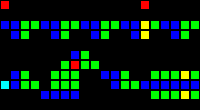
短いURL: http : //play.starmaninnovations.com/varlife/TkwzYIBWln
15メジャーの遅延( これとの比較により確認):
短いURL: http : //play.starmaninnovations.com/varlife/jmgpehYlpT
だから、ここにVarLife回路の主なコンポーネントがあります! 基本的なコンピューター回路の説明については、KZhangが書いた次のパートを参照してください!
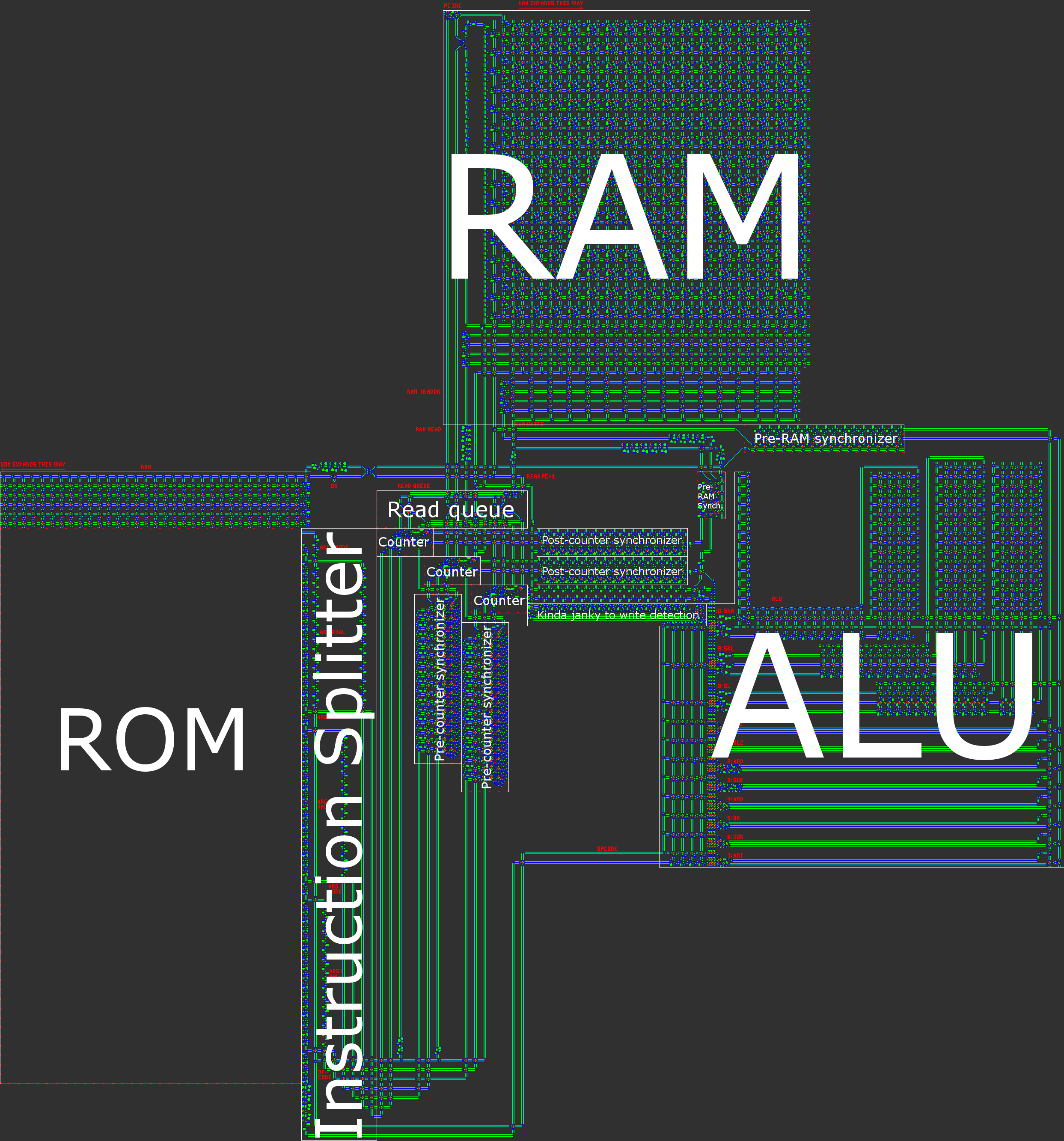
パート3:機器
論理ゲートウェイと一般的なプロセッサ構造に関する知識のおかげで、コンピューターのすべてのコンポーネントの開発を開始できます。
デマルチプレクサ
デマルチプレクサ、つまりdemuxは、ROM、RAM、およびALUの重要なコンポーネントです。 指定されたセレクタデータに応じて、入力信号をいくつかの出力信号のいずれかに向けます。 シリアルパラレルコンバーター、信号制御デバイス、クロックスプリッターの3つの主要部分で構成されています。
まず、セレクターのシリアルデータを「パラレル」に変換します。 これは、左端のデータビットが左端の11x11スクエアのクロック信号と交差し、次のデータビットが次の11x11スクエアのクロック信号と交差するように、データを戦略的に分割および遅延することによって行われます。
各データビットは11x11の各正方形で出力されますが、各データビットはクロックと1回だけ交差します。
次に、パラレルデータが指定されたアドレスと一致するかどうかを確認します。
これは、クロックおよびパラレルデータに使用されるANDおよびANTゲートウェイを使用して行います。 ただし、並列データも出力されていることを確認して、再度比較できるようにする必要があります。 結果として作成したゲートウェイは次のとおりです。

最後に、クロック信号を分離し、複数の信号検証デバイス(アドレス/出力ごとに1つ)を接続するだけで、マルチプレクサが実現します!

ROM
ROMは入力としてアドレスを受信し、出力としてこのアドレスに命令を送信する必要があります。 まず、マルチプレクサを使用して、クロック信号を命令の1つに向けます。 次に、複数のワイヤとORゲートウェイに触れて信号を生成する必要があります。 導体に触れることで、クロック信号が命令の58ビットすべてを通過できるようになり、生成された信号(ROMに沿った)がROMに沿って出力に移動します。
次に、パラレル信号をシリアルに変換するだけで、このROMで準備が整います。
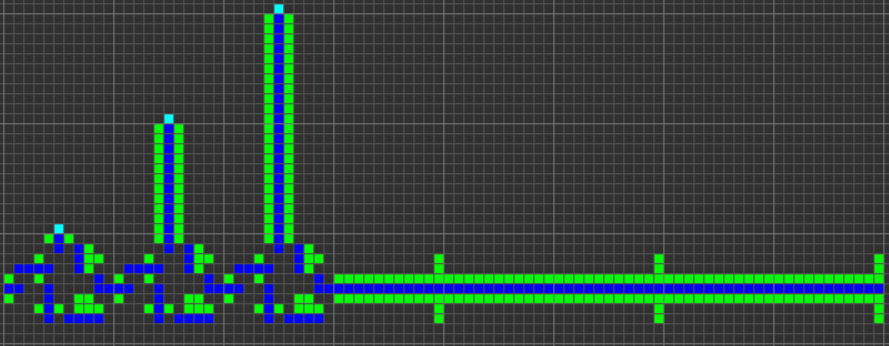
現在、ROMは、クリップボードからROMにアセンブラコードを転送するGollyスクリプトを実行して生成されます。
SRL、SL、SRA
これら3つの論理ゲートウェイはビットシフトに使用され、通常のAND、OR、XORなどよりも複雑です。 これらのゲートウェイが機能するためには、まずデータの「シフト」を実行するために、適切なタイミングでクロック信号を遅延させる必要があります。
これらのゲートウェイに渡される2番目の引数は、オフセットするビット数を示します。
SLおよびSRLには、次のものが必要です。
- 12個の最上位ビットがオンになっていないことを確認してください(そうでない場合、出力は0になります)。
- 下位4ビットに基づいて、適切なタイミングでデータを遅延させます。
これは、複数のAND / ANTゲートウェイとマルチプレクサを使用して実装できます。

SRAは、シフトするときに符号ビットをコピーする必要があるため、少し異なります。 これを行うには、符号付きビットを使用してクロックにANDを適用し、ワイヤーセパレーターとORゲートウェイを使用して出力を数回コピーします。

セットリセットトリガー(SR)
多くのプロセッサ機能は、データを保存する機能に依存しています。 2つの赤血球B12 / S1で実現できます。 2つのセルは、オン状態で互いにサポートしたり、一緒にオフにしたりできます。 追加の切り替えスキーム、リセットおよび読み取りの助けを借りて、単純なSRトリガーを作成できます。
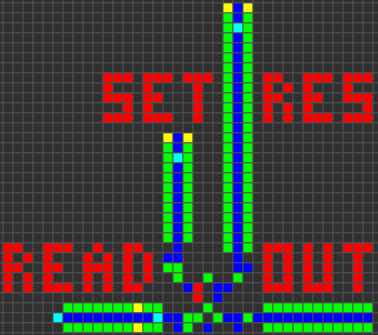
シンクロナイザー
シリアルデータをパラレルに変換し、複数のSRトリガーをオンにすることで、データワード全体を保存できます。 次に、データを再度取得するために、すべてのトリガーを読み取ってリセットし、それに応じてデータを遅延させることができます。 これにより、1つ(または複数)のデータワードを保存し、別のデータワードを待つことができます。 これにより、異なる時間に受信した2ワードのデータを同期できます。

読み取りカウンター
このデバイスは、RAMからアドレス指定を実行する必要がある回数を追跡します。 SRトリガーに似たデバイス、Tトリガーでこの問題を解決します。 Tトリガーは、入力を受け取るたびに状態を変更します。オンの場合はオフになり、逆の場合も同様です。 Tトリガーの状態が変化すると、出力パルスが送信され、これを別のTトリガーに送信して2ビットカウンターを作成できます。

読み取りカウンターを作成するには、2つのANTゲートウェイを使用してカウンターを適切なアドレス指定モードに転送し、カウンター出力信号を使用してクロック信号の送信先(ALUまたはRAM)を決定する必要があります。

読み取りキュー
読み取りキューは、RAM出力を適切な場所に送信できるように、どの読み取りカウンターが入力をRAMに送信したかを追跡する必要があります。 これを行うには、複数のSRトリガーを使用します。各入力に1つのトリガーです。 信号が読み取りカウンターからRAMに転送されると、クロック信号が分周され、カウンターのSRトリガーがオンになります。 その後、RAM出力はSRトリガーとともにANDゲートウェイを通過し、RAMからのクロックがSRトリガーをリセットします。

ALU
ALUは、SRトリガーを使用して信号の送信先を追跡するという点で、読み取りキューと動作が似ています。 まず、マルチプレクサを使用して、命令のオペコードに対応する論理回路のSRトリガーがオンになります。 次に、SRトリガーとともに、1番目と2番目の引数の値がANDゲートウェイを通過してから、論理回路に転送されます。 通過すると、クロックがトリガーをリセットするため、ALUを再び使用できます。

RAM
RAMはこのプロジェクトの最も難しい部分になりました。 データを保存する各SRトリガーの非常に具体的な制御が必要でした。 読み取りの場合、アドレスはマルチプレクサに送信され、RAMセグメントに送信されます。 RAMセグメントは、保存されたデータを同時に表示します。保存されたデータは、順次形式に変換されて表示されます。 記録の場合、アドレスは別のマルチプレクサに転送され、記録されたデータはシリアルからパラレルに変換され、RAMセグメントはRAMを介して信号を伝播します。
各RAMセグメントの22x22メタピクセルの構造は次のとおりです。
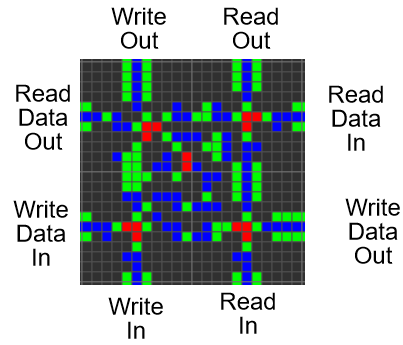
すべてのRAMを接続すると、次のようになります。

すべてをまとめる
これらのすべてのコンポーネントと、パート1で説明した一般的なコンピューターアーキテクチャを使用して、機能するコンピューターを構築できます。
ダウンロード可能なファイル:
- テトリス用の既製コンピューター
-ROM、空のコンピューター、および素数を見つけるためのコンピューターを作成するスクリプト
パート4:QFTASMとCogol
アーキテクチャの概要
要するに、私たちのコンピューターは16ビットRISC非同期ハーバードアーキテクチャを備えています。 プロセッサを手動で作成する場合、RISCアーキテクチャ( 命令セットが削減されたコンピューター )は、ほぼ必須の要件です。 私たちの場合、これはオペコードの数が少ないことを意味し、さらに重要なことには、すべての命令が非常に類似した方法で処理されます。
参考までに、Wireworldコンピューターはトランスポートトリガーアーキテクチャを使用します。このアーキテクチャーでは、唯一の命令は
MOV
であり、計算は特殊レジスターの書き込み/読み取りによって実行されます。 このパラダイムを使用すると、実装するための非常に単純なアーキテクチャを作成できますが、結果は適用性の危機に:しています。すべての算術/論理/条件付き演算には3つの命令が必要です。 より理解しやすいアーキテクチャを作成したかったのは明らかでした。
プロセッサをシンプルなままにすると同時に、使いやすさを向上させるために、設計に関していくつかの重要な決定を下しました。
- レジスタなし。 RAMの各アドレスは等しいと見なされ、任意の操作の引数として使用できます。 ある意味では、これはすべてのRAMをレジスタと見なすことができることを意味します。 これは、特別なロード/保管の指示がないことを意味します。
- メモリ割り当てについても同じことが言えます。 書き込みまたは読み取り可能なものはすべて、共通の統一されたアドレス指定スキームを持っています。 これは、プログラムカウンター(プログラムカウンター、PC)がアドレス0であり、通常の命令と制御命令の唯一の違いは、マネージャーがアドレス0を使用することです。
- データの転送は一貫性があり、ストレージは並行しています。 コンピューターの「電子的」性質により、データがリトルエンディアン順に連続して送信される場合(最下位ビットが最初に来る)、加算と減算の実装がはるかに簡単になります。 さらに、シリアルデータを使用すると、かさばるデータバスを取り除くことができます。これは非常に幅が広く、時間の経過とともに正しく動作するには不便です(データをまとめるには、すべてのバス "バンド"に同じ遅延が必要です)。
- ハーバードアーキテクチャ、つまり、プログラムメモリ(ROM)とデータメモリ(RAM)が分離されています。 これによりプロセッサーの柔軟性は低下しますが、サイズの最適化に役立ちます:プログラムの長さは必要なRAMの量よりもはるかに長いため、プログラムをROMに分割してから、ROMの圧縮に集中できます。これは読み取り専用の場合にはるかに簡単です。
- 16ビットのデータ容量。 これは最小の2の累乗で、テトリスの標準フィールド(10ブロック)よりも広くなっています。 -32768 +32767 65536 . (2^8=256 , , «».)
- . (, , ), , « », . , , .
- すべての指示は同じサイズです。各命令が3つのオペランド(値、値、宛先アドレス)を持つ1つのオペコードを持つアーキテクチャが最も柔軟なオプションになると計算しました。これらには、バイナリデータ操作と条件分岐が含まれます。
- アドレス指定モードのシンプルなシステム。複数のアドレッシングモードを持つことは、配列や再帰などをサポートするのに非常に便利です。比較的単純なシステムを使用して、いくつかの重要なアドレス指定モードを実装できました。
アーキテクチャーの図をパート1に示します。
ALUの作業と運用
その後、プロセッサの機能を決定する必要がありました。実装のシンプルさと各チームの汎用性に特に注意が払われました。
条件付きの動き
条件付きの動きは非常に重要であり、小規模および大規模な管理に役立ちます。 「小規模」は特定のデータ移動の実行を制御する機能であり、「大規模」は、任意のコードに制御を移すための条件付きジャンプ操作としての使用を指します。メモリの割り当てにより、条件付きの移動によりデータを通常のRAMにコピーし、宛先アドレスを命令カウンター(PC)にコピーできるため、プロセッサには特別な移行操作はありません。同様の理由で、無条件移動と無条件遷移の両方を放棄することも決定しました。これらの操作は両方とも条件移動として実装でき、条件の値は常にTRUEです。
2つのタイプの条件付き移動を使用することにしました。「ゼロでない場合は移動」(
MNZ
)と「ゼロ未満の場合は移動」(
MLZ
)です。機能的に
MNZ
は、データビットが1である
MLZ
かどうかのチェック、および符号ビットの値が1であるかどうかのチェックに限定されます。したがって、それらは等値チェックおよび比較に役立ちます。 「ゼロに移動」(
MEZ
)は空の信号からTRUE信号を作成することになっており、「ゼロがさらにある場合に移動」(
MGZ
)は符号ビットを0にする必要があるより複雑なチェックであるため、これら2つの動きを選択しました。前記少なくとも1つの他のビット1に等しい。
算術
プロセッサの設計を決定するときに次に重要な命令は、基本的な算術演算でした。上記のように、リトルエンディアンのシリアルデータを使用し、エンディアンの選択は、加算/減算演算の単純さによって決定されました。最下位ビットが最初に受信されると、算術デバイスはキャリービットをより簡単に追跡できます。
加算と減算をより積分にするために、負の数に追加のコードを使用したルックを使用することにしました。 Wireworldがリバースコードを使用していることは注目に値します。
加算と減算は、プロセッサの算術演算のネイティブサポートの運命です(後で説明するビットシフトを除く)。乗算などの他の操作は複雑すぎるため、アーキテクチャで実行できないため、ソフトウェアで実装する必要があります。
ビット操作ご想像の
とおり、プロセッサには
AND
、
OR
およびの命令があり
XOR
ます。命令の代わりに、
NOT
「and-not」(
ANT
)命令を使用することにしました。命令の
NOT
難しさは、セルオートマトンにとって困難な信号が存在しないときに信号を作成する必要があることです。命令
ANT
は、最初のビット引数が1で、最初のビット引数が0の場合にのみ1を返します。つまり、
NOT x
同様です
ANT -1 x
(また
XOR -1 x
)。また、
ANT
普遍的であり、マスクを適用するときに主な利点があります。テトリス用のプログラムの場合、テトロミノを削除するためにそれを使用します。
ビットシフトビットシフト
操作は、ALUによって処理される最も複雑な操作です。シフト値とオフセット値の2つの入力値を受け取ります。 (シフトの大きさが変化するため)複雑であるにもかかわらず、これらの操作は、テトリスで使用される「グラフィック」操作を含む多くの重要なタスクにとって重要です。ビットシフトは、効率的な乗算/除算アルゴリズムの基礎としても機能します。
プロセッサにはビットシフトの3つの操作があります-「左シフト」(
SL
)、「論理左シフト」(
SRL
)、「算術右シフト」(
SRA
)。最初の2ビットシフト(
SL
および
SRL
)新しいビットをゼロで埋めます(これは、右にシフトした負の数が負ではなくなることを意味します)。2番目のシフト引数が0〜15の範囲外にある場合、ご想像のとおり、結果はゼロのみになります。最後のビットシフトでは
SRA
、ビットシフトは入力データの符号を保持するため、真の2分割として機能します。
命令コンベア
いくつかの基本的なアーキテクチャの詳細について話しましょう。各CPUサイクルは、次の5つのステップで構成されています
。1. ROMから現在の命令を取得する現在
のPC値は、ROMから対応する命令を取得するために使用されます。各命令には、1つのオペコードと3つのオペランドがあります。各オペランドは、1つのデータワードと1つのアドレッシングモードで構成されます。 ROMから読み取る場合、これらの部分は互いに分離されています。
オペコードは4ビットであるため、16個の一意のオペコードをサポートでき、そのうち11個が割り当てられます。2. 前の命令の結果(必要な場合)をRAMに記録します。
0000 MNZ Move if Not Zero
0001 MLZ Move if Less than Zero
0010 ADD ADDition
0011 SUB SUBtraction
0100 AND bitwise AND
0101 OR bitwise OR
0110 XOR bitwise eXclusive OR
0111 ANT bitwise And-NoT
1000 SL Shift Left
1001 SRL Shift Right Logical
1010 SRA Shift Right Arithmetic
1011 unassigned
1100 unassigned
1101 unassigned
1110 unassigned
1111 unassigned
レコードの実行は、前のステートメントの状態(たとえば、条件付き移動の最初の引数の値)に依存します。書き込みアドレスは、前の命令の第3オペランドによって決定されます。
記録は指示を受け取った後に実行されることに注意することが重要です。これにより、分岐先アドレスの最初の命令ではなく、分岐命令(PCに書き込む操作)の直後に命令が実行される遷移遅延スロットが生成されます。
場合によっては(たとえば、無条件の遷移の場合)、最適化により遷移遅延スロットを取り除くことができます。その他の場合、これは不可能であり、分岐後の命令は空白のままにしておく必要があります。さらに、このタイプの遅延スロットは、実行中のPCインクリメントを考慮するために、ターゲット命令自体より1アドレス小さい分岐ターゲットアドレスを使用する必要があります。
つまり、前の命令の出力は次の命令を受け取った後にRAMに書き込まれるため、空の命令は条件付きジャンプの後に行く必要があります。そうしないと、PCは正しく移行するために更新されません。
3.現在の命令の引数のデータをRAMから読み取る
上記のように、3つのオペランドはそれぞれ、データワードとアドレッシングモードの両方で構成されています。データワードは16ビットに等しく、RAMと同じビット容量です。アドレス指定モードには2ビットが必要です。
アドレッシングモードは、実際の世界の多くのアドレッシングモードが多段階の計算(オフセットの追加など)を必要とするため、このようなプロセッサの大きな複雑さの原因になる可能性があります。同時に、柔軟なアドレス指定モードは、プロセッサの使いやすさにおいて重要な役割を果たします。
ハードセット番号をオペランドとして使用し、データアドレスをオペランドとして使用するという概念を統一しようとしました。これにより、カウンターに基づくアドレス指定モードが作成されました。オペランドのアドレス指定モードは、RAM読み取りサイクルでデータを送信する回数を決定する単なる数値です。それらには、直接、直接、間接、および二重間接アドレス指定が含まれます。リンクのデコード後、命令の3つのオペランドは異なる役割を取得します。通常、最初のオペランドは2項演算子の最初の引数ですが、現在の命令が条件付き移動である場合の条件としても機能します。 2番目のオペランドは、2項演算子の2番目の引数です。 3番目のステートメントは、命令の結果の宛先アドレスとして機能します。
00 : . ( )
01 : . ( )
10 : , . ( )
11 : , , . ( )
最初の2つの命令はデータとして機能し、3番目の命令はアドレスとして機能するため、アドレッシングモードは、使用される位置に応じて解釈が若干異なります。たとえば、ダイレクトモードは固定RAMアドレスからデータを読み取るために使用されます(RAMからの読み取りが必要なため)が、ダイレクトモードは固定RAMアドレスにデータを書き込むために使用されます(RAMからの読み取りが不要なため)。
4.結果の計算
オペコードとその最初の2つのオペランドは、バイナリ演算を実行するためにALUに送信されます。算術演算、ビット演算、およびシフト演算の場合、これは対応する演算を実行することを意味します。条件付き移動の場合、これは第2オペランドの単純な戻りを意味します。
オペコードと第1オペランドを使用して、結果をメモリに書き込むかどうかを決定する条件を計算します。条件付き移動の場合、これは、オペランド1のビットの1つが等しい(for
MNZ
)かどうかを判断する必要があるか、符号ビットが1に等しい(for
MLZ
)かどうかを判断する必要があることを意味します。オペコードが条件付き移動でない場合、レコードは常に実行されます(条件は常に真です)。
5.コマンドカウンターの増分次に
、最後に、コマンドカウンターの値が読み取られ、増加され、書き込まれます。
PCの増分は命令の読み取りと命令の書き込みの間にあるため、PCの値を1増やす命令は空(no-op)です。PCをそれ自体にコピーする命令により、次の命令が連続して2回実行されます。ただし、命令パイプラインに注意を払わないと、連続する複数のPC命令が、無限ループを含む複雑な効果につながる可能性があることに注意してください。
テトリスのアセンブラーを作成するオデッセイ
プロセッサ用の新しいアセンブリ言語QFTASMを作成しました。この1対1のアセンブリ言語は、コンピューターのROMにあるマシンコードに対応しています。
QFTASMプログラムは、行ごとの一連の指示に記録されます。各行の形式は次のとおりです。
[ ] [] [1] [2] [3]; [ ]
オペコードのリスト
上記のように、コンピューターは11個のオペコードをサポートし、各オペコードには3つのオペランドがあります。アドレス指定モード各オペランドにはデータ値とアドレス指定モードの両方が含まれます。データ値は、-32768〜65536の範囲の10進数で記述されます。アドレス指定モードは、データ値の1文字のプレフィックスで記述されます。5行のフィボナッチ数コードの例:
MNZ [] [] [ ] – , ; [ ] [], [] .
MLZ [] [] [ ] – , ; [ ] [], [] .
ADD [1] [2] [ ] – ; [1] + [2] [ ].
SUB [1] [2] [ ] – ; [1] - [2] [ ].
AND [1] [2] [ ] – ; [1] & [] [ ].
OR [1] [2] [ ] – ; [1] | [2] [ ].
XOR [1] [2] [ ] – XOR; [1] ^ [2] [ ].
ANT [1] [2] [ ] – -; [1] & (![2]) [ ].
SL [1] [2] [ ] – ; [1] << [2] [ ].
SRL [1] [2] [ ] – ; [1] >>> [2] [ ]. .
SRA [1] [2] [ ] – ; [1] >> [2] [ ] .
0 ()
1 A
2 B
3 C
0. MLZ -1 1 1;
1. MLZ -1 A2 3; ,
2. MLZ -1 A1 2;
3. MLZ -1 0 0;
4. ADD A2 A3 1; ,
このコードは、RAM 1のアドレスに現在のメンバーが含まれる一連のフィボナッチ数を計算します。28657の後、すぐにオーバーフローします。
グレイコード:このプログラムは、グレイコードを計算し、アドレス5から始まる連続したアドレスにコードを保存します。プログラムは、間接アドレス指定や条件分岐など、いくつかの便利な機能を使用します。結果のグレイコードが、アドレス56に51を入力したときの結果と等しい場合にのみ停止します。
0. MLZ -1 5 1;
1. SUB A1 5 2; ,
2. SRL A2 1 3; 1
3. XOR A2 A3 A1; XOR
4. SUB B1 42 4; 42 (101010)
5. MNZ A4 0 0; ( != 101010),
6. ADD A1 1 1; ,
101010
オンライン通訳
El'endia Starmanは非常に便利なオンライン通訳を作成しました。その中で、コードをステップごとに実行し、ブレークポイントを設定し、RAMに手動で書き込み、画面上でRAMの状態を視覚化できます。
コゴル
アーキテクチャとアセンブリ言語を選択した後、プロジェクトの「ソフトウェア」側の次のステップは、テトリスに適した高レベル言語を作成することです。したがって、私はCogolを作成しました。名前はCOBOLのしゃれとGame of Lifeの略語Cの両方ですが、Cと比較したCogolは実際のコンピューターと同じであることは注目に値します。
Cogolは、アセンブリ言語の1レベル上にのみ存在します。一般に、Cogolプログラムのほとんどの行はアセンブラーの行に対応していますが、言語にはいくつかの重要な機能があります。
- 主な機能には、割り当てのある名前付き変数と、より読みやすい構文の演算子が含まれます。たとえば、に
ADD A1 A2 3
なりますz = x + y;
。 コンパイラーは変数をアドレスにバインドします。 - ,
if(){}
,while(){}
do{}while();
. - ( ), «».
- . , .
コンパイラ(最初から書いた)は非常に単純/単純ですが、いくつかの言語構成を手動で最適化して、コンパイルされたプログラムの長さを短くしようとしました。
ここでは、言語のさまざまな機能の概要は次のとおりです。
トークン化
文字がトークンに共存できるかについての簡単なルールに基づいて直線的にソースコードtokeniziruetsya(1回のパスで)。現在のトークンの最後のシンボルに隣接できないシンボルが見つかると、現在のトークンは完了したと見なされ、新しいシンボルが新しいトークンを開始します。一部のシンボル(
{
またはなど
,
)は、他のシンボルと隣接することができないため、それら自体が別個のトークンです。その他(例、
>
または
=
)は自分自身とのみ並べることができます。
>>>
つまり、またはなどのトークンを作成できます
==
。スペース文字はトークン間の境界を強制しますが、それら自体は結果に含まれません。トークン化の最も難しいシンボル
-
は、減算と単項否定の両方を示すことができるため、特別な処理が必要なためです。
解析
解析もシングルパスで実行されます。コンパイラには、各言語構成要素を処理するメソッドがあり、さまざまなコンパイラメソッドに渡された後、トークンのグローバルリストからトークンが抽出されます。コンパイラが予期しないトークンを検出すると、構文エラーが生成されます。
グローバルメモリ割り当て
コンパイラーは、各グローバル変数(ワードまたは配列)に、RAM内の独自のアドレス(アドレス)を割り当てます。すべての変数はキーワードを使用して宣言する必要があります
my
。そのため、コンパイラーは変数にスペースを割り当てる必要があることを認識します。名前付きグローバル変数よりも格段に優れているのは、一時アドレスメモリの管理です。多くの命令(特に、条件ステートメントと多くの配列アクセス操作)は、中間計算を保存するために「一時的な」アドレスを必要とします。コンパイル中、コンパイラは必要に応じて一時アドレスを割り当てて解放します。コンパイラがより多くの一時アドレスを必要とする場合、より多くのRAMを割り当てます。私は通常はいくつかのプログラムが一時アドレスを使用していると考え、各アドレスは何回も使用されている...
構文
IF-ELSE
構文
if-else
Cの標準構文があります。QFTASMに変換すると、コードは次の構造を受け取ります。最初の本文が実行されると、2番目の本文はスキップされます。最初の本文がスキップされると、2番目の本文が実行されます。アセンブラーでは、「条件チェック」は通常、通常の減算であり、結果の符号は遷移を行うか本体を実行するかを決定します。これらの不平等を扱う、両方のために、または命令を使用。命令が処理に使用されるのは、差がゼロに等しくない場合(つまり、引数が等しくない場合)に本体を遷移するためです。複数の式を含む条件はまだサポートされていません。デザインが
if (cond) {
} else {
}
( )
( )
>
<=
MLZ
MNZ
==
else
欠落、無条件ジャンプも省略され、QFTASMコードは次のようになります:コンストラクトコンストラクションにもCの標準構文があります:QFTASMに変換するとき、コードには次のスキームがあります。各ブロックの実行後に実行します。条件がfalseを返す場合、本体は実行されず、ループは終了します。サイクルの実行の開始時に、制御フローはサイクルの本体を介して条件コードにジャンプします。したがって、条件が初めてfalseの場合、本体は実行されません。命令は、フォームまたはの不等式を処理するために使用されます。構造の実行とは異なり、命令
( )
WHILE
while
while () {
}
( )
( )
MLZ
>
<=
if
MNZ
!=
差がゼロに等しくない場合(つまり、引数が等しくない場合)に本体に送られるため、処理に使用されます。
構造
DO-WHILE
間の唯一の違い
while
や
do-while
ループの本体であるということ
do-while
、それは常に、少なくとも一回実行されるように、第1の時間が、完全ではないが。通常
do-while
、ループを完全にスキップする必要がないことが確実にわかっている場合は、コンストラクトを使用してアセンブラコードを数行保存します。
配列
1次元配列は、メモリの隣接ブロックとして実装されます。すべての配列は、宣言に応じて固定長になります。配列は次のように宣言されます。これは、配列のRAMの可能な割り当てであり、アドレス15〜18が予約されていることを示しています。
my alpha[3]; #
my beta[11] = {3,2,7,8}; #
15: alpha
16: alpha[0]
17: alpha[1]
18: alpha[2]
としてマークされたアドレス
alpha
はロケーションポインター
alpha[0]
で埋められます。この場合、アドレス15には値16が含まれ
alpha
ます。この配列をスタックとして使用する必要がある場合、Cogolコード内の変数をスタックポインターとして使用できます。
配列の要素へのアクセスは、標準レコードを使用して実行されます
array[index]
。値
index
が定数の場合、このリンクには要素の絶対アドレスが自動的に入力されます。それ以外の場合は、ポインター演算(加算のみ)を実行して、目的の絶対アドレスを見つけます。たとえば、インラインインデックスも可能
alpha[beta[1]]
です。
ルーチンと呼び出し
サブプログラムは、さまざまなコンテキストから呼び出すことができるコードのブロックであり、コードの重複を避け、再帰的なプログラムを作成します。以下は、フィボナッチ数を生成するための再帰的なサブルーチン(最も遅いアルゴリズム)を備えたプログラムの例です。サブルーチンはキーワードによって宣言され、プログラム内のどこにでも配置できます。各ルーチンには複数のローカル変数を含めることができ、各ローカル変数は引数リストの一部として宣言されます。これらの引数もデフォルト値に設定されます。
#
call display = fib(10).sum;
sub fib(cur,sum) {
if (cur <= 2) {
sum = 1;
return;
}
cur--;
call sum = fib(cur).sum;
cur--;
call sum += fib(cur).sum;
}
sub
再帰呼び出しを処理するために、ローカルサブルーチン変数がスタックに格納されます。 RAMの最後の静的変数は呼び出しスタックポインターであり、それ以降のすべてのメモリは呼び出しスタックとして機能します。サブプログラムが呼び出されると、すべてのローカル変数とリターンアドレス(ROM)を含む新しいフレームが呼び出しスタックに作成されます。プログラム内の各サブプログラムには、ポインターとして機能する1つの静的RAMアドレスが渡されます。このポインターは、呼び出しスタック内の「現在の」サブルーチン呼び出しの場所を設定します。ローカル変数への参照は、この静的ポインターの値とオフセットを使用して実行され、この特定のローカル変数のアドレスを指定します。呼び出しスタックには、静的ポインターの以前の値も含まれます。静的RAMの変数と上記のプログラムのサブルーチン呼び出しフレームの分布は次のとおりです。
RAM map:
0: pc
1: display
2: scratch0
3: fib
4: scratch1
5: scratch2
6: scratch3
7: call
fib map:
0: return
1: previous_call
2: cur
3: sum
ルーチンの興味深い点は、特定の値を返さないことです。サブルーチンの実行後、そのすべてのローカル変数を読み取ることができるため、サブルーチン呼び出しから多くのデータを抽出できます。これは、この特定のサブルーチン呼び出し用のポインターを格納することで実現されます。このポインターを使用して、(最近解放された)スタックフレームからすべてのローカル変数を復元できます。
サブルーチンはいくつかの方法で呼び出すことができ、それらはすべてキーワードを使用します
call
:
call fib(10); # ,
call pointer = fib(10); #
display = pointer.sum; #
call display = fib(10).sum; #
call display += fib(10).sum; #
サブルーチンを呼び出すには、任意の数の値を引数として指定できます。指定されていない引数はすべて、デフォルト値(存在する場合)で埋められます。引数が指定されておらず、クリアされたデフォルト値がない場合(命令/時間を節約するため)、サブルーチンの開始時に任意の値を取得できます。
ポインターはサブプログラムのいくつかのローカル変数にアクセスする方法ですが、このポインターは一時的なものではないことに注意することが重要です。サブプログラムを別の呼び出しを行うと、ポインターが指すデータは破棄されます。任意のブロックへの
タグのデバッグ
{...}
Cogolプログラムの前には、いくつかの単語の説明ラベルが付いている場合があります。このタグは、コンパイルされたアセンブラコードにコメントとして添付され、必要なコードフラグメントの検索を簡単にするため、デバッグに非常に役立ちます。
遷移遅延スロットの最適化
コンパイルされたコードの速度を上げるために、CogolコンパイラーはQFTASMコードの最後のパスとして、遷移遅延スロットの非常に簡単な最適化を実行します。空のジャンプ遅延スロットを使用した無条件ジャンプの場合、遅延スロットに最初の命令としてジャンプ命令を入力し、ジャンプアドレスを1増やして次の命令を示します。これにより、通常、無条件ジャンプが実行されるたびに1サイクル節約されます。
Cogolでテトリスコードを書く
完成したTetrisプログラムはCogolで記述されており、そのソースコードはこちらから入手できます。コンパイルされたQFTASMコードは、ここから入手できます。便宜上、パーマリンクはQFTASMのテトリスにリストされています。目標は(Cogolコードではなく)アセンブリコードを作成することであったため、結果のCogolコードはかなり面倒です。プログラムの多くの部分はルーチンに配置する必要がありますが、これらのルーチンは実際には非常に短いため、コードを複製することで構造よりも多くの命令を保存できます
call
。メインコードに加えて完成したコードには、サブルーチンが1つだけ含まれています。さらに、多くの配列が削除され、同じ長さの個々の変数のリスト、またはプログラム内の多くのハードコードされた数値のいずれかに置き換えられました。完成したコンパイル済みQFTASMコードに含まれる命令は300未満ですが、Cogolソースコード自体よりもわずかに長くなります。
パート5:アセンブリ、ブロードキャスト、および将来
コンパイラーからアセンブラープログラムを受け取ったら、Varlifeコンピューター用のROMのアセンブルを開始し、すべてを大きな「Life」ゲームパターンに変換できます。
組立
ROMでのアセンブラープログラムアセンブリは、従来のプログラミングとほぼ同じ方法で実行されます。各命令はバイナリアナログに変換され、すべて実行可能ファイルと呼ばれる1つの大きなバイナリオブジェクトに連結されます。私たちにとって唯一の違いは、バイナリを回路でブロードキャストし、コンピューターに接続する必要があることです。
K Zhangは、作成および翻訳するGolly用のPythonスクリプトCreateROM.pyを作成しました。スクリプトは非常に単純です。スクリプトは、クリップボードからアセンブラープログラムを受け取り、それをバイナリファイルに収集し、チェーンに変換します。スクリプトに含まれる簡易検証プログラムの例を次に示します。これは、次のバイナリファイルに変換されます。Varlifeチェーンでブロードキャストする場合、次のようになります。
#0. MLZ -1 3 3;
#1. MLZ -1 7 6; preloadCallStack
#2. MLZ -1 2 1; beginDoWhile0_infinite_loop
#3. MLZ -1 1 4; beginDoWhile1_trials
#4. ADD A4 2 4;
#5. MLZ -1 A3 5; beginDoWhile2_repeated_subtraction
#6. SUB A5 A4 5;
#7. SUB 0 A5 2;
#8. MLZ A2 5 0;
#9. MLZ 0 0 0; endDoWhile2_repeated_subtraction
#10. MLZ A5 3 0;
#11. MNZ 0 0 0; endDoWhile1_trials
#12. SUB A4 A3 2;
#13. MNZ A2 15 0; beginIf3_prime_found
#14. MNZ 0 0 0;
#15. MLZ -1 A3 1; endIf3_prime_found
#16. ADD A3 2 3;
#17. MLZ -1 3 0;
#18. MLZ -1 1 4; endDoWhile0_infinite_loop
0000000000000001000000000000000000010011111111111111110001
0000000000000000000000000000000000110011111111111111110001
0000000000000000110000000000000000100100000000000000110010
0000000000000000010100000000000000110011111111111111110001
0000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000011110100000000000000100000
0000000000000000100100000000000000110100000000000001000011
0000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000110100000000000001010001
0000000000000000000000000000000000000000000000000000000001
0000000000000000000000000000000001010100000000000000100001
0000000000000000100100000000000001010000000000000000000011
0000000000000001010100000000000001000100000000000001010011
0000000000000001010100000000000000110011111111111111110001
0000000000000001000000000000000000100100000000000001000010
0000000000000001000000000000000000010011111111111111110001
0000000000000000010000000000000000100011111111111111110001
0000000000000001100000000000000001110011111111111111110001
0000000000000000110000000000000000110011111111111111110001


次に、ROMがコンピューターに接続され、Varlifeで完全に機能するプログラムが作成されます。しかし、私たちはまだ終わっていません...
ゲーム「Life」にブロードキャスト
この間ずっと、Lifeゲームの上にさまざまな抽象化レイヤーを作成しました。しかし、今は抽象化のカーテンを引っ張り、私たちの仕事をゲーム「Life」のパターンに変換する時です。前述のように、Varlifeの基礎としてOTCA メタピクセルを使用します。したがって、最後のステップは、各VarlifeセルをLifeゲームのメタピクセルに変換することです。
幸い、Gollyには、OTCAメタピクセルの助けを借りてさまざまなルールのパターンをゲーム「Life」のパターンに変換できるスクリプト(metafier.py)があります。残念ながら、1つのグローバルルールセットを持つパターンのみを変換できるため、Varlifeでは機能しません。この問題を解決するために、修正版を作成しましたしたがって、各メタピクセルのルールは、セルごとにVarlifeに対して生成されます。
そのため、コンピューター(テトリスROM)には、1 436 x 5 082の境界長方形があります。この長方形の7 297 752セルのうち、6 075 811は空です。つまり、人口は1 221 941セルです。これらの各セルは、64,691(オン状態のメタピクセル)または23,920(オフ状態の状態)の人口を持つ2048 x 2048の境界長方形を持つOTCAメタピクセルに変換する必要があります。つまり、最終結果は、29,228,828,720から79,048,585,231の範囲の人口を持つ、2,940,928 x 10,407,936(メタピクセル境界に数千を加えた)の境界長方形を持つことになります。コンピューターとROMには27〜74ギガバイトが必要です。
これらの計算を設定したのは、スクリプトを実行する前にそれらを無視していたためで、すぐにコンピューターのメモリ不足に遭遇しました。コマンドのパニック実行後
kill
、metafierスクリプトに変更を加えました。メタピクセルが10行ごとに、パターンがディスクに(圧縮されたgzip RLEファイルとして)保存され、その後グリッドがクリアされます。これにより、変換の実行時間が長くなり、より多くのディスク容量が必要になりますが、メモリ使用のレベルは許容範囲内に留まります。 Gollyは、パターンの場所を含む拡張RLE形式を使用するため、パターンの読み込みが複雑になることはありません。1つのレイヤーですべてのパターンファイルを開くだけで済みます。
私の仕事に基づいて、K Zhang は改良されたメタファイラースクリプトを作成しました。、MacroCellファイル形式を使用します。これは、RLEよりも大きなパターンをロードする場合により効率的です。このスクリプトは非常に高速に動作し(元のメタファイラースクリプトの数時間とは異なり、わずか数秒)、はるかに少ない出力(1.7 GBの代わりに121 KB)を作成し、コンピューターとROM全体を一気にメタピクセルに変換できます。メモリ量。MacroCellファイルはパターンを記述するツリーをエンコードするという事実を使用します。特別なテンプレートファイルを使用して、メタピクセルがツリーに読み込まれ、特定の計算と変更を行った後、Varlifeパターンを単純に添付できます。
ゲーム「Life」のコンピューター全体とROMのパターンのファイルは、ここで取得できます。
今後のプロジェクト
それで、テトリスを作りました、それだけです。 種類はありません。 このプロジェクトには、現在取り組んでいる他の目標があります。
- muddyfishとKritixi Lithosは、QFTASMでコンパイルされた高水準言語の作業を続けています。
- El'endia StarmanはQFTASMオンライン通訳の更新に取り組んでいます。
- quartataは、GCCが独立したCおよびC ++コード(および場合によってはFortran、D、Objective-Cなどの言語)をQFTASMにコンパイルできるようにするGCCバックエンドに取り組んでいます。これにより、標準ライブラリがなくても、より使い慣れた言語でより複雑なプログラムを作成できます。
- , , , , - (PIC) (.. ). PIC , . PIC.
- , QFT. Pong.
6: QFTASM
Cogol言語はTetrisのかなり初歩的な実装ですが、汎用プログラミングには読みやすいレベルでは単純すぎて低レベルです。
2016年9月に新しい言語の作業を開始しました。言語開発のプロセスは、実生活のように理解しにくいエラーのために遅かった。
単純な型システム、再帰対応ルーチン、埋め込みステートメントなど、Pythonに似た構文で低レベル言語を作成しました。
QFTASMテキストコンパイラは、トークナイザ、文法ツリー、高レベルコンパイラ、低レベルコンパイラの4段階で作成されました。
トークナイザー
Pythonの開発は、組み込みのトークナイザーライブラリの使用から始まりました。つまり、この手順は非常に簡単でした。
コメントの切り取りを含む、デフォルト出力への小さな変更のみを行う必要がありました(ただし、変更は行いません
#include
)。
文法ツリー
文法ツリーは、ソースコードを変更せずに便利に拡張できるように設計されています。
ツリーの構造は、ツリーを構成するノードの構造と、他のノードおよびトークンとの接続を含むXMLファイルに格納されます。
文法は、オプションのノードだけでなく、繰り返しノードをサポートすることになっています。トークンの読み取り方法を記述するメタタグを追加することにより、この問題を解決しました。
生成されたトークンは、たとえば、出力が文法要素のツリーを形成するような方法で、文法規則に従って解析され、
sub
さらに
generic_variables
他の文法要素とトークンが含まれます。
高レベルコードへのコンパイル
各言語関数は、高レベルの構造にコンパイルする必要があります。たとえば、
assign(a, 12)
および
call_subroutine(is_prime, call_variable=12, return_variable=temp_var)
。要素の埋め込みなどの機能は、このセグメントで実行されます。それらは定義されます
operator
、それらの特異性はそれらがなどのオペレータ
+
が使用されるたびに埋め込まれるということ
%
です。したがって、通常のコードよりも制限されています。特定の演算子に応じて、独自の演算子や他の演算子を使用することはできません。
埋め込みの過程で、内部変数は呼び出された変数に置き換えられます。これは:
operator(int a + int b) -> int c
return __ADD__(a, b)
int i = 3+3
になります
int i = __ADD__(3, 3)
ただし、入力変数と出力変数がメモリ内の同じ場所を指している場合、この動作は悪意があり、エラーが発生しやすくなります。より安全な動作を使用
unsafe
するために、これらの追加変数が作成され、必要に応じて置換からコピーされるように、キーワードはコンパイルプロセスを制御します。
スクラッチ変数と複雑な操作
フォームの数学演算は、
a += (b + c) * 4
追加のメモリセルを使用しないと計算できません。高レベルコンパイラは、操作を異なる部分に分割することでこの問題に対処します。したがって、計算の中間情報を格納するために使用される一時変数の概念が導入されます。必要に応じて割り当てられ、共通プールでの作業の完了後に解放されます。これにより、操作に必要な一時メモリの量を減らすことができます。一時変数はグローバルと見なされます。各ルーチンには、そのルーチンで使用されるすべての変数とその型への参照を格納するための独自のVariableStoreがあります。コンパイルの最後に、リポジトリの先頭からの相対オフセットに変換され、RAM内の有効なアドレスが与えられます。
scratch_1 = b + c
scratch_1 = scratch_1 * 4
a = a + scratch_1
RAM構造
( )
...
低レベルのコンパイル
-低レベルのコンパイラで動作するように持っている唯一のこと
sub
、
call_sub
、
return
、
assign
、
if
と
while
。これは大幅に削減されたタスクリストであり、QFTASM命令に変換すると便利です。
sub
名前付きルーチンの開始と終了を設定します。低レベルコンパイラはラベルを追加し、サブルーチンの場合は
main
exitステートメントを追加します(ROMの最後にジャンプします)。
if
そして while
低レベルの通訳
while
と
if
非常にシンプル:彼らは彼らの状態とその依存移行へのポインタです。ループは
while
、次のようにコンパイルされるという点でわずかに異なります
...
:
...
call_sub
そして return
ほとんどのアーキテクチャとは異なり、コンパイル対象のコンピューターは、スタックの追加と削除をハードウェアでサポートしていません。つまり、スタックへの追加とスタックからの削除にはそれぞれ2つの命令が必要です。抽出の場合、スタックポインターをデクリメントし、値をアドレスにコピーします。追加する場合は、アドレスから現在のスタックポインターのアドレスに値をコピーし、インクリメントを実行します。
サブルーチンのすべてのローカル変数は、コンパイル時に指定された固定RAMロケーションに保存されます。再帰を実装するには、関数のすべてのローカル変数が呼び出しの開始時にスタックにプッシュされます。サブルーチンの引数は、ローカル変数ストアの位置にコピーされます。戻りアドレス値がスタックにプッシュされ、サブルーチンが実行されます。
コンストラクトが検出されると
return
、スタックの最上部が取得され、命令カウンターがこの値に設定されます。呼び出しルーチンのローカル変数の値は、スタックの最上部から取得され、以前の位置に戻ります。
assign
変数の割り当ては、コンパイルする最も簡単な方法です。変数と値を取得し、それらを1行にコンパイルする必要があります。
MLZ -1 VALUE VARIABLE
紹介アドレスの割り当て
最後に、コンパイラは、命令に追加されたラベルのジャンプアドレスを作成します。マークの絶対位置が決定され、その後、これらのマークへの参照がこれらの値に置き換えられます。ラベル自体はコードから削除され、その後、最後に命令番号がコンパイルされたコードに追加されます。
段階的なコンパイルの例
すべての段階を経て、このプログラムをコンパイルするプロセスをステップスルーしてみましょう。とても簡単です。これは、そのプログラムの最後に明らかです、、。開始するために、適切なパーツを挿入してみましょう。したがって、すべてが少し複雑になりました。トークナイザーに進み、何が起こるか見てみましょう。この段階では、構造のないトークンの線形ストリームしかありませんが、すべてのトークンは文法パーサーを通過し、各部分の名前を持つツリーが表示されます。読み取りコードの高レベルの構造を示します。
#include stdint
sub main
int a = 8
int b = 12
int c = a * b
a = 8
b = 12
c = 96
stdint.txt
operator (int a + int b) -> int
return __ADD__(a, b)
operator (int a - int b) -> int
return __SUB__(a, b)
operator (int a < int b) -> bool
bool rtn = 0
rtn = __MLZ__(ab, 1)
return rtn
unsafe operator (int a * int b) -> int
int rtn = 0
for (int i = 0; i < b; i+=1)
rtn += a
return rtn
sub main
int a = 8
int b = 12
int c = a * b
NAME NAME operator
LPAR OP (
NAME NAME int
NAME NAME a
PLUS OP +
NAME NAME int
NAME NAME b
RPAR OP )
OP OP ->
NAME NAME int
NEWLINE NEWLINE
INDENT INDENT
NAME NAME return
NAME NAME __ADD__
LPAR OP (
NAME NAME a
COMMA OP ,
NAME NAME b
RPAR OP )
...
GrammarTree file
'stmts': [GrammarTree stmts_0
'_block_name': 'inline'
'inline': GrammarTree inline
'_block_name': 'two_op'
'type_var': GrammarTree type_var
'_block_name': 'type'
'type': 'int'
'name': 'a'
'_global': False
'operator': GrammarTree operator
'_block_name': '+'
'type_var_2': GrammarTree type_var
'_block_name': 'type'
'type': 'int'
'name': 'b'
'_global': False
'rtn_type': 'int'
'stmts': GrammarTree stmts
...
この文法ツリーは、高レベルのコンパイラによる解析情報を設定します。構造のタイプと変数の属性に関する情報が含まれています。次に、文法ツリーはこの情報を取得し、ルーチンに必要な変数を割り当てます。ツリーはすべての順列も挿入します。次に、低レベルコンパイラはこの高レベルビューをQFTASMコードに変換する必要があります。変数には、次のようにRAM内の場所が割り当てられます。次に、単純な命令がコンパイルされます。最後に、命令番号が追加され、結果はQFTASM実行可能コードになります。
('sub', 'start', 'main')
('assign', int main_a, 8)
('assign', int main_b, 12)
('assign', int op(*:rtn), 0)
('assign', int op(*:i), 0)
('assign', global bool scratch_2, 0)
('call_sub', '__SUB__', [int op(*:i), int main_b], global int scratch_3)
('call_sub', '__MLZ__', [global int scratch_3, 1], global bool scratch_2)
('while', 'start', 1, 'for')
('call_sub', '__ADD__', [int op(*:rtn), int main_a], int op(*:rtn))
('call_sub', '__ADD__', [int op(*:i), 1], int op(*:i))
('assign', global bool scratch_2, 0)
('call_sub', '__SUB__', [int op(*:i), int main_b], global int scratch_3)
('call_sub', '__MLZ__', [global int scratch_3, 1], global bool scratch_2)
('while', 'end', 1, global bool scratch_2)
('assign', int main_c, int op(*:rtn))
('sub', 'end', 'main')
int program_counter
int op(*:i)
int main_a
int op(*:rtn)
int main_c
int main_b
global int scratch_1
global bool scratch_2
global int scratch_3
global int scratch_4
global int <result>
global int <stack>
0. MLZ 0 0 0;
1. MLZ -1 12 11;
2. MLZ -1 8 2;
3. MLZ -1 12 5;
4. MLZ -1 0 3;
5. MLZ -1 0 1;
6. MLZ -1 0 7;
7. SUB A1 A5 8;
8. MLZ A8 1 7;
9. MLZ -1 15 0;
10. MLZ 0 0 0;
11. ADD A3 A2 3;
12. ADD A1 1 1;
13. MLZ -1 0 7;
14. SUB A1 A5 8;
15. MLZ A8 1 7;
16. MNZ A7 10 0;
17. MLZ 0 0 0;
18. MLZ -1 A3 4;
19. MLZ -1 -2 0;
20. MLZ 0 0 0;
構文
それで、私たちは単純な言語を持ち、それに小さなプログラムを書く必要があります。Pythonのようにインデントを使用して、論理ブロックとコマンドのフローを分離します。つまり、プログラムではスペースが重要です。完成した各プログラムには、Cに似た言語の
main
機能として機能するサブルーチンがあり
main()
ます。この関数は、プログラムの開始時に実行されます。
変数と型
変数を初めて設定するときは、それに関連付けられた型が必要です。これまでに、指定された型
int
と
bool
指定された配列がありますが、コンパイラ構文はありません。
ライブラリと演算子
stdint.txt
基本的な演算子を定義するライブラリがあります。プログラムに組み込まれていない場合、最も単純な演算子でさえ定義されません。このライブラリはで使用できます
#include stdint
。
stdint
以下のような定義オペレータ
+
、
>>
およびさらに
*
有する
%
ない直接オペコードQFTASMを有するいずれも、。
さらに、この言語では、を使用してQFTASMオペコードを直接呼び出すことができます
__OPCODENAME__
。
では
stdint
、次のように定義された追加このエントリをオペレータがいると判断、彼は2つの数値を渡されたときに行う必要があります。
operator (int a + int b) -> int
return __ADD__(a, b)
+
int