みなさんこんにちは!
今日は位置の視覚化についてお話します。 空間参照を明確に持っている統計を手元に持っているので、常に美しい地図を作りたいと思うでしょう。 できれば、ノートブックのナビゲーションおよび情報ウィンドウを使用してください。 そしてもちろん、後でインターネット全体に視覚化の進捗状況を示すことができるように!
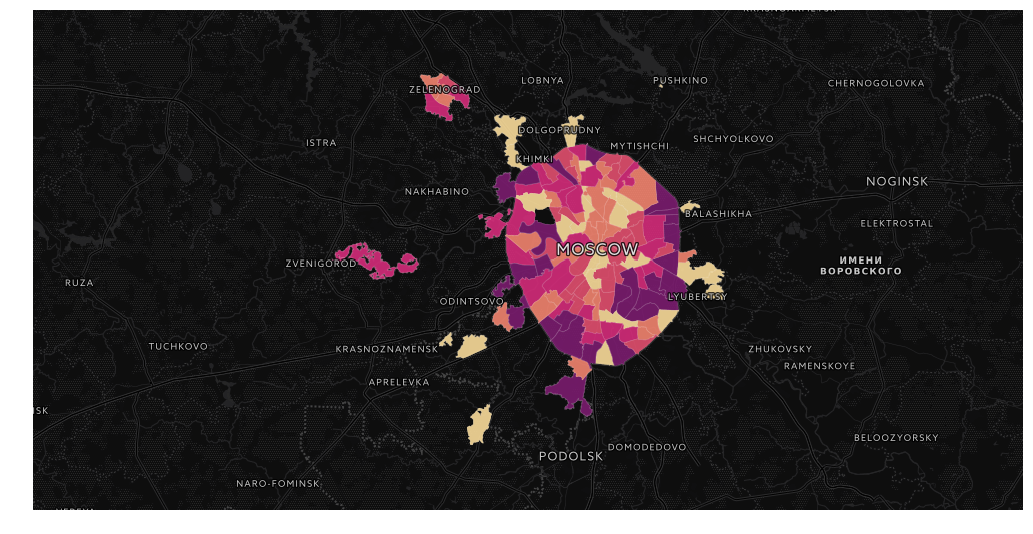
例として、モスクワで最近衰退している地方選挙を考えてみましょう。 データ自体はモスクワ市選挙管理委員会のウェブサイトから取得できます 。データセットはhttps://gudkov.ru/から取得できます 。 そこには何らかの視覚化もありますが、さらに深くなります。 だから、私たちは何で終わるべきですか?
選挙委員会のサイトのパーサーを書くのに少し時間を費やして、必要なデータを受け取りました。 それでは、インポートから始めましょう。
import pandas as pd import numpy as np import os import pickle
Linuxマシンでjupyterノートブックを使用しています。 Windowsマシンでコードを使用する場合は、テキストの重要な逸脱だけでなく、パスの記述にも注意してください。
通常、プロジェクトには個別のフォルダーを使用するため、簡単にするために現在のディレクトリを設定します。
os.chdir('/data01/jupyter/notebooks/habr/ods_votes/')
さらに、選挙委員会のサイト自体からデータを収集する必要があります。 データを解析するために、別のパーサーを作成しました。 プロセス全体には10〜15分かかります。 リポジトリから取得できます 。
データフレームを内部に持つ大きな辞書を作成することにしました。 htmlページをデータフレームに変換するために、read_htmlを使用し、必要なデータフレームを経験的に選択し、その後少し処理を行い、余分な部分を捨てて不足分を追加しました。 以前は、当事者に関するデータをすでに処理していました。 最初は、それらは特に読みやすくありませんでした。 さらに、同じパーティーの異なるスペルがあります(面白いですが、場合によっては異なるスペルではなく、実際には異なる部分です)。
選挙委員会のデータの分析
ディレクトリを直接組み立てます。 ここで何が起こっていますか:
- 行政および市区町村の構造が組み立てられています。
- 地域選挙委員会(TEC)への言及はすべて収集されます。
- 各TECについて、候補者のリストが収集されます。
- 各TEC内には、地区選挙委員会(OEC)が集まります。
- DECの統計と候補者の統計は、DECごとに収集されます。
- 受信したデータセットから市区町村の統計を収集します。
この記事のリポジトリには、既製のデータが含まれています。 それらを使用します。
import glob # with open('tmp/party_aliases.pkl', 'rb') as f: party_aliases = pickle.load(f) votes = {} # votes['atd'] = pd.read_csv('tmp/atd.csv', index_col=0, sep=';') votes['data'] = {} # for v in votes['atd']['municipal'].values: votes['data'][v] = {} # candidates = glob.glob('tmp/data_{}_candidates.csv'.format(v))[0] votes['data'][v]['candidates'] = pd.read_csv(candidates, index_col=0, sep=';') votes['data'][v]['votes'] = {} # # okrug_stats_list = glob.glob('tmp/data_{}*_okrug_stats.csv'.format(v)) for okrug_stats in okrug_stats_list: okrug = int(okrug_stats.split('_')[2]) try: votes['data'][v]['votes'][okrug] except: votes['data'][v]['votes'][okrug] = {} votes['data'][v]['votes'][okrug]['okrug_stats'] = pd.read_csv(okrug_stats, index_col=0, sep=';') # candidates_stats_list = glob.glob('tmp/data_{}*_candidates_stats.csv'.format(v)) for candidates_stats in candidates_stats_list: okrug = int(candidates_stats.split('_')[2]) votes['data'][v]['votes'][okrug]['candidates_stats'] = pd.read_csv(candidates_stats, index_col=0, sep=';') # data = [] # for okrug in list(votes['data'].keys()): # candidates = votes['data'][okrug]['candidates'].replace(to_replace={'party':party_aliases}) group_parties = candidates[['party','elected']].groupby('party').count() # stats = np.zeros(shape=(12)) for oik in votes['data'][okrug]['votes'].keys(): stat = votes['data'][okrug]['votes'][oik]['okrug_stats'].iloc[:,1] stats += stat # # sum_parties = group_parties.sum().values[0] # data_parties = candidates[['party','elected']].groupby('party').count().reset_index() # data_parties['percent'] = data_parties['elected']/sum_parties*100 # tops = data_parties.sort_values('elected', ascending=False) c = pd.DataFrame({'okrug':okrug}, index=[0]) c['top1'], c['top1_elected'], c['top1_percent'] = tops.iloc[0,:3] c['top2'], c['top2_elected'], c['top2_percent'] = tops.iloc[1,:3] c['top3'], c['top3_elected'], c['top3_percent'] = tops.iloc[2,:3] c['voters_oa'], c['state_rec'], c['state_given'], c['state_anticip'], c['state_out'], c['state_fired'], c['state_box'], c['state_move'], c['state_error'], c['state_right'], c['state_lost'] , c['state_unacc'] = stats c['voters_percent'] = (c['state_rec'] - c['state_fired'])/c['voters_oa']*100 c['total'] = sum_parties c['full'] = (c['top1_elected']== sum_parties) # data.append(c) # winners = pd.concat(data,axis=0)
投票率、投票数(発行された数から破損した数まで)、パーティー間の座席の分布に関する統計情報を含むデータフレームを取得しました。
視覚化を開始できます!
ジオパンダのジオデータを使用した基本作業
ジオデータを操作するには、geopandasライブラリを使用します。 ジオパンダとは何ですか? これは、地理的抽象化によるパンダの機能の拡張(Shapelyから継承)であり、選択、オーバーレイ、集計(PostgresqlのPostGISなど)のジオデータで地理的操作を分析できます。
ジオメトリには3つの基本的なタイプがあることを思い出させてください-ポイント、ライン(または、接続されたセグメントで構成されているためポリライン)、およびポリゴン。 それらのすべてには、マルチ(マルチ)のオプションがあり、ジオメトリは、個々の地理的エンティティを1つに組み合わせたものです。 たとえば、地下鉄の出口はポイントかもしれませんが、「駅」の本質に組み込まれたいくつかの出口はすでにマルチポイントです。
geopandasは、Windows環境の標準的なPythonインストールでは、pipを介してインストールすることに消極的であることに注意してください。 問題は、いつものように、依存関係です。 Geopandasは、Windows用の公式ビルドがないfionaライブラリの抽象化に依存しています。 たとえば、DockerコンテナーでLinux環境を使用することが理想的です。 さらに、Windowsでは、condaマネージャーを使用して、リポジトリからすべての依存関係をプルできます。
市町村のジオメトリでは、すべてが非常に簡単です。 これらは、OpenStreetMap( 詳細はこちら )またはNextGIS アップロードなどから簡単に取得できます。 既製の図形を使用します。
それでは始めましょう! 必要なインポートを実行し、matplotlibチャートをアクティブにします...
import geopandas as gpd %matplotlib inline mo_gdf = gpd.read_file('atd/mo.shp') mo_gdf.head()
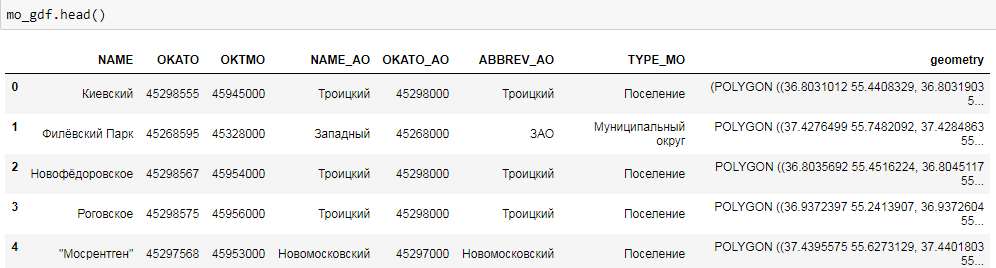
ご覧のとおり、これは使い慣れたDataFrameです。 ジオメトリフィールドは、WKT形式の地理オブジェクト(この場合はポリゴン)の表現であり、よく知られているテキストです(詳細については、 https://en.wikipedia.org/wiki/Well-known_textを参照してください )。 オブジェクトのマップを簡単に作成できます。
mo_gdf.plot()

モスクワを推測! 確かに、あまり馴染みがないようです。 その理由は、地図の投影です。 Habrには既に優れた教育プログラムがあります。
そのため、より使い慣れたWebメルカトル図法でデータを表示します(crsパラメーターを使用して、初期図法を簡単に取得できます)。 行政区の名前でポリゴンに色を付けます。 線の幅を0.5に設定します。 cmapのカラーリング方法は、標準のmatplotlib値を使用します(私のように、覚えていない場合は、 ここにチートシートがあります )。 マップの凡例を表示するには、凡例パラメーターを設定します。 さて、figsizeはマップのサイズを決定します。
mo_gdf_wm = mo_gdf.to_crs({'init' :'epsg:3857'}) # mo_gdf_wm.plot(column = 'ABBREV_AO', linewidth=0.5, cmap='plasma', legend=True, figsize=[15,15])

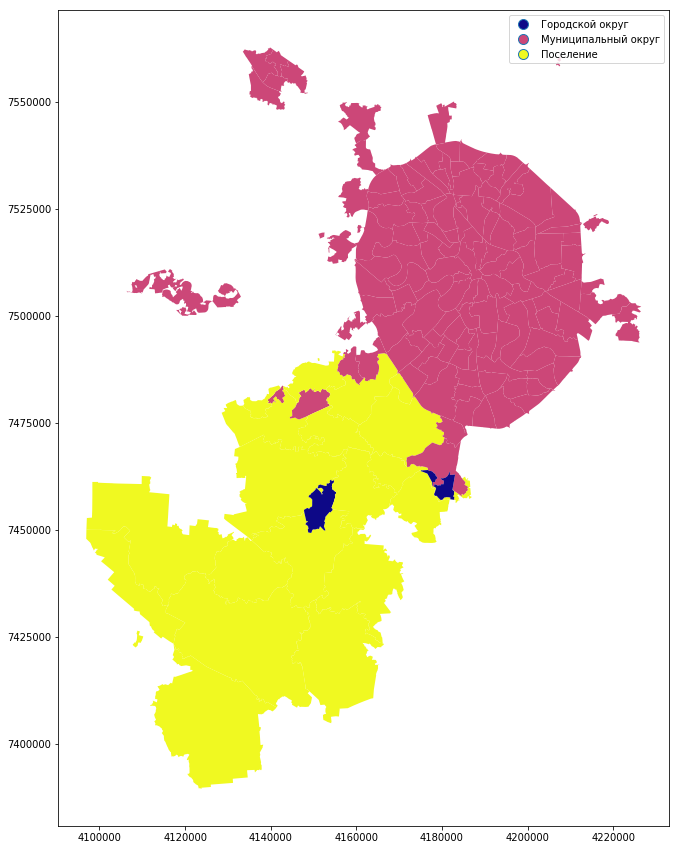
自治体の種類ごとに地図を作成できます。
mo_gdf_wm.plot(column = 'TYPE_MO', linewidth=0.5, cmap='plasma', legend=True, figsize=[15,15])
そのため、市区町村の統計マップを作成します。 先に、勝者のデータフレームを作成しました。
データフレームとジオデータフレームを組み合わせて地図を作成する必要があります。 少しの髪が市区町村の名前をcombくので、驚くことなくつながりができました。
winners['municipal_low'] = winners['okrug'].str.lower() winners['municipal_low'] = winners['municipal_low'].str.replace('', '') mo_gdf_wm['name_low'] = mo_gdf_wm['NAME'].str.lower() mo_gdf_wm['name_low'] = mo_gdf_wm['name_low'].str.replace('', '') full_gdf = winners.merge(mo_gdf_wm[['geometry', 'name_low']], left_on='municipal_low', right_on='name_low', how='left') full_gdf = gpd.GeoDataFrame(full_gdf)
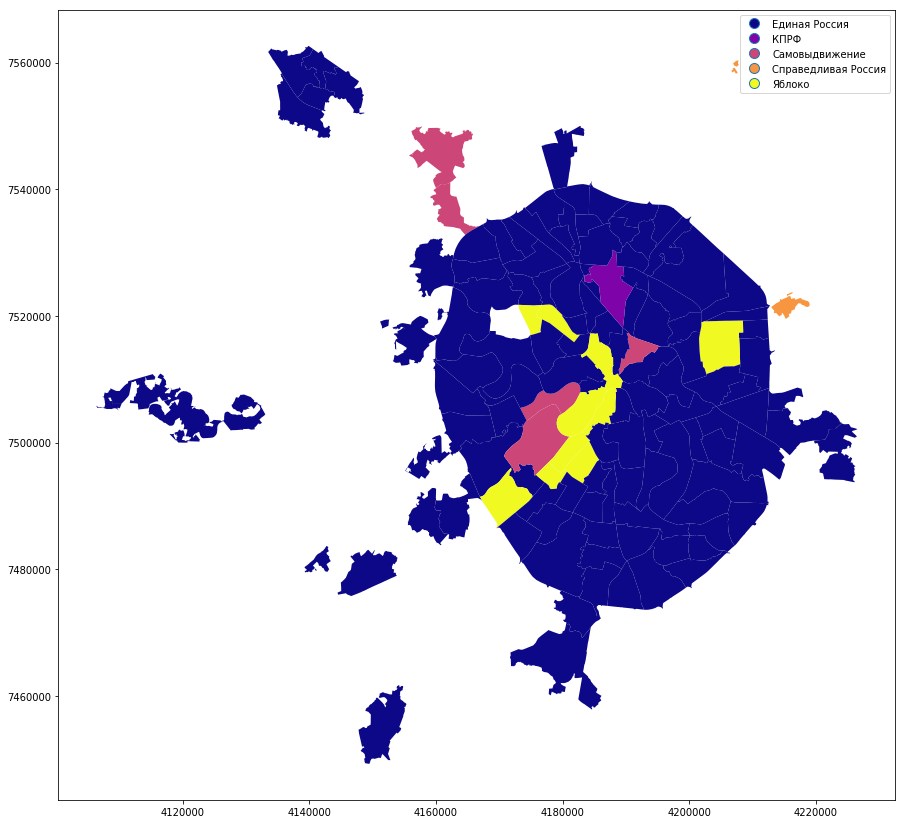
勝者が表示される単純なカテゴリマップを作成します。 今年のシュキノーノ地区では、実際に選挙はありませんでした。
full_gdf.plot(column = 'top1', linewidth=0, cmap='GnBu', legend=True, figsize=[15,15])
投票率:
full_gdf.plot(column = 'voters_percent', linewidth=0, cmap='BuPu', legend=True, figsize=[15,15])
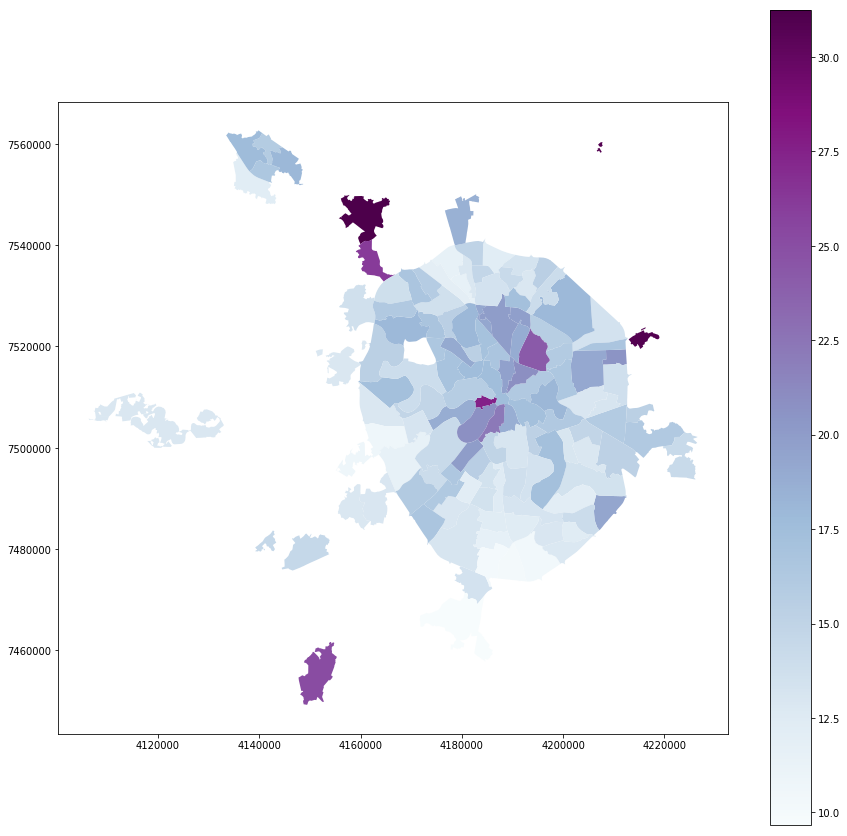
居住者:
full_gdf.plot(column = 'voters_oa', linewidth=0, cmap='YlOrRd', legend=True, figsize=[15,15])

いいね! 素晴らしい視覚化を得ました。 しかし、ベースマップとナビゲーションの両方が必要です。 cartoframesライブラリは私たちの助けになります。
カートフレームを使用したジオデータの視覚化
ジオデータの視覚化に最も便利なツールの1つがCartoです。 このサービスを使用するために、cartoframesライブラリがあります。これにより、Jupyterノートブックからサービスの機能を直接操作できます。
cartoframesライブラリは、設計機能のためにWindowsで慎重に扱う必要があります(たとえば、データセットに入力するとき、ライブラリはlinuxフォルダスタイルを使用しようとしますが、これは悲しい結果につながります)。 キリル文字データを使用すると、自分の足を簡単に撃つことができます(cp1251エンコードをクラコジアブリーに変換できます)。 DockerコンテナまたはフルLinuxで使用することをお勧めします。 ライブラリはpipを介してのみ配置されます。 Windowsでは、conda経由でgeopandasを最初にインストールすることで(またはすべての依存関係を手動で設定することで)、正常にインストールできます。
CartoframesはWGS84投影で動作します。 データセットを再投影します。 2つのデータフレームを接続すると、投影情報が失われる場合があります。 再度設定し、再投影します。
full_gdf.crs = ({'init' :'epsg:3857'}) full_gdf = full_gdf.to_crs({'init' :'epsg:4326'})
必要なインポートを行う...
import cartoframes import json import warnings warnings.filterwarnings("ignore")
Cartoアカウントからデータを追加します。
USERNAME = ' Carto' APIKEY = ' API'
最後に、Cartoに接続してデータセットを入力します。
cc = cartoframes.CartoContext(api_key=APIKEY, base_url='https://{}.carto.com/'.format(USERNAME)) cc.write(full_gdf, encode_geom=True, table_name='mo_votes', overwrite=True)
データセットは、Cartoからアンロードできます。 ただし、これまでのところ、完全なジオデータフレームはプロジェクト内にのみ存在します。 確かに、gdalとshapelyを使用して、PostGISジオメトリのバイナリ表現をWKTに戻すことができます。
プラグインの機能は型キャストです。 残念ながら、現在のバージョンでは、各列にstr型が割り当てられたデータフレームがテーブルに注がれています。 これは、カードを操作するときに覚えておく必要があります。
最後に地図! データに色を付け、ベースマップに配置してナビゲーションを有効にします。 ここで染色パターンを見ることができます 。
クラス分割の通常の作業では、型キャストを使用してクエリを作成します。 PostgreSQLの構文
query_layer = 'select cartodb_id, the_geom, the_geom_webmercator, voters_oa::integer, voters_percent::float, state_out::float from mo_votes'
したがって、投票率:
from cartoframes import Layer, BaseMap, styling, QueryLayer l = QueryLayer(query_layer, color={'column': 'voters_percent', 'scheme': styling.darkMint(bins=7)}) map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)
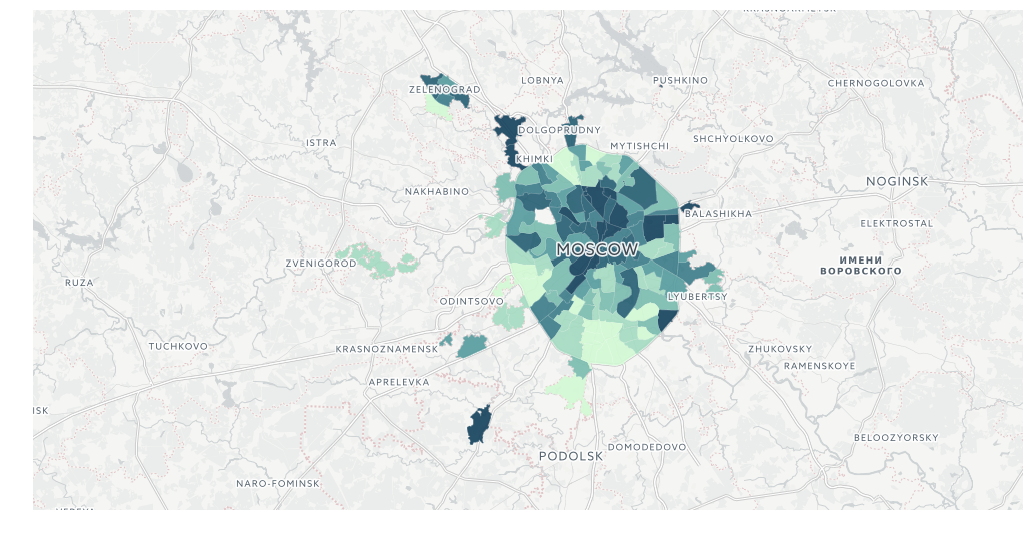
住民数
l = QueryLayer(query_layer, color={'column': 'voters_oa', 'scheme': styling.burg(bins=7)}) map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)

そして、例えば、自宅投票
l = QueryLayer(query_layer, color={'column': 'state_out', 'scheme': styling.sunsetDark(bins=5)}) map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)
現時点では、cartoframesでは、情報ウィンドウをノートブックウィンドウに直接埋め込み、凡例を表示し、地図をCartoに公開することはできません。 ただし、これらのオプションは実装中です。
Jupyter Notebookにカードを埋め込む、より複雑で非常に柔軟な方法を試してみましょう...
Foliumを使用して位置を視覚化する
そのため、ナビゲーションだけでなく、地図上の情報ウィンドウも取得したいと考えています。 また、サーバーまたはgithubで視覚化を公開する機会を得ます。 フォリウムは私たちを助けてくれます。
Foliumライブラリは非常に特殊なものです。 これは、地図作成の視覚化を担当するLeaflet JSライブラリのPythonラッパーです。 次の操作はあまり見た目はよくありませんが、心配する必要はありません。すべてを説明します。
import folium
Cartoのようなシンプルな視覚化は簡単です。 何が起こっているの?
- 選択した座標の中心にマップインスタンスmを作成します。
- カートグラムのインスタンスを追加(コロプレス)
カートグラムインスタンスでは、多くの属性を設定します。 - geo_data-ジオデータ。データフレームのデータをgeojsonに変換します。
- name-レイヤーの名前を設定します;
- データ-データ自体、データフレームからも選択します。
- key_on-接続するキー(geojsonでは、すべての属性が個別の要素、プロパティに折り畳まれていることに注意してください);
- 列-カラーリングのキーと属性。
- fill_color、fill_opacity、line_weight、line_opacity-塗りつぶしカラースケール、塗りつぶし透明度、線幅、透明度。
- legend_name-凡例のタイトル。
- ハイライト-オブジェクトのインタラクティブ機能(ホバー時の強調表示とクリック時の拡大)を追加します。
カラースケールはColor Brewerライブラリに基づいています 。 カードを扱う際に使用することを強く推奨します。
m = folium.Map(location=[55.764414, 37.647859]) m.choropleth( geo_data=full_gdf[['okrug', 'geometry']].to_json(), name='choropleth', data=full_gdf[['okrug', 'voters_oa']], key_on='feature.properties.okrug', columns=['okrug', 'voters_oa'], fill_color='YlGnBu', line_weight=1, fill_opacity=0.7, line_opacity=0.2, legend_name='type', highlight = True ) m
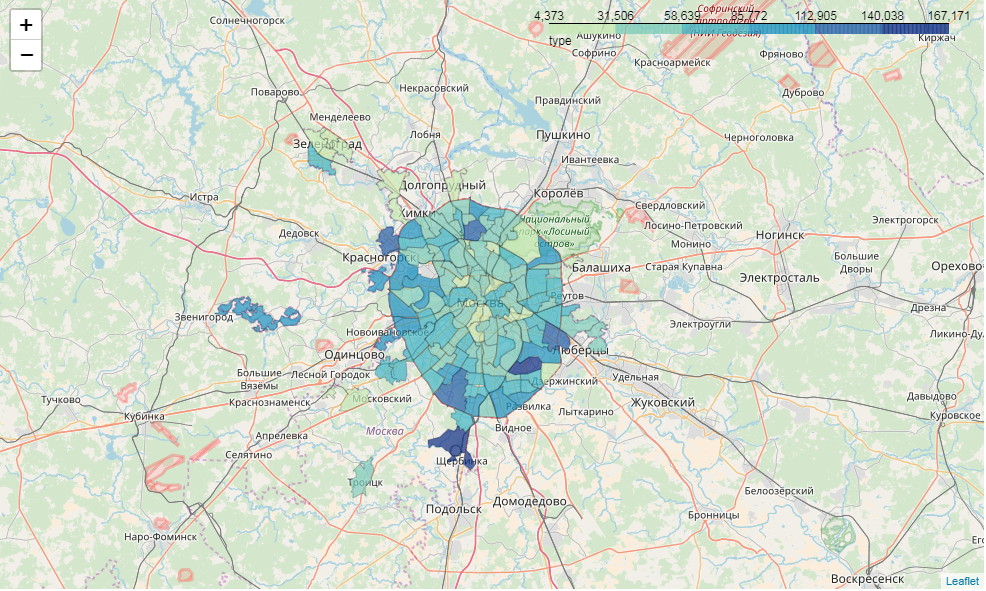
したがって、インタラクティブなカートグラムがあります。 しかし、情報ウィンドウが欲しいのですが...
ここでは、小さなライブラリをハックする必要があります。 各TECには勝者がいます。 それらのそれぞれについて、基本色を決定します。 しかし、すべての地区で党の勝利が投票の100%を意味するわけではありません。 各基本色に対して、絶対パワー(100%)、制御ステーク(> 50%)、および協調(<50%)の3つのグラデーションを定義します。 色を決定する関数を書きましょう:
def party_color(feature): party = feature['properties']['top1'] percent = feature['properties']['top1_percent'] if party == ' ': if percent == 100: color = '#969696' elif 50 < percent < 100: color = '#bdbdbd' else: color = '#d9d9d9' elif party == '': if percent == 100: color = '#78c679' elif 50 < percent < 100: color = '#addd8e' else: color = '#d9f0a3' elif party == '': if percent == 100: color = '#ef3b2c' elif 50 < percent < 100: color = '#fb6a4a' else: color = '#fc9272' elif party == ' ': if percent == 100: color = '#2171b5' elif 50 < percent < 100: color = '#4292c6' else: color = '#6baed6' elif party == '': if percent == 100: color = '#ec7014' elif 50 < percent < 100: color = '#fe9929' else: color = '#fec44f' return {"fillColor":color, "fillOpacity":0.8,"opacity":0}
次に、情報ウィンドウのhtml生成関数を作成します。
def popup_html(feature): html = '<h5> {}</h5>'.format(feature['properties']['okrug']) for p in ['top1', 'top2', 'top3']: if feature['properties'][p + '_elected'] > 0: html += '<br><b>{}</b>: {} '.format(feature['properties'][p], feature['properties'][p + '_elected']) return html
最後に、データフレームの各オブジェクトをgeojsonに変換してマップに追加し、各スタイル、ホバー動作、および情報ウィンドウにアタッチします
m = folium.Map(location=[55.764414, 37.647859], zoom_start=9) for mo in json.loads(full_gdf.to_json())['features']: gj = folium.GeoJson(data=mo, style_function = party_color, control=False, highlight_function=lambda x:{"fillOpacity":1, "opacity":1}, smooth_factor=0) folium.Popup(popup_html(mo)).add_to(gj) gj.add_to(m) m
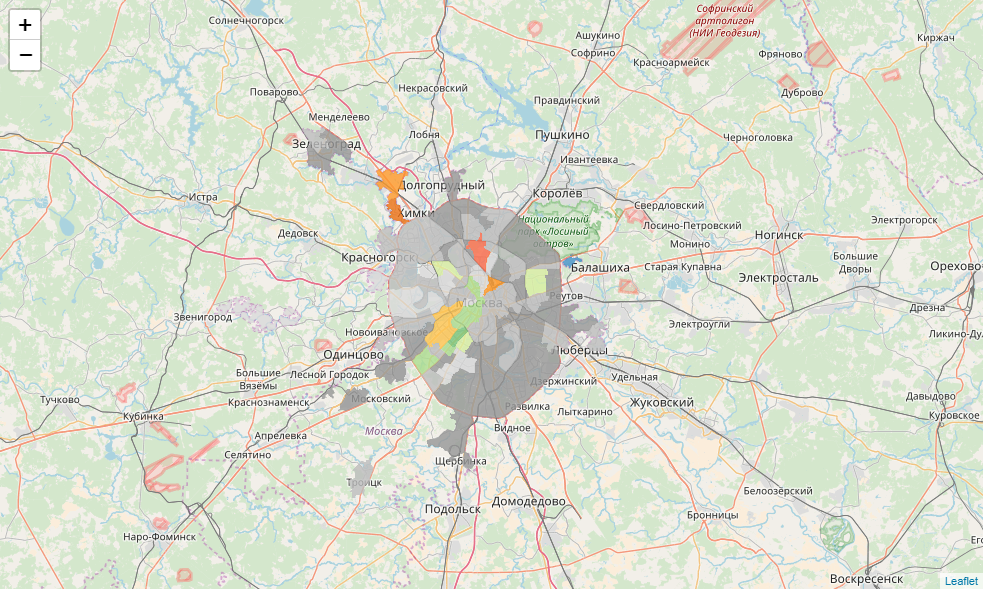
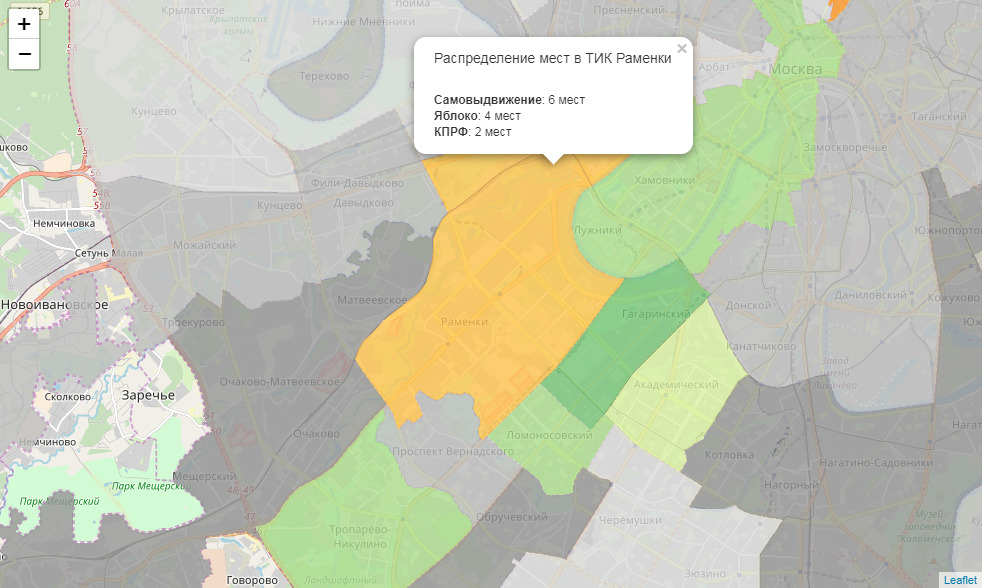
最後に、マップを保存します。 たとえば、 Githubで公開できます。
m.save('tmp/map.html')
おわりに
シンプルなロケーション可視化ツールを使用すると、洞察の無限の範囲を見つけることができます。 そして、データと視覚化に関する少しの作業で、洞察をCartoまたはgithubで正常に公開できます。 この記事のリポジトリ 。
おめでとうございます、あなたは今、政治学者です!

選挙結果を分析することを学びました。 コメントで洞察を共有してください!