 念のため、GitHubが最大のソフトウェア開発プラットフォームの1つであり、多くの人気のあるオープンソースプロジェクトの本拠地であることを忘れました。 Explore GitHubページでは、人気が高まっているプロジェクト、好きな人が購読しているプロジェクト、および方向やプログラミング言語ごとにグループ化された人気のあるプロジェクトに関する情報を見つけることができます。
念のため、GitHubが最大のソフトウェア開発プラットフォームの1つであり、多くの人気のあるオープンソースプロジェクトの本拠地であることを忘れました。 Explore GitHubページでは、人気が高まっているプロジェクト、好きな人が購読しているプロジェクト、および方向やプログラミング言語ごとにグループ化された人気のあるプロジェクトに関する情報を見つけることができます。
あなたが見つけられないのは、あなたの活動に基づいたプロジェクトの個人的な推薦です。 ユーザーは毎日さまざまなプロジェクトに膨大な数の星を付けており、この情報を使用して推奨事項を簡単に作成できるため、これはやや驚くべきことです。
この記事では、アイデアから実装までGitHubの推奨システムを構築した経験を共有します。
アイデア
各GitHubユーザーは、好きなプロジェクトにスターを付けることができます。 各ユーザーがどのリポジトリを評価したかについての情報があるため、同様のユーザーを見つけて、まだ見たことがないかもしれないが似た趣味のユーザーがすでに気に入っているプロジェクトに注意を払うことをお勧めします。 スキームは反対方向に機能します。ユーザーがすでに気に入っているプロジェクトに似たプロジェクトを見つけて、彼に推奨することができます。
言い換えると、アイデアは次のように定式化できます:ユーザーと設定したスターに関するデータを取得し、このデータに協調フィルタリングメソッドを適用し、すべてをWebアプリケーションにラップします。
データ収集
GHTorrentは、パブリックGitHub APIを使用して取得したデータを収集し、毎月のMySQLダンプを考慮してデータへのアクセスを提供する素晴らしいプロジェクトです。 これらのダンプはGHTorrentサイトのダウンロードセクションにあります。
各ダンプ内には、データベーススキーマの説明を含むSQLファイルと、テーブルのデータを含むいくつかのCSVファイルがあります。 前のセクションで述べたように、私たちのアプローチは協調フィルタリングに基づいています。 このアプローチは、ユーザーとその好みに関する情報、またはGitHubの観点から言い換えると、ユーザーがさまざまなプロジェクトに設定したユーザーとスターに関する情報が必要であることを意味します。
幸いなことに、上記のダンプには、次のファイルに必要な情報がすべて含まれています。
-
watchers.csv
は、リポジトリとそれらに星を付けたユーザーのリストが含まれています -
users.csv
は、githubのユーザーIDペアとユーザー名が含まれています -
projects.csv
は、projects.csv
に対して同じことを行います。
データをより詳しく見てみましょう。 以下はwatchers.csv
ファイルの始まりです(便宜上、列名が追加されています):

id = 1のプロジェクトは、id = 1、2、4、6、7、...のユーザーに好かれていることがわかります。タイムスタンプのある列は必要ありません。
良いスタートですが、モデルの構築に移る前に、データをより詳細に調べて、場合によってはクリーンにすることをお勧めします。
データマイニング
すぐに思い浮かぶ興味深い質問は、「各ユーザーが平均して何個の星を平均しましたか?」です。異なる数の星を付けたユーザーの数を示すヒストグラムを以下に示します。
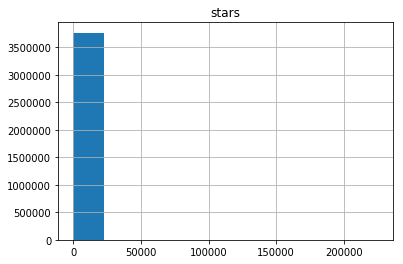
うーん...それは非常に有益に見えません。 大多数のユーザーは非常に少数の星を評価しているように見えますが、一部のユーザーは20万を超えると評価しています(すごい!)。 以下のデータの視覚化により、仮定が確認されます。

すべてが収束します。ユーザーの1人が20万個以上の星を付けました。 また、大量の放出が見られます-ユーザーは25,000以上です。 続行する前に、このユーザーが20万の星を持つユーザーを確認しましょう。 ニックネーム4148のヒーローユーザーに会いましょう。 この記事の執筆時点で、ページは404番目のエラーを返します。 授与された星の数の銀メダリストは、 46,000個の星を持つ「話す」という名前のStarTheWorldを持つユーザーです(ページも404番目のエラーを返します)。
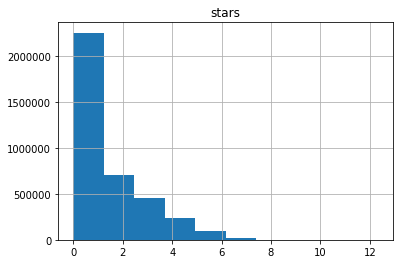
これで、変数が指数分布に従うことが明らかになりました(パラメーターを見つけることは興味深いタスクになる可能性があります)。 重要な観察結果は、ユーザーの約半数が5プロジェクト未満と評価したことです。 この観察は、モデリングを開始するときに役立ちます。
リポジトリを見て、星の数の分布を見てみましょう。

ユーザーの場合と同様に、1つの非常に顕著なサージがあります-20万以上の星を持つfreeCodeCampプロジェクトです!
対数変換後のリポジトリ内のランダムな数の星のヒストグラムを以下に示し、再び指数分布を処理しているが、より急降下していることを示しています。 ご覧のとおり、リポジトリのごく一部に10個以上の星が付いています。

データの前処理
どのようなデータ操作を行う必要があるかを理解するには、使用する協調フィルタリングメソッドをより詳しく調べる必要があります。
ほとんどの協調フィルタリングアルゴリズムは、行列の因数分解に基づいており、ユーザーの好みの行列を因数分解します。 因数分解の過程で、製品の隠された特性とそれらに対するユーザーの反応があります。 ユーザーがまだ評価していない製品のパラメーターを知っていれば、好みに基づいてユーザーの反応を予測できます。
この場合、サイズmxn
マトリックスがあります。各行はユーザーを表し、各列はリポジトリを表します。 i
番目のユーザーがj
番目のリポジトリにスターを設定した場合、 r_ij
は1に等しくなります。

マトリックスR
は、 watchers.csv
ファイルを使用して簡単に作成できます。 ただし、ほとんどのユーザーが星を非常に少なく評価したことを思い出してください! わずかな情報でユーザーの好みに関するどのような情報を見つけることができますか? 実際、どれもありません。 好きなものを1つだけ知って、誰かの好みについて推測することは非常に困難です。
同時に、「1つ星」のユーザーはモデルの予測力に大きな影響を与え、過度のノイズを発生させる可能性があります。 したがって、情報がほとんどないユーザーを除外することにしました。 実験では、星の数が30未満のユーザーを除外すると良い結果が得られることが示されています。 除外ユーザーの場合、推奨事項はプロジェクトの人気度に基づいており、良い結果が得られます。
モデルの有効性の評価
ここで、モデルのパフォーマンスを評価する重要な問題について説明します。 次の指標を使用しました。
- 精度とリコール
- 二乗平均平方根誤差(RMSE)
そして、「精度-完全性」というメトリックは、私たちの場合にはあまり役に立たないという結論に達しました。
しかし、始める前に、効果を評価する別の簡単で効果的な方法-自分自身のための推奨事項を構築し、それらがどれほど良いかを主観的に評価すること-に言及することは理にかなっています。 もちろん、これは博士論文で言及したい方法ではありませんが、初期段階で間違いを避けるのに役立ちます。 たとえば、データの完全なセットを使用して自分自身の推奨事項を作成すると、受け取った推奨事項が完全に関連しているわけではないことがわかりました。 少数の星を持つユーザーを削除すると、関連性が大幅に向上しました。
再び「正確性-正確性」のメトリックに戻りましょう。 簡単に言えば、2つの可能な結果のうちの1つを予測するモデルの精度は、予測の総数に対する真に肯定的な予測の数の比率です。 この定義は式として書くことができます:
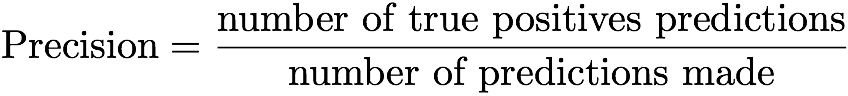
したがって、精度とは、試行回数の合計に対するターゲットのヒット数です。
完全性とは、すべてのデータでの真にポジティブな予測の数とポジティブな例の数の比率です。
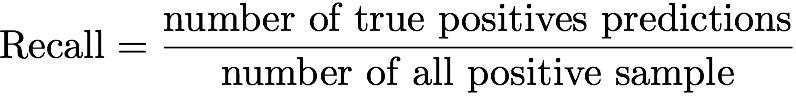
私たちのタスクに関しては、精度は、ユーザーが星を設定したレコメンデーションのリポジトリの比率として定義できます。 残念ながら、このメトリックは、ユーザーが既に評価したものではなく、ユーザーが最も評価する可能性のあるものを予測することを目的としているため、あまり意味がありません。 一部のプロジェクトには、ユーザーが気に入った次のプロジェクトの役割の候補となる一連のパラメーターがあり、ユーザーがそれらをまだ評価していない唯一の理由は、彼がまだそれらを見ていないことです。
このメトリックを変更して有用にすることができます。ユーザーが次に評価した推奨プロジェクトの数を測定し、発行された推奨の数で割ると、より正確な精度の値が得られます。 ただし、現時点ではフィードバックを収集していないため、精度は使用したい指標ではありません。
タスクに適用される完全性とは、ユーザーが星を設定した推奨事項のリポジトリの数と、ユーザーが評価したすべてのリポジトリの数の比率です。 精度の場合と同様に、このメトリックはあまり推奨されません。これは、推奨事項のリポジトリの数が固定されており(現時点では100)、かなりの数のプロジェクトを評価したユーザーの精度の値がゼロに近いためです。
上記の考えを考慮して、モデルの有効性を評価するための主要な指標として標準偏差を使用することが決定されました。 問題に関しては、メトリックは次のように記述できます。
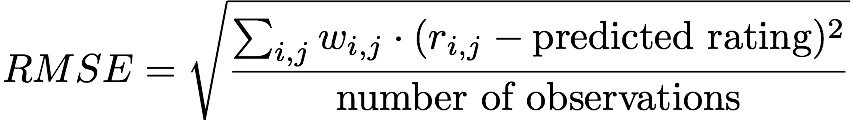
言い換えると、プロジェクトのユーザー評価(0および1)と、リポジトリに対して1に近い予測評価との間の標準誤差を測定します。これは、モデルに従ってユーザーが評価します。 wはすべてのr_ij = 0
に対して0であることに注意してください。
すべてをまとめる-モデリング
すでに述べたように、推奨システムは行列の因数分解に基づいており、より正確には交互最小二乗(ALS)アルゴリズムに基づいています。 私たちの実験によれば、行列因数分解アルゴリズムも機能することは注目に値します(SVD、NNMF)。
ALS実装は、多くの機械学習ソフトウェアパッケージで利用できます(たとえば、 Apache Sparkの実装を参照)。 アルゴリズムは、サイズmxnの元の行列を、サイズmxk
とnxk
2つの行列の積に分解しようとしnxk
。

パラメータk
は、検索しようとしている「隠された」プロジェクトパラメータの数を決定します。 k
の値は、モデルの効率に影響します。 k
の値は、相互検証を使用して選択する必要があります。 次のグラフは、テストデータセットのk
値に対するRMSE値の依存性を示しています。 値k=12
は最良の選択のように見えるため、最終モデルに使用されました。

結果のアクションシーケンスをまとめて見てみましょう。
-
watchers.csv
ファイルからデータをロードし、30プロジェクト未満と評価したすべてのユーザーを削除します。 - データをトレーニングセットとテストセットに分割します。
- RMSEとテストデータを使用してパラメーター
k
を選択します。 - 因子数=
k
ALSを使用して、ジョイントデータセットでモデルをトレーニングします。
私たちに合ったモデルができたら、それをエンドユーザーが利用できるようにする方法について議論し始めることができます。 言い換えれば、その周りにWebアプリケーションを構築する方法。
バックエンド
バックエンドでできることのリストは次のとおりです。
- ユーザー名を取得するためのGitHub認証
- 「ニックネームXのユーザーに100件の推奨事項をください」などのリクエストを送信するためのREST API
- 更新のユーザーサブスクリプションに関する情報の収集
すべてを素早く簡単にしたかったので、選択はDjango、Django RESTフレームワーク、Reactのテクノロジーに依存していました。
リクエストを正しく処理するには、GHTorrentで受信したデータを保存する必要があります。 主な理由は、GHTorrentがGitHubのユーザーIDと一致しない独自のユーザーIDを使用しているためです。 したがって、 user id <-> user GitHub name
ペアを保存する必要がありuser id <-> user GitHub name
。 リポジトリについても同じことが言えます。
ユーザーとリポジトリの数は非常に多く(それぞれ2,000万件と6,400万件)、インフラストラクチャに多額の費用をかけたくなかったため、MongoDBで圧縮を使用する「新しい」タイプのストレージを試すことにしました 。
そのため、MongoDBにはusers
とprojects
2つのコレクションがありprojects
。
users
コレクションのドキュメントは次のとおりです。
{ "_id": 325598, "login": "yurtaev" }
login
フィールドによってインデックス付けされ、クエリ処理を高速化します。
projects
コレクションのサンプルドキュメントを以下に示します。
{ "_id": 32415, "name": "FreeCodeCamp/FreeCodeCamp", "description": "The https://freeCodeCamp.org open source codebase and curriculum. Learn to code and help nonprofits." }
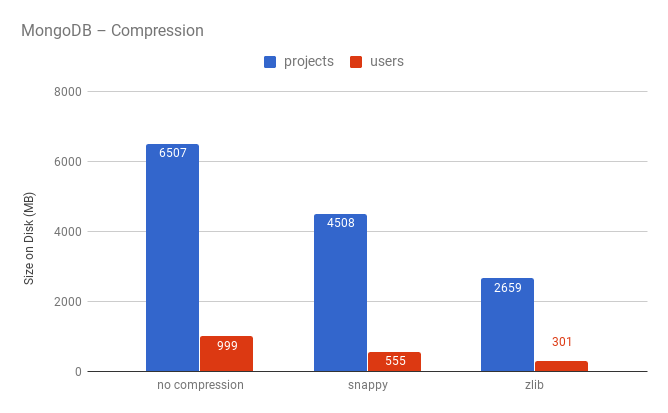
ご覧のとおり、zlib圧縮により、ディスク領域の使用率が2倍になります。 圧縮の使用に関する懸念の1つはクエリの処理速度でしたが、実験では時間が統計誤差内で変化することが示されています。 圧縮のパフォーマンスへの影響に関する詳細は、 こちらをご覧ください 。
要約すると、MongoDBでの圧縮は、ディスク領域の使用量の点で大幅に向上すると言えます。 もう1つの利点は、スケーリングの単純さです。これは、リポジトリとユーザーに関するデータ量が1つのサーバーに配置されなくなったときに非常に役立ちます。
動作中のモデル
モデルを使用するには、2つのアプローチがあります。
- 各ユーザーの推奨事項の予備生成とデータベースへの保存。
- リクエストに応じた推奨事項の生成。
最初のアプローチの利点は、モデルが「ボトルネック」にならないことです(現時点では、モデルは1秒間に推奨ごとに30〜300のリクエストを処理できます)。 主な欠点は、保存する必要があるデータの量です。 2,000万人のユーザーがいます。 ユーザーごとに100件の推奨事項を保持すると、20億エントリになります! ちなみに、これらの2,000万人のユーザーのほとんどはサービスを使用しません。つまり、ほとんどのデータはそのように保存されます。 最後になりましたが、推奨事項の作成には時間がかかります。
2番目のアプローチの長所と短所-最初のアプローチの長所と短所を反映しています。 しかし、オンデマンドで推奨事項を作成するのが好きなのは柔軟性です。 2番目のアプローチでは、必要な数の推奨事項を返すことができ、モデルを簡単に置き換えることもできます。
すべての長所と短所を検討した後、2番目のオプションを選択しました。 モデルはdockerコンテナーにパッケージ化され、RPC呼び出しを使用して推奨事項を返します。
フロントエンド
面白くないものはありません: React 、 Reactアプリの作成、およびセマンティックUI 。 唯一のトリック-React Snapshotを使用して、メインページの静的バージョンを事前生成し、検索エンジンによるインデックス作成を改善しました。
便利なリンク
GitHubユーザーの場合、 GHRecommender Webサイトで推奨事項を取得できます。 評価したリポジトリが30未満の場合、最も人気のあるプロジェクトが推奨事項として受け取られることに注意してください。
GHRecommenderのソースはこちらから入手できます 。
textテキストとプロジェクトavliの共著者