
参加者は、改善と重大なバグのタイミングを予測するのに役立つ機械学習のソリューションを開発するように求められました。 これらのソリューションにより、SberTechの開発効率が向上します。
- 開発のさまざまな段階のパッチ中にコマンドのロードを計画することをお勧めします。
- ホットフィックスの観点からリリース構造を形成する。
- スプリントでの作業の計画-問題を修正するために予約されているストーリーポイントを定義します。
- 一般に、プログラムコードのバグの数を減らします。
- 製品の市場投入までの時間を短縮します。
- 意思決定の予測可能性とテストの有効性を高めます。
参加者の最高のアイデアは、近い将来SberTechに実装される予定です。
ハッカソンの限られた時間で産業用ソリューションを作成することは不可能であることを完全に理解しました。 誰も幻想を抱いておらず、決定が大雑把に行われることは明らかでした。 しかし、非常に具体的なタスクがある場合、なぜ空からタスクを思い付くのでしょうか? その結果、私たちはみんなにファン(そしてもちろん賞金)を贈り、見返りに仕事に取り入れられる興味深いアイデアを受け取りました。
ソースデータ
このタスクは、MCA(内部自動プロジェクト管理システム)だけでなく、Jiraの内部および外部作業ネットワークからのデータに基づいて解決されました。 Jiraのデータセットが履歴と添付ファイル付きのテキストフィールドである場合、MCCは変更の計画に使用されるより具体的な情報を保存しました。
データセットは、参加者がアクセスできるファイル共有に投稿されました。 これはハッカソンであるため、彼らはどのように、そして何を扱うべきかを理解することになっていた。 実生活のように:)
鉄
同僚の知識とスキルをほとんど疑わなかった場合、デスクトップコンピューターの能力は、控えめに言っても、とんでもないことではありません。 したがって、リクエストに応じて小さなHadoopクラスターが追加で提供されました。 クラスター構成(80 CPU、200 GB、1.5 TB)は、コンピューティングに重点を置いた単一ユニットサーバーに似ていますが、いまだにOpenstackにデプロイされたクラスターです。
もちろん、これは小さなスタンドです。 ソリューションを開発し、データラボを統合するように設計されており、産業用コピーのコピーを大幅に削減しました。 しかし、ハッカソンにはそれで十分でした。
データラボにはJupyterNotebookの個別のインスタンスを作成するJupyterHUBが関係していました。 また、Clouderaパーセルの助けを借りて並列コンピューティングを使用できるようにするために、さまざまなPythonライブラリのセットを使用していくつかのカーネルオプションをJupyterに追加しました。
その結果、入り口では、誰も邪魔することなく必要なバージョンのライブラリを使用できるNユーザーの独立した仕事を得ました。 さらに、頭痛のない並列コンピューティングを開始できました(ClouderaのData Science Workbenchがあり、すでに作業を試みていますが、ハッカソンの時点ではこのツールはまだ利用できませんでした)。
配置-自動処理のバグ
目的:Sberbank-Technologyプロジェクトのバグを自動処理するためのパイプラインの作成。
ソリューションの作成者:Anna Rozhkova、Pavel Shvets、Mikhail Baranov(モスクワ)
データのソースとして、チームは、Google PlayとAppStoreのSberbank Onlineモバイルアプリケーションの顧客からのフィードバックと、Jiraのバグに関する情報を使用しました。

最初に、参加者は、ツリーベースの分類器を使用して、レビューをポジティブとネガティブに分割する問題を解決しました。 次に、否定的なレビューを使用して、ユーザーの不満を引き起こした主なトピックを特定しました。 これは例えば次のとおりです。
- 更新
- ウイルス対策(ルート、ファームウェア)
- SMSと支払い
「すべてが悪い」と書いた人々は、別のカテゴリーに分類されました。
凝集階層クラスタリングを使用して、チームは顧客レビューを分割しました(このアプローチの利点は、たとえば、目標と貢献に関するレビューが1つのクラスターに起因する場合に専門家の意見を追加できることです)。 そのため、たとえば、選択したクラスターの1つは、Asus Zenfone 2デバイスへのログインと問題を組み合わせました(問題に関する最初のレビューからJiraでのバグ登録までの期間は16日間でした)。

参加者は、銀行の利点を活用して、選択したクラスターのバグを自動作成するオンラインフィードバック処理を行うことで、ユーザーの問題に対する応答時間を可能な限り短縮することを提案しました-多数の思いやりのある顧客(1日あたり1,500件のレビュー)。 作業の過程で、否定的なレビューを決定する際に、精度= 86%および精度= 88%が達成されました。
別のチームの決定は、開発中のプロセスを視覚化することです。 ケースは、Sberbank Online Android(ASBOL)の例を使用して分析されました。

参加者は、チームメンバー間のバグステータスの遷移数を計算し、グラフの形で描きました。 このツールを使用すると、管理上の意思決定が容易になり、チーム内で負荷を均等に分散できます。 さらに、誰がチームの主要メンバーであり、プロジェクトのどこにボトルネックがあるかを明確に確認できます。 この情報に基づいて、特定のチームメンバーにバグを自動的に割り当てることをお勧めします。特定のチームメンバーの負荷とバグの重大度が考慮されます。
さらに、参加者は、ロジスティック回帰と単純なベイズ分類器を使用して、自動的にバグに優先順位を付けるという問題に対処しようとしました。 このため、バグの重要性は、その説明、投資の有無、およびその他の特性によって決定されました。 ただし、モデルは3倍の交差検証の精度= 54%の結果を示しました。作業の配信時に、プロトタイプは実装に適していませんでした。
チームメンバーによると、彼らのモデルの利点は、シンプルさ、結果の適切な解釈、および迅速な作業です。 これは、機械学習を使用したユーザーレビューのリアルタイム処理に向けたステップです。これにより、ユーザーとのリアルタイムの対話、問題の特定と除去、顧客ロイヤルティの向上が可能になります。
チームプレゼンテーション
II場所-生産プロセスの最適化
決定者:アントン・バラノフ(モスクワ)
タスク:
- バグに関する情報を使用して、バグの最終的な優先順位を予測します。 例:説明、発見フェーズ、プロジェクトなど。
- 時間内のバグの分布に関するデータに基づいて、予測期間内の特定のタイプ、システム、ステージなどのバグの数を予測します。
アントンはJiraのバグに取り組みました。 データセットには、2011年から2017年までの「完了」状態の67,000を超えるバグに関する情報が含まれていました。 彼は、Python言語ライブラリーと他のMLライブラリーの助けを借りて、問題の解決策を探しました。
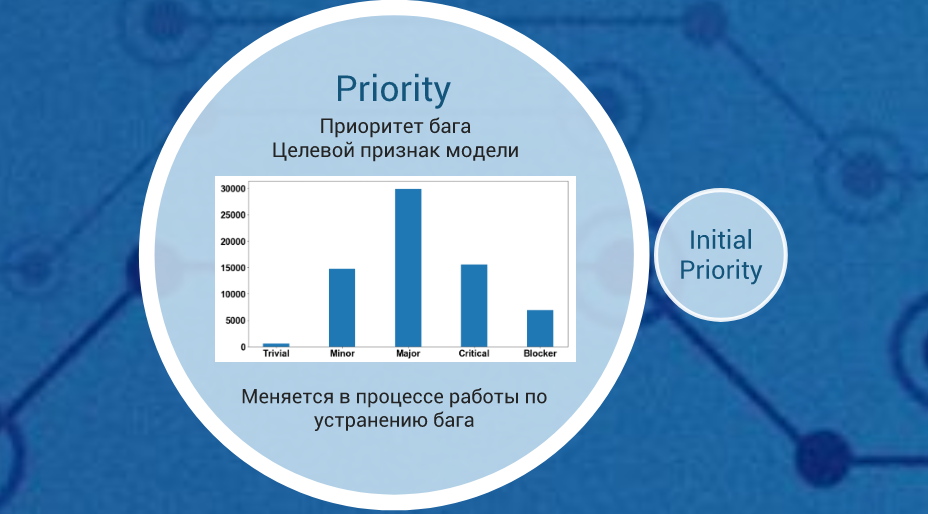
アントンは、バグの最終優先度に影響する機能を分析および選択し、それらに基づいて最終優先度を予測するモデルを構築しました。 さらに、さまざまな時系列の特徴を分析および検索した後、彼はバグ数の予測モデルを構築しました。 提案されたソリューションは、テストに役立ちます。

アジャイルでは、将来のスプリントでの作業を計画するときに、このモデルによる欠陥の数の予測結果を考慮することができます。 アントンの決定は、最終的なパフォーマンスに影響を与える問題の修正に必要な時間をより正確に決定するのに役立ちます。
参加者プレゼンテーション
III位:リスク予測
決定者:ニコライ・ゼルトフスキー(イノポリス)
目的: ITプロジェクトの管理におけるリスクを最小限に抑えるためのニューラルネットワークに基づく予測システムの作成。
主催者によって提案されたソースデータのセットから、参加者はJiraからタスクのリストをアップロードすることを選択しました。 タスクは、ソフトウェアコンポーネントを開発するための独立したタスクです。 ライフサイクルのプロセスにおける各タスクには、作成、開発、さまざまな種類のテストと調整、終了などのさまざまな状態があります。 このような状態は数十あります。
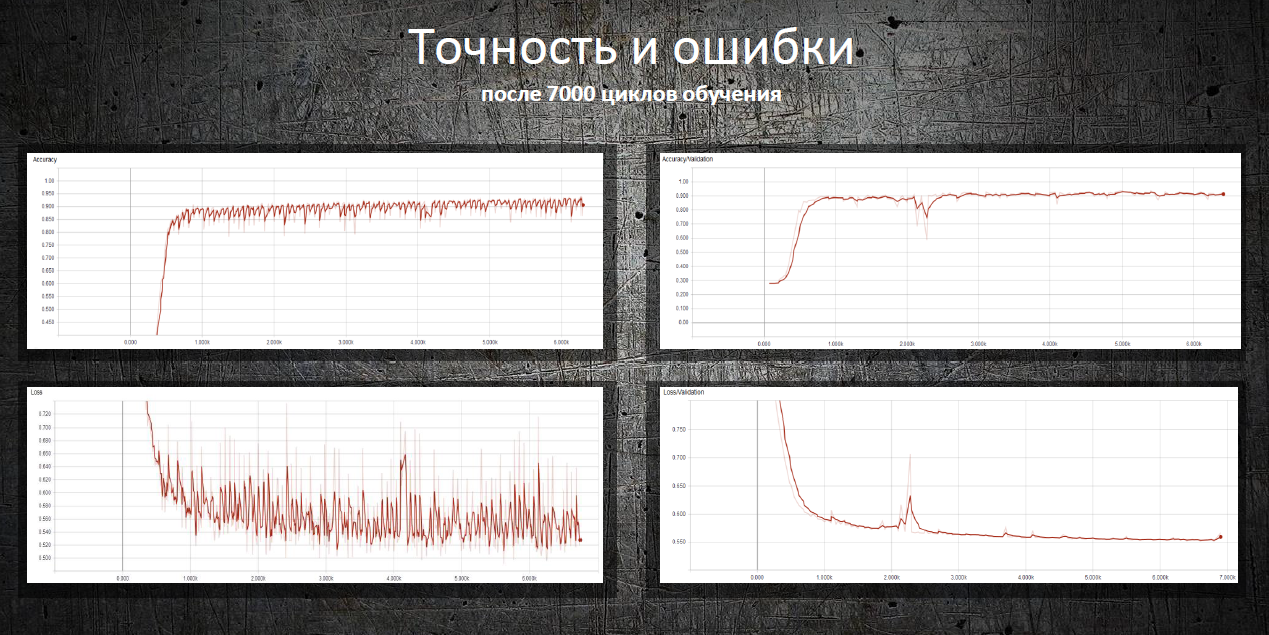
ニコライは、特定の状態へのタスクの移行を予測し、これらのイベントの日付を予測し、起こりうる重大なイベントまたは計画値からの逸脱を報告できるニューラルネットワークを構築およびトレーニングしました。

ニューラルネットワークをトレーニングするために、ニコライはイベントログから各タスクの中間状態のシーケンスを復元しました。 タスクの中間状態の1つがニューラルネットワークの入力に送られ、最終が出力に送られたため、ネットワークはイベントを予測することを学びました。 さらに、派生データがトレーニングに使用されました-たとえば、過去のすべてのイベント間の一時的な違いを含むテーブル。 週末に作業が行われるタスクには問題がある可能性があるという仮説が考慮されました。

ニューラルネットワークは、91〜94%の精度でいくつかの重要なイベントを予測します。 たとえば、タスクを再度開きます。 タスク終了日は、作成直後に0〜37日の偏差で予測されます。 後の段階で、タスクの作業が実行されると、最大偏差は1週間以内になります。
参加者プレゼンテーション