
こんにちは、Habr。 私の記事では、機械学習の世界で過去1年間(主にディープラーニングで)起こった興味深いことをお話しします。 そして多くのことが起こったので、私の意見では、壮大なおよび/または重要な成果に最も落ち着きました。 この記事では、ネットワークアーキテクチャを改善する技術的な側面については説明していません。 視野を広げます!
1.テキスト
1.1。 Google Neural Machine Translation
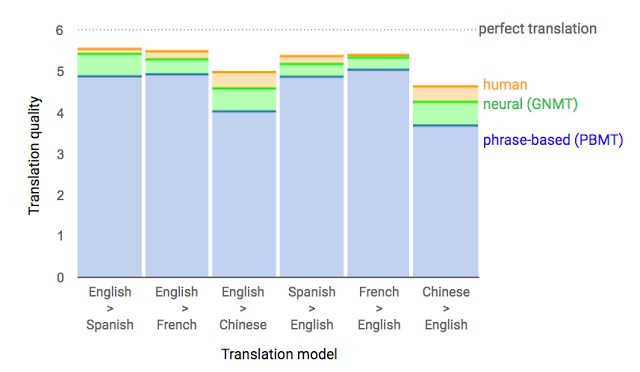
ほぼ1年前、Google は Google翻訳の新しいモデルの発売を発表しました 。 同社は、その記事でネットワークアーキテクチャ(リカレントニューラルネットワーク(RNN))について詳しく説明しました。
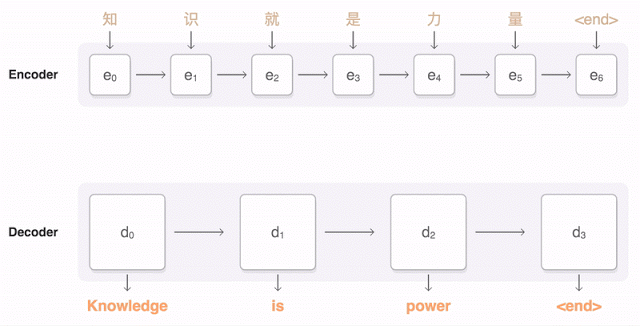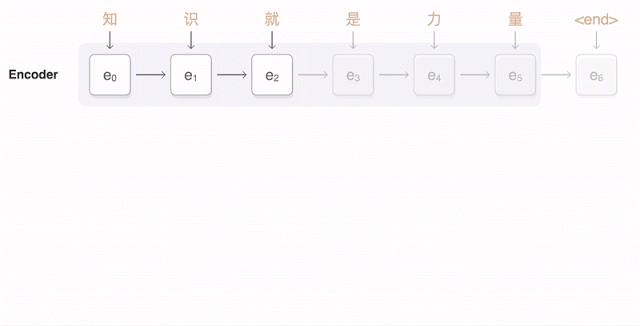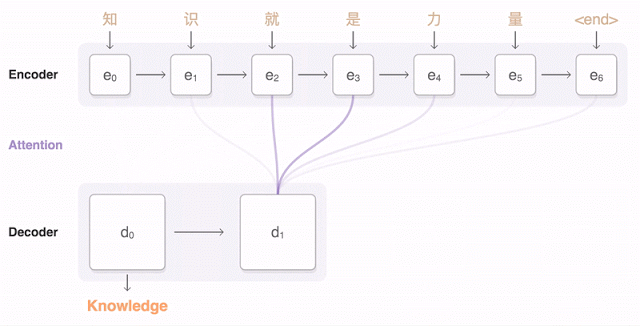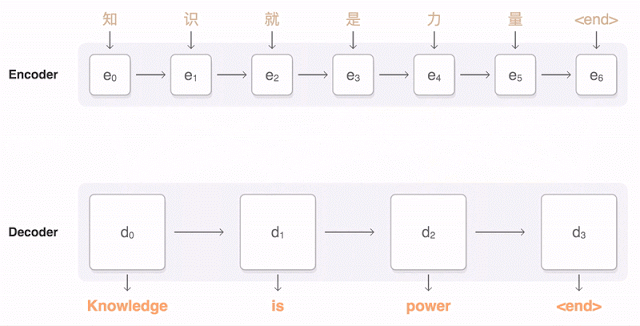
主な結果:翻訳の正確さの点で人の遅れを55〜85%(人は6点スケールで評価)削減しました。 Googleが持つ膨大なデータセットなしでは、このモデルの高い結果を再現することは困難です。
1.2。 交渉。 取引はありますか?
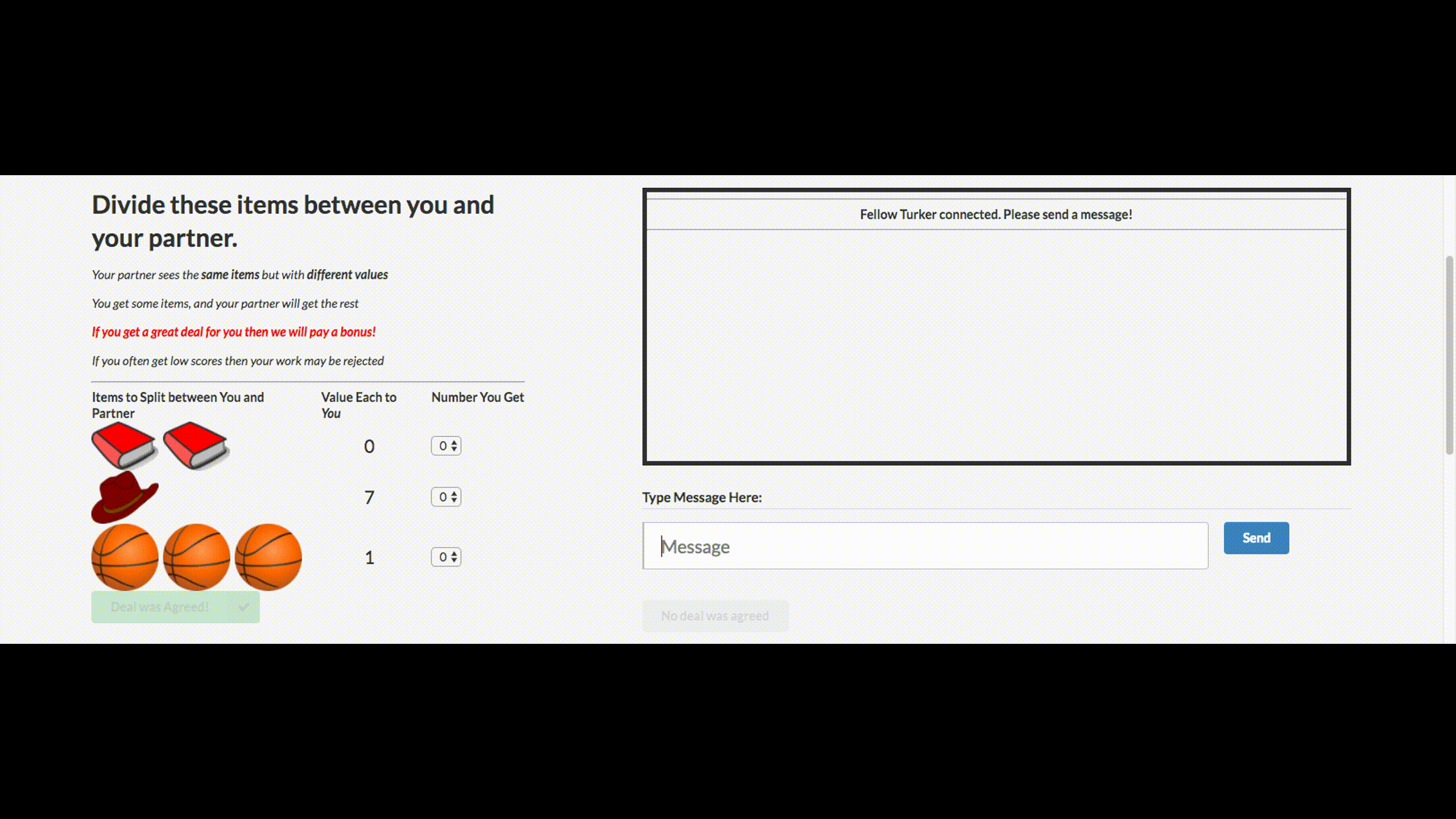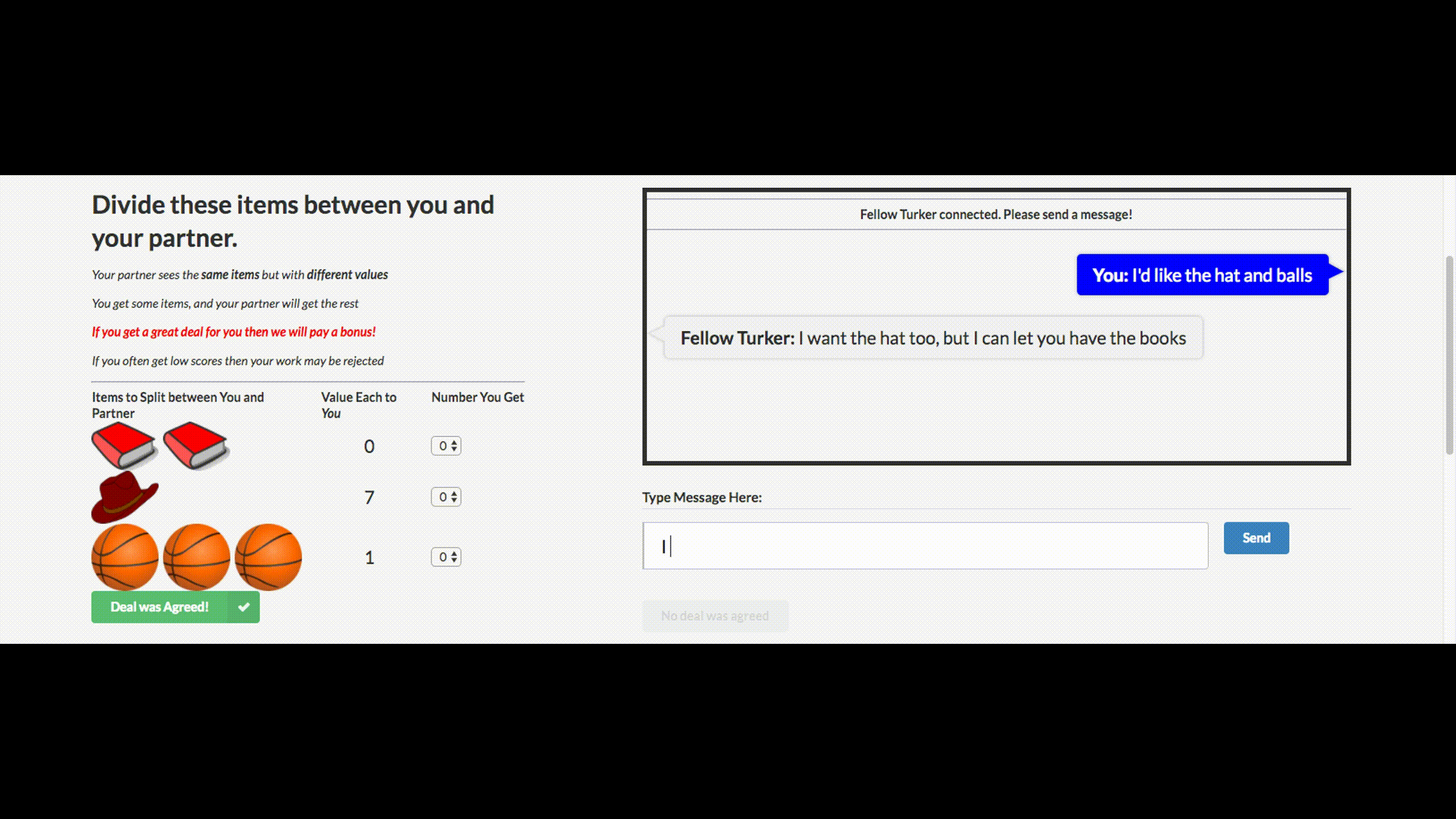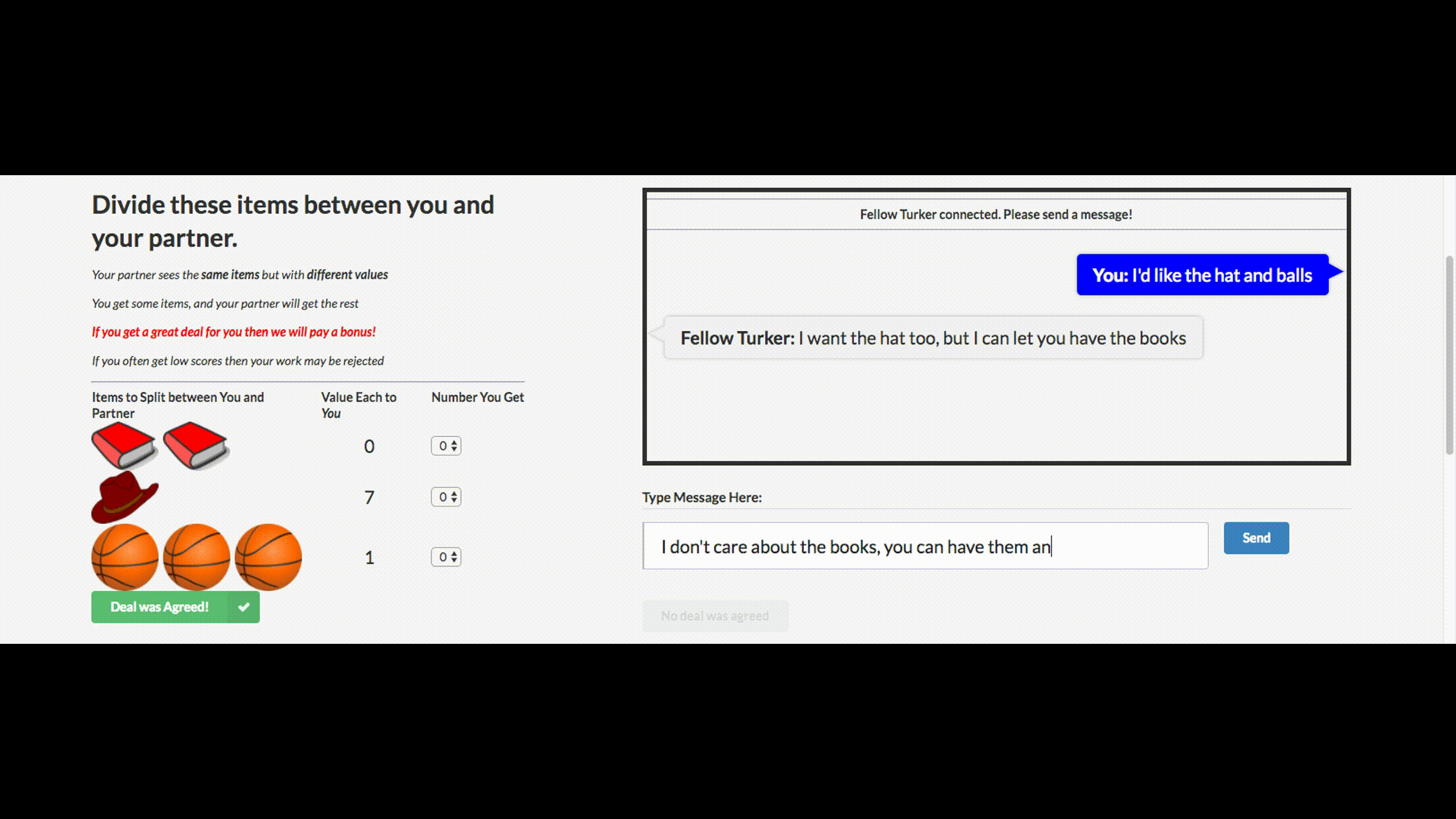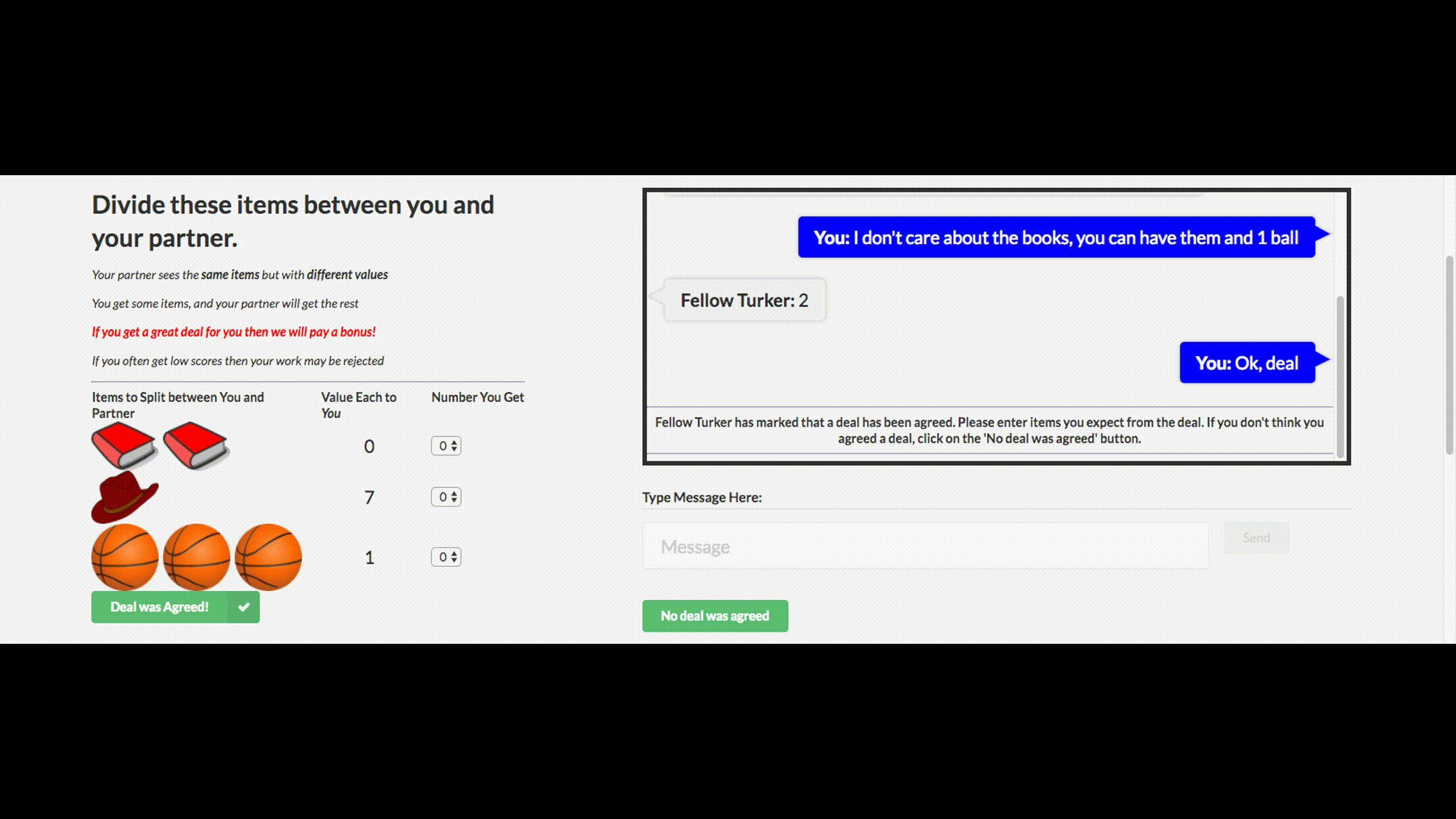
Facebookがチャットボットをオフにしたという愚かなニュースを聞いたことがあるかもしれません。 会社は交渉のためにこのチャットボットを作成しました。 彼の目標は、他のエージェントとテキストによる交渉を行い、取引を達成することです。オブジェクトを2つに分割する方法(本、帽子など)。 各エージェントは交渉で独自の目標を持っていますが、他のエージェントはそれを知りません。 交渉なしで交渉を離れることはできません。
トレーニングのために、彼らは人間の交渉のデータセットを収集し、監督された再発ネットワークを訓練し、強化学習(強化学習)を使用してエージェントを訓練し、自分自身と会話するように訓練しました。
ボットは、実際の交渉のための戦略の1つを学びました-トランザクションのいくつかの側面に偽の関心を示し、それにより彼らは彼らの本当の目標のために利益を得て、彼らに屈することができました。 これは、このような交渉ボットを作成する最初の試みであり、非常に成功しています。
詳細- 記事では、 コードはオープンアクセスでレイアウトされています。
もちろん、ボットが言語を発明したというニュースはゼロから膨らみました。 トレーニング中(同じエージェントとの交渉中)、テキストと人間の類似性の制限が無効になり、アルゴリズムが対話言語を変更しました。 異常なことは何もありません。
過去1年にわたり、リカレントネットワークが積極的に開発され、多くのタスクやアプリケーションで使用されてきました。 リカレントネットワークのアーキテクチャははるかに複雑になりましたが、一部の分野では単純なフィードフォワードネットワークDSSMが同様の結果を達成しています。 たとえば、GoogleはSmart Replyメール機能で以前のLSTMと同じ品質を達成しました。 そして、Yandexはそのようなネットワークに基づいた新しい検索エンジンを立ち上げました 。
2.スピーチ
2.1。 WaveNet:Rawオーディオの生成モデル
DeepMind(現在、Googleが所有しているボットで知られている会社)の従業員は、 記事でオーディオ生成について語っています。
要するに、研究者たちは、画像生成への以前のアプローチ( PixelRNNとPixelCNN )に基づいて自己回帰のフルコンボリューションWaveNetモデルを作成しました。

ネットワークはエンドツーエンドで学習しました:入力テキスト、出力オーディオ。 結果は素晴らしく、人との差は50%減りました。
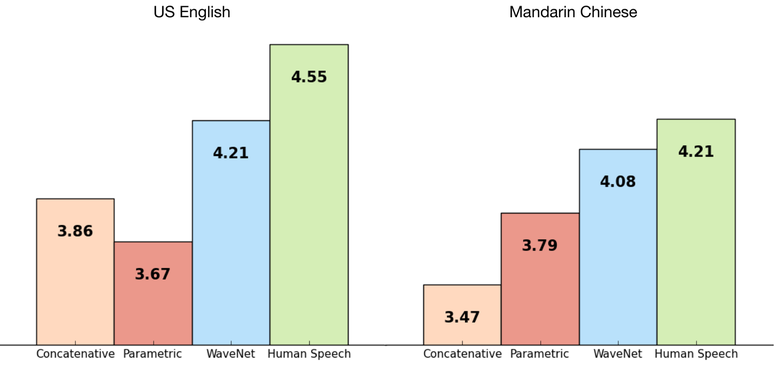
ネットワークの主な欠点は、パフォーマンスが低いことです。これは、自己回帰サウンドが連続して生成されるため、1秒のオーディオを作成するのに約1〜2分かかります。
英語: 例
入力テキストへのネットワークの依存関係を削除し、以前に生成された音素への依存のみを残すと、ネットワークは人間の言語に似ているが意味のない音素を生成します。
音声生成: 例
同じモデルを音声だけでなく、たとえば音楽の作成にも適用できます。 ピアノ演奏データセットでトレーニングされたモデルによって生成されたオーディオの例(再び、入力データに依存しない)。
詳細は記事にあります。
2.2。 リップリーディング
人に対する機械学習の別の勝利;)今回-リップリーディングで。
Google Deepmindは、オックスフォード大学と共同で、 「 Lip Reading Sentences in the Wild」という記事で、テレビデータセットでトレーニングされたモデルがどのようにBBCチャンネルのプロのリップリーダーを上回ることができたかを説明しています。

データセットには、音声とビデオを含む10万のオファーが含まれています。 モデル:オーディオのLSTM、ビデオのCNN + LSTM、これら2つの状態ベクトルは、結果(文字)を生成する最終LSTMに送られます。
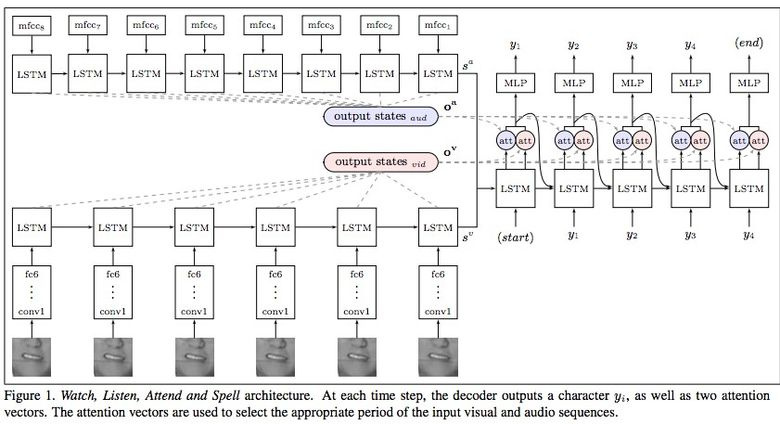
トレーニング中に、さまざまなタイプの入力データが使用されました:オーディオ、ビデオ、オーディオ+ビデオ、つまり、モデルはオムニチャネルです。
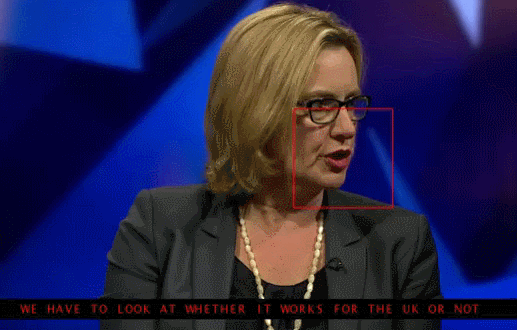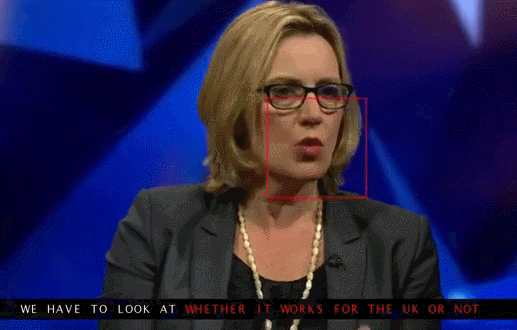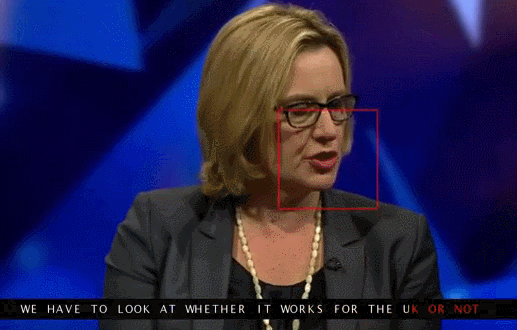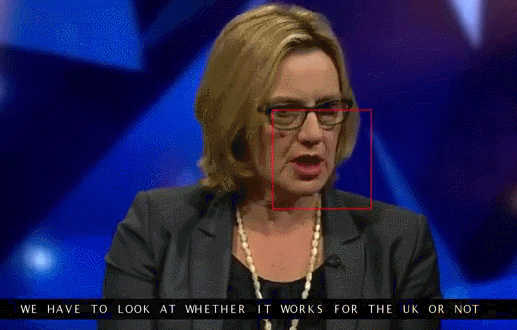
2.3。 オバマ氏の合成:オーディオとのリップシンク
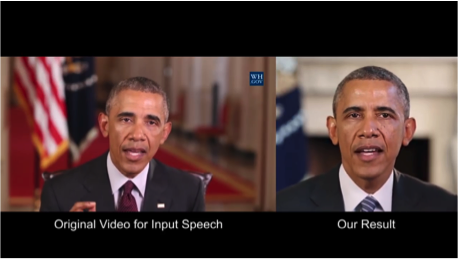
ワシントン大学は、オバマ前米国大統領の口先の動きを生み出すために真剣に取り組んできました 。 ネットワーク上での膨大な数のスピーチの録音(17時間のHDビデオ)を含め、選択は彼にかかった。
1つのネットワークを省くことができず、アーティファクトが多すぎました。 そのため、この記事の著者は、テクスチャとタイミングを改善するために、松葉杖(または、必要に応じてトリック)を作成しました。
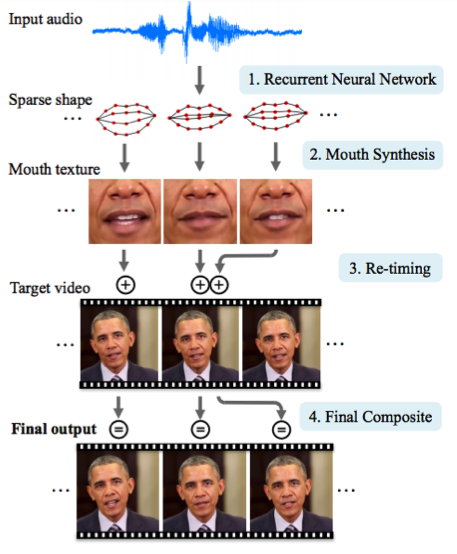
結果は印象的です。 すぐに大統領とのビデオさえ信じることは不可能になります;)
3.コンピュータービジョン
3.1。 OCR:Googleマップとストリートビュー
Google Brainチームは、 投稿と記事で、どのOCR(光学文字認識)エンジンをマップに導入したか、どの道路標識と店舗標識が認識されるかについて説明しています。


技術開発の過程で、同社は多くの複雑なケースを含む新しいFSNS (French Street Name Signs)を編集しました。
ネットワークは、最大4枚の写真を使用して各キャラクターを認識します。 CNNを使用して、特徴が抽出され、空間的注意を使用して重み付けされ(ピクセル座標が考慮されます)、結果がLSTMに供給されます。
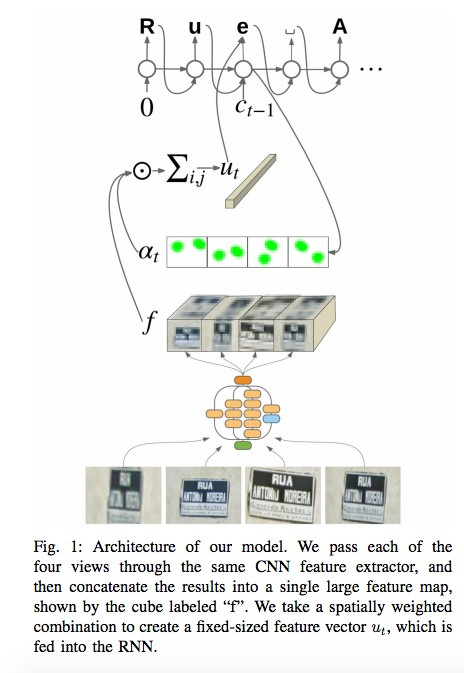
著者は、看板の店名を認識するタスクに同じアプローチを適用します(そこには多くの「ノイズ」データが存在する可能性があり、ネットワーク自体は適切な場所に「焦点を合わせる」必要があります)。 このアルゴリズムは800億枚の写真に適用されました。
3.2。 視覚的推論
視覚的推論などのタスクのタイプがあります。つまり、ニューラルネットワークは写真からの質問に答える必要があります。 たとえば、「黄色の金属シリンダーと同じサイズのゴム製のアイテムはありますか?」という質問は本当に些細なことではなく、最近まで、問題はわずか68.5%の精度で解決されていました。

また、Deepmindのチームによってブレークスルーが達成されました。CLEVRデータセットでは、95.5%の超人的精度を達成しました。
ネットワークアーキテクチャは非常に興味深いものです。
- テキストの質問の場合、事前学習済みのLSTMを使用して、質問の埋め込み(表現)を取得します。
- CNNを使用した画像(4つのレイヤーのみ)から、機能マップ(画像を特徴付ける機能)を取得します。
- 次に、座標ごとのslice'ov機能マップ(下図の黄色、青、赤)のペアごとの組み合わせを作成し、各座標にテキストの埋め込みを追加します。
- 要約すると、これらすべてのトリプルを別のネットワークで駆動します。
結果のプレゼンテーションを別のフィードフォワードネットワークで実行します。これにより、すでにソフトマックスに関する回答が得られます。
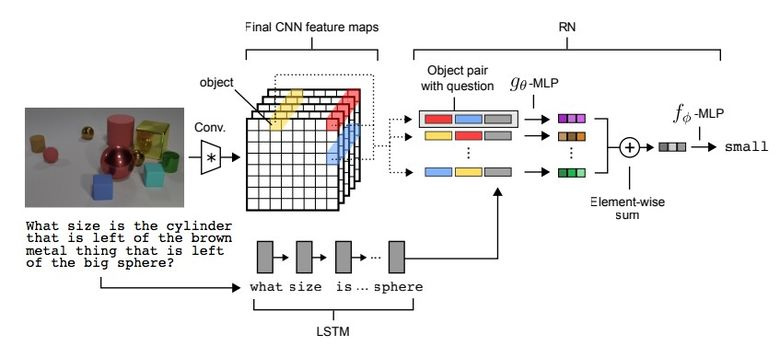
3.3。 Pix2code
ニューラルネットワークの興味深いアプリケーションがUizardによって考案されました。インターフェイスデザイナーのスクリーンショットからレイアウトコードを生成します。

ニューラルネットワークの非常に便利なアプリケーション。ソフトウェアを開発する際の作業を容易にします。 著者は、77%の正確性を得たと主張しています。 これがまだ研究作業であり、戦闘雇用の話がないことは明らかです。
オープンソースにはまだコードとデータセットはありませんが、投稿することを約束します。
3.4。 SketchRNN:車に描画方法を教える
クイックドローを見たことがあるかもしれません! Googleから、さまざまなオブジェクトのスケッチを20秒で描くように訴えています。 Googleがブログと記事で 説明しているように、企業はこのデータセットを組み合わせて、ニューラルネットワークを描画するように訓練しました。

組み立てられたデータセットは7万枚のスケッチで構成され、最終的には公開されました。 スケッチは写真ではなく、図面の詳細なベクトル表現(ユーザーが鉛筆をクリックしたとき、手放し、線を引いた場所など)。
研究者は、RNNをエンコード/デコードメカニズムとして使用して、シーケンスからシーケンスへの変分オートエンコーダー(VAE)をトレーニングしました。
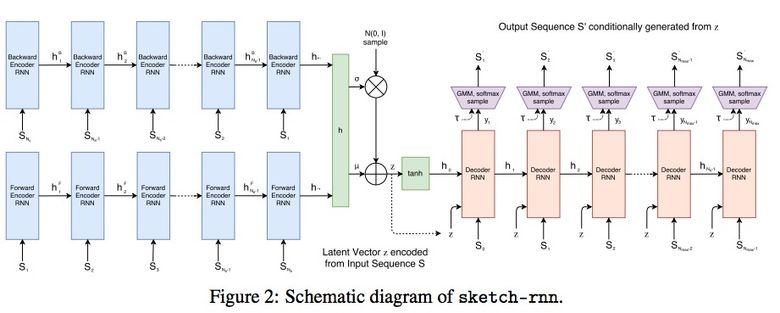
その結果、オートエンコーダーに適しているため、モデルは元の画像を特徴付ける潜在ベクトルを受け取ります。

デコーダーはこのベクトルから画像を抽出できるため、それを変更して新しいスケッチを取得できます。

さらに、ベクトル演算を実行して豚猫を作成します。
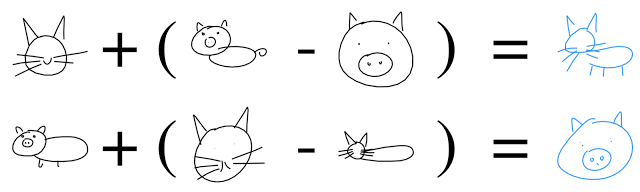
3.5。 ガン
ディープラーニングの最もホットなトピックの1つは、Generative Adversarial Networks(GAN)です。 ほとんどの場合、このアイデアは画像の処理に使用されるため、それらの概念を説明します。
アイデアの本質は、ジェネレーターとディスクリミネーターという2つのネットワークの競合です。 最初のネットワークは画像を作成し、2番目のネットワークはその画像が本物か生成物かを理解しようとします。
概略的には、次のようになります。
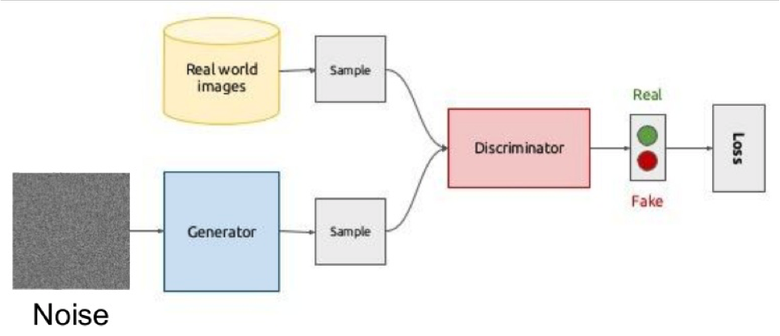
トレーニング中、ランダムベクトル(ノイズ)からのジェネレーターは画像を生成し、偽物かどうかを示す弁別器に供給します。 弁別器は、データセットから実画像も受け取ります。
2つのネットワークの平衡点を見つけることは困難であるため、このような構造を訓練することはしばしば困難です。ほとんどの場合、弁別器が勝ち、訓練は停滞します。 しかし、このシステムの利点は、損失関数を設定するのが困難な問題を解決できることです(たとえば、写真の品質を向上させる)。これを弁別器に渡します。
GAN学習成果の典型的な例は、寝室または顔の写真です。


以前は、生データを潜在的な表現にエンコードする自動エンコーダー(Sketch-RNN)を見てきました。 ジェネレーターでも同じことが起こります。
顔の例を使用してベクトルによって画像を生成するアイデアは、 ここで非常に明確に示されています (ベクトルを変更して、どの顔が出てくるかを確認できます)。

潜在空間でも同じ計算が機能します。「眼鏡をかけた男」マイナス「男」プラス「女」は「眼鏡をかけた女」と同じです。

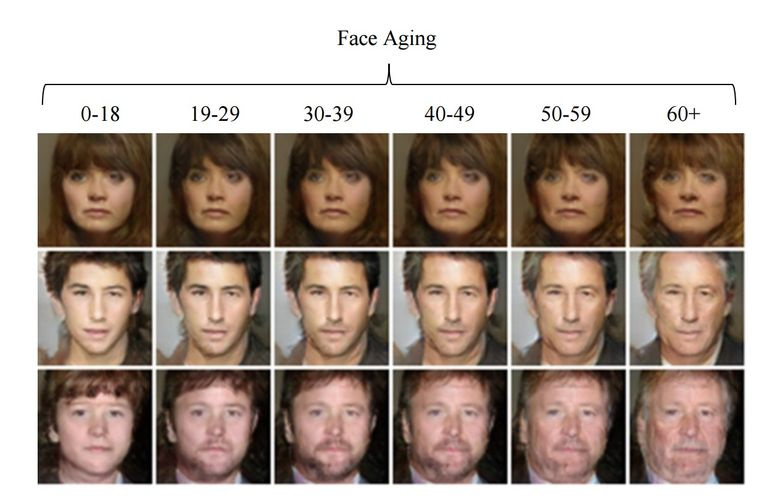
3.6。 GANを使用した顔の年齢の変更
トレーニング中に制御されたパラメーターを潜在ベクトルにスリップした場合、それを生成するときに、それを変更して画像内の正しい方法で制御できます。 このアプローチは、条件付きGANと呼ばれます。
それが、条件付き生成的敵対ネットワークによる顔の老化の著者たちがしたことです。 IMDBデータセットでアクターの既知の年齢で車をトレーニングした後、研究者は顔の年齢を変更する機会を得ました。
3.7。 プロの写真
GoogleはGANの別の興味深いアプリケーション-写真の選択と改善を発見しました 。 GANはプロの写真のデータセットでトレーニングされました。ジェネレーターは悪い写真(特別なフィルターを使用して専門的に撮影および劣化)を改善しようとし、弁別器は「改善された」写真と実際のプロの写真を区別しようとします。
訓練されたアルゴリズムは、最高の構図を求めてGoogleストリートビューパノラマを歩き、プロとセミプロの品質の写真を(写真家によると)得ました。


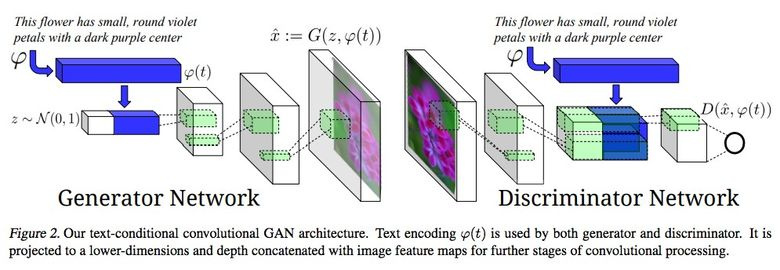
3.8。 テキスト記述から画像への合成
GANの使用の印象的な例は、テキストによる画像の生成です。

この記事の著者は、埋め込みテキストをジェネレーター(条件付きGAN)だけでなく、識別器にも入力して、テキストと写真の対応を確認することを提案しています。 弁別者がその機能を果たすことを学ぶために、訓練に加えて、実際の写真に誤ったテキストのペアが追加されました。
3.9。 Pix2pix
2016年末のハイライトの 1つは、Berkeley AI Research(BAIR)による「条件付き敵対ネットワークによる画像から画像への変換」です。 研究者は、たとえば衛星画像またはオブジェクトのスケッチからマップを作成する必要がある場合、画像間の画像生成の問題を解決しました-現実的なテクスチャです。
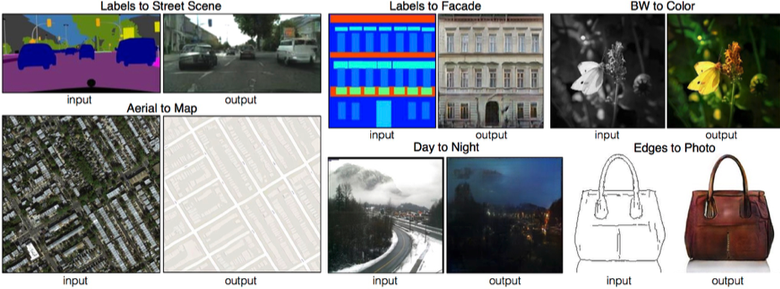
これは、条件付きGANの成功の別の例です。この場合、条件は全体像になります。 画像のセグメンテーションで一般的なUNetはジェネレーターアーキテクチャとして使用され、ぼやけた画像と戦うために、新しいPatchGAN分類器が弁別器として使用されました(画像はN個のパッチにカットされ、偽物/実際の予測はそれぞれ個別に行われます)。
著者は 、ネットワークのオンラインデモをリリースしました。これはユーザーに大きな関心を呼びました。
ソースコード 。
3.10。 CycleGAN
Pix2Pixを使用するには、異なるドメインの対応する画像のペアを含むデータセットが必要です。 たとえば、カードの場合、そのようなデータセットの収集は問題になりません。 しかし、オブジェクトの「変形」やスタイリングなど、もっと複雑なことをしたい場合は、原則としてオブジェクトのペアを見つけることはできません。 したがって、Pix2Pixの作成者はアイデアを開発することを決定し、特定のペアなしで異なる画像ドメイン間で転送するためのCycleGANを考案しました-Unpaired Image-to-Image Translation。

考え方は次のとおりです.1つのドメインから別のドメインへ、またはその逆に2つのジェネレーターとディスクリミネーターのペアを学習しますが、サイクルの一貫性が必要です-ジェネレーターを連続して使用した後、元のL1損失と同様の画像が得られます ジェネレータが1つのドメインの画像を元の画像とはまったく無関係に変換し始めるだけではないように、循環損失が必要です。
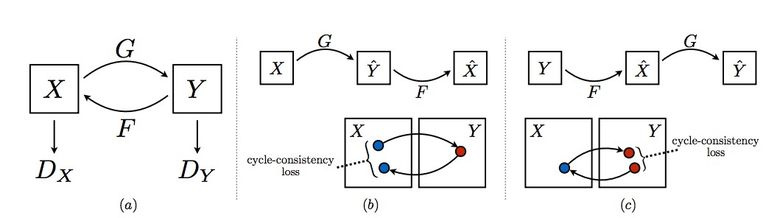
このアプローチにより、馬のマッピング->シマウマを学ぶことができます。

このような変換は不安定に機能し、多くの場合、失敗したオプションを作成します。

ソースコード 。
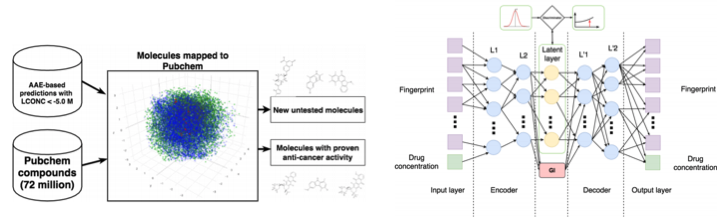
3.11。 腫瘍学における分子の開発
機械学習は医学になりました。 超音波、MRI、診断の認識に加えて、がんと戦うための新薬の検索にも使用できます。
この研究については、すでに簡単にここで詳細に書いています 。したがって、Adversarial Auto Encoder(AAE)を使用すると、分子の潜在表現を学習し、それを使用して新しい分子を探すことができます。 その結果、69個の分子が発見されましたが、その半分は癌と戦うために使用され、残りは重大な可能性を秘めています。
3.12。 敵の攻撃
敵対攻撃に関するトピックは積極的に調査されています。 これは何ですか たとえば、ImageNetでトレーニングされた標準ネットワークは、分類された画像に特別なノイズを追加するには完全に不安定です。 以下の例では、人間の目にノイズのある画像は実質的に変化しないことがわかりますが、モデルは狂って完全に異なるクラスを予測します。

安定性は、たとえば高速勾配符号法(FGSM)を使用して実現されます。モデルパラメーターにアクセスできるため 、目的のクラスの方向に1つ以上の勾配ステップを実行して、元の画像を変更できます。
今後のNIPSのためのKaggleのタスクの1つは、これに正確に関連しています。参加者は、最終的にすべての人に対して最善を決定するためのすべての攻撃/防御を作成するように招待されます。
なぜこれらの攻撃を調査する必要があるのですか? まず、製品を保護する場合は、キャプチャにノイズを追加して、スパマーが自動的に認識できないようにします。 第二に、アルゴリズムは私たちの生活にますます関与しています-顔認識システム、無人車両。 同時に、攻撃者はアルゴリズムの欠点を利用できます。 特殊な眼鏡を使用すると、顔認識システムをだまして、他の人に「自分を紹介する」ことができる例を次に示します。 そのため、攻撃の可能性を考慮してモデルを教える必要があります。

記号を使用したこのような操作でも、記号を正しく認識できません。

攻撃用のすでに記述されたライブラリ: cleverhansおよびfoolbox
4.強化トレーニング
強化学習(RL)、または強化学習も、機械学習で最も興味深く活発に開発されているトピックの1つです。
アプローチの本質は、相互作用するときに報酬を提供する環境でエージェントの成功した行動を学ぶことです。 一般的に、経験を通じて-人々が生涯を通じて学ぶように。
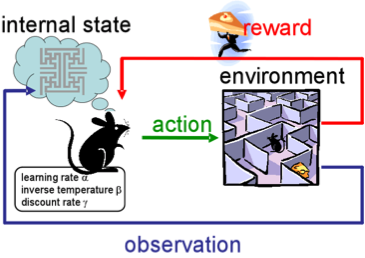
RLは、ゲーム、ロボット、およびシステム管理(トラフィックなど)で積極的に使用されています。
もちろん、最高のプロを追いかけるゲームで、DeepMindからのAlphaGoの勝利については誰もが耳にしました。 著者による記事がNatureの「Goのゲームをマスターする」に掲載されました。 トレーニングでは、開発者はRLを使用しました。ボットは戦略を改善するためにボット自体を使用しました。
4.1。 制御されていないサポートタスクによる強化トレーニング
過去数年間、DeepMindはDQNを使用して人間よりもアーケードゲームを上手にプレイする方法を学びました。 アルゴリズムは、 Doomのようなより複雑なゲームをプレイすることを教えています。
環境と対話するエージェントのエクスペリエンスを構築するには、最新のGPUで何時間ものトレーニングが必要になるため、学習の加速に多くの注意が払われています。
彼のブログのDeepmindは、フレームの変化の予測(ピクセル制御)などの追加の損失(補助タスク、補助タスク)の導入により、エージェントがアクションの結果をよりよく理解し、学習を大幅にスピードアップするという事実について語っています。
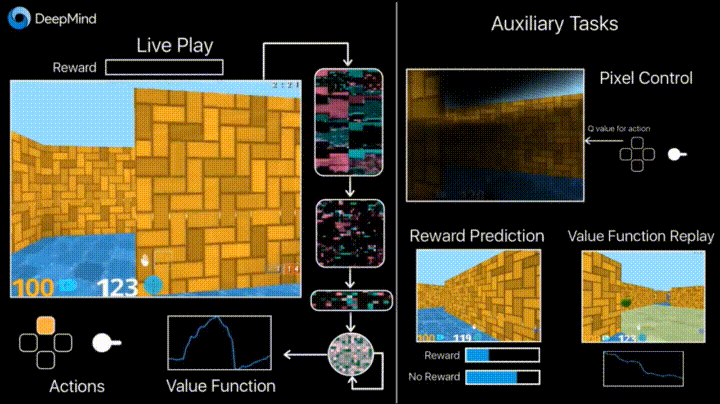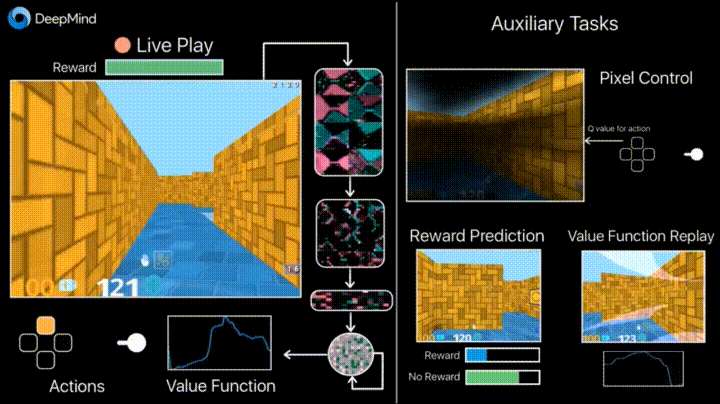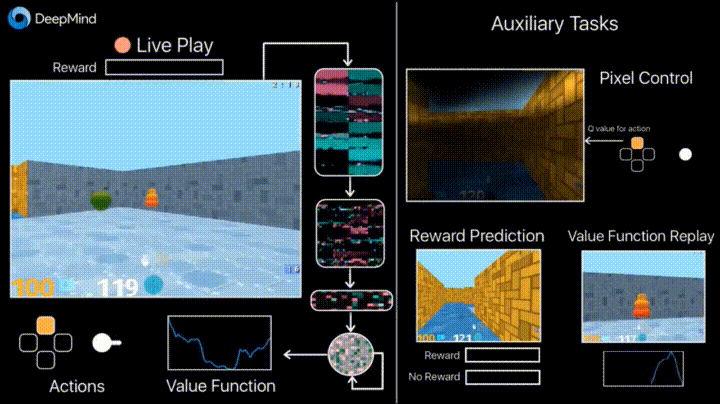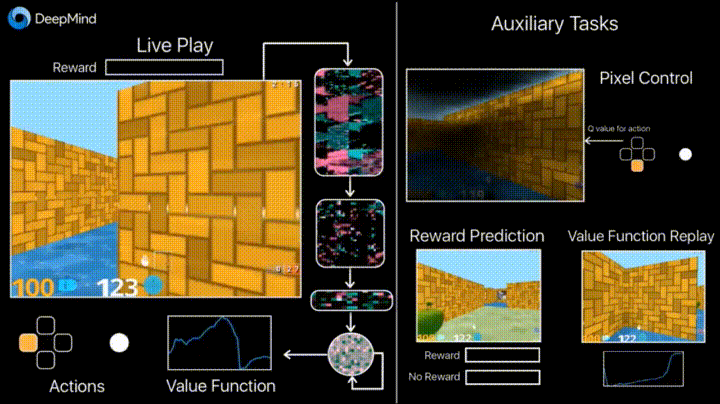
学習成果:
4.2。 学習ロボット
OpenAIは、仮想環境でのヒューマンエージェントトレーニングを積極的に模索しています。これは、実生活よりも実験の方が安全です。)
調査の 1つで、チームはワンショット学習が可能であることを示しました:人がVRで特定のタスクを実行する方法を示し、1つのデモンストレーションでそれを学習し、それを実際の条件で再生するのに十分です。

ああ、もしそれが人々にとってとても簡単だったら;)
4.3。 人間の好みに関するトレーニング
OpenAIとDeepMindは同じトピックで機能します。 要するに、エージェントには特定のタスクがあり、アルゴリズムは人に2つの可能な解決策を提供し、人はどちらが良いかを示します。 このプロセスは繰り返し繰り返され、人からの900ビットのフィードバック(バイナリマークアップ)のアルゴリズムは問題を解決することを学びました。


いつものように、人は注意を払い、自分が機械を教えていることについて考える必要があります。 たとえば、評価者は、アルゴリズムがオブジェクトを実際に取得することを望んでいると判断しましたが、実際には、このアクションを模倣しただけです。
4.4。 複雑な環境での動き
DeepMindからの別の研究 。 ロボットの複雑な動作(歩行/ジャンプ/ ...)、さらには人間に似た動作を教えるには、希望する動作を促進する損失関数の選択と非常に混同する必要があります。 しかし、単純な報酬に依存して、アルゴリズム自体に複雑な動作を学習させたいと思います。
研究者はこれをなんとか達成しました:彼らは、障害物と動きの進歩に対する単純な報酬で複雑な環境を構築することにより、複雑なアクションを実行するエージェント(ボディエミュレーター)を教えました。

結果の印象的なビデオ 。 しかし、音が重ね合わされている方がずっとおもしろいです;)
最後に、最近公開されたOpenAI RL学習アルゴリズムへのリンクを提供します。 これで、すでに標準のDQNになっているよりも新しいソリューションを使用できます。
5.その他
5.1。 データセンターの冷却
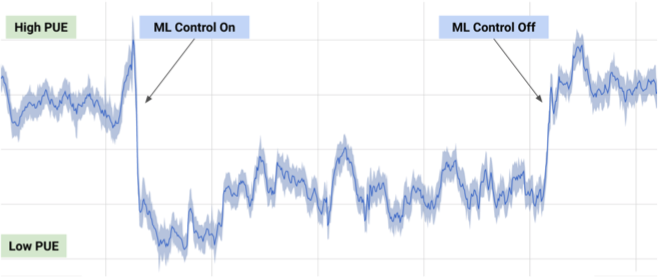
2017年7月、Google は 、機械学習におけるDeepMindの開発を活用して、データセンターのエネルギーコストを削減したと述べました。
データセンターの数千のセンサーからの情報に基づいて、Google開発者は、PUE(電力使用効率)とより効率的なデータセンター管理を予測するために、ニューラルネットワークのアンサンブルをトレーニングしました。 これは、MLの印象的で意味のある実用的な例です。
5.2。 すべてのタスクに対応する1つのモデル
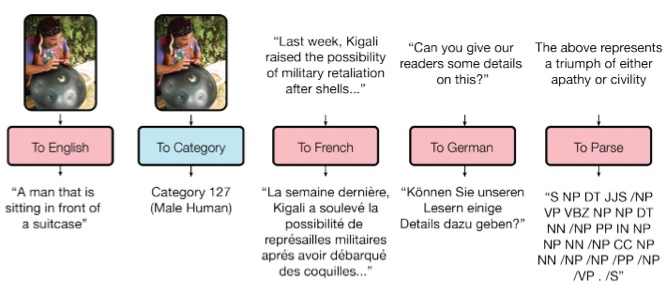
ご存知のように、特定のモデルをトレーニング/再トレーニングする必要がある各タスクについて、トレーニングされたモデルはタスクからタスクにほとんど移行されません。 Google Brainは、 記事 「すべてを学ぶ1つのモデル」で、モデルの普遍性に向けて小さな一歩を踏み出しました。
研究者は、異なるドメイン(テキスト、音声、画像)から8つのタスクを実行するモデルをトレーニングしました。 たとえば、異なる言語からの翻訳、テキストの解析、画像と音声の認識。
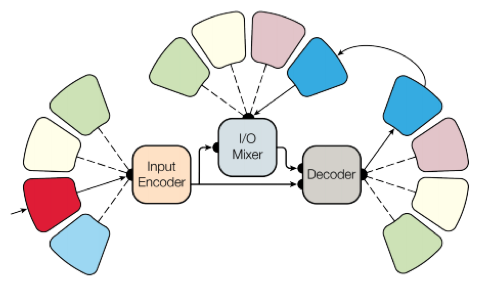
この目標を達成するために、彼らはさまざまな入力データを処理して結果を生成するためのさまざまなブロックを持つ複雑なネットワークアーキテクチャを作成しました。 エンコーダー/デコーダーのブロックは、畳み込み、注意、 ゲーテッドエキスパートミックス (MoE)の3つのタイプに分けられます。
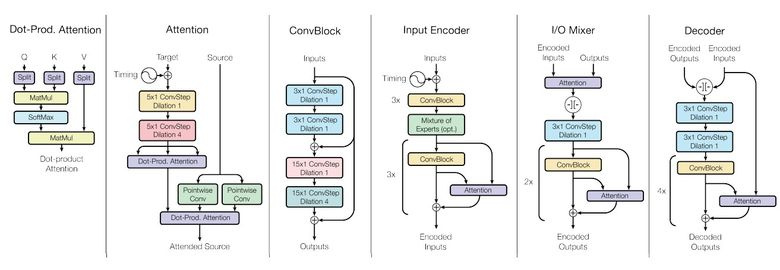
主要な学習成果:
- ほぼ完璧なモデルが得られました(著者はハイパーパラメーターを微調整しませんでした)。
- 異なるドメイン間で知識が転送されます。つまり、大量のデータを持つタスクでは、パフォーマンスはほぼ同じになります。 そして、小さなタスク(例えば、解析)で-より良い;
- さまざまなタスクに必要なブロックは相互に干渉せず、ImagenetタスクのMoEなどにも役立つことがあります。
ところで、このモデルは tensor2tensorにあります。
5.3。 1時間でのImagenetトレーニング
Facebookの投稿で、従業員は、エンジニアがImagenetでResnet-50モデルをわずか1時間でトレーニングできた方法を説明しました。 確かに、これには256 GPUのクラスターが必要でした(Tesla P100)。
分散学習では、GlooとCaffe2が使用されました。 プロセスを効率的に進めるには、学習戦略を巨大なバッチ(8192要素)に適応させる必要がありました:勾配の平均化、ウォームアップフェーズ、特別な学習率など。 詳細については、記事をご覧ください 。
その結果、8個から256個のGPUに拡張しながら、90%の効率を達成することができました。 現在、Facebookの研究者は、このようなクラスターのない単なる人間とは異なり、さらに高速に実験できます;)
6.ニュース
6.1。 無人車両
無人車両の分野は急速に発展しており、マシンは戦闘状態で積極的にテストされています。 比較的最近の出来事の中で、IntelがMobilEyeを購入したこと、Uberをめぐるスキャンダル 、Googleの元従業員が盗んだ技術、オートパイロットの仕事中の最初の死などが注目に値します。
注意点:Google Waymo はベータプログラムを開始します。 Googleはこの分野の先駆者であり、自動車は300万マイル以上走行しているため、同社の技術は非常に優れていると想定されています。
また、最近では、無人の車両がすべての米国の州を横断することが許可されました 。
6.2。 ヘルスケア
私が言ったように、現代のMLは医学に定着し始めています。 たとえば、Googleは診断センターを支援するために医療センターと協力しています。
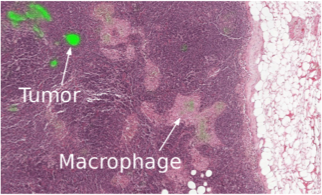

今年は、データサイエンスボウルの一環として、詳細な画像に基づいて1年で肺がんを予測するコンテストが開催されました。賞金は100万ドルです。
6.3。 投資
今では、以前と同様、BigDataでMLに多大な投資を行っています。
中国はAIに1500億ドルを投資し、業界の世界的リーダーになりました。
比較のために、Baidu Researchで1,300人、FAIR(Facebook)で80人が働いています。最後のKDDで、Alibabaの従業員は、1兆個のパラメーターを持つ1,000億のサンプルで実行されるパラメーターサーバーKungPengについて話しました。 c)

結論を出し、MLを学びます。 いずれにせよ、時間の経過とともに、すべての開発者は機械学習を使用するようになります。これは今日のデータベースを操作する能力であるため、能力の1つになります。