PostgreSQLのインデックスメカニズム 、 アクセスメソッドインターフェイス、および3つのメソッド( ハッシュインデックス 、 Bツリー、 GiST)については既に説明しました 。 このパートでは、SP-GiSTについて説明します。
SP-GiST
まず、名前について少し。 「GiST」という言葉は、同じ名前のメソッドとの特定の類似性を示唆しています。 本当に類似点があります。両方とも一般化された検索ツリーであり、異なるアクセス方法を構築するためのフレームワークを提供する一般化された検索ツリーです。
「SP」はスペースパーティションを表します。 多くの場合、 スペースの役割は、 スペースと呼ばれるものとまったく同じです。たとえば、2次元の平面です。 しかし、これから見るように、これは任意の検索スペース、本質的には任意の値の範囲を指します。
SP-GiSTは、空間が非連結領域に再帰的に分割される構造に適しています。 このクラスには、四分木、k次元木(kD木)、接頭辞木(トライ)が含まれます。
装置
そのため、SP-GiSTインデックス方式の考え方は、値の範囲を重複しないサブドメインに分割し、各サブドメインを分割することです。 このようなパーティションは、 不均衡なツリーを生成します(Bツリーや通常のGiSTとは異なります)。
非交差プロパティは、挿入および検索時の意思決定を簡素化します。 一方、結果のツリーは通常、弱く分岐しています。 たとえば、通常、象限ノードには4つの子ノード(数百単位で測定されるBツリーとは異なります)と大きな深さがあります。 このようなツリーはRAMでの作業に適していますが、インデックスはディスクに格納されるため、I / Oの数を減らすには、ノードをページにパックする必要があります。これは効率的に行うのは容易ではありません。 また、分岐の深さが異なるため、インデックス内の異なる値の検索時間は異なる場合があります。
GiSTのように、このアクセス方法は低レベルのタスク(同時アクセスとブロッキング、ロギング、検索アルゴリズム自体)を処理し、新しいデータ型とパーティションアルゴリズムのサポートを追加して、このための特別な簡素化されたインターフェイスを提供します。
SP-GiSTツリーの内部ノードには、子ノードへのリンクが保存されます。 各リンクにラベルを付けることができます。 さらに、内部ノードはプレフィックスと呼ばれる値を保存できます。 実際、この値はプレフィックスである必要はありません。 すべての子ノードに対して実行される任意の述語と見なすことができます。
SP-GiSTリーフノードには、インデックス値とテーブル行(TID)へのリンクが含まれます。 インデックス付きデータ自体(検索キー)を値として使用できますが、必ずしもそうである必要はありません。短縮値も保存できます。
さらに、リーフノードをリストにまとめることができます。 したがって、内部ノードは単一の値ではなく、リスト全体を参照できます。
リーフノードのプレフィックス、ラベル、および値はすべて、完全に異なるデータ型にすることができます。
GiSTの場合と同様に、検索のために定義する必要がある主な関数は一貫性関数です。 この関数はツリーノードに対して呼び出され、値が検索述語(通常、「 インデックスフィールド演算子式 」の形式)と「一貫性がある」子ノードのセットを返します。 リーフノードの場合、整合性関数は、そのノードのインデックス値が検索述語を満たすかどうかを判断します。
検索はルートノードから始まります。 一貫性機能を使用すると、どの子ノードに入るのが理にかなっているかが明らかになります。 アルゴリズムは、見つかったノードごとに繰り返されます。 検索は詳細に行われます。
物理レベルでは、インデックスノードはページにパックされるため、I / O操作の観点から効率的に操作できます。 同時に、1ページに内部ノードまたはリーフノードのいずれかがありますが、同時に両方はありません。
例:象限木
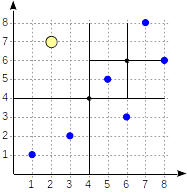
四分木は、平面上の点にインデックスを付けるために使用されます。 この考え方は、 中心点を基準にして領域を4つの部分(象限)に再帰的に分割することです。 このようなツリーの枝の深さは変化し、対応する象限の点の密度に依存します。
以下は、サイトopenflights.orgの空港で補完されたデモベースの例の写真での外観です。 ところで、最近データベースの新しいバージョンをリリースしました。このバージョンでは、経度と緯度をタイプポイントの1つのフィールドに置き換えました。

まず、平面を4つの象限に分割します...
次に、各象限を分割します...
そして、最終パーティションが得られるまで続きます。
次に、GiSTパートですでに見た簡単な例を詳しく見てみましょう。 この場合、分割面は次のようになります。
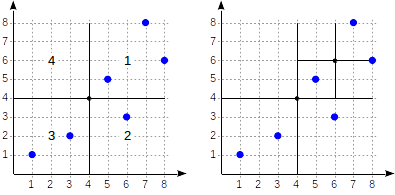
象限には、最初の図に示すように番号が付けられています。 明確にするために、子ノードをこの順序で左から右に並べます。 この場合に可能なインデックス構造を次の図に示します。 各内部ノードは、最大4つの子ノードを参照します。 図のように、各リンクに象限番号を付けることができます。 ただし、実装にはラベルはありません。 4つのリンクの固定配列を保存する方が便利です。そのうちのいくつかは空の場合があります。
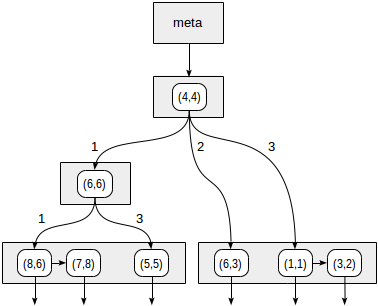
境界線上にあるポイントは、数字が小さい象限を指します。
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index points_quad_idx on points using spgist(p);
CREATE INDEX
この場合、デフォルトではquad_point_ops演算子クラスが使用され、次の演算子が含まれます。
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1
>>(point,point) | 5
~=(point,point) | 6
<^(point,point) | 10
>^(point,point) | 11
<@(point,box) | 8
(6 rows)
たとえば
select * from points where p >^ point '(2,7)'
クエリが実行される
select * from points where p >^ point '(2,7)'
どのように実行されるかを考えます
select * from points where p >^ point '(2,7)'
指定されたポイントよりも高いすべてのポイントを見つけます)。
ルートノードから開始し、整合性関数を使用して、どの子ノードを下降させるかを選択します。 演算子
>^
この関数はポイント(2,7)をノードの中心ポイント(4,4)と比較し、目的のポイントを配置できる象限(この場合は1番目と4番目)を選択します。
最初の象限に対応するノードで、一貫性関数を使用して子ノードを再度決定します。 中心点(6.6)、そして再び、第1および第4象限を見る必要があります。
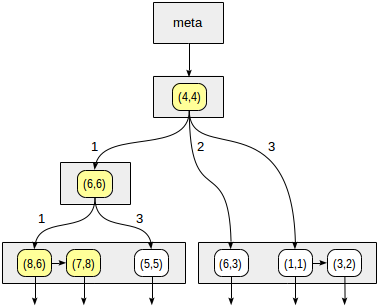
最初の象限は、リーフノード(8.6)および(7.8)のリストに対応し、そのうちポイント(7.8)のみがクエリ条件に適しています。 4番目の象限への参照は空です。
内部ノード(4.4)では、4番目の象限への参照も空であり、検索が完了します。
postgres=# set enable_seqscan = off;
SET
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
内側
SP-GiSTインデックスの内部構造は、前述のgevel拡張を使用して調べることができます。 悪いニュース:エラーのため、拡張機能は最新バージョンのPostgreSQLでは正しく機能しません。 良いニュース:gevel機能をpageinspectに移植する予定です( ディスカッション )。 そして、エラーはすでに修正されています。
例として、世界地図で絵を描くために使用された拡張デモベースを取り上げます。
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
CREATE INDEX
最初に、インデックスに関するいくつかの統計情報を見つけることができます。
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats
----------------------------------
totalPages: 33 +
deletedPages: 0 +
innerPages: 3 +
leafPages: 30 +
emptyPages: 2 +
usedSpace: 201.53 kbytes+
usedInnerSpace: 2.17 kbytes +
usedLeafSpace: 199.36 kbytes+
freeSpace: 61.44 kbytes +
fillRatio: 76.64% +
leafTuples: 5993 +
innerTuples: 37 +
innerAllTheSame: 0 +
leafPlaceholders: 725 +
innerPlaceholders: 0 +
leafRedirects: 0 +
innerRedirects: 0
(1 row)
次に、インデックスツリー自体を表示します。
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, --
node_label int, -- ( )
leaf_value point --
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...
しかし、覚えておいてください。 spgist_print関数はすべてのリーフ値を表示するのではなく、リストの最初の値のみを表示するため、インデックスの構造を表示し、その全内容を表示しないこと。
例:k次元の木
平面上の同じ点に対して、空間を分割する別の方法を提案できます。
最初のインデックス付きポイントを通る水平線を描画します。 彼女は飛行機を上下の2つの部分に分けます。 2番目のインデックスポイントは、これらの部分のいずれかに該当します。 この部分に垂直線を引いて、この部分を2つに分割します:右と左。 次の点まで、水平線を再度描画し、次の点まで-垂直線などを描画します。
この方法で構築されたツリーのすべての内部ノードには、2つの子ノードしかありません。 2つのリンクのそれぞれは、階層内の次の内部ノード、またはリーフノードのリストのいずれかにつながる可能性があります。
この方法は、k次元空間に簡単に一般化できるため、文献では、ツリーはk次元(kDツリー)とも呼ばれます。
たとえば、空港:
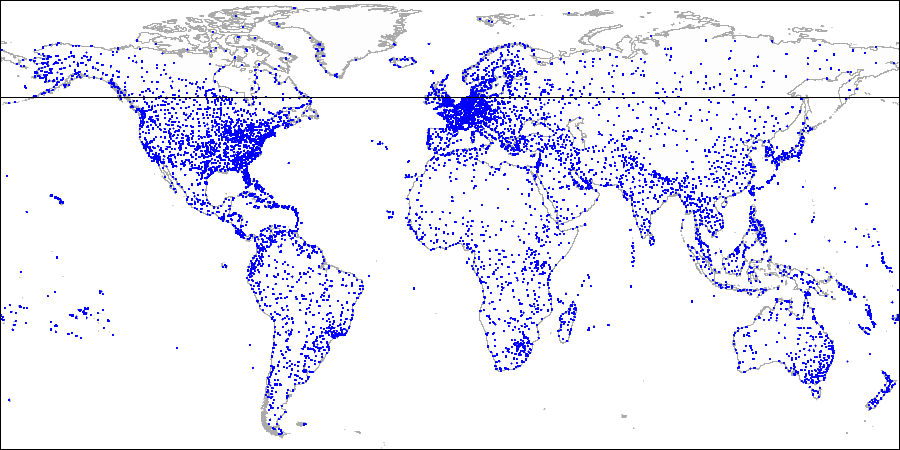
まず、飛行機を上下に分けて......
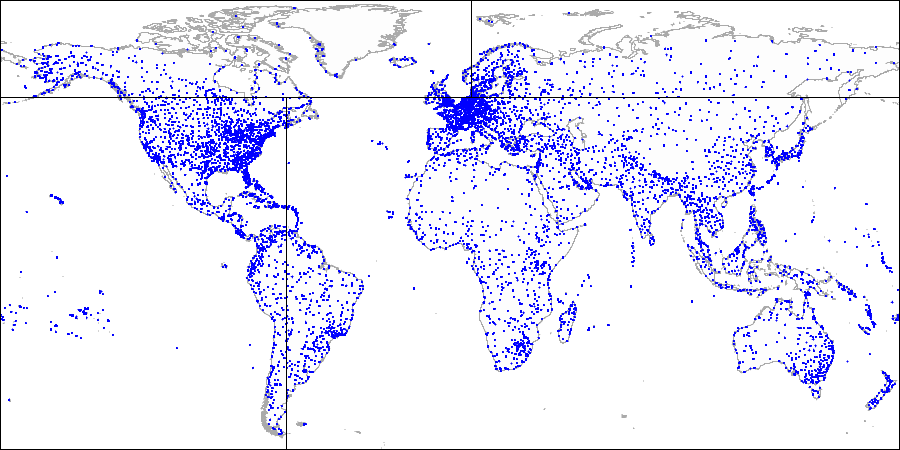
それから左右の各ピースは......

そして、最終パーティションが得られるまで続きます。
このようなパーティションのみを使用するには、インデックスを作成するときにkd_point_ops演算子クラスを明示的に指定する必要があります。
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops );
CREATE INDEX
このクラスには、「デフォルト」のquad_point_opsとまったく同じ演算子が含まれています。
内側
ツリーの構造を表示するとき、この場合の接頭辞は点ではなく、1つの座標のみであることに注意する必要があります。
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, --
node_label int, -- ( )
leaf_value point --
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
例:プレフィックスツリー
SP-GiSTを使用して、文字列のプレフィックスツリー(基数ツリー)を実装することもできます。 プレフィクスツリーの考え方は、インデックス付けされた行が完全にリーフノードに格納されるのではなく、ノードに格納された値を特定のルートからルートに連結することによって取得されるというものです。
たとえば、「postgrespro.ru」、「postgrespro.com」、「postgresql.org」、「planet.postgresql.org」などのサイトのアドレスにインデックスを付ける必要があるとします。
postgres=# create table sites(url text);
CREATE TABLE
postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
INSERT 0 4
postgres=# create index on sites using spgist(url);
CREATE INDEX
ツリーは次のようになります。
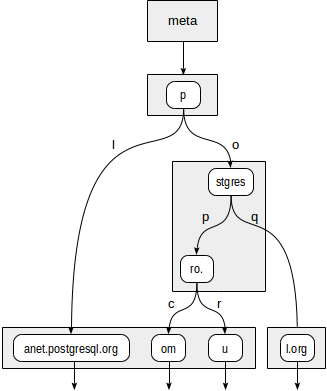
ツリーの内部ノードは、すべての子ノードに共通のプレフィックスを格納します。 たとえば、stgresノードの娘では、値はp + oおよびstgresで始まります。
象限のツリーとは対照的に、子ノードへの各ポインターは、さらに1文字(実際には2バイトですが、これはそれほど重要ではありません)でマークされます。
演算子クラスtext_opsは、b-treeの従来の演算子「equal」、「more」、「less」をサポートします。
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
チルダを使用した演算子は、 文字ではなくバイトで機能するという点で異なります。
場合によっては、値が完全に保存されず、ツリー内を移動するときに必要に応じて再構築されるため、プレフィックスツリーの形式の表現はBツリーよりも大幅にコンパクトになることがあります。
select * from sites where url like 'postgresp%ru'
。 インデックスを使用して実行できます。
postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
実際、インデックスには「postgresp」以上で「postgresq」(Index Cond)よりも小さい値が含まれており、結果から適切な値(Filter)が選択されます。
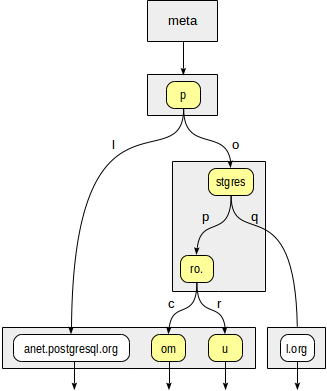
最初に、一貫性関数は、ルート「p」のどの子ノードに到達する必要があるかを決定する必要があります。 次の2つのオプションがあります。「p」+「l」(さらには見えなくても適合しません)および「p」+「o」+「stgres」(適合)。
stgresノードは、postgres + p + ro。(適切)およびpostgres + q(不適切)を確認するために、一貫性関数を使用する必要があります。
「ro。」ノードとそのすべての子リーフノードの場合、整合性関数は「適切」と言うため、インデックスメソッドは2つの値「postgrespro.com」と「postgrespro.ru」を返します。 これらのうち、すでにフィルタリング段階で、1つの適切な値が選択されます。
内側
ツリーの構造を表示するときは、データ型を考慮する必要があります。
postgres=# select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, --
node_label smallint, --
leaf_value text --
)
order by tid, n;
プロパティ
spgistアクセスメソッドのプロパティを見てみましょう(リクエストは以前に与えられました ):
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
SP-GiSTインデックスを使用して、一意性をソートおよび維持することはできません。 さらに、そのようなインデックスは、(GiSTとは異なり)複数の列に構築できません。 制限をサポートするための例外の使用は許可されています。
インデックスプロパティ:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
ここで、GiSTとの違いはクラスタリングの欠如です。
最後に、列レベルのプロパティ:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
ソートはサポートされていませんが、これは理解できます。 SP-GiSTで最近傍を見つけるための距離演算子はまだ利用できません。 おそらく、そのようなサポートは将来登場するでしょう。
SP-GiSTは、少なくとも考慮される演算子のクラスに対して、インデックススキャン専用に使用できます。 これまで見てきたように、場合によっては、インデックス付けされた値がリーフノードに直接格納され、場合によっては、ツリーの下降時に部分的に復元されます。
未定義の値
これまでのところ、状況を複雑にしないために、不確実な値については何も述べていません。 インデックスプロパティからわかるように、NULLがサポートされています。 そして本当に:
postgres=# explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
ただし、SP-GiSTのあいまいな意味は異質なものです。 spgistメソッドの演算子のクラスに含まれるすべての演算子は厳密でなければなりません。未定義のパラメーターについては、未定義の結果を返す必要があります。 これにより、メソッド自体が提供されます。 未定義の値は単に演算子に渡されません。
ただし、アクセス方法をインデックススキャン専用に使用するには、不定値をインデックスに保存する必要があります。 これらは保存されますが、独自のルートを持つ別のツリーに保存されます。
その他のデータ型
PostgreSQLは、文字列のポイントとプレフィックスツリーに加えて、SP-GiSTに基づいた他のメソッドも実装しています。
- 四角形の象限木は、box_ops演算子クラスを提供します。
各長方形は4次元空間の点として表されるため、象限の数は16です。長方形間の交差点が多い場合、このようなインデックスはパフォーマンスでGiSTを上回ることができます。 4次元でも)そのような問題はありません。
- 範囲の象限木は、range_ops演算子クラスを提供します。
間隔は2次元の点で表されます。下の境界が横座標になり、上の境界が縦座標になります。
継続する 。