そのため、最初からデータサイエンスを教えることに専念したサイクルの最後の記事では 、ランプおよび昼光放射スペクトルの分類の例を使用して、scikit-learnライブラリ(Python)から独自のデータセットおよびトレーニングモデルを作成する問題について説明しました。
今回は、データセットが消えないように、前回の記事を見て、機械学習タスクの小さな断片と比較しますが、今回はC#
猫を歓迎します。

そもそも、機械学習、Python、およびC#の知識が等しく乏しいこと、つまりほとんど何も知らないことに注意する必要があります。したがって、この記事では読者にあらゆる種類の名手コードや特に貴重な情報を提供することはほとんどありません。 他の問題では、私たちはそのような目標を設定していませんか?
前と同様に、コードスニペットとデータをGitHubで取得できます
パート1.プレリュード
前の記事で説明したことを簡単に思い出してみましょう。
Spectralworkbench (Public Lab)オープンソースプロジェクトを使用して、昼光スペクトル、蛍光灯、白色光の色合いが異なると思われる色レンダリング品質のLEDランプの小さなコレクションをまとめました。 セットには、各クラスの30のトレーニングサンプルと11のコントロールサンプルがそれぞれ含まれていました。
さらに、長い怒りの末、ようやく機械学習を開始し、最終的にトレーニングを行いました。パラメーターの選択を含むRandomForestClassifierおよびLogisticRegression分類器は、T-SNEおよびPCAを使用して2次元形式で記号を表示することにふさわしく、最後にクラスタリングを試みましたデータはDBSCANを使用していましたが、この記事は私のコンピューターとの壮大な戦いを終わらせました。
パート2.アリア
そのため、インターネットで簡単に検索すると、 Accord.NETは .Netエコシステムで最も人気のあるものの1つであることが示唆されています。これは、主にC#向けに設計されているという事実によるものです。 もちろん、このプラットフォームを使用すると、すべての.Net言語(まあ、正確には大部分の言語)でフレームワークを実行できます。
最初に目を引くのは、PythonやRのソリューションと比較して、フレームワークの人気がまだ1桁少ないことです。その結果、例やドキュメントに依存する必要があります。 Visual Studioで開くと便利な、既に組み立てられたプロジェクトとして。 Pythonでの機械学習に関する情報の海のすべての後、これは少し反発的です。この場合、おそらくPCAを使用して分類(SVM)と標識の表示に自分を限定した理由です。
そのため、MS Visual Studio(2015があった)またはMonoDevelop(Linuxの場合など)が必要です。
原則として、 クイックスタートの手順を使用することもできますし、私の言葉を取り入れることもできます。 Visual Studioの例を示します。
- 新しいコンソールアプリケーションを作成します。
- System.Windows.Forms.dllアセンブリへのリンクを追加すると、グラフを表示するのに役立ちます。
- NuGetパッケージを追加します。Accord、Accord.Controls、Accord.IO、Accord.MachineLearning、Accord.Statistics(これらの一部は、他の人を引っ張ると自動的に追加されます)
- 「コーディング」を開始
Program.csを開き、名前空間を追加します。
using System; using System.Linq; using Accord.Statistics.Models.Regression.Linear; using Accord.Statistics.Analysis; using Accord.IO; using Accord.Math; using System.Data; using Accord.MachineLearning.VectorMachines.Learning; using Accord.Math.Optimization.Losses; using Accord.Statistics.Kernels; using Accord.Controls;
次に、簡単にするために、すべてを基本クラスに詰めます
class Program { static void Main(string[] args) {
だから:
残念ながら便利なライブラリはなく、パンダはありませんが、データは読み取りますが、類似物はあります(私の意見ではあまり便利ではありませんが)。
マイナス面の1つは、これも明らかではありません。必要に応じてcsvまたはxslsを処理するためのアコードが独自のソリューションを提供することに気付く前に、いくつかの「自転車」を集めました。
//This is a program for demonstrating machine //learning and classifying the spectrum of light sources using .net //read data (If you use linux do not forget to correct the path to the files) string trainCsvFilePath = @"data\train.csv"; string testCsvFilePath = @"data\test.csv"; DataTable trainTable = new CsvReader(trainCsvFilePath, true).ToTable(); DataTable testTable = new CsvReader(testCsvFilePath, true).ToTable(); // Convert the DataTable to input and output vectors (train and test) int[] trainOutputs = trainTable.Columns["label"].ToArray<int>(); trainTable.Columns.Remove("label"); double[][] trainInputs = trainTable.ToJagged<double>(); int[] testOutputs = testTable.Columns["label"].ToArray<int>(); testTable.Columns.Remove("label"); double[][] testInputs = testTable.ToJagged<double>();
実際、scikit-learnの用語をすでに吸収している場合は、最初は馴染みのない分類子モデルを教えています。 しかし、原則として、モデルのクラスをプッシュする教師のすべてが明確である必要があり、それからデータでそれをトレーニングし、ラベルの予測を呼び出します(0-LED、1-ランプ、-2昼光)
// training model SVM classifier var teacher = new MulticlassSupportVectorLearning<Gaussian>() { // Configure the learning algorithm to use SMO to train the // underlying SVMs in each of the binary class subproblems. Learner = (param) => new SequentialMinimalOptimization<Gaussian>() { // Estimate a suitable guess for the Gaussian kernel's parameters. // This estimate can serve as a starting point for a grid search. UseKernelEstimation = true } }; // Learn a machine var machine = teacher.Learn(trainInputs, trainOutputs); // Obtain class predictions for each sample int[] predicted = machine.Decide(testInputs);
次に、データを印刷します(結果は写真の少し後で表示されます)
// print result int i = 0; Console.WriteLine("results - (predict ,real labels)"); foreach (int pred in predicted) { Console.Write("({0},{1} )", pred, testOutputs[i]); i++; } //calculate the accuracy double error = new ZeroOneLoss(testOutputs).Loss(predicted); Console.WriteLine("\n accuracy: {0}", 1 - error);
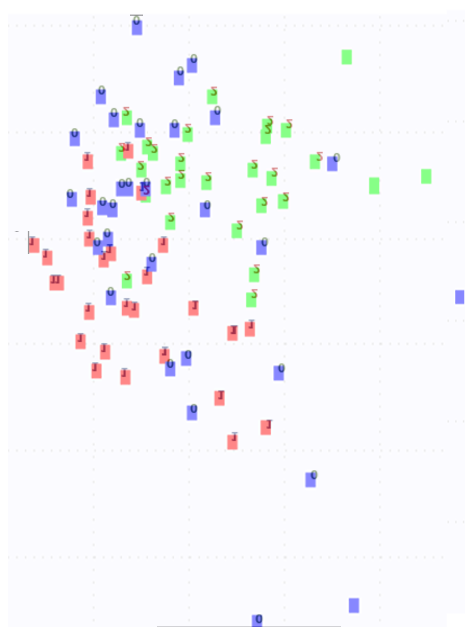
さて、最後のコード-PCAを使用してデータを変換し、散布図を表示します
// consider the decrease in the dimension of features using PCA var pca = new PrincipalComponentAnalysis() { Method = PrincipalComponentMethod.Center, Whiten = true }; pca.NumberOfOutputs = 2; MultivariateLinearRegression transform = pca.Learn(trainInputs); double[][] outputPCA = pca.Transform(trainInputs); // print it on the scatter plot ScatterplotBox.Show(outputPCA, trainOutputs).Hold(); Console.ReadLine();
さて、最後に何が起こったのか:

以前の記事で学んだことと比較しましょう
選択したパラメーターを使用したロジスティック回帰
(予測、事実):
[(0、0)、(0、0)、(0、0)、(2、0)、(0、0)、(0、0)、(0、0)、(0、0)、( 0、0)、(0、0)、(2、0)、(1、1)、(1、1)、(1、1)、(1、1)、(2、1)、(2、 1)、(1、1)、(1、1)、(1、1)、(1、1)、(2、1)、(2、2)、(2、2)、(2、2) 、(0、2)、(2、2)、(2、2)、(2、2)、(2、2)、(2、2)、(2、2)、(2、2)]
テストデータの精度:0.81818
ご覧のとおり、結果は同等です。
PCAチャートをご覧ください。

まあ、原則として、それは少し違いますが、ウェブサイトの開発者は「すべてが正常であり、すべて同じである必要があり、すべてが正しい可能性があり、これらはアルゴリズムの機能である」と述べています(まあ、テキストに近い)。
UPD:ありがとうAirLight
判明したように、グラフが正しく適用され、完全に一致する場合、アルゴリズムの操作と実装の残りの機能だけ、または多分全体がスケールにあると、私はそれを当然とは思わない
パート3.最終。
まとめましょう。 客観的に判断する経験がほとんどないことは明らかなので、主観的になります。
1. Pythonの後の最初に、.Netに戻り、このフレームワークはひどく「凍結」しました。 動的な型指定と便利なデータ操作にすぐに慣れます。 多くの地獄があり、すべてのクラスが実装されていたため、他のモデル名も迷惑でした(まあ、何をすべきかはC#パラダイムです)
2.プロジェクト全体をダウンロードしたくありませんでしたが、クラスを説明する例は、ここに投稿したものを分析した結果「スカム」であり、思ったよりも時間がかかり、複数クラスの分類を本当に理解していませんでした。 scikit-learnでは、箱から出して何とかしてはるかに優れています。
3.一方、モデルは同じ精度を示し、パラメーターを整理する必要さえありませんでした。実装を理解するのが面倒でなければ、ランダムフォレストも収束すると思います。
4.適用する場所 まあ、どうやら、最初に、Windowsフォームに基づいたアプリケーションでは-技術は確かに尊敬と尊敬に値するが、長い間時代遅れであり、MSは開発されていない一方で、私は試していませんが、アコードが普遍的なアプリケーションにフックする可能性はかなりありますWindowsを使用すると、Windows IoTを実行する小さなデバイスでの機械学習とデータ分析の問題を解決できます。
5.クロスプラットフォームに興味がある人なら、そうです-そうです! MonoDevelopを2番目のシステム(Mint)にインストールして、プロジェクトがビルドおよび起動されていることを確認するのは面倒ではありませんでした。つまり、MacOSでも動作するはずです。
プロジェクトのウェブサイトに対する多数のC#ファンと楽観的なコメントを考えると、このフレームワークは、データサイエンスの分野でのC#アプリケーション全体と同様に、わずかではありますが、生命に対する権利を持っていると思います。
データサイエンスの初心者から見た記事「A Train That Can !!」または「Specialization Machine Learning and Data Analysis」で成し遂げたすべての約束が満たされたので、明確な良心をもって短期間退職することができます。
すべての成功と良い週末!