
先日、iOS用の新しいYandex.Taxiアプリをリリースしました。 更新されたインターフェイスでは、ルートの終点(「ポイントB」)の選択に重点が置かれています。 しかし、新しいバージョンは単なる新しいUIではありません。 更新の開始までに、目的地を予測する技術を大幅に作り直し、古いヒューリスティックを履歴データで訓練された分類器に置き換えました。
ご存知のように、機械学習には「良い」ボタンはありません。そのため、一見簡単なタスクがかなりエキサイティングなケースに変わりました。その結果、ユーザーの生活が楽になることを願っています。 現在、新しいアルゴリズムの作業を注意深く監視し続けており、予測の品質がより安定するように変更します。 今後数週間のうちにフル稼働を開始しますが、今後は内部で何が起こっているのかを話す準備ができています。
挑戦する
目的地を選択するとき、「where」フィールドでは、ユーザーがメイン画面の文字通り2〜3のオプションを提供する機会があり、ポイントBを選択するためのメニューに行く場合はさらにいくつかあります。
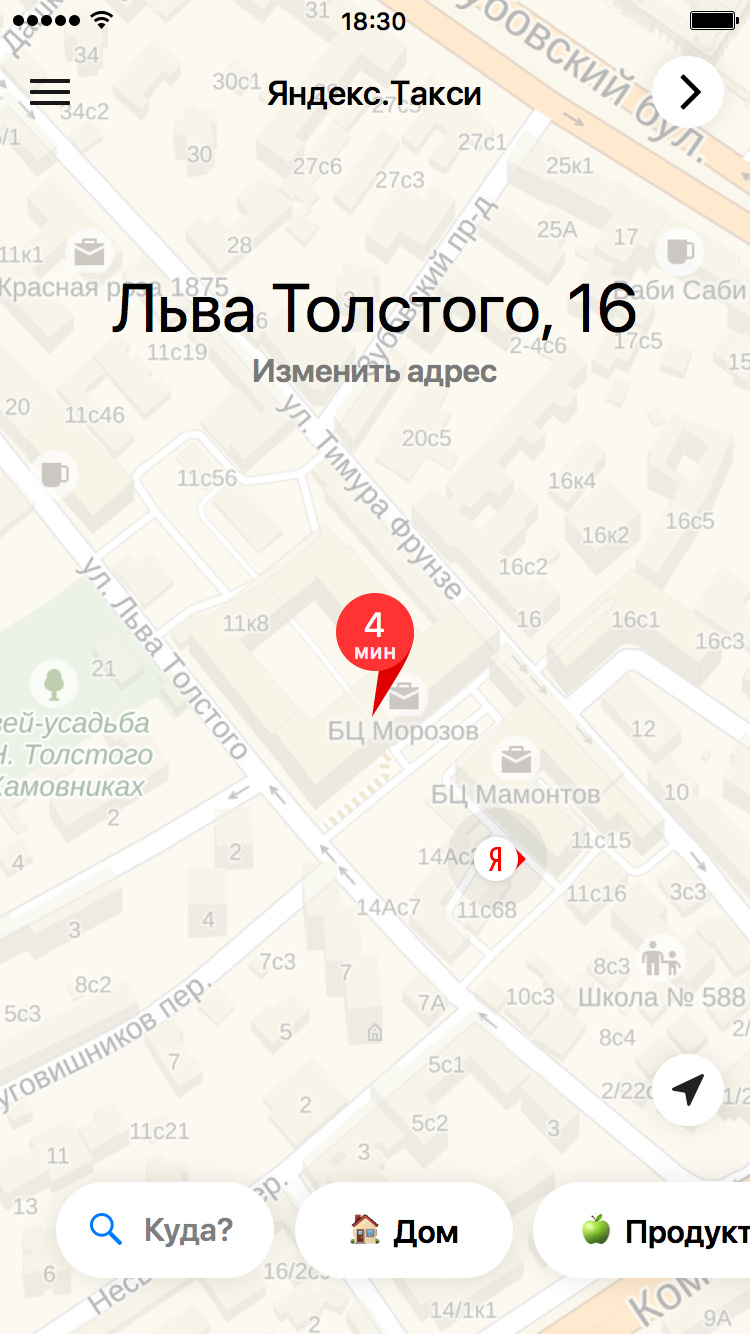
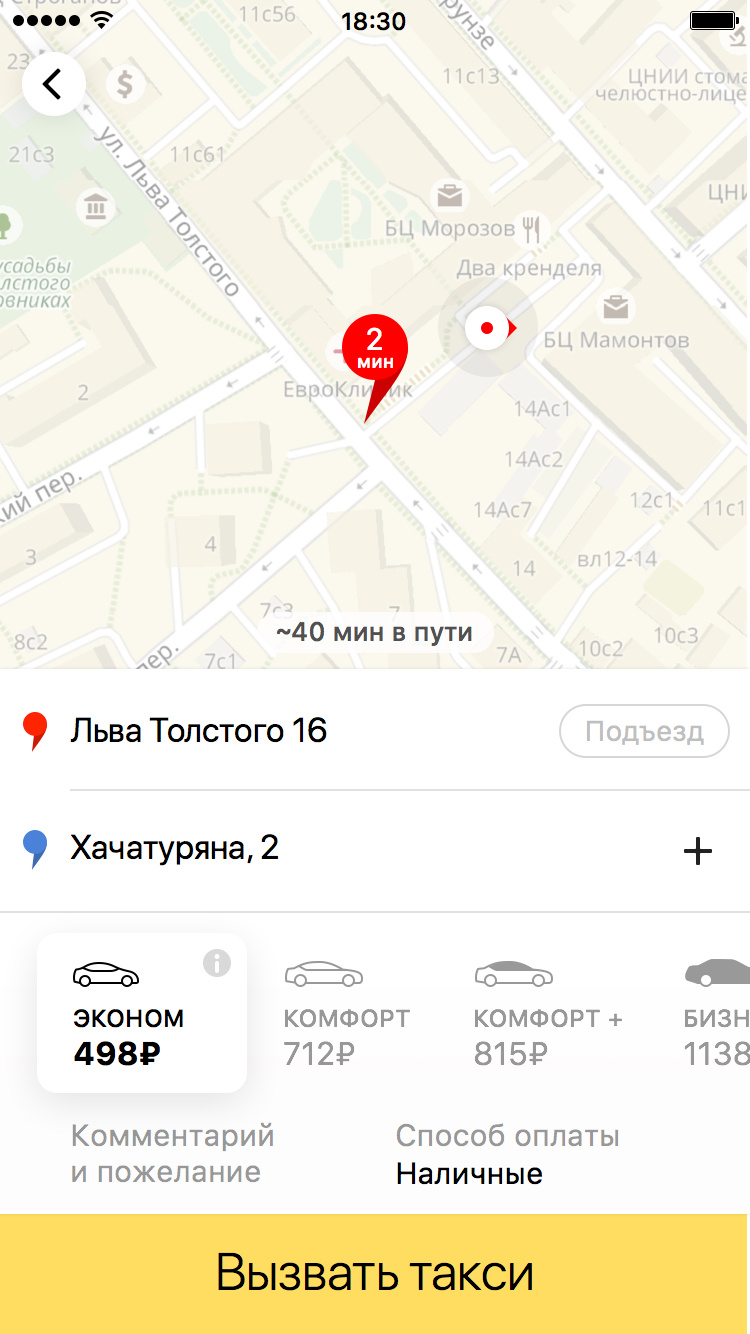
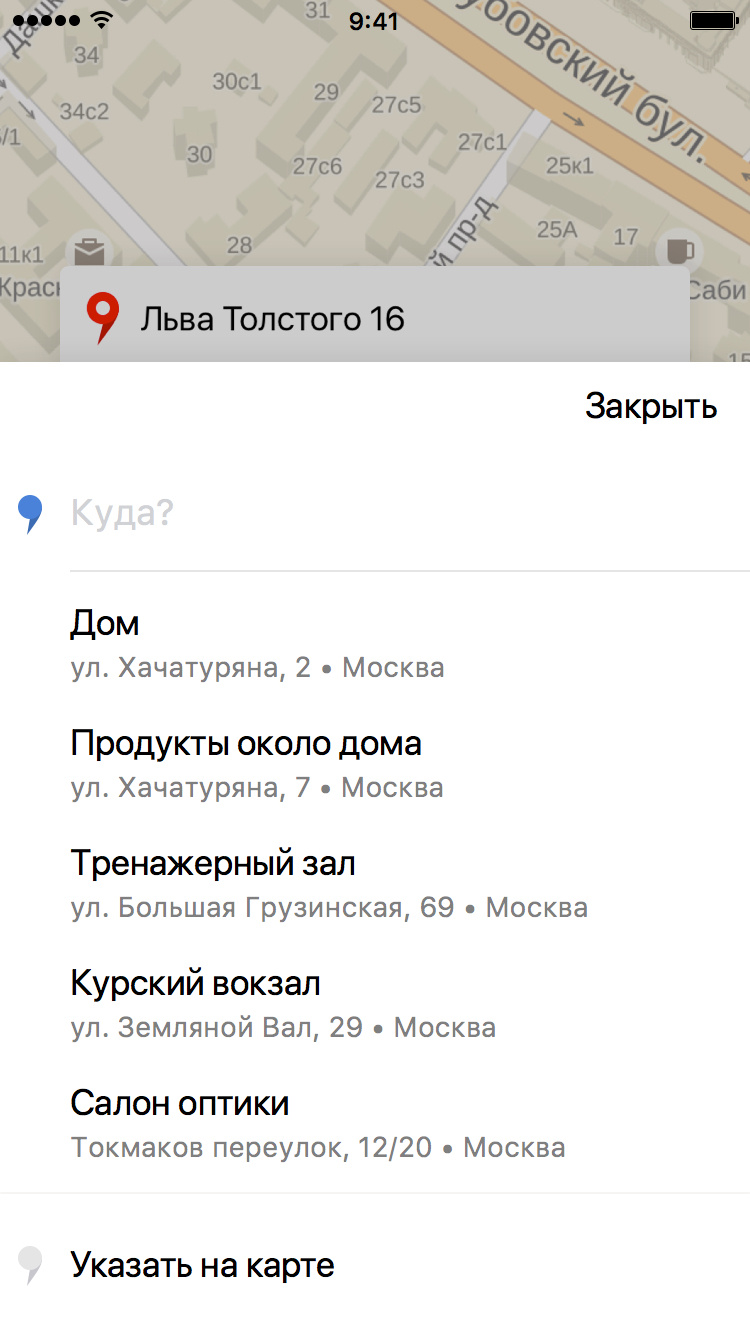
予測が正しい場合、ユーザーは住所を操作する必要はありません。一般的に、アプリケーションが自分の好みを少なくともわずかに記憶できることを喜ぶ理由があります。 これらのヒントのために、ユーザーの旅行履歴に基づいて、どこに行く可能性が高いかを予測しようとするモデルが開発されました。
機械学習に基づいてモデルを構築する前に、次の戦略が実装されました:履歴からすべてのポイントが取得され、「同一の」ポイント(同じ住所または近くにある)がマージされ、異なる場所に異なるポイントが付与されます(ユーザーがこのポイントに移動した場合、この時点で、ある種の時間枠などでこの時点に進みました)。 次に、最高スコアの場所が選択され、ユーザーに推奨されます。 私が言ったように、歴史的にこの戦略はうまくいきましたが、予測の精度は改善される可能性があります。 そして最も重要なこと-私たちは方法を知っていました。
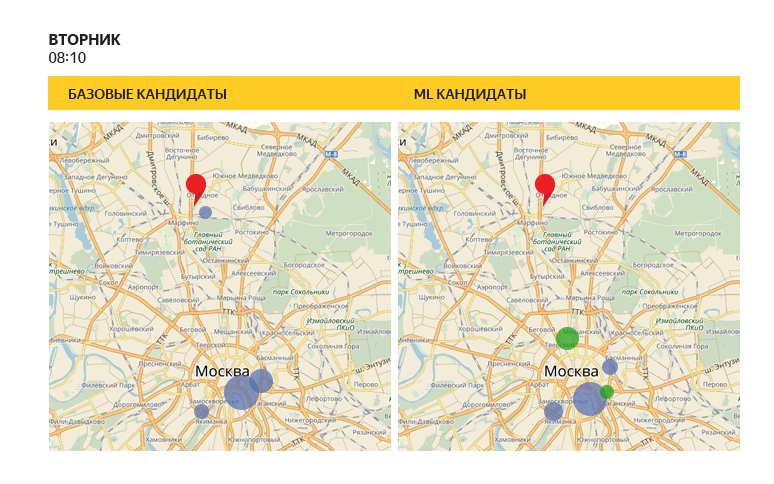
「古い」ヒューリスティックと訓練された分類子は、異なる予測を与えることができます。この図では、円のサイズは、特定の日と特定の時間の推奨リストでこのポイントがどれだけ高いかを示しています。 この例の訓練されたアルゴリズムは、いくつかの追加の場所(緑の円)を示唆していることに注意してください。
私たちのタスクは、「古い」戦略の上に、機械学習を使用して最も可能性の高い「ポイントB」の並べ替えを使用することでした。 一般的なアプローチは次のとおりです:最初に、以前のようにポイントを追加し、次にこれらのポイントの上位n個を取得します(nは明らかに推奨されるものよりも多い)、次に再配置し、ユーザーには最も可能性の高い3つのポイントBのみが表示されますもちろん、リストの候補は最適化中に決定されるため、候補の品質と再配置の品質の両方が可能な限り高くなります。 私たちの場合、候補者の最適数は20でした。
品質評価と結果について
最初に、品質は、候補者の品質とランキングの品質の2つの部分に分割する必要があります。 候補者の質は、選択した候補者が原則として正しく再配置できる範囲です。 そして、ランク付けの品質は、目的地が一般的に候補に含まれている場合に、目的地をどれだけ正確に予測するかです。
最初のメトリック、つまり候補の品質から始めましょう。 注文の約72%のみで、選択されたポイントB(または地理的に非常に近いポイント)が歴史の初期に存在していたことは注目に値します。 これは、候補者の最大の質がこの数によって制限されることを意味します。これは、人が以前に旅行したことがないポイントをまだ推奨できないためです。 これらのポイントの上位20の候補を選択したときに、正解がケースの71%に含まれるように、ポイントの割り当てによるヒューリスティックを選択しました。 最大72%で、これは非常に良い結果です。 候補者のこの質は私たちに完全に適していたので、原則としてはできましたが、モデルのこの部分にはこれ以上触れませんでした。 たとえば、ヒューリスティックの代わりに、別のモデルをトレーニングできます。 しかし、ヒューリスティックに基づく候補検索メカニズムは既に技術的に実装されているため、必要な係数を選択するだけで開発を節約できました。
並べ替えの品質に戻りましょう。 トリップ順序のメイン画面には1つ、2つ、まあ最大で3つのポイントを表示できるため、正しいリストがそれぞれランキングリストのトップ1、トップ2、トップ3にあった場合の割合に関心があります。 機械学習では、(すべての正解の)ランキングリストの上位kにおける正解の割合は、リコール@ kと呼ばれます。 私たちの場合、リコール@ 1、リコール@ 2、リコール@ 3に興味があります。 同時に、問題には「正解」が1つしかありません(間隔が狭い点まで)。つまり、このメトリックは、実際の「点B」がアルゴリズムのトップ1、トップ2、トップ3に該当する場合の割合を示すだけです。 。
基本的なランキングアルゴリズムとして、ポイント数による並べ替えを行い、次の結果(パーセント)を受け取りました。リコール@ 1 = 63.7。 リコール@ 2 = 78.5およびリコール@ 3 = 84.6。 ここでの割合は候補に正しい答えが一般的に存在したそれらの場合の一部であることに注意してください。 ある時点で、論理的な疑問が生じました。おそらく、人気による単純な並べ替えはすでに良い品質を与えており、ポイントによる並べ替えと機械学習の使用のすべてのアイデアは不要ですか? しかし、いいえ、そのようなアルゴリズムは最悪の品質を示しました。リコール@ 1 = 41.2; リコール@ 2 = 64.6; リコール@ 3 = 74.7。
最初の結果を記憶し、機械学習モデルの説明に進みます。
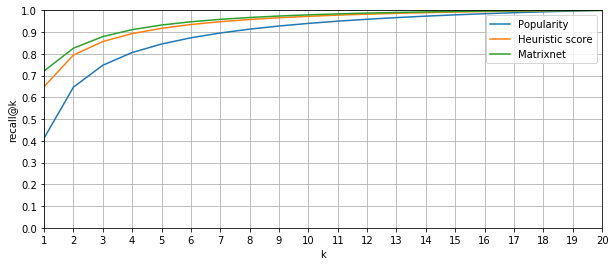
実際の目的地が最初のk個の推奨事項に含まれるケースの割合
構築されたモデル
最初に、候補を見つけるメカニズムについて説明します。 すでに述べたように、ユーザーの旅行の統計に基づいて、ポイントはさまざまな場所に付与されます。 ポイントは、往復する場合にポイントを受け取ります。 さらに、ユーザーが現在いる場所から移動したポイントは、はるかに多くのポイントを受け取ります。これが同じ時期に発生した場合はさらに多くのポイントを受け取ります。 さらに、ロジックは明確です。
それでは、再配置のためにモデルに移りましょう。 最初の近似として、リコール@ kを最大化するため、特定の場所へのユーザーの旅行の確率を予測し、確率によって場所をランク付けします。 「最初の近似」では、これらの推論は確率の非常に正確な推定でのみ真実であり、エラーが表示される場合、別のソリューションでリコール@ kを最適化できるためです。 簡単な例え:機械学習では、すべての確率分布を正確に知っている場合、最良の分類器はBayesianですが、実際には分布はおおよそデータから再構築されるため、他の分類器の方がよく機能します。
分類タスクは次のように設定されました:オブジェクトはペア(ユーザーの以前の旅行の履歴、推奨の候補)で、肯定的な例(クラス1)はユーザーがまだこのポイントBに行ったペアであり、否定的な例(クラス0)はペアですユーザーは最終的に別の場所に行きました。
したがって、1人が燃やされた形式主義者である場合、モデルは人が特定のポイントに行く確率を評価しませんでしたが、与えられた「ストーリーと候補」のペアが関連するシフトされた確率を評価しました。 それにもかかわらず、この値によるソートは、ポイントへのトリップの確率によるソートと同じくらい意味があります。 過剰なデータがある場合、これらは同等のソートになることを示すことができます。
対数損失を最小限に抑えるために分類器をトレーニングし、モデルとして、 Mandrixnet (決定木に対する勾配ブースティング)を使用しました。これは、Yandexで積極的に使用されています。 そして、MatrixNetですべてが明らかな場合、なぜログ損失は依然として最適化されているのでしょうか?
まあ、まず、このメトリックの最適化は、確率の正しい推定値につながります。 これが発生する理由は、最尤法の数学的統計に基づいています。 i番目のオブジェクトの単位クラスの確率を 、そして真のクラスは 。 次に、結果が独立していると見なされる場合、サンプルの尤度(大まかに言えば、取得された結果を正確に取得する確率)は次の積に等しくなります。
理想的には、そのようにしたい この式の最大値を取得します(取得した結果を可能な限り信頼できるものにする必要があるためです)。 しかし、この式を対数化すると(対数は単調関数であるため、元の式の代わりに最大化できます)、次のようになります。 。 そして、これは、私たちが交換した場合、すでにログ損失を知っています 予測によって、式全体にマイナス1を掛けます。
第二に、もちろん、私たちは理論を信頼しますが、念のために、さまざまな損失関数を最適化しようとし、ログ損失が最大のリコール@ kを示したため、すべてが収束しました。
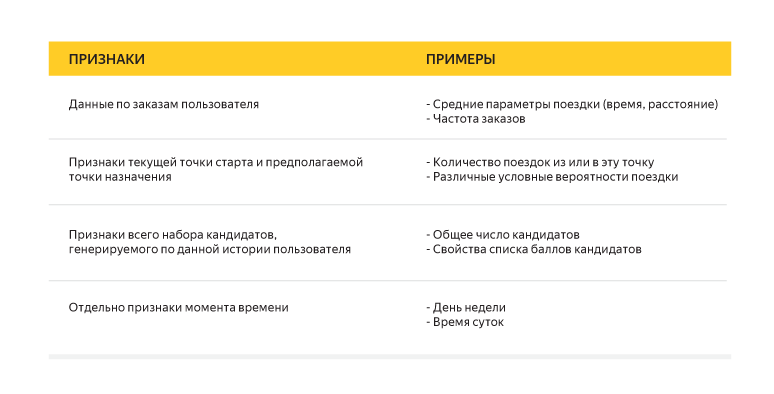
メソッド、エラー関数についても話しましたが、重要な詳細が1つありました。それは、分類器をトレーニングするための記号です。 各ストーリーと候補のペアを説明するために、100以上の異なるキャラクターを使用しました。 以下に例を示します。
そして最後に、結果について:構築したモデルの助けを借りて再配置した後、次のデータが得られました(再び、パーセントで)。リコール@ 1 = 72.1(+8.4); リコール@ 2 = 82.6(+4.1); リコール@ 3 = 88(+3.4)。 悪くはありませんが、標識に追加情報を含めることにより、将来の改善が可能です。
新しい予測アルゴリズムがユーザーに対してどのように見えるかの例を見ることができます。

今後の計画
もちろん、モデルを改善するための多くの実験があります。 ユーザーの関心、Yandex Cryptsおよび関連機能からの「自宅」と「職場」の疑い、およびこのタスクのさまざまな分類方法を比較する実験など、推奨事項を作成するための新しいデータが追加されます。 たとえば、Yandexは既にMatrixnetチーム内で厳密に使用しているだけでなく、Yandexと外部の両方で人気を集めているCatBoostも使用しています。 同時に、もちろん、私たちは自分の開発だけでなく、人気のあるアルゴリズムの他の実装も比較することに興味があります。
さらに、投稿の冒頭で既に述べたように、アプリケーション自体がいつ、どこで、どのマシンを使用する必要があるかを理解できれば素晴らしいことです。 現在、ユーザーに適した注文パラメーターとアプリケーション設定を正確に推測できる履歴データを言うことは困難ですが、私たちはこの方向に取り組んでおり、アプリケーションをますます「スマート」にし、あなたに適応できるようにします。