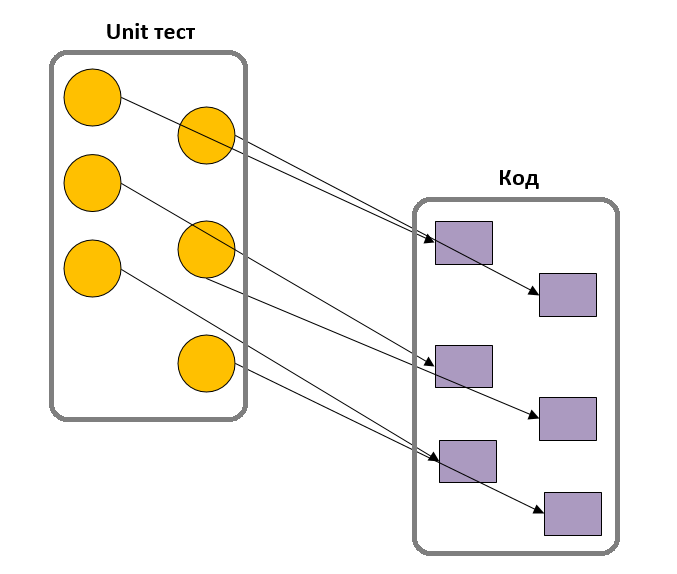
単体テストの解釈は異なりますが、この用語を組み合わせるものがいくつかあります。
しかし、ユニットテストの定義にはまだ議論の余地があるポイントがあります。 特に、ユニット(テストの単位)の下で何が考慮されますか? OOPアプローチでは、クラスをユニットと見なし、手続き型(または機能)アプローチでは、単一の関数をユニットと見なします。 一部の開発者は、いくつかのクラスを取り、それをユニットと見なすか、メソッドのセットをユニットと見なします。 しかし、実際にはこれは状況的なものであり、チームは自分のシステムでテストの単位を何にするかを自ら決定します。
単体テストの利点は明らかです。
- それらは低レベルであり、ソフトウェアのごく一部に焦点を当てています。
- 開発者自身が作成したテスト
- テストは非常に高速で実行され、1分間に数回テストを実行できます
- 開発中、すべてのテストを実行できるわけではなく、必要なテストのみを実行できます
したがって、単体テストを使用する場合、開発速度はそれほど低下しませんが、製品自体の品質は向上します。
単体テストの重要な違いは、選択するテストの種類:孤独(孤独)テストと社交性(社交性)テストです。 Jay Fieldsが最初に導入した用語。
社交的なテストは、テスト対象のユニットの一部である実際のメソッド(またはクラス)を使用するテストです。 たとえば、注文クラスから価格メソッドをテストしています。 priceメソッドは、クライアントクラスと製品クラスからメソッドを呼び出す必要があります。 このタイプのテストでは、これらのメソッドが呼び出され、これらのメソッドでエラーが発生するとテストエラーが発生します。 クライアントおよび製品クラスからのメソッドは、コラボレーターと呼ばれます。

孤独(孤独)テストは、doubleをパートナーとして使用するテスト( TestDouble )です。 テストの複製は、テストのみを目的として、実際のオブジェクトを置き換える場合の一般的な用語です。

テイクの適切な分類は、ジェラルド・メザロス(ジェラルド・メザロス)によって行われました。詳細については、 こちらを参照してください。
これらのテスト方法にはそれぞれ長所と短所があり、これら2つの方法の支持者の間で激しい議論があります。 孤独な(孤独な)テストの支持者は条件付きでモック主義者(モック-偽)と呼ばれ、社交的な(社交的な)テストの支持者は条件付きで古典主義者と呼ばれます ( ロシア語で類似物を見つけることができませんでした )。 Sociable(発信)テストのサポーターも、データベースなどの外部リソースにアクセスするために二重テストを使用することに注意してください。 これは、アクセスの速度に一部起因します。 ただし、重複を使用して外部リソースにアクセスすることは絶対的なルールではありません。それらへのアクセスが安定しており、十分に高速であれば、重複なしで実行できます。 いずれにせよ、開発者はdoubleを使用する方が適切かどうかを判断します。
Solitaryのテストテクニック(孤独)の長所の1つは、開発者が状態ではなくアプリケーションの動作に集中することです。 欠点は、偽物がパートナーメソッドに存在するエラーをマスクできることです。 したがって、重複テストを使用する場合、統合テストを実行する必要があります。 Sociable(通信)をテストする利点は、これが本質的に最初の統合テストであることですが、欠点は、1つのメソッドが失敗すると、このメソッドに関連するすべてのテストが失敗し、デバッグが困難になることです。
このアプローチまたはテストのアプローチの長所と短所については説明しません。これについては、ファウラーの記事Mocks Aren 's Stubsを参照してください。
単体テストの主な特性は、プログラマ自身が作成した少量と速度です。つまり、プログラミング中に頻繁に実行できることを意味します。
開発者は、コードの変更後にそれらを実行できます。 ただし、常にすべてのテストを実行する必要はありません。現在作業中のコードと対話するテストのみを実行するだけで十分です。
1990年代後半、Kent Beckは極端なプログラミングの一部としてテスト駆動開発(TDD)を開発しました。 これは、テストを記述して開発プロセスを管理するソフトウェアを構築するための手法です。 本質的に、3つの単純なルールを繰り返します。
- テストは最初に書かれます
- 次に、このテスト用のコードが作成されます。
- 新しいコードと古いコードをリファクタリングしてコード品質を改善する
目的の結果が得られるまで、プロセスは新たに開始されます。
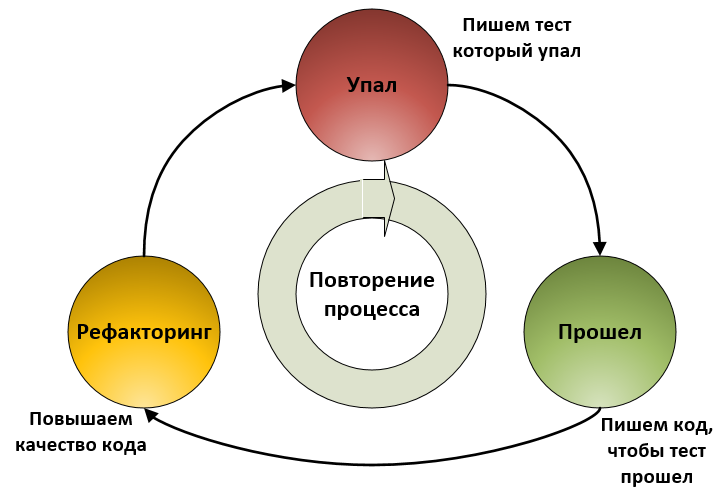
最初にテストを作成すると、次の2つの利点があります。
1.これは、自己テストコードを取得する方法です。
2.最初にテストについて考えると、コード自体のインターフェースについて考えるようになります。 インターフェイスとクラスの使用方法に焦点を当てることで、インターフェイスを実装から分離するのに役立ちます。
この方法論を使用する際の最大の間違いは、3番目のステップであるリファクタリングの怠慢です。 これにより、コードが「ダーティ」になります(ただし、少なくともテストが行われます)。
BDD(Behavior Driven Development)、または行動ベースの開発は、ユニットテストの進化の過程で登場し、2006年にDan Northによって開発されました。 著者自身によると、この方法論はTDDの学習に役立つはずです。 これはアジャイルプラクティスから生まれたものであり、アジャイルへの新参者にとってよりアクセスしやすく効果的なものにすることを目的としています。
時間が経つにつれて、BDDは、アジャイル分析と自動受け入れテストのより広い視野をカバーし始めました。
これにより、テスト自体の名前が動作(仕様)に変更されるようになり、オブジェクトの実行に集中できるようになりました。 したがって、開発者は自分用のドキュメントを作成し、テストの名前を文の形で記録し始めました。 彼らは、生成されたドキュメントが企業、開発者、テスターに利用可能になることを発見しました。
行動に基づいた開発は、モックスタイル(または単独テスト)のブランチの1つであると考えられています。 テストは主に複製を使用して構築されます。
その後、Given-When-Thenテストの記述スタイルが登場しました。または、彼らがそれを呼び出し始めたときに、システムの動作の仕様が登場しました。 このスタイルは、クリス・マットと共にダン・ノースによって開発されました。 アイデアは、テストスクリプトの記述を3つのセクションに分割することです。
- 動作の説明を開始する前の状態を指定します。 テストの前提条件と見なすことができます。
- いつ (いつ)-説明する動作。
- その後 (その後)-動作から予想される変更
例:
説明:ユーザーは株を販売しています。
シナリオ:入札が終了する前にユーザーが販売をリクエストする
与えられた:私は100 MSFT株と150 APPL株を持ち、取引終了までの時間を持っています。
いつ (いつ):MSFTの20株を売ることをお願いします
その後 (その後):80 MSFT株と150 APPL株が残っていなければならず、20株の売却申請を完了しなければなりません。
TDDおよびBDD方法論の出現からかなりの時間が経過したという事実にもかかわらず、多くの開発者は、アプリケーションの適切性について互いに議論しています。 コードの前にテストを書く必要はないと主張する人もいれば、コードの後にテストを書くことは無意味だと言う人もいます。 ただし、テストを作成する必要があるという点で双方が同意します。 プログラマーの観点からのBDD方法論は、その著者( BDD IS LIKE TDD IF ... )によると、TDDと違いはありません。 TDDと同じルールがすべて使用されます:テスト、コード、リファクタリング。 違いは、BDDがより多くの対象者を対象にしていることです。 仕様はプログラマーだけでなく、コードに精通していないがソフトウェア開発に携わっている人々にも利用可能になります。 したがって、チーム全体がテストの作成プロセスに関与します:アナリスト、テスター、マネージャー。
単体テストの明らかな利点の1つは、製品に発生するエラーの数を大幅に削減できることです。 これの中心にあるのは、開発者がコードとテストを一緒に書くことを考える文化です。
しかし、最大の利点は、製品のエラーを回避するだけでなく、システムに変更を加えることができるという自信です。 多くの場合、古いコードは恐ろしい画像であり、開発者はそれを変更することを恐れています。 1つの間違いを修正するだけでも危険です。 正しいエラーよりも多くのエラーを作成できます。 そのような場合、新しい機能の追加は非常に遅く、システムをリファクタリングすることも恐れているため、技術的な負債( TechnicalDebt )が増加し、悪いスパイラルに陥ります。
テストとは異なる状況。 ここでは、間違いを修正しても安全に行えることを人々は確信しています。間違いを犯した場合、エラーディテクタが機能し、すばやく回復して続行できるからです。 このセキュリティシステムを使用すると、コードを常に良好な状態に保つことができ、悪いスパイラルに陥ることがなくなります。
一連の自動テスト(ユニットだけでなく)を実行するプロセスは、エラー検出(自己テストシステム)として機能し、テストに合格し、コードに重大な欠陥が含まれていないことを確認します。 チームの誰かが誤ってミスをすると、検出器が作動します。 テストを頻繁に1日に数回実行すると、エラーが発生した直後に検出できるため、最新の変更を確認するだけで、エラーの検索が非常に容易になります。 動作するコード、およびその動作をサポートするテストなしでは、プログラムエピソードは完了しません。
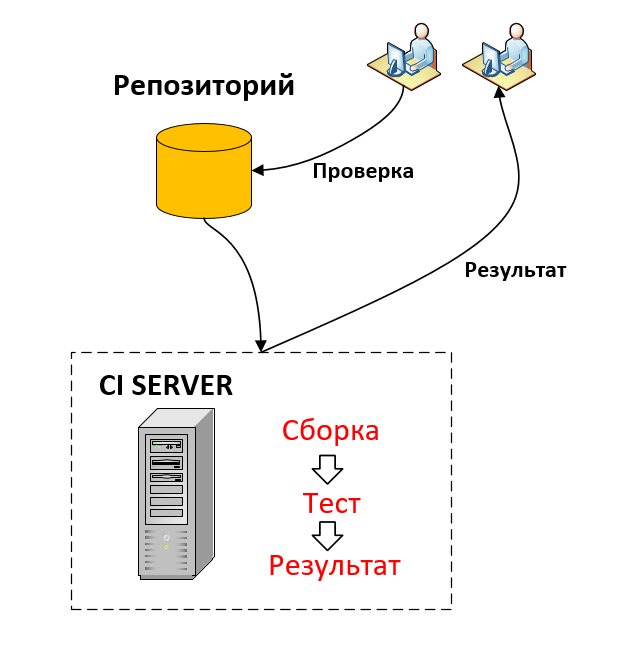
テスト対象のシステム自体は継続的インテグレーションと継続的デリバリの一部ですが、このトピックはすでにこの記事の範囲外です。
さまざまなテストを実施するチームの重要なアクションの1つは、製品のエラーに対応することです。 チームの通常の反応は、 最初にテストを記述してエラーを公開し、その後で修正を試みることです。 多くの場合、このテストの記述は一連のテストであり、エラーをエミュレートする単体テストを達成するまで、徐々に範囲を狭めていきます。 この手法により、エラーを修正した後も修正されたままになります。 位置は、エラーはコードの失敗だけでなく、保護のテストの失敗でもあるということです。
エラーまたは自動テストの検出器として、単体テストだけでなく、統合テスト、およびその他の自動テストも機能します。 ただし、ここでの単体テストは基本です。 それらの記述は簡単で、非常に高速です。
高レベルのテストは、2番目の防衛線です。 高レベルのテストでエラーが発生した場合、 これはコードのエラーだけではなく、単体テストの欠落または不正です。
ソースのリスト:
- マーティンファウラーユニットテスト
- マーティンファウラーテスト
- マーティンファウラーセルフテストコード
- マーティンファウラーテスト駆動開発
- James Shore The Agile Development of Art:Test-Driven Development
- 行動プログラミング(BDD)の概要
- マーティン・ファウラー