ニュース収集システムの不可欠な部分は、サイト(クローラー、クローラー、「クモ」)をクロールするロボットです。 その機能には、これらのサイトでの変更の追跡や、システムのデータベース(DB)への新しいデータの入力が含まれます。
完全に既製の適切なソリューションはありませんでした。これに関連して、既存のプロジェクトから次の基準を満たすものを選択する必要がありました。
- セットアップの容易さ;
- 複数のサイトをクロールするように構成する機能。
- 低リソース要件。
- 追加のインフラストラクチャの不足(作業のコーディネーター、「クモ」のデータベース、追加のサービスなど)。
選択されたソリューションは、サイトをクロールするためのかなり人気のあるロボットcrawler4jでした 。 もちろん、受信したコンテンツを分析するために多くのライブラリを引き出しますが、これはその作業の速度や消費されるリソースには影響しません。 Berkley DBをリンクデータベースとして使用し、分析された各サイトのカスタムディレクトリに作成されます。
カスタマイズの方法として、開発者は行動パターン「 戦略 」(分析するサイトのリンクおよびセクションをクライアントが受け入れるべきかを決定する権利)と「 オブザーバー 」(サイトをクロールするとき、ページ情報(アドレス、形式、コンテンツ、メタデータ) )クライアントに転送されます。クライアントは、クライアントへの対処方法を自分で自由に決定できます)。
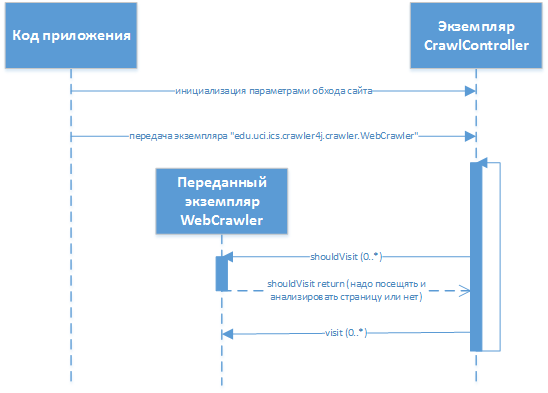
実際、開発者にとって、「スパイダー」はプロジェクトに接続し、動作をカスタマイズするためのインターフェースの必要な実装が転送されるライブラリのように見えます。 開発者は、ライブラリクラス
«edu.uci.ics.crawler4j.crawler.WebCrawler»
(メソッド
«shouldVisit»
および
«visit»
)を展開し、その後ライブラリに転送します。 作業プロセスにおける相互作用は次のようになります。
、
edu.uci.ics.crawler4j.crawler.CrawlController
は、対話の実行に使用されるライブラリのメインクラスです(セットアップのバイパス、制御コードの転送、ステータス情報の取得、開始/停止)。
以前はサイト解析の実装に対処する必要はありませんでした。したがって、すぐに一連の問題に直面する必要があり、それらを排除する過程で、実装と取得したクロールデータの処理方法についていくつかの決定を行う必要がありました。
- 受信したコンテンツと「戦略」テンプレートの実装を分析するためのコードは、「スパイダー」自体のバージョンとは別のプロジェクトのバージョンで表示されます。
- 受信したコンテンツとリンク分析を分析するための実際のコードはgroovyに実装されます。これにより、スパイダーを再起動せずに作業のロジックを変更できます(
«org.codehaus.groovy.control.CompilerConfiguration»
オプション«recompileGroovySource»
«org.codehaus.groovy.control.CompilerConfiguration»
)(対応する実装コードは«edu.uci.ics.crawler4j.crawler.WebCrawler»
には、実際には、送信されたデータを処理するgroovyインタープリターのみが含まれています。
- 「スパイダー」で検出された各ページからのデータ抽出は完了していません-コメント、「ヘッダー」および「フッター」は削除されます。 各ページのボリュームの50%を費やしても意味がないという事実-それ以外はすべて、後の分析のためにMongoDBデータベースに保存されます(これにより、サイトを再クロールせずにページ分析を再開できます)。
- 各ニュース項目のキーフィールド(「日付」、「見出し」、「件名」、「著者」など)は、MongoDBのデータベースから既に抽出されていますが、完全性が監視されています-ある程度のエラーに達すると、通知が送信されますスクリプトを調整する必要性(サイトの構造の変更の確実な兆候)。
ライブラリコードの変更
私にとっての主な問題は、サイトのページが変わらないというcralwer4j開発者のアーキテクチャ上のソリューションでした。 彼の作品の論理は次のとおりです。
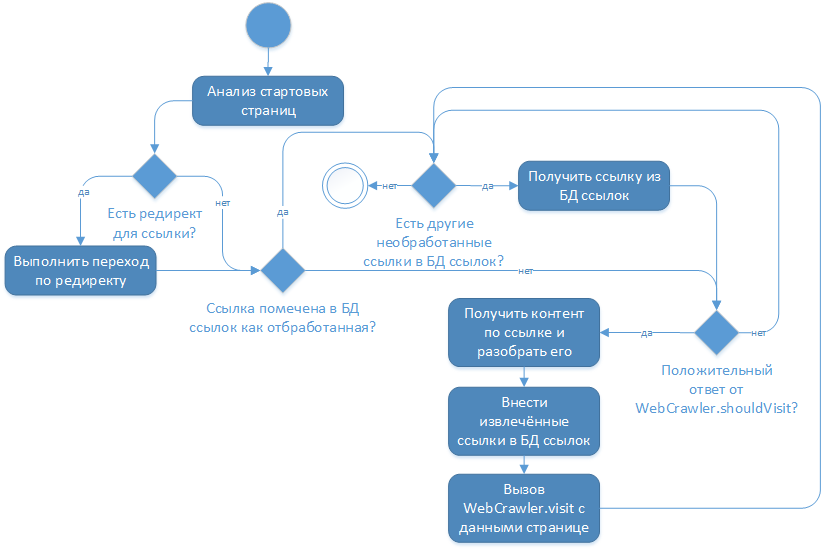
ライブラリのソースコードを検討した結果、この設定はどの設定でも変更できず、メインプロジェクトの分岐を作成することになりました。 示されたブランチで、「抽出されたリンクをリンクデータベースに追加する」アクションの前に、リンクデータベースへのリンクを作成する必要があるかどうかの追加チェックが行われます。最新ニュースへのリンクを提供します。
ただし、このような改良には、ライブラリを使用した作業の変更が必要であり、主なメソッドの起動は定期的に実行する必要があり、 クォーツライブラリを使用して簡単に実装できました。 開始ページに新しいニュースがない場合、メソッドは数秒で作業を完了しました(開始ページを受信し、それらを分析し、既に渡されたリンクを受信した後)、またはデータベースに最新のニュースを書き込みます。
ご清聴ありがとうございました!