
負荷平均は、業界で重要な指標です。 多くの企業は、これと他の多くのメトリックに基づいてクラウドインスタンスを自動的にスケーリングする何百万ドルも費やしています。 しかし、Linuxでは、いくつかの謎に包まれています。 Linuxの平均負荷を追跡することは、中断できないスリープ状態です。 なんで? 私は説明に会ったことがありません。 この記事では、この謎を解決し、それらを解釈しようとしているすべての人の平均負荷値に関するリファレンスを作成します。
Linuxの負荷平均は、実行可能スレッドと待機スレッドの平均数として実行可能スレッド(タスク)の必要性を示す「システム負荷平均」です。 これは、システムによって現在処理されているものを超える可能性のある負荷の尺度です。 ほとんどのツールは、3つの平均値を表示します:1、5、および15分間:
$ uptime 16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46 top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37 $ cat /proc/loadavg 25.72 23.19 23.35 42/3411 43603
いくつかの解釈:
- 値が0.0の場合、システムはアイドル状態です。
- 1分間の平均値が5または15よりも高い場合、負荷は増加します。
- 1分間の平均値が5または15の平均値よりも低い場合、負荷は軽減されます。
- 負荷値がプロセッサの数よりも大きい場合、パフォーマンスの問題が発生する可能性があります(状況に応じて)。
この3つの値のセットから、負荷のダイナミクスを評価できます。これは確かに便利です。 また、これらのメトリックは、たとえばクラウドサービスを自動的にスケーリングする場合など、リソース要件の1つの評価が必要な場合に役立ちます。 しかし、それらをより詳細に処理するには、他のメトリックに目を向ける必要があります。 23-25の範囲自体の値は何も意味しませんが、プロセッサの数がわかっていて、プロセッサに関連する負荷について話している場合には意味があります。
平均負荷値をデバッグする代わりに、通常は他のメトリックに切り替えます。 これについては、記事の終わり近くの「その他の適切な指標」の章で説明します。
物語
最初は、平均負荷値は、プロセッサリソースの必要性、つまり実行中のプロセスと完了を待機しているプロセスの数のみを示します。 RFC 546には、1973年8月の「TENEX Load Averages」と呼ばれる優れた説明があります 。
[1] TENEXの平均負荷は、CPUリソース要件の尺度です。 これは、一定期間の実行可能プロセスの平均数です。 たとえば、1時間あたりの平均負荷が10の場合、これは(ユニプロセッサシステムの場合)この時間中の任意の時点で、1つのプロセスが実行され、9つの実行準備ができている(つまり、入出力がブロックされていない)ことを意味しますプロセッサは無料です。
ietf.orgバージョンでは、1973年7月に手書きのグラフのPDFスキャンが行われ、このメトリックが何十年も使用されてきたことを実証しています。
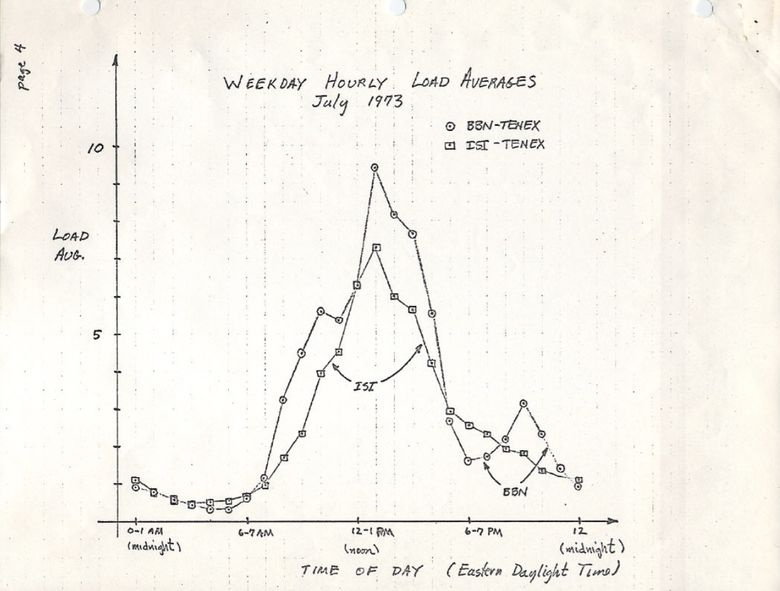
ソース: https://tools.ietf.org/html/rfc546
今日、あなたはネット上で古いオペレーティングシステムのソースコードを見つけることができます。 DECマクロアセンブラ上のTENEX (1970年代初頭)SCHED.MACのスニペットを次に示します。
NRJAVS==3 ;NUMBER OF LOAD AVERAGES WE MAINTAIN GS RJAV,NRJAVS ;EXPONENTIAL AVERAGES OF NUMBER OF ACTIVE PROCESSES [...] ;UPDATE RUNNABLE JOB AVERAGES DORJAV: MOVEI 2,^D5000 MOVEM 2,RJATIM ;SET TIME OF NEXT UPDATE MOVE 4,RJTSUM ;CURRENT INTEGRAL OF NBPROC+NGPROC SUBM 4,RJAVS1 ;DIFFERENCE FROM LAST UPDATE EXCH 4,RJAVS1 FSC 4,233 ;FLOAT IT FDVR 4,[5000.0] ;AVERAGE OVER LAST 5000 MS [...] ;TABLE OF EXP(-T/C) FOR T = 5 SEC. EXPFF: EXP 0.920043902 ;C = 1 MIN EXP 0.983471344 ;C = 5 MIN EXP 0.994459811 ;C = 15 MIN
そして、ここに現代のLinux (include / linux / sched / loadavg.hから)の抜粋があります:
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */ #define EXP_5 2014 /* 1/exp(5sec/5min) */ #define EXP_15 2037 /* 1/exp(5sec/15min) */
Linuxでは、1、5、および15分間の定数もハードコードされています。
Multicsを含む古いシステムでも同様のメトリックが見つかりました。これには、指数スケジューリングのキュー平均が含まれていました。
3つの数字
3つの数値は、1、5、および15分間の平均負荷値です。 しかし、それらは実際には平均ではなく、1、5、15分間ではありません。 上記のコードからわかるように、1、5、および15は、5秒平均の指数関数的に減衰する移動合計を計算する方程式で使用される定数です。 したがって、1、5、および15分間の平均負荷は、指定された期間の負荷をまったく反映していません。
アイドルシステムを使用し、プロセッサに関連付けられたシングルスレッドの負荷(サイクル内の1つのスレッド)を適用した場合、60秒後の1分間の平均負荷値はどうなりますか? それが平均的なものであれば、1.0になります。 実験グラフは次のとおりです。
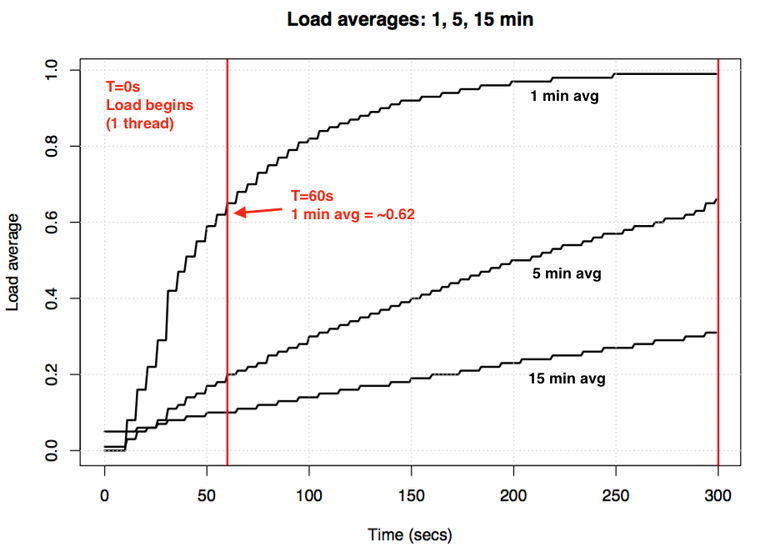
負荷の平均値の指数関数的減衰に関する実験の視覚化。
いわゆる「1分間の平均」は、約1分間で約0.62に達します。 Neil Gunther博士は、この実験およびその他の実験についてHow It Worksの記事で詳細に説明しており、 loadavg.cに関するLinux関連のコメントも多数あります。
Linuxの継続的なタスク
Linuxが最初に平均負荷値を導入したとき、それらは他のOSと同様に、プロセッサリソースの必要性のみを反映していました。 しかし、後で変更が加えられ、実行されたタスクだけでなく、中断されていない状態(TASK_UNINTERRUPTIBLEまたはnr_uninterruptible)のタスクも含まれました。 この状態は、ディスクI / Oによってブロックされたタスクや一部のロックなど、信号の中断を回避したいコードブランチによって使用されます。 この状態はすでに発生している可能性がありますps
およびtop
出力に「D」状態として表示されます。 ps(1)ページでは、「uninterruptible sleep(通常IO)」と呼ばれます。
非破壊的な状態が導入されるということは、Linuxでは、プロセッサリソースだけでなく、ディスク(またはNFS)のI / O負荷のために平均負荷が増加する可能性があることを意味します。 他のオペレーティングシステムとその平均プロセッサ負荷に精通しているすべての人にとって、最初はこの状態を含めることは非常に混乱します。
なんで? Linuxでこれが行われたのはなぜですか?
平均負荷に関する無数の記事があり、その多くはLinuxでnr_uninterruptibleに言及しています。 しかし、なぜこの条件を考慮し始めたのか、単一の説明、または少なくとも重大な仮定はありませんでした。 個人的には、プロセッサだけでなく、より一般的なリソース要件を反映することをお勧めします。
Linuxの古代のパッチを見つける
Linuxで何かが変更されている理由を理解するのは簡単です。目的のファイルのgitコミットの履歴を見て、変更の説明を読んでください。 loadavg.cの履歴を調べましたが、不変の状態を追加する変更は、以前のファイルのコードを含むファイルよりも前の日付です。 別のファイルをチェックしましたが、機能しませんでした。コードが異なるファイルに「ジャンプ」しました。 幸運を祈って、4 GBのテキストを含むLinux Githubリポジトリ全体でgit log -p
をzamumpitし、最後から読み始め、このコードが最初に現れた場所を探しました。 それも私を助けませんでした。 リポジトリの最も古い変更は、LinusがLinux 2.6.12-rc2をインポートした2005年にさかのぼり、必要な変更はさらに早く行われました。
古いLinuxリポジトリ( 1および2 )がありますが、この変更の説明もありません。 少なくともその実装の日付を見つけようとして、 kernel.orgのアーカイブを調べたところ、0.99.15にあったことがわかりましたが、0.99.13にはありませんでした。 ただし、バージョン0.99.14が欠落していました。 私はそれを見つけて、1993年11月にLinux 0.99.14に目的の変更が登場することを確認しました。このリリースの説明が役立つことを期待していましたが、 ここでは説明が見つかりませんでした。
「最新の公式リリース(p13)の変更は、リストするには多すぎる(または思い出すことさえできません)...」-Linus
彼は、負荷の平均値に関係のない主な変更点のみに言及しました。
日付までに、私はカーネルメーリングリストのアーカイブと特定のパッチを見つけることができましたが、古い手紙は1995年6月に日付が付けられました。
「メールアーカイブをより効率的にスケーリングできるシステムで作業しているときに、誤って現在のアーカイブを破壊しました(ah)。」
私は気の毒に感じ始めました。 幸いなことに、サーバーのバックアップから取得した古いlinux-develメーリングリストアーカイブを発見することができました。これは多くの場合、ダイジェストアーカイブとして保存されています。 私は、98,000以上の文字を含む6,000以上のダイジェストを調べましたが、そのうち30,000は1993年のものです。 しかし、何も見つかりませんでした。 パッチの元の説明は永久に失われたようで、「なぜ」という質問には答えられません。
連続性の起源
しかし、1993年のアーカイブされたメールボックスファイルのoldlinux.org Webサイトで突然、 次のことがわかりました。
From: Matthias Urlichs <urlichs@smurf.sub.org> Subject: Load average broken ? Date: Fri, 29 Oct 1993 11:37:23 +0200 "" . . , , "", , /, . , , … , . , , . ;-) --- kernel/sched.c.orig Fri Oct 29 10:31:11 1993 +++ kernel/sched.c Fri Oct 29 10:32:51 1993 @@ -414,7 +414,9 @@ unsigned long nr = 0; for(p = &LAST_TASK; p > &FIRST_TASK; --p) - if (*p && (*p)->state == TASK_RUNNING) + if (*p && ((*p)->state == TASK_RUNNING) || + (*p)->state == TASK_UNINTERRUPTIBLE) || + (*p)->state == TASK_SWAPPING)) nr += FIXED_1; return nr; } -- Matthias Urlichs \ XLink-POP N|rnberg | EMail: urlichs@smurf.sub.org Schleiermacherstra_e 12 \ Unix+Linux+Mac | Phone: ...please use email. 90491 N|rnberg (Germany) \ Consulting+Networking+Programming+etc'ing 42
この変化を引き起こした24年前の考えを読むのは信じられないほど素晴らしかった。 この手紙は、メトリックの変更がプロセッサだけでなく他のシステムリソースのニーズを考慮に入れるべきであることを確認しました。 Linuxは「平均CPU負荷」から「平均システム負荷」のようなものに移行しました。
スワップが遅いディスクを使用した前述の例には意味があります。システムのパフォーマンスを低下させると、リソース(実行可能プロセスおよびキューイングプロセス)の需要が増加します。 ただし、平均負荷値は、プロセッサの実行状態(CPUの実行状態)のみを考慮し、スワッピング状態は考慮しないため、減少しました。 マティアスはそれを非論理的であると正しく考え、したがって修正した。
今日の継続性
しかし、Linuxの平均負荷はディスクI / Oでは説明できないほど高くならない場合がありますか? はい、これは本当です。ただし、これは1993年には存在しなかったTASK_UNINTERRUPTIBLEを使用した新しいコードブランチの結果だと思います。 Linux 0.99.14には、TASK_UNINTERRUPTIBLEまたはTASK_SWAPPINGを直接使用するコードの分岐が13個ありました(スワップ状態は後にLinuxから削除されました)。 現在、Linux 4.12には、TASK_UNINTERRUPTIBLEを使用するブランチが約400あり、ロックプリミティブも含まれています。 これらの分岐の1つは、負荷の平均値で考慮されるべきではない可能性があります。 値が高すぎることを再度確認したときにこれが当てはまるかどうかを確認し、修正できるかどうかを確認します。
私はマティアスに手紙を書き、24年後に彼が平均負荷の変化についてどう思うかを尋ねました。 彼は1時間後に答えた:
「「平均負荷」の本質は、人間の観点からシステムの使用を数値的に評価することです。 TASK_UNINTERRUPTIBLEは(意味?)プロセスがディスクからの読み取りのようなものを期待することを意味し、これはシステム負荷に影響します。 ディスク依存システムは非常に遅くなる可能性がありますが、平均TASK_RUNNINGは約0.1であり、これはまったく役に立ちません。
そのため、少なくともTASK_UNINTERRUPTIBLEの目的については、Matthiasはこのステップの正確性をまだ確信しています。
しかし今日、TASK_UNINTERRUPTIBLEはより多くのものに対応しています。 プロセッサとディスクのみのリソース要件を反映するように、平均負荷値を変更する必要がありますか? Peter Zijstraはすでに良いアイデアを送ってくれました。ディスクI / Oにより密接に対応しているため、平均負荷でtask_struct->in_iowait
ではなくtask_struct->in_iowait
検討してください。 しかし、これは別の質問を提起します:私たちは本当に何が欲しいのでしょうか? システムリソースの需要を実行スレッドの形で測定したいですか、それとも物理リソースが必要ですか? 最初の場合、これらのスレッドはシステムリソースを消費するため、中断のないロックを検討する必要があります。 アイドル状態ではありません。 そのため、Linuxの平均的な負荷は、おそらく既に正常に機能しています。
中断のないコードブランチをよりよく理解するために、それらを実際に測定したいと思います。 その後、さまざまな例を評価し、費やした時間を測定し、これが理にかなっているかどうかを理解できます。
継続的なタスクを測定する
これは、実稼働サーバーから60秒に渡ってカーネルスタックのみを表示するオフCPU(オフCPU) フレームチャートです。ここでは、TASK_UNINTERRUPTIBLE( SVG )状態のみを残しています。
グラフは、中断のないコードブランチの多くの例を示しています。

フレームグラフに慣れていない場合:ブロックをクリックして 、ブロックから列として表示されるスタック全体を調べます。 X軸のサイズは、プロセッサ外でのブロックに費やされた時間に比例し、ソート順(左から右)は重要ではありません。 プロセッサ外のスタックの場合、青色が選択され(プロセッサ内のスタックの場合は暖色を使用します)、彩度の変化は異なるフレームを示します。
bccの offcputimeツールを使用してグラフを生成しました(動作させるにはLinux 4.8+ eBPF機能が必要です)。また、 フレームグラフを作成するためのアプリケーションも作成しました。
# ./bcc/tools/offcputime.py -K --state 2 -f 60 > out.stacks # awk '{ print $1, $2 / 1000 }' out.stacks | ./FlameGraph/flamegraph.pl --color=io --countname=ms > out.offcpu.svgb>
出力をマイクロ秒からミリ秒に変更するには、awkを使用します。 Offcputime "--state 2"はTASK_UNINTERRUPTIBLE(sched.hを参照)に対応しています。これは、この記事のために追加したオプションです。 これは、Joseph Bachikがカーネルスコープツールで最初に行ったもので、bccおよびフレームグラフィックも使用します。 私の例では、カーネルスタックのみを示していますが、offcputime.pyはカスタムスタックもサポートしています。
上のグラフに関して:中断されていないスリープ状態で費やされた60秒のうち926ミリ秒しか表示されません。 これにより、平均負荷値はわずか0.015になります。 これはcgroupブランチによって費やされた時間ですが、このサーバーでは多くのディスクI / O操作が実行されません。
そして、これは10秒( SVG )のみをカバーするより興味深いチャートです:
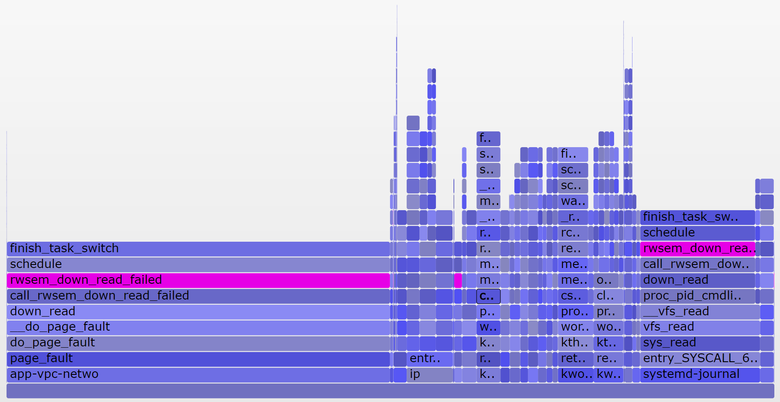
右側の幅の広いタワーは、 systemd-journal proc_pid_cmdline_read()
(read / proc / PID / cmdline)のロックされたsystemd-journal proc_pid_cmdline_read()
し、平均負荷に0.07を追加します。 左側には幅の広いページフォールトタワーがあり、 rwsem_down_read_failed()
でrwsem_down_read_failed()
平均負荷に0.23を追加します)。 ツールの検索機能を使用して、これらの関数にマゼンタの色を付けました。 rwsem_down_read_failed()
コードスニペットをrwsem_down_read_failed()
ます。
/* wait to be given the lock */ while (true) { set_task_state(tsk, TASK_UNINTERRUPTIBLE); if (!waiter.task) break; schedule(); }
これは、TASK_UNINTERRUPTIBLEを使用したロック取得コードです。 Linuxは、セマフォのmutex取得関数(例: mutex_lock()
およびmutex_lock_interruptible()
、 down()
およびdown_interruptible()
などmutex_lock_interruptible()
中断バージョンと中断なしバージョンを持っています。 中断されたバージョンでは、シグナルのタスクを中断してから、ウェイクアップしてロックを受け取る前に処理を続行できます。 中断のないロックでのスリープに費やす時間は、通常、平均負荷にほとんど追加されません。この場合、増加は0.3に達します。 さらに多い場合は、ロック中の競合を減らすことができるかどうかを調べる価値があります(たとえば、 systemd-journal
とproc_pid_cmdline_read()
掘り始めます!)パフォーマンスを改善し、平均負荷を減らすために。
これらのコードの分岐を平均負荷で考慮することは理にかなっていますか? はいと言うでしょう。 これらのスレッドは実行中に停止され、ブロックされます。 アイドル状態ではありません。 ハードウェアではなく、少なくともソフトウェアが必要です。
Linuxの負荷平均の分析
平均負荷を完全にコンポーネントに分解できますか? 次に例を示します。アイドル状態の8プロセッサシステムでtarを実行して、キャッシュされていないファイルをいくつかアーカイブしました。 アプリケーションは数分を費やしましたが、そのほとんどはディスク読み取り操作によってブロックされていました。 以下に、3つの異なるターミナルウィンドウの統計を示します。
terma$ pidstat -p `pgrep -x tar` 60 Linux 4.9.0-rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU) 10:15:51 PM UID PID %usr %system %guest %CPU CPU Command 10:16:51 PM 0 18468 2.85 29.77 0.00 32.62 3 tar termb$ iostat -x 60 [...] avg-cpu: %user %nice %system %iowait %steal %idle 0.54 0.00 4.03 8.24 0.09 87.10 Device: rrqm/s wrqm/sr/sw/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvdap1 0.00 0.05 30.83 0.18 638.33 0.93 41.22 0.06 1.84 1.83 3.64 0.39 1.21 xvdb 958.18 1333.83 2045.30 499.38 60965.27 63721.67 98.00 3.97 1.56 0.31 6.67 0.24 60.47 xvdc 957.63 1333.78 2054.55 499.38 61018.87 63722.13 97.69 4.21 1.65 0.33 7.08 0.24 61.65 md0 0.00 0.00 4383.73 1991.63 121984.13 127443.80 78.25 0.00 0.00 0.00 0.00 0.00 0.00 termc$ uptime 22:15:50 up 154 days, 23:20, 5 users, load average: 1.25, 1.19, 1.05 [...] termc$ uptime 22:17:14 up 154 days, 23:21, 5 users, load average: 1.19, 1.17, 1.06
また、中断のない状態( SVG )専用のプロセッサ外フレームグラフも作成しました。
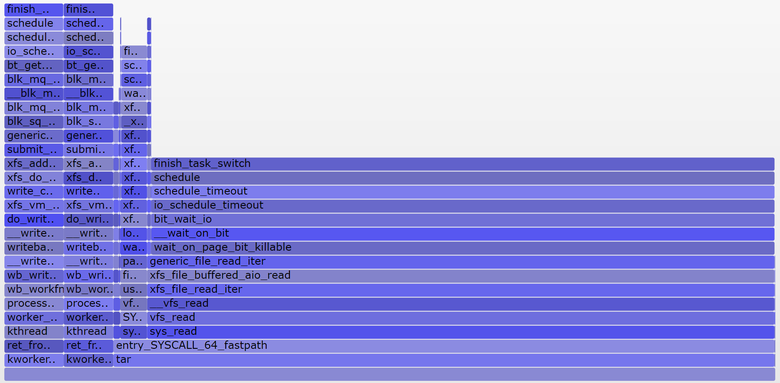
直前の平均負荷は1.19でした。 コンポーネントに分けましょう。
- 0.33-CPU時間tar(pidstat)
- 0.67-おそらくディスクからの連続読み取り(グラフ0.69では、彼にとってデータ収集は少し遅れて開始され、わずかに異なる時間範囲をカバーしていると思います)
- 0.04-他のプロセッサコンシューマ(mpstatユーザー+システム、pidstatからのtarによるCPU消費を差し引いたもの)
- 0.11-カーネルワーカーの連続的なディスク入力/出力、ディスクへの排出(グラフでは左側に2つの塔があります)
合計で1.15が取得されます。 別の0.04が欠落しています。 一部には、これには間隔シフトの丸め誤差と測定誤差が含まれる場合がありますが、これは主に、平均負荷が指数関数的に減衰する移動合計であり、使用される他のメトリック(pidstat、iostat)が通常の平均であるという事実による可能性があります 1.19までは、1分間の平均負荷は1.25でした。これは、上記のいずれかが依然としてメトリックを引き上げていることを意味します。 いくら 私の初期のチャートによると、1分の時点で、メトリックの62%は現在の分にあり、残りは前の分にありました。 0.62 x 1.15 + 0.38 x 1.25 = 1.18です。 1.19に十分近い。
このシステムでは、1つのスレッド(tar)が作業を実行し、さらにカーネルワーカースレッドによってもう少し時間が費やされるため、Linuxの1.19での平均負荷に関するレポートは妥当に見えます。 「平均プロセッサ負荷」を測定すると、0.37(mpstatから計算された値)のみが表示されます。これはプロセッサリソースについてのみ正しいものですが、複数のストリームを処理する必要があるという事実は考慮しません。
この例で、これらの数値が天井から取られたものではなく(プロセッサ+中断なし)、自分でコンポーネントに分解できることを示していただければ幸いです。
Linuxの負荷平均の意味
私は平均負荷値がプロセッサのみに関連するオペレーティングシステムで育ったため、Linuxバージョンは常に私を悩ませました。 おそらく実際の問題は、「平均負荷」という用語が「I / O」と同じくらいあいまいであることです。 どのような入力/出力ですか? ドライブ? ファイルシステム? ネットワーク?..同様に、何の平均負荷? CPU? システム? :
- Linux — ( ) « » , . (, , ). , , . : .
- — « » . , . : ( ).
: « » , ( ).
, - Linux , , : , , . .
«» «» ?

: , , . .
- , 1,0, . , ( ) . 1,5 , , .
, 11 16 ( 5,5 8). , . : / 2.
Linux: , , . : , 20, 40, , , .
Linux (, , ), , . , . , :
- (per-CPU utilization): ,
mpstat -P ALL 1
. - (per-process CPU utilization): ,
top, pidstat 1
. - () (per-thread run queue (scheduler) latency): , /proc/PID/schedstats, delaystats, perf sched
- (CPU run queue latency): ,
/proc/schedstat
,perf sched
, runqlat bcc . - (CPU run queue length): , vmstat 1 'r',
runqlen bcc
.
— , — (saturation metrics). , — . — ( ): , / , . . , . , .
Linux 4.6 schedstats
( sysctl kernel.sched_schedstats
) , . (delay accounting) cpustat , htop , . , , , ( ) /proc/sched_debug:
$ awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug task PID tree-key switches prio wait-time sum-exec sum-sleep systemd 1 5028.684564 306666 120 43.133899 48840.448980 2106893.162610 0 0 /init.scope ksoftirqd/0 3 99071232057.573051 1109494 120 5.682347 21846.967164 2096704.183312 0 0 / kworker/0:0H 5 99062732253.878471 9 100 0.014976 0.037737 0.000000 0 0 / migration/0 9 0.000000 1995690 0 0.000000 25020.580993 0.000000 0 0 / lru-add-drain 10 28.548203 2 100 0.000000 0.002620 0.000000 0 0 / watchdog/0 11 0.000000 3368570 0 0.000000 23989.957382 0.000000 0 0 / cpuhp/0 12 1216.569504 6 120 0.000000 0.010958 0.000000 0 0 / xenbus 58 72026342.961752 343 120 0.000000 1.471102 0.000000 0 0 / khungtaskd 59 99071124375.968195 111514 120 0.048912 5708.875023 2054143.190593 0 0 / [...] dockerd 16014 247832.821522 2020884 120 95.016057 131987.990617 2298828.078531 0 0 /system.slice/docker.service dockerd 16015 106611.777737 2961407 120 0.000000 160704.014444 0.000000 0 0 /system.slice/docker.service dockerd 16024 101.600644 16 120 0.000000 0.915798 0.000000 0 0 /system.slice/ [...]
, , . . , . ( ), ( ), . , .
, , — . , , , , . , .
おわりに
1993 Linux- , « » « ». , , . ( , ). , 1, 5 15 . , .
Linux , . ( , ), , .
, Linux 1993- — , — . bcc/eBPF Linux- , -. , , . , .
kernel/sched/loadavg.c Linux:
, . , . , tickless-.
参照資料
- Saltzer, J., and J. Gintell. “ The Instrumentation of Multics ,” CACM, August 1970 ( ).
- system_performance_graph Multics ( ).
- TENEX ( SCHED.MAC).
- RFC 546 "TENEX Load Averages for July 1973" ( ).
- Bobrow, D., et al. “TENEX: A Paged Time Sharing System for the PDP-10,” Communications of the ACM, March 1972 ( ).
- Gunther, N. "UNIX Load Average Part 1: How It Works" PDF ( ).
- Linux 0.99 patchlevel 14 .
- oldlinux.org ( alan-old-funet-lists/kernel.1993.gz, linux-, ).
- Linux kernel/sched.c : 0.99.13 , 0.99.14 .
- Linux 0.99 kernel.org .
- Linux: loadavg.c , loadavg.h
- bcc , offcputime , TASK_UNINTERRUPTIBLE.
- - , .