
Intelは7月12日に、Skylake-SPというコードネームのサーバープロセッサの新しいラインを発表しました。 行名のSPという文字は、スケーラブルプロセッサ(ロシア語では「スケーラブルプロセッサ」)の略語です。 この名前は偶然ではありません。Intelは多くの興味深い革新を実装し、 あるレビューで述べたように、「ほぼ全員を満足させようとしました」。
SPプロセッサは、「 10年のプラットフォーム 」と呼ばれるPurleyサーバープラットフォームの一部です。
データセンターでは、新しいプロセッサをベースにしたサーバーをすでに注文可能です 。
Intel Skylake-SPにはどのような革新が実装されていますか? これらのプロセッサの仕様は何ですか? 以前のモデルと比較した場合の利点は何ですか? このすべての詳細については、この記事で説明します。
新しいプロセッサ-新しい名前
Xeonプロセッサの以前のラインは、Exvxなどの名前を受け取りました:E3v3、E3v5など。 SPラインは異なる命名スキームを使用します。すべてのプロセッサは、コードネームがブロンズ、シルバー、ゴールド、プラチナの4つのシリーズに分けられます。 これらのシリーズはすべて、コアの数と一連のテクノロジーが異なります。
ブロンズは最もシンプルなプロセッサです。最大8コアを搭載でき、ハイパースレッディングをサポートしていません。 プラチナは、その名前が示すように、高負荷の下で動作するように設計されており、最大数(最大28)のコアを備えています。
一部のモデルの名前には新しいインデックスがあります。 したがって、文字Fは統合されたOmni-Pathコントローラーの存在を示し、M-より多くのメモリ(ソケットあたり最大1.5 TB)をサポートし、T-標準のNEBS(ネットワーク機器構築システム)をサポートします。 名前にTインデックスが付いているプロセッサは、高温負荷に耐え、他のモデルに比べて寿命がはるかに長くなります。
技術仕様
この構成では、Intel Xeon Silver 4114およびIntel Xeon Gold 6140を選択しました。それらの主な技術的特徴を以下の表に示します。
| 特徴 | Intel Xeon Silver 4114 | Intel Xeon Gold 6140 |
|---|---|---|
| 技術プロセス | 14 nm | 14 nm |
| コアの数 | 10 | 18 |
| スレッド数 | 20 | 36 |
| 基本周波数 | 2.20 GHz | 2.30 GHz |
| 最大ターボ周波数 | 3.00 GHz | 3.70 GHz |
| L3キャッシュ | 13.75 MB | 24.75 MB |
| UPIラインの数 | 2 | 3 |
| TDP(熱設計力) | 85ワット | 140ワット |
主な革新
Skylake-SPプロセッサに実装されている最も重要な技術革新のリストは次のとおりです。
- AVX-512命令セットのおかげで、整数および浮動小数点計算のパフォーマンスが大幅に改善されました。
- 6チャンネルメモリコントローラーの存在(前の行では4チャンネルでした)。
- UPI(Ultra Path Interconnect)テクノロジーのおかげで、コア間の通信が加速されました。
- PCIライン数の増加(最大48);
- 変更されたトポロジ:リングバスはメッシュアーキテクチャに置き換えられました。
マイクロアーキテクチャ
SPラインのプロセッサーの基本的なコア構造は、以前のモデルのSkylakeとまったく同じままでした。 ただし、いくつかの違いと改善点があります。 L2キャッシュのサイズが増加しました:1 MBです。 L3キャッシュのサイズは、コアあたり1.375 MBです。 L2キャッシュはRAMから直接読み込まれ、次に未使用のラインがL3にプッシュされます。 複数のコアに共通のデータはL3に保存されます。
もう1つのポイントに注目しましょう。L3キャッシュのボリュームはコアの数に依存しません。 24.75 MBキャッシュには、8コアおよび12コア、さらには18コア(上記の表を参照)モデルの両方が装備されています。
多くのレビューで指摘されているように(たとえば、 こちらを参照 )、L2キャッシュの操作に重点が置かれています。 SkylakeプロセッサにはeDRAM内蔵メモリはありません。
新しいトポロジー
Intel Skylake-SPプロセッサの重要な革新は、ほぼ10年間コア間の通信に使用されてきたプロセッサ内リングバスの拒否です。
リングバスは、2009年に8コアのNehalem-EXプロセッサで初めて登場しました。 彼女は非常に高速で働いていました(最大3 GHz)。 L3キャッシュの待ち時間は最小限でした。 カーネルがキャッシュフラグメントでデータを検出した場合、必要な追加ループは1つだけです。 別のフラグメントからキャッシュラインを取得するには、最大12サイクル(平均6サイクル)かかりました。
その後、リングバス技術は多くの変更と改善を受けました。 そのため、2012年に導入されたIvy Bridgeプロセッサでは、3列のコアが2つのリングバスと組み合わされました。 データを2方向(時計回りと反時計回り)に移動したため、最短ルートでの配信を保証し、遅延時間を短縮できました。 データがリング構造に入った後、以前のデータとの混乱を避けるために、ルートを調整する必要がありました。
Intel Xeon E5v3プロセッサー (2014)では、すべてがはるかに複雑になりました:4列のコア、2つの互いに独立したリングバス、バッファースイッチ(詳細については、提供されているリンクに関する記事を参照してください)。
プロセッサに最大8コアが搭載されると、リングバステクノロジーが普及しました。 そして、20を超えるコアが存在する場合、その能力の限界が近いことが明らかになりました。 もちろん、最も簡単な方法で別の3つ目のリングを追加することもできます。 しかし、Intelは別の方法でタイヤ構造の新しいトポロジであるメッシュに進むことにしました。 このアプローチは、Xeon Phiプロセッサで既にテストされています(詳細については、この記事を参照してください) 。
概略的に、タイヤ構造のセル構造は次のように表すことができます。

Intelの図
新しいトポロジのおかげで、コア間の相互作用の速度を大幅に向上させることができ、メモリでの作業の効率を向上させることができました。
新しいAVX-512命令セット
Skylake-SPプロセッサは、新しいAVX-512命令セットの使用により、計算操作のパフォーマンスを向上させることができました。 512ビットのベクトルを使用して、32ビットおよび64ビットのAVX命令を拡張します。
プログラムは、8つの倍精度浮動小数点数、16の単精度浮動小数点数、または8つの64ビット整数、または16の32ビット整数を512ビットベクトル内にパックできるようになりました。 これにより、命令あたりの処理済みデータ要素の数を、Intel AVX / AVX2の2倍、Intel SSEの4倍に増やすことができます。
AVX-512はAVX命令セットと完全に互換性があります。 これは、特に、パフォーマンスを犠牲にすることなく、両方の命令セットを同じプログラムで使用できることを意味します(この問題は、SSEとAVXを一緒に使用したときに観察されました)。 AVXレジスタ(YMM0 — YMM15)は、SSEおよびAVXレジスタと同様に、AVX-512レジスタ(ZMM0 — ZMM15)の下位部分を指します。 したがって、AVX-512をサポートするプロセッサでは、AVXおよびAVX2命令は最初の16 ZMMレジスタの下位128または256ビットで実行されます。
性能試験
Sysbenchテスト
新しいプロセッサの機能の説明は、パフォーマンステストの結果なしでは完全ではありません。 このようなテストを実施し、 Intel Xeon 8170 PlatinumプロセッサとIntel Xeon E5-2680v4プロセッサに基づく2つのサーバーを比較しました。 両方のサーバーにUbuntu 16.04 OCがインストールされました。
人気のあるsysbenchパッケージのテストから始めましょう。
最初に行ったベンチマークは、素数を見つけるためのテストでした。
両方のサーバーにsysbenchをインストールし、コマンドを実行しました:
sysbench --test=cpu --cpu-max-prime=200000 --num-thread=1 run
テスト中に、スレッド数(--num-threadsパラメーター)を1から100に増やしました。
テスト結果はグラフィカルに表示されます(数値が小さいほど、結果は良くなります)。
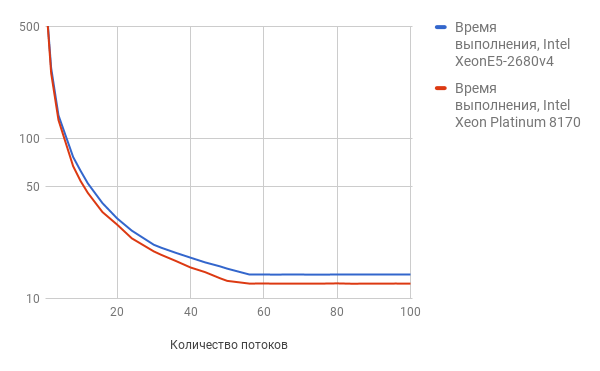
スレッドの数が増えると、Intel Xeon Platinum 8170のパフォーマンスが向上します。
次に、メモリバッファからの読み取り/書き込み操作の速度のテスト結果を検討します(数値が小さいほど、結果が良くなります)。
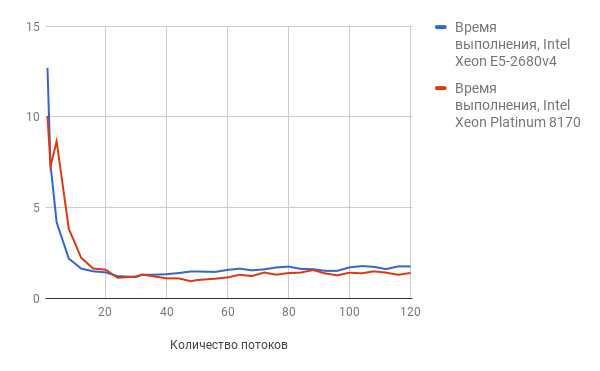
スレッド数の増加に伴い、Intel Xeon 8170 Platinumがリードしています。
スレッドテストは、多数の競合するスレッドをチェックします。 実験中に、スレッド数を1から120に増やしました。
このテストの結果を以下に示します(数値が小さいほど、結果は良くなります)。
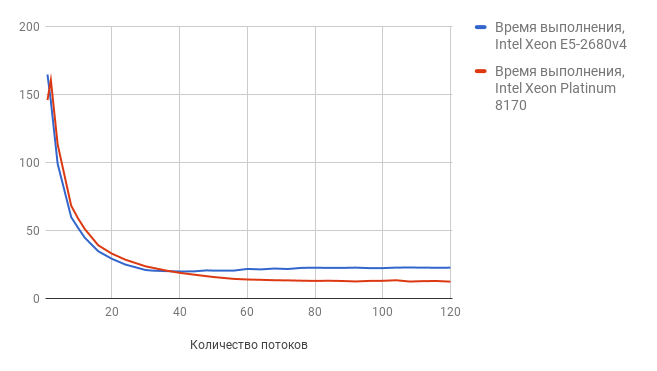
グラフからわかるように、スレッドの数が増えると、Intel Xeon Skylake-SP Platinumの結果が高くなります。
Linpackテスト
次のテストはLinpackでした。 このテストは、浮動小数点コンピューティングのパフォーマンスを測定するために使用され、コンピューティングテストの事実上の標準です。 その結果に基づいて、世界で最も生産性の高いシステムのリストが作成されています。
テストの意味は、 LU分解法を使用して、線形代数方程式(SLAE)の密なシステムを解くことです。 パフォーマンスはフロップで測定されます-これは、1秒あたりの浮動小数点数、つまり1秒あたりの浮動小数点演算の回数の減少です。 Linpackの基礎となるアルゴリズムについては、 こちらをご覧ください 。
Linpackベンチマークは、Intelからダウンロードできます。 テスト中に、プログラムは異なる次元の行列(1000〜45000)で15の連立方程式を解きます。 テストの結果はグラフで表示されます(数値が大きいほど、結果は良くなります)。
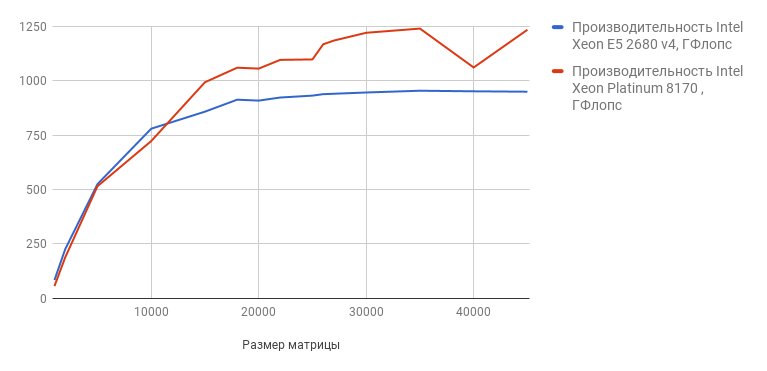
ご覧のとおり、新しいプロセッサの方がはるかに優れた結果を示しています。 最大マトリックスサイズ(45,000)のテストでは、Intel Xeon E5-2680v4のパフォーマンスは948.9728 GFlops、Intel Xeon Platinumは1233.2960 GFlopsです。
ブーストスピードアセンブリ
プロセッサのパフォーマンスを評価するには、ベンチマークだけでなく、実際のプラクティスに可能な限り近いテストも実施することが非常に望ましいです。 したがって、サーバーがソースコードからC ++ Boostライブラリのセットをコンパイルする速度を調べることにしました。
Boostの最新の安定バージョン1.64.0を使用しました。 公式サイトからソースコードを含むアーカイブをダウンロードしました。
Intel XeonプロセッサE5-2680v4を搭載したサーバーでは、アセンブリに12分25秒かかりました 。 Intel Xeon Platinumベースのサーバーは、 9分16秒でさらに高速にタスクに対応しました。
おわりに
この記事では、Intel Skylake-SPプロセッサに登場した最も重要な技術革新を確認しました。 詳細を知りたい人のために、トピックに関する便利なリンクを以下に示します。
- http://www.anandtech.com/show/11544/intel-skylake-ep-vs-amd-epyc-7000-cpu-battle-of-the-decade ;
- https://servernews.ru/955164 ;
- https://itpeernetwork.intel.com/intel-mesh-architecture-data-center ;
- https://software.intel.com/en-us/node/683422 ;
サンクトペテルブルクとモスクワのデータセンターでは、新しいプロセッサをベースにしたサーバーを注文できます。
次の構成を提供します。
| CPU | 記憶 | ディスク |
|---|---|---|
| Intel Xeon Silver 4114 | 96 GB DDR4 | 2×480 GB SSD + 2×4 TB SATA |
| Intel Xeon Silver 4114 | 192 GB DDR4 | 2×480 GB SSD |
| Intel Xeon Silver 4114 | 384 GB DDR4 | 2×480 GB SSD |
| Intel Xeon Gold 6140 2.1 | 384 GB DDR4 | 2×800 GB SSD |
新しいプロセッサに基づいてサーバーをレンタルするには、事前注文が必要ですが、すぐに継続的に利用できるようになります。