
私たちの多くは、ウェブアプリケーションのパフォーマンスについて常に考えています。遅い携帯電話で60 FPSを達成し、資産を完璧な順序でダウンロードし、可能な限りすべてをキャッシュします。
しかし、このWebアプリケーションのパフォーマンスの概念はあまりにも制限されていますか? ユーザーの観点から見ると、これらのアクションはすべて、パフォーマンスの大きなパイのほんの一部です。
この記事では、サイトを使用するすべての段階を説明します。まるで普通の人がそれぞれの期間を測定することでそれを行ったかのように。 そして、特定のサイトの特定のステップに特別な注意を払い、さらに最適化することができます。 このソリューション(機械学習)は、さまざまなサイトのさまざまなケースで使用できると考えています。
問題
例として、一部のユーザーが追加のアイテムを販売して、他のユーザーが新しい宝物を購入できるサイトを考えてみましょう。
ユーザーが新製品を販売するために登録するとき、ユーザーはカテゴリを選択し、次に希望する提案パッケージを選択し、詳細を入力し、広告を表示してから公開します。
カテゴリの選択-最初のステップを混乱させます。
第一に、674のカテゴリがあり、ユーザーは、たとえば壊れたカヤックに「移動」することにこだわることができます(Steve Krugは完全に言った: 考えさせないでください )。
第二に、製品がどのカテゴリ/サブカテゴリ/サブカテゴリに属するかが明確になった場合でも、プロセスには約12秒かかります。
ページの読み込み時間を12秒短縮できると言うと、驚くことでしょう。 さて、他の場所で12秒節約するのに十分に夢中になりませんか?
ジュリアスシーザーが言ったように、「12秒は12秒です」
最初に頭に浮かぶのは、適切に訓練された機械学習モデルを使用して製品のタイトル、説明、価格を入力すると、製品が属するカテゴリが決定されることです。
そのため、ユーザーはカテゴリを選択する時間を無駄にする代わりに、redditで2段式の二段ベッドを見るのにさらに12秒を費やすことができます。
機械学習-恐れることをやめるべき理由
通常、機械学習についてまったく何も知らない開発者は、そのプログラムがビデオゲームをプレイし、世界最高のチェスプレーヤーを上回ることができることを除いて、何をしますか?
- Google Machine Learning。
- リンクをクリックしてください。
- Amazon Machine Learningをご覧ください。
- 機械学習について何も知る必要がないことを理解してください。
- リラックスする。
そのまま処理する
Amazon MLのドキュメントで詳細に説明されています。 このアイデアに興味がある場合は、約5時間計画してドキュメントを読んでください。ここでは検討しません。
ドキュメントを読んだ後、そのような計画を策定できます。
- データをCSVファイルに書き込みます。 各行は要素(カヤックなど)であり、列は見出し、説明、価格、およびカテゴリでなければなりません。
- AWS S3にダウンロードします。
- このデータに基づいてマシンを「トレーニング」します(すべてが、組み込みのヘルプを備えたビジュアルウィザードを使用して行われます)。 小さなクラウドロボットは、名前、説明、価格に基づいてカテゴリを予測する方法を知る必要があります。
- 以下のフロントエンドにコードを追加します。これは、ユーザーが入力したタイトル/説明/価格を受け取り、予測のエンドポイントに送信し(Amazonによって自動的に作成されます)、予測カテゴリを画面に表示します。
サイトの例
このプロセスの重要な側面を模倣した素晴らしい形状を使用できます。
これらのエキサイティングな結果は、今後の退屈な説明中に興味を失うことはありません。 提案されたカテゴリが実際に機械学習に基づいて予測されたと信じてください。
冷蔵庫を販売してみましょう:

水族館はどうですか:

小さなクラウドロボットは、水族館とは何かを知っています!
とてもクールですね
(フォームは、React / Redux、jQuery、MobX、RxJS、Bluebird、Bootstrap、Sass、Compass、NodeJS、Express、およびLodashを使用して作成されました。アセンブリ用のWebPack。完成したものは1 MB強です-#perfwin)。
さてさて、さほど印象的なものではありません。
最初はただ甘やかされていたので、今からどこからでも実際のデータを取得する必要があります。 たとえば、多数のカテゴリにある10,000個のアイテム。 ローカル取引サイトが取得され、URLとDOMをCSV形式で保存する小さなパーサーが作成されました。 約4時間かかりました。機械学習実験全体の半分の時間です。
完成したCSVはS3にアップロードされ、ウィザードを通過してプログラムを構成およびトレーニングしました。 トレーニングの合計CPU時間は3分でした。
インターフェースはリアルタイムで動作するため、特定のパラメーターを渡した場合に必要なものが本当に返されるかどうかを確認できます。
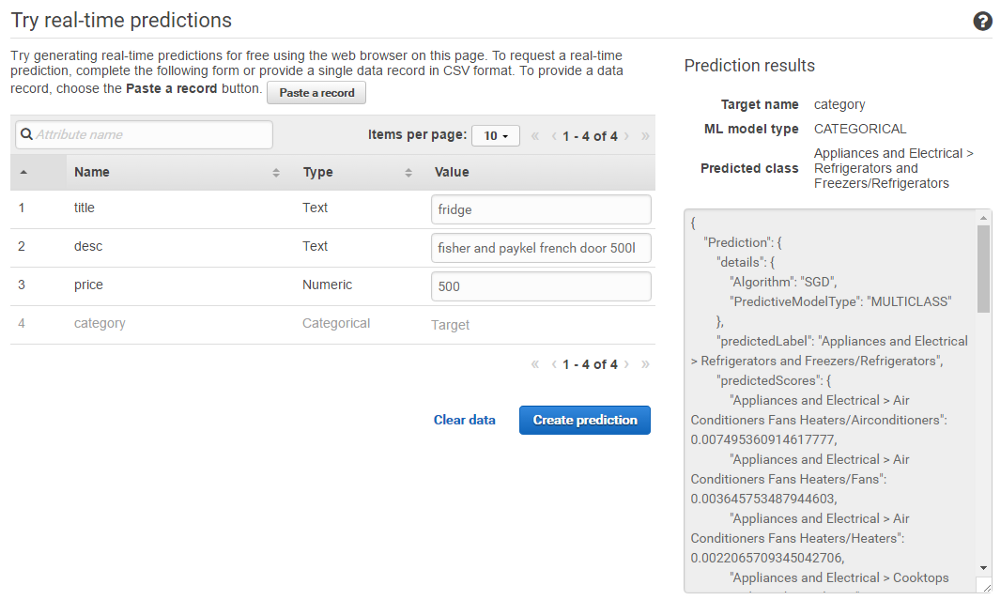
OK、動作します。
そして今、私はブラウザーからAmazon APIを直接プルしたくないので、一般公開されていません。 したがって、ノードサーバーから削除します。
バックエンドコード
一般的なアプローチは非常に簡単です。 識別子とデータをAPIに渡し、予測を送信します。
const AWS = require('aws-sdk'); const machineLearning = new AWS.MachineLearning(); const params = { MLModelId: 'some-model-id', PredictEndpoint: 'some-endpoint', Record: {}, }; machineLearning.predict(params, (err, prediction) => { // ! });
record
、申し訳ありませんが、
Record
はJSONオブジェクトであり、プロパティはモデルのトレーニング対象(名前、説明、価格)です。
記事に不完全なコードを残さないために、
/predict
エンドポイントを提供するserver.jsファイル全体を以下に示します。
const express = require('express'); const bodyParser = require('body-parser'); const AWS = require('aws-sdk'); const app = express(); app.use(express.static('public')); app.use(bodyParser.json()); AWS.config.loadFromPath('./private/aws-credentials.json'); const machineLearning = new AWS.MachineLearning(); app.post('/predict', (req, res) => { const params = { MLModelId: 'my-model-id', PredictEndpoint: 'https://realtime.machinelearning.us-east-1.amazonaws.com', Record: req.body, }; machineLearning.predict(params, (err, data) => { if (err) { console.log(err); } else { res.json({ category: data.Prediction.predictedLabel }); } }); }); app.listen(8080);
そして、aws-credentials.jsonの内容:
const express = require('express'); const bodyParser = require('body-parser'); const AWS = require('aws-sdk'); const app = express(); app.use(express.static('public')); app.use(bodyParser.json()); AWS.config.loadFromPath('./private/aws-credentials.json'); const machineLearning = new AWS.MachineLearning(); app.post('/predict', (req, res) => { const params = { MLModelId: 'my-model-id', PredictEndpoint: 'https://realtime.machinelearning.us-east-1.amazonaws.com', Record: req.body, }; machineLearning.predict(params, (err, data) => { if (err) { console.log(err); } else { res.json({ category: data.Prediction.predictedLabel }); } }); }); app.listen(8080);
(明らかに、
/private
ディレクトリは
.gitignore
にあるため、チェックされません。)
バックエンドが完成しました。
フロントエンドコード
フォームのコードは非常に簡単です。 彼は次のことを行います。
- 適切なフィールドで
blur
イベントをリッスンします。 - フォーム要素から値を取得します。
- 上記のコードで作成されたエンドポイント
/predict
エンドポイントにPOSTリクエストでそれらを転送します。 - 受信した予測をカテゴリフィールドに配置し、セクション全体を表示します。
(function() { const titleEl = document.getElementById('title-input'); const descriptionEl = document.getElementById('desc-input'); const priceEl = document.getElementById('price-input'); const catSuggestionsEl = document.getElementById('cat-suggestions'); const catSuggestionEl = document.getElementById('suggested-category'); function predictCategory() { const fetchOptions = { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify({ title: titleEl.value, description: descriptionEl.value, price: priceEl.value, }) }; fetch('/predict', fetchOptions) .then(response => response.json()) .then(prediction => { catSuggestionEl.textContent = prediction.category; catSuggestionsEl.style.display = 'block'; }); } document.querySelectorAll('.user-input').forEach(el => { el.addEventListener('blur', predictCategory); }); })();
以上です。 これは、クラウドロボットがユーザーデータを使用し、アイテムが属するカテゴリを予測するために必要なコードの100%です。
黙ってお金を取って
あなたの帽子を友達にしてください、この魔法はすべて無料ではありません...
例として使用したモデル(10,000行/ 4列でトレーニング)には6.3 MBが必要です。 リクエストの受信を待機しているエンドポイントがあるため、メモリ消費は6.3 MBと見なすことができます。 費用は1時間あたり0.0001ドルです。 または、年間約8ドル。 予測ごとに、0.0001ドルの手数料も請求されます。 無駄に予測を使用しないでください。
もちろん、Amazonが同様のサービスを提供しているだけではありません。 GoogleにはTensorFlowがありますが、最初の行からは非常にキラーな入門 ガイドがあります。 マイクロソフトでは、機械学習モデルも提供しています。 Microsoft Azure Machine LearningはAmazonよりもはるかに優れています。 ファイルをリロードせずに列を追加/削除できるため、反復ははるかに高速です。 Amazonでの11分間のトレーニングには、Azureで23秒かかります。 ちなみに、彼らの「スタジオ」インターフェースは非常によくできたWebアプリケーションです。
次は?
上記の例は確かに不自然です。 また、ここでは、プログラムが馬のトースターを撮影したスクリーンショットを掲載していません。 とにかく最高だ。 普通の人は機械学習を試すことができ、場合によってはユーザーのために改善を加えることができます。
考えられるすべての問題を一覧表示することは可能ですが、自分で見つけた場合はさらに興味深いものになります。 それで、それを試して、成功してください。